Linux系统性能监控与调优
Linux系统性能监控与调优 - 简书
性能调优攻略 | 酷 壳 - CoolShell
基本概念
QPS:query per second, 1秒内完成的请求数
RT:response time, 1个请求完成的时间
Throughput越大,Latency会越差。因为请求量过大,系统太繁忙,所以响应速度自然会低
Latency越好,能支持的Throughput就会越高。因为Latency短说明处理速度快,于是就可以处理更多的请求
最佳线程数量=((线程等待时间+线程cpu时间)/线程cpu时间) * cpu数量
线程过多,时间消耗长,并不是说代码执行效率下降了,而是资源的竞争,导致线程等待的时间上升了,线程越多消耗内存越多,过多的线程直接将系统内存消耗殆尽
平均响应时间 = (并发线程数/最佳线程数) * 最佳线程数的响应时间
总QPS=线程数*单个线程的QPS
CPU监控与调优
系统负载
系统负载:可运行(运行中或者等待CPU调度)或不可中断(等待IO)的进程数
uptime
load average: 2.03, 20.17, 15.09
表示过去1分钟、5分钟、15分钟的系统负载情况
多核情况下,真实的负载是需要除去CPU个数,如load为1,在1个CPU时,是满的,在2个CPU时,是50%
如果Load Average高,但CPU的us、sy使用率低,这时要看一下磁盘IO或网络IO的等待时间(等待进程包括等待CPU时间片和等待IO(不可中断),等待IO的进程的状态为“D”,可以通过ps aux的state列进行查看,磁盘的IO等待可以通过iostat -x查看,主要看await, svctm列)
使用率
使用率分为:us(用户)、sy(系统)、id(空闲)、wa(IO等待)、ni(通过nice命令改变过优先级)、hi(硬中断)、si(软中断)、st(虚拟机)
如果在多核的机器侠,使用率有可能超过100%,也存在多个进程加起来后超过100%的情况
一般us:65%-70%,sy:30%-35%,idle:0%-5%,证明CPU被充分使用和均衡
如果wa很高,就需要看一下磁盘I/O
如果wa很低,id很高,但系统还是很慢,那就要查一下网络IO或者远程服务器的回应是不是很慢,或者查一下上下文切换和锁,看看是否存在大量的锁争用和等待的情况
监控工具:top, vmstat
查看某个进程的使用率
while :; do ps -eo pid,ni,pri,pcpu,psr,comm | grep ‘mysqld’; sleep 1;
找到消耗CPU最多的前10个进程
ps -eo pcpu,pid,user,args | sort -k 1 -r | head -10
找到消耗内存最多的前10个进程
ps -auxf | sort -nr -k 4 | head -10
运行队列大小
一个进程可以有running,runnable,block(等待IO或者系统调用)
运行队列是指runnable(等待运行)的进程数
每个处理器的运行队列大小不应超过3个,少于10倍的CPU个数,否则线程过多或者CPU不够
监控工具:vmstat(procs下的r列)
上下文切换
- 上下文
进程运行时的寄存器和CPU缓存等 - 保存位置
进程描述符和内核堆栈 - 发生时机
IO操作、资源同步、优先级抢占、时间片到达、软硬中断
时钟中断:每隔一段时间就会发生一次时钟中断(切换),可以通过以下办法判断时钟中断的频率
cat /proc/interrupts | grep timer
...wait 10s...
cat /proc/interrupts | grep timer
将两个结果值相减然后除以10,则得到每秒因时钟中断发生的切换数,如果系统的上下文切换数比该值大,则有可能发生了IO操作或者资源争用或者sleep等
- 主动切换
锁争用、调用系统函数 - 被动切换
除主动切换之外的切换
监控工具:vmstat(system下的cs列)
更多描述可参考Context Switching, Some Resources
锁争用
主要是监控主动切换
监控工具:pidstat -w -I -p [pid] seconds的cswch/s列
统计的是全部核的总切换数,占用率=count/核数*80000/CPU时钟数,通常一次切换消耗80000次时钟频率,如假设当前切换数是3500,CPU为双核的3.0GHz,那么上下文切换占用的CPU率为:(3500/2)*80000/3000000000=4.7%
如果切换率超过5%,则证明程序存在锁争用;如果在3%-5%之间,则要注意,可能存在锁争用
线程迁移
一个线程最好在同一个CPU中运行,因为缓存等可以重新利用,如果因为一个CPU忙而无法运行,然后将线程迁移到其他的核,则要重新加载缓存,造成性能损耗
快速监控
通过vmstat查看整体CPU使用情况
top查看CPU占用高的几个进程
pidstat查看这几个进程对应的线程
调优
- 确保没有没用的进程在运行(ps -ef)
- 检查可运行队列,确定每个CPU不超过3个,如果过多,要不就减少线程数,要不就把应用迁移到其他机器上或者增加CPU
- 确定CPU利用率中user/system的比例维持在70/30,当system的利用率比较高时,要查看是IO中断还是锁竞争,同时检查wa(IO等待)的比例是否过高
- 调高关键进程的优先级,将非关键的,但使用CPU较多的进程的优先级降低
- 将进程绑定到特定的CPU(CPU亲近性),减少CPU缓存的失效
- 将产生大量中断的进程绑定到一个固定的CPU上
- 修改程序,增加并行性
内存监控与调优
内存主要看可用内存大小、SWAP空间大小、页面换入换出频率
free -m
total used free shared buffers cached
Mem: 2887 2789 97 0 26 1177
-/+ buffers/cache: 1585 1301
Swap: 0 0 0
- Mem:物理内存统计
| 字段 | 说明 |
|---|---|
| total | 物理内存总量 |
| used | 已分配的内存(包含buffers与cache),但其中可能部分缓存并未实际使用 |
| free | 未被分配的内存 |
| shared | 共享内存 |
| buffers | 系统分配但未被使用的buffers的数量,针对磁盘块数据的cache,块设备的读写缓冲区 |
| cached | 系统分配但未被使用的cache的数量,针对文件的cache |
- -/+ buffers/cache
| 字段 | 说明 |
|---|---|
| used | 实际使用的内存总数, 第一行的used - buffers - cached |
| free | 实际剩余的内存总数, 第一行的free + buffers + cached |
Linux会尽量使用尽可能多的内存,如果存在足够的内存,Linux会对经常被访问的文件进行缓存(cached),同时在进行IO操作时,Linux会使用块缓存机制(buffers),加快IO处理
所以一般查看内存还剩余多少,要查看free的第二行参数
- swap:交换分区大小
swap空间的大小并不能表明内存存在瓶颈,因为如果一个进程空闲了,Linux会把它换出到磁盘
主要是要看页面换入换出的大小(vmstat的si、so列)
如果可用内存不多,有大量的页面交换活动,则要考虑加内存;(每秒有200-300的页面换入或换出则代表内存存在瓶颈)
如果仍有很多内存,但有页面活动,则代表系统没有页面交换,而可能是正在加载程序

调优
- 增大内存
- 使用大页、大的TLB,特别适合于数据库服务器
- 创建一个或多个单独的swap分区
- 调整swap写到硬盘的参数:vm.swappiness, vm.dirty_background_ratio, vm.dirty_ratio
磁盘监控与调优
只显示磁盘信息,以M为单位,显示扩展信息,n代表多少秒输出一次
iostat -dmx n
Device: rrqm/s wrqm/sr/s w/s rMB/swMB/s avgrq-sz avgqu-sz await svctm %util
sda 0.11 33.49 0.27 26.820.00 0.24 18.16 0.10 3.68 0.67 1.82
| 字段 | 描述 |
|---|---|
| rrqm/s | 队列中每秒钟合并的读请求数量(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge) |
| wrqm/s | 队列中每秒钟合并的写请求数量 |
| r/s | 每秒钟完成的读请求数量 |
| w/s | 每秒钟完成的写请求数量 |
| rMB/s | 每秒钟读取的数量,读IOPS=(rMB/s) / (r/s),IOPS:一次磁盘的连续读或者连续写称为一次磁盘 I/O,随机读写频繁的应用的关键衡量指标,IOPS = 1s/(寻道时间+旋转延迟+数据传输时间) |
| wMB/s | 每秒钟写入的数量,写IOPS=(wMB/s) / (w/s) |
| avgrq-sz | 平均请求扇区的大小,平均每次请求的大小,avgrq-sz < 32K 随机存取为主。 avgrq-sz > 32K 顺序存储为主 |
| avgqu-sz | 平均请求队列的长度,此值越小越好,avgqu-sz > 2 可以认为存在I/O性能问题 |
| await | 平均每次请求的等待时间,单位毫秒,一般系统IO响应时间应该低于5ms,如果大于10ms就比较大了。等待时间包括了队列时间和服务时间,await和svctm越接近越好,代表几乎无需等待,反之差值越大,队列的时间越长,应用得到的响应时间变慢, 还可参考vmstat结果b参数(等待资源的进程数)和wa参数(IO等待所占用CPU时间百分比) |
| svctm | 平均每次请求的服务时间,即磁盘读或写操作执行的时间,包括寻道,旋转时延,和数据传输等时间。(寻道时间:是指将读写磁头移动至正确的磁道上所需要的时间。寻道时间越短,I/O操作越快,目前磁盘的平均寻道时间一般在3-15ms。旋转延迟: 是指盘片旋转将请求数据所在扇区移至读写磁头下方所需要的时间。旋转延迟取决于磁盘转速,通常使用磁盘旋转一周所需时间的1/2表示。比如,7200 rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms,而转速为15000 rpm的磁盘其平均旋转延迟约为2ms。数据传输时间: 是指完成传输所请求的数据所需要的时间,它取决于数据传输率,其值等于数据大小除以数据传输率。目前IDE/ATA能达到133MB/s,SATA II可达到300MB/s的接口数据传输率,数据传输时间通常远小于前两部分消耗时间,简单计算时可忽略。) (r/s+w/s)*(svctm/1000)=util,如果util达到100%,那么此时svctm=1000/(r/s+w/s),假设IOPS是1000,那么svctm大概在1毫秒左右,如果长时间大于这个数值,说明系统出了问题。 |
| util | 设备的利用率,如果util接近100%,则说明设备的能力趋向于饱和(如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈) |
每个参数的理解可以参考下面的图片
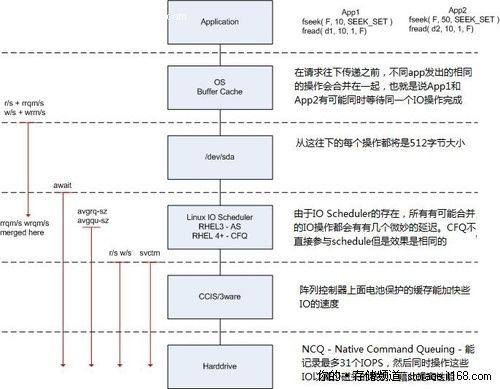
上图的左边是iostat显示的各个性能指标,每个性能指标都会显示在一条虚线之上,这表明这个性能指标是从虚线之上的那个读写阶段开始计量的,比如说图中的w/s从Linux IO scheduler开始穿过硬盘控制器(CCIS/3ware),这就表明w/s统计的是每秒钟从Linux IO scheduler通过硬盘控制器的写IO的数量。
结合上图对读IO操作的过程做一个说明,在从OS Buffer Cache传入到OS Kernel(Linux IO scheduler)的读IO操作的个数实际上是rrqm/s+r/s,直到读IO请求到达OS Kernel层之后,有每秒钟有rrqm/s个读IO操作被合并,最终转送给磁盘控制器的每秒钟读IO的个数为r/w;在进入到操作系统的设备层(/dev/sda)之后,计数器开始对IO操作进行计时,最终的计算结果表现是await,这个值就是我们要的IO响应时间了;svctm是在IO操作进入到磁盘控制器之后直到磁盘控制器返回结果所花费的时间,这是一个实际IO操作所花的时间,当await与svctm相差很大的时候,我们就要注意磁盘的IO性能了;而avgrq-sz是从OS Kernel往下传递请求时单个IO的大小,avgqu-sz则是在OS Kernel中IO请求队列的平均大小。
最终得出
平均单次IO大小(IO Chunk Size) = avgrq-sz
平均IO响应时间(IO Response Time) = await
IOPS(IO per Second) = r/s + w/s
吞吐率(Throughtput) = rkB/s + wkB/s
iowait并不能反应磁盘瓶颈
其实际测量的是cpu时间: iowait = (cpu idle time)/(all cpu time)
高速cpu会造成很高的iowait值,但这并不代表磁盘是系统的瓶颈。唯一能说明磁盘是系统瓶颈的方法,就是很高的read/write时间,一般来说超过20ms,就代表了不太正常的磁盘性能。为什么是20ms呢?一般来说,一次读写就是一次寻道+一次旋转延迟+数据传输的时间。由于,现代硬盘数据传输就是几微秒或者几十微秒的事情,远远小于寻道时间220ms和旋转延迟48ms,所以只计算这两个时间就差不多了,也就是15~20ms。只要大于20ms,就必须考虑是否交给磁盘读写的次数太多,导致磁盘性能降低了。
在Linux下,可以通过iostat命令查看磁盘性能。其中的svctm一项,反应了磁盘的负载情况,如果该项大于15ms,并且util%接近100%,那就说明,磁盘现在是整个系统性能的瓶颈了
上述理论也就是说只有磁盘表现出的读写能力可以说明磁盘是否有问题,如果磁盘发挥正常,如达到15ms的要求,那么如果cpu超水平发水,iowait还是会出现的。也就说iowait其实是cpu和磁盘的比赛,有一个发挥不正常都会产生iowait高的现象,但不能说磁盘的问题,也可能是cpu的问题
同时还可以安装iotop工具,查看每个进程使用了多少IO流量
例子
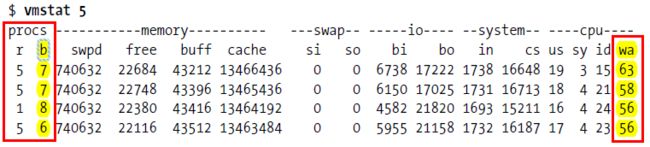
vmstat下的b和wa列的值比较大,iostat下的磁盘利用率高
如果wa超过20%,说明IO等待严重,引起IO等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作)
bi+bo参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘IO有问题

调优
- 各个磁盘的使用率是否非常高(%util),确定是哪块磁盘问题
- 确定应用是顺序还是随机读取硬盘,顺序要看每秒的读写量,随机要看IOPS(同时计算磁盘所能承受的最大的IOPS)
- 如果磁盘慢,要比较await和svctm(等待时间、实际操作时间),如果await远大于svctm,则应用将变慢
- 监控swap和系统分区,确保虚拟内存不是文件系统IO的瓶颈
- 更换更快的存储设备
- 使用多个磁盘(RAID)
- 增加系统的文件缓存
- 应用级别则减少读写次数(使用buffered的IO、整合数据、合并读写)
- 选择正确的IO调度算法:CFQ、Deadline、NOOP
- 选择正确的文件系统:Ext2、Ext3、ReiserFS
- 选择正确的日志模式:journal、ordered、writeback
- 选择正确的块大小
网络监控与调优
- 网络质量监控
netstat -i
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 0 20403566 0 0 0 7747807 0 0 0 BMRU
lo 16436 0 55899937 0 0 0 55899937 0 0 0 LRU
| 字段 | 说明 |
|---|---|
| Iface | 网络设备的接口名称 |
| MTU | 最大传输单元,单位字节 |
| RX-OK/TX-OK | 已经准确无误的接收/发送了多少数据包 |
| RX-ERR/TX-ERR | 接收/发送数据包时产生了多少错误 |
| RX-DRP/TX-DRP | 接收/发送数据包时丢弃了多少数据包 |
| RX-OVR/TX-OVR | 由于误差而遗失了多少数据包 |
| Flg | 接口标记,L:表示该接口是个回环设备,B:表示设置了广播地址,M:表示接收所有数据包,R:表示接口正在运行,U:表示接口处于活动状态,O:表示在该接口上禁用arp,P:表示一个点到点的连接 |
正常情况下,RX-ERR/TX-ERR、RX-DRP/TX-DRP和RX-OVR/TX-OVR的值都应该为0,如果这几个选项的值不为0,并且很大,那么网络质量肯定有问题,网络传输性能也一定会下降
- 显示各种连接状态的个数
netstat -nat | awk '{print $6}' | sort | uniq -c | sort -n
指定某个ip的
netstat -nat |grep {IP-address} | awk '{print $6}' | sort | uniq -c | sort -n
指定某个端口
netstat -nat |grep {port} | awk '{print $6}' | sort | uniq -c | sort -n
- 列出当前端口被哪个进程占用
netstat -nap | grep port
- 安装iftop工具,查看各进程的网络的流量
调优
- 增加网络缓存
/proc/sys/net/ipv4/tcp_mem
/proc/sys/net/core/rmem_default
/proc/sys/net/core/rmem_max
/proc/sys/net/core/wmem_default
/proc/sys/net/core/wmem_max
/proc/sys/net/core/optmem_max - 调整窗口大小
通过读写缓存大小进行调整(rmem_max、wmem_max)
设定的值=网卡速率(bytes/s)*延时(sec),延时通过ping命令可得 - TCP调优
接收大量客户端:sysctl -w net.ipv4.tcp_tw_reuse=1和sysctl -w net.ipv4.tcp_tw_recycle=1 (TIME_WAIT重用)
尽快释放回收FIN_WAIT_2状态的socket:sysctl -w net.ipv4.tcp_fin_timeout=30
尽快释放回收空闲的连接:sysctl -w net.ipv4.tcp_keepalive_time=1800
增加backlog以便接收更多客户端:sysctl -w net.ipv4.tcp_max_syn_backlog=4096
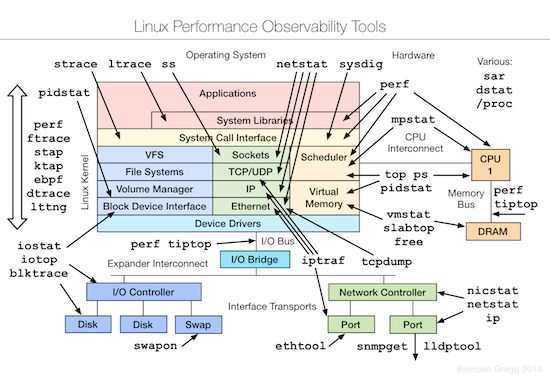
性能监控工具
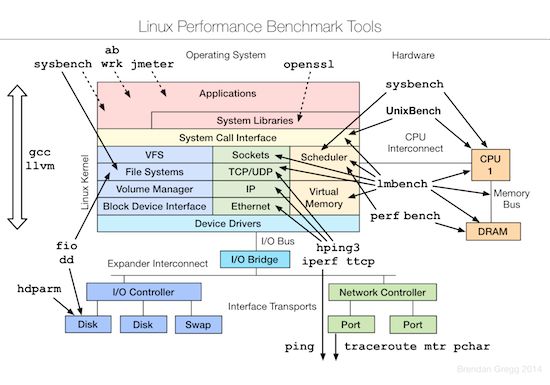
性能测试工具
性能优化工具
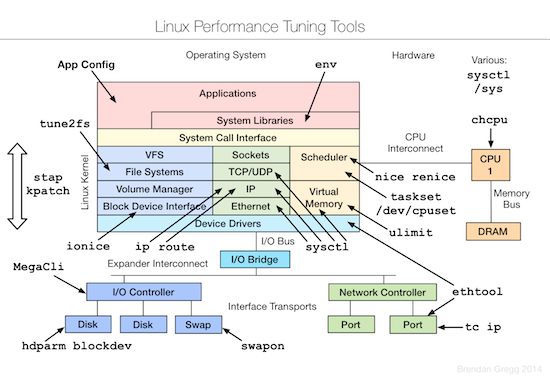
总结
- 调优的目的是高效地使用资源,尽可能地使用最多的资源,从而提高性能
- 任何资源都要查看是资源使用率满了,还是没有高效使用资源
例如CPU使用率高,是因为算法问题(死循环,低效算法),还是因为程序本身就需要这么多CPU。如果CPU使用率低,则查看是因为资源等待还是线性操作。
又如I/O,wa低下,也有可能I/O的问题(当然不是硬件问题),wa低下代表磁盘的使用率低下。这时要看到底是程序本身不怎么使用磁盘,还是没有高效使用(大量随机操作,而不是批量操作,顺序写入,使用缓冲等) - 如果要提升服务器端的响应时间RT
采用减少IO的时间能达到最佳效果,比如合并多个IO请求
减少IO的调用次数:并发HTTP请求(无上下文依赖,多个连接,一个线程)、HTTP连接池(长连接)
减少CPU的使用时间
使用缓存 - 如果要提升QPS
采用优化CPU的时间能达到最佳效果,同时可以加大线程数
减少CPU的使用时间
增加CPU的数量
减少同步锁
如果CPU不能被压到85%以上,并且此时的QPS已经达到了峰值,则说明另有瓶颈
参考
性能调优攻略
作者:PennyWong
链接:https://www.jianshu.com/p/c750acdc10e4
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。