约2万字-Vue源码解读汇总篇(续更)
约2万字-Vue源码解读汇总篇(续更)
一、前言
1.系列汇总
未完待续...
Vue源码解读:06Vue3探索篇
Vue源码解读:05生命周期篇
Vue源码解读:04模板编译篇
Vue源码解读:03虚拟Dom篇
Vue源码解读:02变化侦测篇
Vue源码解读:01核心思想篇
Vue源码解读:前言篇
2.有关说明
①受限学识水平和实践经验,难免错漏,欢迎各位前辈同学批评指正。
②本系列文章仅从源码角度进行学习,不作 vue 基本使用和api的解释,相关需要可阅读官网。
③本系列(Vue源码剖析笔记),目前共6篇即01核心思想篇,02变化侦测篇(响应式篇)、03虚拟dom篇、04模板编译篇、05生命周期篇、06vue3探索篇,主要基于vue2.6和vue3.2版本源码库分析,共约2万字。
④本系列文章的学习目的:
a.学习如何更好的设计代码以及搭建架构。
b.深入了解vue。
二、总目录
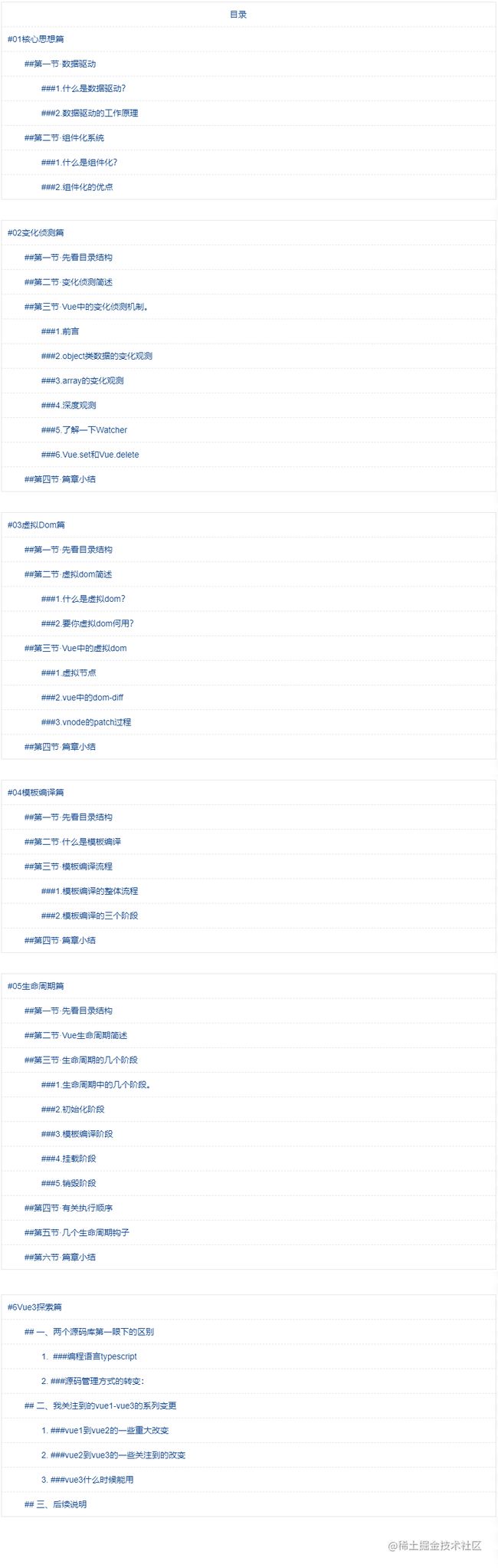
正文集合
6Vue3探索篇
vue-next 源码
Composition API
vue3 官网
目录
一、两个源码库第一眼下的区别
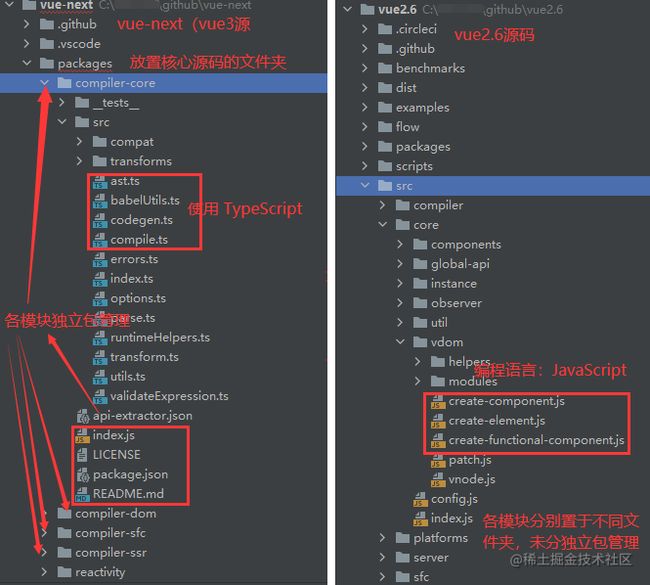
正如vue3和vue2 源码库目录对比图所示,我们学习源码,第一眼看去就发现了两个版本,在源码库的设计上,有着醒目的明显区别,vue3并没有延续vue2的目录结构,从中我们可以得到的信息有:
1. 编程语言typescript
①编程语言的选择:TypeScript取代JavaScript
vue3在编程语言上选用了TypeScript,而vue2是javascript,为什么会有这样的变化。官网引用npm包中的官方说明:
随着应用的增长,静态类型系统可以帮助防止许多潜在的运行时错误,这就是为什么 Vue 3 是用 TypeScript 编写的。这意味着在 Vue 中使用 TypeScript 不需要任何其他工具——它具有一等公民支持。
②拓展:TypeScript与JavaScript的区别
这里引用一下美团郭凯老师在知乎上的一个回答:
TypeScript is a syntactic sugar for JavaScript. TypeScript syntax is a superset of ECMAScript 2015 (ES2015) syntax. Every JavaScript program is also a TypeScript program.
语言层面:JavaScript和TypeScript都是ECMAScript(ECMA-262)的具体实现。
执行环境层面:浏览器引擎和Node.js都能够直接运行JavaScript,但无法直接运行TypeScript。
时序层面:TypeScript被真正执行前,会通过编译转换生成JavaScript,之后才能被解释执行。
厂商层面:JavaScript由Netscape率先推出,现在主要由各大浏览器厂商实现。而TypeScript is >a trademark of Microsoft Corporation,目前由微软进行设计和维护。
TypeScript是ECMAScript 2015的语法超集,是JavaScript的语法糖。JavaScript程序可以直接>移植到TypeScript,TypeScript需要编译(语法转换)生成JavaScript才能被浏览器执行。
③个人观点:TypeScript会是趋势
从css预处理语言sass的角度看TypeScript的发展趋势,TypeScript很有可能会成为日常开发首选(在TypeScript和JavaScript之间),就好像web前端开发者,现在的日常开发主要是使用css预处理语言而不是原生的css。
css预处理语言sass于css,和TypeScript于JavaScript的相似之处:
a. css预处理语言和TypeScript的妙处,TypeScript是ECMAScript 2015的语法超集,是JavaScript的语法糖。而类似sass这样的css预处理语言也是css的语法超集,也同样有很多语法糖。
b. sass最终会被编译(转换)成css,TypeScript最终会被编译(语法转换)成JavaScript,才能在浏览器上执行。
c. 日常业务开发,css预处理语言已成为取代css的选项,但css预处理语言不会取代css,至少相当长一段时间不会。相信TypeScript之于JavaScript也会是这样的趋势。
顺带提一下,Angular很早就选用了TypeScript而非JavaScript。
2. 源码管理方式的转变:
vue3源码管理上,采用monorepo管理方式,和vue2相比,实现从模块管理到包管理的转变。
①什么是monorepo
web前端开发者熟悉的Babel代码仓库就是使用monorepo进行管理的。在Babel的GitHub仓库中的 README.md 中是这样描述的:
How is the repo structured?
The Babel repo is managed as a [monorepo]>( https://github.com/babel/babel/blob/main/doc/design/monorepo.md) that is composed of many npm packages.
Monorepo 是管理项目代码的一个方式,指在一个项目仓库 (repo) 中管理多个模块/包 (package)。
②monorepo 的优缺点
优点:当分模块改为分包,各部分内容就降低了耦合性,给多人独立开发提供了便利;统一了工作流Code Sharing(这点实践不足,以后再谈)。
缺点:很明显的缺点是体积要变大,各包的依赖项可能会重复,也许有我未知的好方法。此外就是有一点门槛,需要一个团队的成员都熟悉monorepo管理方式,以及相关技巧,并且准守约定。
二、我关注到的vue1-vue3的系列变更
1.vue1到vue2的一些重大改变
①虚拟dom的引入
虚拟dom,虚拟节点的引入,除了提升了性能外,与html的解耦,为vue支持ssr提供了条件。
②根元素
vue2中,在模板中只允许一个根元素;而在vue1中是被允许多个的。没意外,vue3会回归允许多个根元素。(这个变化挺有意思的)
③生命周期

④其他细节
2. vue2到vue3的一些关注到的改变
①源码使用typescript编写,vue3对typescript的支持更友好。
②新增 hook api。
③变化观测机制,使用proxy替换Object.defineProperty。proxy在数据劫持上做的更好更全面,不仅可以劫持object数据,还可以劫持数组,且可以观测动态新增的属性。
④重写虚拟dom,优化插槽生成,静态树提升。
⑤其他,了解更多vue2版本的源码剖析:
01核心思想篇:https://note.youdao.com/s/363fiG3R
02变化侦测篇:https://note.youdao.com/s/aJFtug2F
03虚拟dom篇:https://note.youdao.com/s/sb5yDRO
04模板编译篇:https://note.youdao.com/s/WdWD5Nuj
05生命周期篇:https://note.youdao.com/s/McRiwMwq
vue2到vue3的变更,更详细的说明请阅读官网:https://v3.cn.vuejs.org/guide/migration/introduction.html
3.vue3什么时候能用
2020年4 月 21 日,在由前端圈组织发起的 B 站直播中,尤大大最后表示,目前的 Vue 3.0 Beta 已经可以投入使用,但对稳定性要求高的项目,暂时不建议使用。他建议生产项目暂时不要上,新的、小的项目可以试水。
根据规律,每一个程序的大本版后面都会有n多个是解决bug的小版本,所以那啥。此外,还有一点值得一提,2.x还有会最有一个版本,即2.7。
2022年1月,vue3已经发布正式版本,更新到了 v3.2.26,生态也逐渐完善。
三、后续说明
后续也许大概可能也会像剖析vue2那样,分析每个核心包。
├─packages # 放置核心代码的文件夹
│ ├─compiler-core # 模板编译-核心相关
│ ├─compiler-dom # 模板编译-浏览器dom渲染相关
│ ├─compiler-ssr # 模板编译-服务端渲染相关
│ ├─reactivity # 响应式相关
│ ├─reactivity-transform # 响应式相关
│ ├─runtime-core # 运行时-核心相关
│ ├─runtime-dom # 运行时-浏览器渲染dom相关
│ ├─runtime-test # 运行时-测试相关
│ ├─server-renderer # 服务端渲染相关
│ ├─sfc-playground #
│ ├─shared # 公共共享部分
│ ├─size-check # 代码量大小检测相关
│ ├─template-explorer #
│ ├─vue # 包括运行时和编译时的完整版本
│ └─vue-compat # Vue源码解读:05生命周期篇
目录
第一节·先看目录结构
├─instance # 实现vue实例的代码
│ ├─render-helpers # render辅助代码
│ ├─events.js # 事件初始化处理相关代码
│ ├─index.js #
│ ├─init.js # 初始化代码
│ ├─inject.js #
│ ├─lifecycle.js # 生命周期相关代码
│ ├─proxy.js # 代理相关代码
│ ├─render.js # render渲染函数相关代码
│ └─state.js #第二节·Vue生命周期简述
我不太敢写什么是生能周期这个定义,总感觉压力很大,虽然只是笔记,哈哈哈。在学校上C语言的必修课的时候,似乎没听说过生命周期这个说话,但从java开始,很多技术栈,也不知道是个啥东东,就老爱有生命周期这个东东。反正不管啥,生命周期应该也许大概可能就是从开始到结束的过程,前提是支持周期的。了解生命周期的意义应在于可以帮助我们写出更优雅的代码,以及快速定位bug,而不是纠结于定义本身。知道vue的生命周期中都干了啥,啥时候干的,是我们了解vue生周期核心所在。
第一段就当做是日记,下面开始正经的笔记。vue实例开始创建直至被销毁的过程,称为vue的生命周期。vue的生命周期依次,主要经历初始化,模板编译,挂载,销毁四个阶段(官网vue实例生命期图示底部提示了一句话,模板编译在使用构造生成文件中,将提前执行。)。与vue生命周期密切相关的钩子函数有beforeCreate,created,beforeMount,mounted,beforeUpdate,updated,beforeDestroy,destroyed。vue的api文档上,一共有11个和生命周期有关的钩子函数,另外三个分别是activated,deactivated,最后一个是vue2.5.0新增的,叫errorCaptured。
那么来一张官方的生命周期图。

第三节·生命周期的几个阶段
1.生命周期中的几个阶段。
从官网的生命周期图和源码看,可以大致将vue的生命周期分为4个阶段,分别是初始化阶段,模板编译阶段,挂载阶段,销毁阶段。
初始化阶段:为vue实例初始化属性、事件、数据观测等。
模板编译阶段:将模板字符串编译成渲染函数。(该阶段在runtime版本中不存在,因为已经编译好了。)
挂载阶段:将vue实例挂载到指定dom上,即将模板渲染到真实dom中。
销毁阶段:解绑指令,移除事件监听器,销毁子实例。
2.初始化阶段
初始化阶段主要干了两件事,一是创建Vue实例,二是为实例初始化属性、事件、响应式数据。
从instance的入口文件index.js可以看到,Vue函数代码很少,核心代码就一行即调用实例的_init方法,如下:
//源码位置 src/instance/index.js
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}
//源码位置 src/instance/init.js
而_init方法是在initMixin函数中被挂载到Vue原型上的。initMixin代码如下:
export function initMixin (Vue: Class) {
Vue.prototype._init = function (options?: Object) {
const vm: Component = this
// a uid
vm._uid = uid++
let startTag, endTag
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
startTag = `vue-perf-start:${vm._uid}`
endTag = `vue-perf-end:${vm._uid}`
mark(startTag)
}
// a flag to avoid this being observed
vm._isVue = true
// merge options
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options)
} else {
vm.$options = mergeOptions(
resolveConstructorOptions(vm.constructor),
options || {},
vm
)
}
/* istanbul ignore else */
if (process.env.NODE_ENV !== 'production') {
initProxy(vm)
} else {
vm._renderProxy = vm
}
// expose real self
vm._self = vm
initLifecycle(vm) //初始化生命周期
initEvents(vm) //初始化事件
initRender(vm) //初始化渲染
callHook(vm, 'beforeCreate') //触发beforeCreate钩子
initInjections(vm) // resolve injections before data/props
initState(vm) //初始化状态,例如props,methods,data,computed,watch
initProvide(vm) // resolve provide after data/props
callHook(vm, 'created') //触发created钩子
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
vm._name = formatComponentName(vm, false)
mark(endTag)
measure(`vue ${vm._name} init`, startTag, endTag)
}
if (vm.$options.el) {
vm.$mount(vm.$options.el) //调用$mount,进入下一阶段:挂载阶段或模板编译阶段
}
}
} 从源码中可以看到,在init初始化中,初始化了生命周期,事件,render渲染,触发beforeCreate钩子,实例状态(props,methods,data,computed,watch),触发created钩子等。从这里我们可以得到一个信息,created钩子的时候,实例已经被初始化,且props,methods,data,computed,watch可用;因为触发beforeCreate钩子在初始化实例状态之前,所以按理beforeCreate钩子中是无法使用实例的props,methods,data,computed,watch属性的。
//源码位置 src/instance/state.js
export function initState (vm: Component) {
vm._watchers = []
const opts = vm.$options
if (opts.props) initProps(vm, opts.props)//初始化Props属性
if (opts.methods) initMethods(vm, opts.methods)//初始化Methods属性
if (opts.data) {
initData(vm) //初始化data属性
} else {
observe(vm._data = {}, true /* asRootData */)
}
if (opts.computed) initComputed(vm, opts.computed) //初始化Computed计算属性
if (opts.watch && opts.watch !== nativeWatch) {
initWatch(vm, opts.watch)//初始化Watch监听属性
}
}关注一下initState(vm) 初始化状态,这个函数,里面核心代码如下,从中我们可以得到一个信息,vue实例的属性在初始化的时候的执行顺序依次是props,methods,data,computed,watch。
初始化阶段通过callHook触发的生命周期钩子是beforeCreate,created。
3.模板编译阶段
在初始化函数_init中,在调用一系列初始化函数后,即初始化工作完成后之后,在改该函数的末尾,调用了$mount,使vue生命周期进入下一个阶段。这里的下一个阶段是模板编译阶段,当然这个阶段不一定存在,有可能初始化阶段完成之后就直接跳到挂载阶段了。
模板编译阶段的主要内容是将模板字符串转换成render函数,在vue的某些版本比如vue.runtime.js,就不会有模板编译阶段。模板编译阶段的之所以有可能不存在,是因为某些情况下,模板字符串可能已经提前编译了,比如vue-loader就有预编译的功能。事实上,我们的日常开发中,使用.vue的文件内部的模板字符串,都是在构建的时候就已经预编译了。
4.挂载阶段
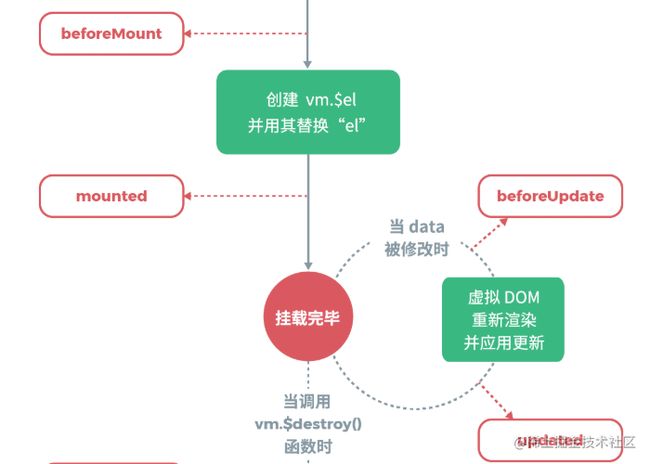
瞅一眼官方的生命周期图示,大概就可以知道挂载阶段主要工作一是创建创建Vue实例并用其替换el选项对应的DOM元素,二是开启数据状态的监控(如何监控的详看变化侦测篇)。挂载阶段有关的钩子函数有beforeMount,beforeUpdate,mounted,updated。
关于挂载阶段beforeMount,beforeUpdate,mounted的触发时机,可以看下lifecycle.js文件中的mountComponent函数,该函数是在进入挂载阶段时调用的。
// 源码位置 src/instance/lifecycle.js
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
if (!vm.$options.render) {
vm.$options.render = createEmptyVNode
if (process.env.NODE_ENV !== 'production') {
/* istanbul ignore if */
if ((vm.$options.template && vm.$options.template.charAt(0) !== '#') ||
vm.$options.el || el) {
warn(
'You are using the runtime-only build of Vue where the template ' +
'compiler is not available. Either pre-compile the templates into ' +
'render functions, or use the compiler-included build.',
vm
)
} else {
warn(
'Failed to mount component: template or render function not defined.',
vm
)
}
}
}
callHook(vm, 'beforeMount')
let updateComponent
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
const name = vm._name
const id = vm._uid
const startTag = `vue-perf-start:${id}`
const endTag = `vue-perf-end:${id}`
mark(startTag)
const vnode = vm._render()
mark(endTag)
measure(`vue ${name} render`, startTag, endTag)
mark(startTag)
vm._update(vnode, hydrating)
mark(endTag)
measure(`vue ${name} patch`, startTag, endTag)
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
// we set this to vm._watcher inside the watcher's constructor
// since the watcher's initial patch may call $forceUpdate (e.g. inside child
// component's mounted hook), which relies on vm._watcher being already defined
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
hydrating = false
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
return vm
}5.销毁阶段

vue实例生命周期的最后一个阶段,销毁阶段,该阶段的主要工作是销毁,比如解绑指令,销毁子组件,取消依赖最终,销毁事件监听器。从上图可以看出,当调用vm.$destroy()时进入销毁阶段。$destroy函数的源码如下。
//源码位置 src/instance/lifecycle.js
Vue.prototype.$destroy = function () {
const vm: Component = this
if (vm._isBeingDestroyed) {
return
}
callHook(vm, 'beforeDestroy') //触发beforeDestroy钩子
vm._isBeingDestroyed = true
// remove self from parent
const parent = vm.$parent
if (parent && !parent._isBeingDestroyed && !vm.$options.abstract) {
remove(parent.$children, vm)
}
// teardown watchers
if (vm._watcher) {
vm._watcher.teardown()
}
let i = vm._watchers.length
while (i--) {
vm._watchers[i].teardown()
}
// remove reference from data ob
// frozen object may not have observer.
if (vm._data.__ob__) {
vm._data.__ob__.vmCount--
}
// call the last hook...
vm._isDestroyed = true
// invoke destroy hooks on current rendered tree
vm.__patch__(vm._vnode, null)
// fire destroyed hook
callHook(vm, 'destroyed') //触发destroyed钩子
// turn off all instance listeners.
vm.$off() //解绑所有的实例监听器
// remove __vue__ reference
//移除ref引用
if (vm.$el) {
vm.$el.__vue__ = null
}
// release circular reference (#6759)
if (vm.$vnode) {
vm.$vnode.parent = null
//将vue实例从父级中解绑
}
}由源码看到,在销毁阶段触发钩子函数有beforeDestroy,destroyed。beforeDestroy是在比较靠前的位置,这时vue实例还没被销毁,即是说vue实例还是可以正常使用的。我们想要在实例销毁前做的事情,可以再beforeDestroy钩子中写,比如销毁定时器等。
第四节·有关执行顺序
几个生命周期钩子的运行顺序,依次先后是beforeCreate,created,beforeMount,mounted,beforeDestroy,destroyed。beforeUpdate,updated的话,dom只要有更新,他们就会运行,可以确定的只能是beforeUpdate必定在updated之前运行。
几个内置属性的执行顺序依次是props,methods,data ,computed,watch。
第五节·几个生命周期钩子
// 源码位置 src/shared/constants.js
// 2.6.11版本的vue
export const LIFECYCLE_HOOKS = [
'beforeCreate',
'created',
'beforeMount',
'mounted',
'beforeUpdate',
'updated',
'beforeDestroy',
'destroyed',
'activated',
'deactivated',
'errorCaptured',
'serverPrefetch'
]研究vue版本是2.6.11,如上代码,我们可以看到一共注册了12钩子。
serverPrefetch:最后一个serverPrefetch不了解,我猜是和vue支持ssr服务端渲染有关。
errorCaptured:倒数第二个errorCaptured是在2.5.0+ 新增,官网关于它的介绍是:
当捕获一个来自子孙组件的错误时被调用。此钩子会收到三个参数:
错误对象、发生错误的组件实例以及一个包含错误来源信息的字符串。
此钩子可以返回 false 以阻止该错误继续向上传播。
activated:被 keep-alive 缓存的组件激活时调用。(在服务器端渲染期间不被调用)
deactivated:被 keep-alive 缓存的组件停用时调用。(在服务器端渲染期间不被调用)
beforeCreate:初始化阶段,vue实例的挂载元素$el和数据对象data都为undefined,还不可用。
created:初始化阶段,data,methods已经初始化,可用。$el不可用。
beforeMount:挂载阶段,实例挂载前,此时按理$el还不可用,但$el已经初始化,dom节点还是虚拟dom节点。
mounted:挂载阶段,此时实例已经完成挂载,$el可用。
beforeUpdate:有更新才会触发,data被修改时,dom更新前触发。
updated:有更新才会触发,dom更新时触发。
beforeDestroy:销毁阶段,实例销毁前执行,此时vue实例还可正常使用。
destroyed:销毁阶段,据官网实例销毁后调用。此时this指向的实例还存在,但是子实例,监听器等已经被销毁。
我做了一个简单的打印验证,打印结果和代码如下:
{{name}}
跳转到别的页面

第六节·篇章小结
本篇章小结如下:
①1个定义:vue实例开始创建直至被销毁的过程,称为vue的生命周期。
②4个阶段:介绍了初始化、模板编译、挂载、销毁四个阶段。
③12个钩子:简单介绍了12个钩子函数:beforeCreate,created, beforeMount, mounted, beforeUpdate, updated, beforeDestroy,destroyed, activated,deactivated, errorCaptured, serverPrefetch。
④2个排序:一是几个钩子执行顺序依次为beforeCreate,created,beforeMount,mounted,beforeDestroy,destroyed。beforeUpdate,updated则是dom有要更新才会出发。二是vue实例几个属性的执行顺序依次是props,methods,data ,computed,watch。
Vue源码解读:04模板编译篇
目录

第一节·先看目录结构
本篇研究的代码位置:src/compiler
├─compiler # 实现模板编译的代码
│ ├─codegen # 代码生成器,将ast树生成render渲染函数。
│ │ ├─events.js # 事件处理相关代码,例如键盘事件,stopPropagation()事件等。
│ │ └─index.js #
│ │
│ ├─directives # 处理相关指令的代码,例如v-model,v-bind,v-on等。
│ │ ├─bind.js # v-bind指令相关代码
│ │ ├─index.js #
│ │ ├─model.js # v-model指令相关代码
│ │ └─on.js # v-on指令相关代码
│ │
│ ├─parser # 模板解析器,将模板字符串转换成ast树
│ │ ├─entity-decoder.js # 实体解码器,返回元素节点的文本内容
│ │ ├─filter-parser.js # 过滤解析器
│ │ ├─html-parser.js # html解析器
│ │ ├─index.js #
│ │ └─text-parser.js # 文本解析器
│ │
│ ├─codeframe.js #
│ ├─create-compiler.js # 创建模板编译器相关代码
│ ├─error-detector.js # 错误检测器
│ ├─helpers.js # 辅助代码,里面引入过滤解析器和工具类util里面的emptyObject。
│ ├─index.js #
│ ├─optimizer.js # 优化器,优化ast树,主要是标记静态节点
│ └─to-function.js # 将render函数字符串转换成真正的函数第二节·什么是模板编译
从写下的代码,到用户见到界面,大致经历以下几个流程:
模板字符串=》ast树=》render函数=》vnode=》用户见到的界面。

将开发者写下的模板字符串,经过一些列处理,生成render函数的这一过程就是模板编译。简单地说,模板编译解析就是为了得到render函数。
第三节·模板编译流程
1.模板编译的整体流程
从目录结构中,我们看到compiler下有一个parser和codegen的文件夹,这两个文件夹的内容就是模板编译的核心代码,parser负责将模板字符串解析成AST树,codegen则是负责将AST树生成可渲染的render函数。当然其中还有一个优化阶段,优化的内容主要是标记AST树中的静态节点,这部分代码则放在optimizer.js文件中。将开发者写下的模板字符串,编译解析成render函数的过程,我们称之为模板编译。大致的,我们将模板编译流程分为模板解析阶段,优化阶段,代码生成阶段,三个阶段。
模板编译的整体流程,大致如下图:
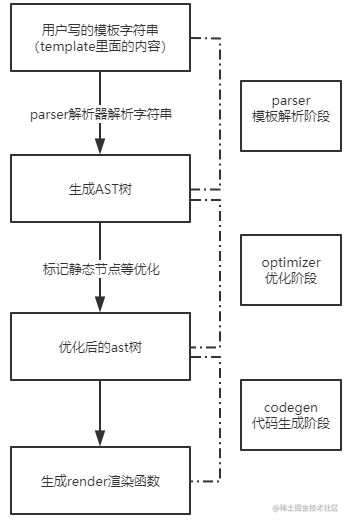
看下模板编译的入口文件index.js。
//源码位置 src/compiler/index.js
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
const ast = parse(template.trim(), options)//解析器,解析模板字符串,生成AST树
if (options.optimize !== false) {
optimize(ast, options)//优化器,对代码优化,主要是标记静态节点
}
const code = generate(ast, options)//代码生成器,将ast树转换成render渲染函数
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})模板编译的入口文件代码不多,但也很清晰地将模板编译的三个阶段变现出来了。
2.模板编译的三个阶段
①解析阶段
模板解析阶段,解析模板字符串,并输出ast树,看下模板解析的入口文件src/compiler/parser/index.js。

源码中的注释就说得很清楚明确,主函数parse的作用就是讲html转换为ast树,解析流程大致是这样的,调用parserHTML函数,对模板进行解析,主要是解析模板中的原生html。在解析过程遇到文本信息,则调用parseText函数进行解析,遇到过滤器则调用parseFilters函数解析。大致流程如下。

模板解析的关键手段。正则表达式和js提供的字符串的方法,是解析模板字符串的核心手段,例如识别是原生html标签,还是文本内容,指令的识别,例如v-on,v-bind,v-if,v-for等。还有错误检查的作用,例如缺少结束标签等。
感受一下src/compiler/parser/index.js中使用的正则表达式。
模板解析的本质。前文已经提到,解析器的作用是将模板字符串生成ast树,ast树其实和vnode很相似,都是用js来描述的。感受一下解析前后对比。
// 解析前模板字符串
{{name}}
//解析后的的ast树
{
tag: "div"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: undefined,
attrsList: [],
attrsMap: {},
children: [
{
tag: "p"
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: {tag: "div", ...},
attrsList: [],
attrsMap: {},
children: [{
type: 2,
text: "{{name}}",
static: false,
expression: "_s(name)"
}]
}
]
}看过前后对比,我们可以试想一下,要是自己有没有办法做一个转换呢。没有什么是无理由的凭空出现的。我粗浅的下个定义,所有的解析器本质上都是基于原物做识别和截取。如果这种解析有输出,那么通常会识别和截取相结合,而解析的输出物就是基于原物的一种增删改查。
没错,ast就是基于模板字符串,截取出来,然后根据需要,进行自定义的增删改查得来的。源码中识别和截取的手段就是字符串的方法结合正则表达式。比如截取标签名。
let html = '{{name}}
'
let tagNameStart = html.indexOf('<')
let tagNameEnd = html.indexOf('>')
let tagName = html.substring(tagNameStart+1, tagNameEnd)
console.log(tagName)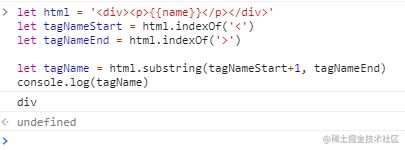
②优化阶段
优化的意义。优化阶段的目标是标记静态节点,而标记静态节点的意义在于,减小开销,优化性能。原本ast是可以直接生成render函数的了,但是为了性能,还是加了一个优化器进行优化,给vue点赞。标记静态节点,是如何与性能优化挂钩的呢,这在虚拟dom篇章中有解释,其实就是服务于虚拟dom的patch过程的,patch过程遇到静态节点,会跳过新旧vnode的比较过程,从而减小开销。
优化阶段做的两件事。优化阶段主要是做两件事,一是标记静态节点,而是标记静态根节点。看下源码。
//源码位置 src/compiler/optimizer.js
export function optimize (root: ?ASTElement, options: CompilerOptions) {
if (!root) return
isStaticKey = genStaticKeysCached(options.staticKeys || '')
isPlatformReservedTag = options.isReservedTag || no
// first pass: mark all non-static nodes.
//第一部分:标记所有静态节点
markStatic(root)
// second pass: mark static roots.
//第二部分:标记根节点。
markStaticRoots(root, false)
}标记静态节点。标记静态节点大致流程是调用先标记根节点是否静态节点,然后根据节点的类型(node.type,type为1表示元素节点,2表示包含动态变量的文本节点,3表示纯文本节点)判断,如果是元素节点则递归调用markStatic方法,继续标记,直到递归结束,遍历标记完整个AST树。看下源码。
function markStatic (node: ASTNode) {
node.static = isStatic(node)//标记根节点
if (node.type === 1) {//type为1表示元素节点,2表示包含动态变量的文本节点,3表示纯文本节点
// do not make component slot content static. this avoids
// 1. components not able to mutate slot nodes
// 2. static slot content fails for hot-reloading
if (
!isPlatformReservedTag(node.tag) &&
node.tag !== 'slot' &&
node.attrsMap['inline-template'] == null
) {
return
}
for (let i = 0, l = node.children.length; i < l; i++) {
const child = node.children[i]
markStatic(child)//递归标记子节点
if (!child.static) {
node.static = false
}
}
if (node.ifConditions) {
for (let i = 1, l = node.ifConditions.length; i < l; i++) {
const block = node.ifConditions[i].block
markStatic(block)
if (!block.static) {
node.static = false
}
}
}
}
}
function isStatic (node: ASTNode): boolean {
if (node.type === 2) { // expression 包含变量的文本节点,不属于静态节点,返回false
return false
}
if (node.type === 3) { // text 纯文本节点,属于静态节点,返回true
return true
}
//元素节点,则须符合一定条件,才能成为静态节点。
return !!(node.pre || (
!node.hasBindings && // no dynamic bindings
!node.if && !node.for && // not v-if or v-for or v-else
!isBuiltInTag(node.tag) && // not a built-in
isPlatformReservedTag(node.tag) && // not a component
!isDirectChildOfTemplateFor(node) &&
Object.keys(node).every(isStaticKey)
))
}静态节点标记流程大致如下图所示。
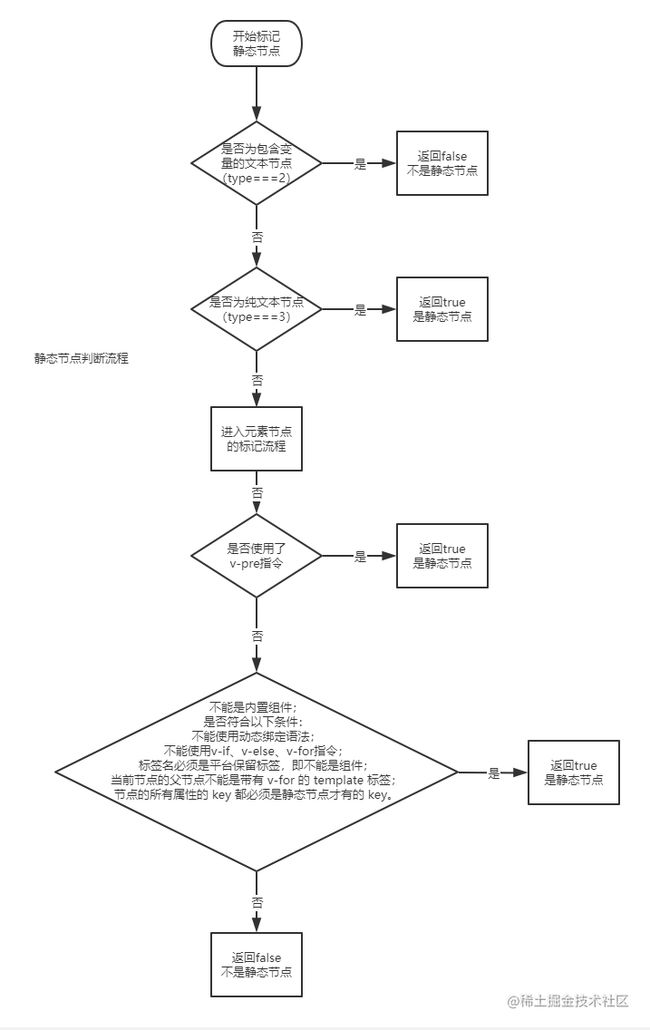
标记静态根节点。关于静态根节点的条件,源码的写得很清楚,第一,必须是元素节点;第二,节点本身必须是静态节点;第三,有子节点;第四,不能只有静态文本的子节点。
function markStaticRoots (node: ASTNode, isInFor: boolean) {
if (node.type === 1) {
if (node.static || node.once) {
node.staticInFor = isInFor
}
// For a node to qualify as a static root, it should have children that
// are not just static text. Otherwise the cost of hoisting out will
// outweigh the benefits and it's better off to just always render it fresh.
//要使节点符合静态根节点的条件,它应该有且不只是静态文本的子节点。
// 否则,标记的成本将超过效益,最好还是让它更新。
if (node.static && node.children.length && !(
node.children.length === 1 &&
node.children[0].type === 3
)) {
node.staticRoot = true
return
} else {
node.staticRoot = false
}
if (node.children) {
for (let i = 0, l = node.children.length; i < l; i++) {
//递归调用markStaticRoots进行标记
markStaticRoots(node.children[i], isInFor || !!node.for)
}
}
if (node.ifConditions) {
for (let i = 1, l = node.ifConditions.length; i < l; i++) {
markStaticRoots(node.ifConditions[i].block, isInFor)
}
}
}
}③代码生成阶段
代码生成阶段做的事。
代码生成阶段的做的事情就是将ast树,转换成render函数代码。这一点在在代码生成器的主函数generate的返回值就可以清晰地看到。
export function generate (
ast: ASTElement | void,
options: CompilerOptions
): CodegenResult {
const state = new CodegenState(options)
const code = ast ? genElement(ast, state) : '_c("div")'
return {
render: `with(this){return ${code}}`,//返回render函数代码
staticRenderFns: state.staticRenderFns
}
}generate生成器函数的入参是ast树和编译器配置项,没错,这个ast就是优化阶段的输出,而代码生成器的输出结果集,返回的的就是render函数代码。在return前有一个判断,判断ast是否为空,非空则调用genElement生成节点;空则返回'_c("div")',实质是返回一个空div的vnode。
没错模板编译和虚拟dom的关联性极大,触发vnode的产生时机就是在代码生成阶段。generate 函数中起主要作用的是genElement,genElement的作用是生成vnode。
genElement根据入参,调用不同的代码生成器,比如静态节点生成器genStatic、组件生成器genComponent等,生成不同的vnode。genElement调用的众多生成器函数中,其中有一个生成器叫genChildren,这算是核心的了,这是在遇到标签名为template的元素的时候调用的。而genChildren又会调用genNode生成节点。在虚拟dom篇中有提到真正会挂载到dom上的节点,只有三种,即为元素节点,文本节点,注释节点。所以我们可以看到节点生成器的源码中,就是通过判断node的type等属性,来决定生成这三种节点中的哪种节点。源码如下。
export function genElement (el: ASTElement, state: CodegenState): string {
if (el.parent) {
el.pre = el.pre || el.parent.pre
}
if (el.staticRoot && !el.staticProcessed) {
return genStatic(el, state)
} else if (el.once && !el.onceProcessed) {
return genOnce(el, state)
} else if (el.for && !el.forProcessed) {
return genFor(el, state)
} else if (el.if && !el.ifProcessed) {
return genIf(el, state)
} else if (el.tag === 'template' && !el.slotTarget && !state.pre) {
return genChildren(el, state) || 'void 0'
} else if (el.tag === 'slot') {
return genSlot(el, state)
} else {
// component or element
let code
if (el.component) {
code = genComponent(el.component, el, state)
} else {
let data
if (!el.plain || (el.pre && state.maybeComponent(el))) {
data = genData(el, state)
}
const children = el.inlineTemplate ? null : genChildren(el, state, true)
code = `_c('${el.tag}'${
data ? `,${data}` : '' // data
}${
children ? `,${children}` : '' // children
})`
}
// module transforms
for (let i = 0; i < state.transforms.length; i++) {
code = state.transforms[i](el, code)
}
return code
}
}
function genNode (node: ASTNode, state: CodegenState): string {
if (node.type === 1) {//生成元素节点
return genElement(node, state)
} else if (node.type === 3 && node.isComment) {//生成注释节点
return genComment(node)
} else {//生成文本节点
return genText(node)
}
}有了代码生成器,我们就可以得到render函数代码,其实这里render并不是真正意义上的函数。这里可cue一下,模板编译文件夹的最后一个文件to-function.js了,没错,就是它将代码生成器输出的render代码串,转换成真正的render函数,一个function。Vue实例在挂载的时候,会调用对应的render函数来生成实例上的template选项所对应的VNode,没错,这个Vue调用render函数就是to-function的输出。
第四节·篇章小结
①模板编译的定义:将开发者写下的模板字符串,经过一些列处理,生成render函数的这一过程就是模板编译。
②模板编译的整体流程:解析器将模板字符串解析成ast树,然后优化器对ast进行标记静态节点的优化,最后代码生成器将优化后的ast树生成render函数。
③介绍模板编译三个阶段:解析阶段,优化阶段,代码生成阶段的工作过程,并回看了源码。
Vue源码解读:03虚拟Dom篇
目录

第一节·先看目录结构

第二节·虚拟dom简述
1.什么是虚拟dom?
前端三大主流框架中,React和Vue都涉及到虚拟dom,那么虚拟dom是啥呢?程序的世界,见名知意,是一个被广泛认可的编码命名规则。从见名知意这个角度,虚拟dom就是dom的一种虚拟,假的dom。开发中,真实dom通常使用html来描述,而虚拟dom采用的虚拟技术通常是JavaScript,也就是说使用JavaScript来编写模拟dom,这样并非真实的dom就是虚拟dom。简单的说,虚拟dom是指用JavaScript编写的伪dom。例如下面这样。
//真实dom:html标签描述的dom节点
真实dom节点
//虚拟dom:js描述的dom节点
Element({
tagName:'div',
attr:{ id:'divNode', value:'虚拟dom节点' }
})2.要你虚拟dom何用?
React在众多前端框架中,性能算是它的优点,其中缘由之一就是虚拟dom,React使用的JSX语法将HTML、CSS,全部使用JS表示,可以说将虚拟dom演绎到了极致。因为操作真实的dom性能消耗很大,很大是多大,俺也不知道也不敢问。可以看下,下面这张将一个普通div节点使用JS打印出来的结果,粗略感受一下。

总之吧,就是说操作真实dom的开销很大,而使用虚拟dom,可以减少重排重绘,减少操作真实dom。基于性能优化的需求,选择了虚拟dom。所以,在v-show和v-if,两个指令中,我会尽可能的选择使用v-show。因为v-show的切换不会频繁创建和销毁dom节点,它是利用HTML的display属性实现的。重排和重绘的概念,这里不多说。
第三节·Vue中的虚拟dom
1.虚拟节点
组成虚拟dom的重要一环是虚拟节点,vue节点分为组件节点、元素节点、函数组件节点、注释节点、文本节点、克隆节点。下面是vnode.js的相关代码。
//源码位置 src/core/vdom/vnode.js
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
// strictly internal
raw: boolean; // contains raw HTML? (server only)
isStatic: boolean; // hoisted static node
isRootInsert: boolean; // necessary for enter transition check
isComment: boolean; // empty comment placeholder?
isCloned: boolean; // is a cloned node?
isOnce: boolean; // is a v-once node?
asyncFactory: Function | void; // async component factory function
asyncMeta: Object | void;
isAsyncPlaceholder: boolean;
ssrContext: Object | void;
fnContext: Component | void; // real context vm for functional nodes
fnOptions: ?ComponentOptions; // for SSR caching
devtoolsMeta: ?Object; // used to store functional render context for devtools
fnScopeId: ?string; // functional scope id support
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions,
asyncFactory?: Function
) {
this.tag = tag //标签名
this.data = data //数据信息
this.children = children //子节点,一个数组
this.text = text //节点的文本信息
this.elm = elm //虚拟节点对应的真实节点
this.ns = undefined //当前节点的名字空间
this.context = context //当前节点对应的Vue实例
this.fnContext = undefined //函数组件对应的Vue实例
this.fnOptions = undefined //函数组件实例的配置项
this.fnScopeId = undefined //函数组件的
this.key = data && data.key //函数组件scopeId
this.componentOptions = componentOptions //组件配置项
this.componentInstance = undefined //组件实例对象
this.parent = undefined //其父节点
this.raw = false //
this.isStatic = false //是否为静态节点
this.isRootInsert = true //是否作为根节点插入
this.isComment = false //是否为注释节点
this.isCloned = false //是否为克隆节点
this.isOnce = false //是否含有v-once指令
this.asyncFactory = asyncFactory //异步工厂模式
this.asyncMeta = undefined //异步元
this.isAsyncPlaceholder = false //是否有异步占位符
}
// DEPRECATED: alias for componentInstance for backwards compat.
//不推荐:用于向后兼容的组件实例的别名
/* istanbul ignore next */
get child (): Component | void {
return this.componentInstance
}
} 可以看到源码中不同类型的虚拟节点,其实都是VNode实例,通过入参控制,决定生成什么类型的节点。有了虚拟节点,就有了虚拟dom。前文提到选择虚拟dom的理由是减少开销,其实比起操作真实dom,操作虚拟dom,就是使用js计算性能消耗替换操作真实dom的性能消耗。都是性能消耗,简单的说操作js单价比较便宜,而操作dom的消耗单价比较贵。也就是说操作真实dom的消耗更大,大到值得选择虚拟dom替代真实dom。
虚拟节点在性能优化上的优势,除了操作js相比dom的开销小外,就是差异更新和缓存原理了。在视图渲染之前,先把编译模板编译成虚拟节点,并且进行缓存,新生成的虚拟节点,会和上一次缓存下来的虚拟节点进行差异比较,有差异的虚拟节点,即为需要更新到真实dom上的部分。没有差异的节点,则不更新,这样就减少了开销。具体的差异比较原理后面会说。
2.vue中的dom-diff
我们知道vue中在视图更新的时候,使用了diff算法,diff算法想必大家并不陌生。比如git中diff,linux中的difff,感受一下git diff算法的结果。

对一个文件使用git的diff命令后,得出的是该文件新旧版本的diff算法后的差异部分,其余并不展示,可以比较清晰展示出变化情况。而在vue中diff算法,是用在视图更新过程,具体上是新旧虚拟节点的比较,使用缓存结合diff算法更新,而不是全部更新的目的之一就是为了减少开销,提升性能。我们知道前端提升性能的方向之一,就是减少dom的操作,减少浏览器的重排。而使用虚拟dom和diff差异更新就可以达到减少操作dom,减少重排,减少开销,提升性能的目的。
3.vnode的patch过程
①前言
vnode的比较更新过程,可以称之为patch过程,根据有道翻译,patch有很多解释,这里取“打补丁”之意,打补丁使用Windows系统的同学想必不陌生。打补丁本质上是一种更新。简单地说,新旧vnode比较找差异更新过程就是dom-diff过程,而dom-diff可以说是整个虚拟dom的核心。那么vue中的dom-diff,vnode的patch在源码是怎样的呢。
②patch过程
patch过程就干了一件事,就是对比新旧vnode找差异并更新,具体上分为三部分,创建节点,删除节点,更新节点。新旧vnode更新过程是以新生成的vnode为基准,给旧vnode打补丁,最终使用的是打补丁后的vnode,即旧的vnode。新vnode中有而旧vnode没有的节点,则在旧vnode中创建节点;新vnode中没有而旧vnode中有的vnode,则在旧vnode中删除该节点;新旧vnode中都有的节点,则使用新vnode中的节点替换旧vnode中的。
③回到源码
创建节点
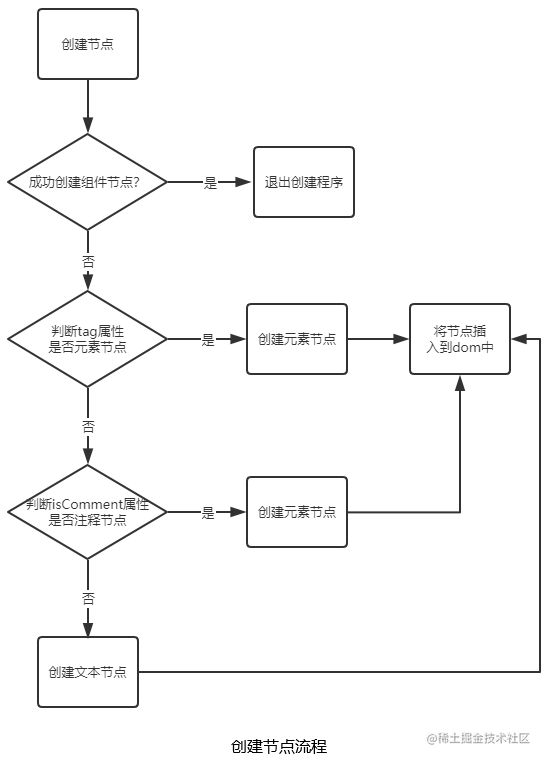
前文中提到虚拟节点有6种,但从源码来看,创建之后执行insert()方法,将节点插入到dom中的节点只有三种,即元素节点,注释节点,文本节点。而判断应当创建哪种节点,则由传入的参数节点。但在创建这三种节点前会先尝试创建组件节点,创建成功则退出程序。
//源码位置 src/core/vdom/patch.js
//添加节点
function addVnodes (parentElm, refElm, vnodes, startIdx, endIdx, insertedVnodeQueue) {
for (; startIdx <= endIdx; ++startIdx) {
createElm(vnodes[startIdx], insertedVnodeQueue, parentElm, refElm, false, vnodes, startIdx)
}
}
//创建元素节点
function createElm (
vnode,
insertedVnodeQueue,
parentElm,
refElm,
nested,
ownerArray,
index
) {
if (isDef(vnode.elm) && isDef(ownerArray)) {
vnode = ownerArray[index] = cloneVNode(vnode) // 克隆节点
}
vnode.isRootInsert = !nested // for transition enter check
if (createComponent(vnode, insertedVnodeQueue, parentElm, refElm)) {
//成功创建组件节点退出程序
return
}
const data = vnode.data
const children = vnode.children
const tag = vnode.tag
if (isDef(tag)) {
vnode.elm = vnode.ns
? nodeOps.createElementNS(vnode.ns, tag)
: nodeOps.createElement(tag, vnode)//创建元素节点
setScope(vnode)
/* istanbul ignore if */
if (__WEEX__) {
//WEEX环境的代码省略...
} else {//创建子节点
createChildren(vnode, children, insertedVnodeQueue)
if (isDef(data)) {
invokeCreateHooks(vnode, insertedVnodeQueue)
}
insert(parentElm, vnode.elm, refElm)
}
if (process.env.NODE_ENV !== 'production' && data && data.pre) {
creatingElmInVPre--
}
} else if (isTrue(vnode.isComment)) {//创建注释节点
vnode.elm = nodeOps.createComment(vnode.text)
insert(parentElm, vnode.elm, refElm)
} else {//创建文本节点
vnode.elm = nodeOps.createTextNode(vnode.text)
insert(parentElm, vnode.elm, refElm)
}
}
删除节点
删除节点逻辑相对简单,新节点中没有而旧节点中有的,就执行删除。
//源码位置 src/core/vdom/patch.js
//删除节点
function removeNode (el) {
// 获取父节点
const parent = nodeOps.parentNode(el)
// 调用父节点的removeChild方法,删除子节点
if (isDef(parent)) {
nodeOps.removeChild(parent, el)
}
}更新节点

//源码位置 src/core/vdom/patch.js
//比较节点,更新节点
function patchVnode (
oldVnode,
vnode,
insertedVnodeQueue,
ownerArray,
index,
removeOnly
) {
if (oldVnode === vnode) { //新旧节点全等,return结束比较过程
return
}
if (isDef(vnode.elm) && isDef(ownerArray)) {
// clone reused vnode 克隆重复使用的节点
vnode = ownerArray[index] = cloneVNode(vnode)
}
const elm = vnode.elm = oldVnode.elm
if (isTrue(oldVnode.isAsyncPlaceholder)) {
if (isDef(vnode.asyncFactory.resolved)) {
hydrate(oldVnode.elm, vnode, insertedVnodeQueue)
} else {
vnode.isAsyncPlaceholder = true
}
return
}
//新旧节点都是同key名的静态节点,是则return退出程序。
if (isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
vnode.componentInstance = oldVnode.componentInstance
return
}
let i
const data = vnode.data
if (isDef(data) && isDef(i = data.hook) && isDef(i = i.prepatch)) {
i(oldVnode, vnode)
}
const oldCh = oldVnode.children
const ch = vnode.children
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
if (isDef(i = data.hook) && isDef(i = i.update)) i(oldVnode, vnode)
}
//新节点vnode的text属性未定义
if (isUndef(vnode.text)) {
//新旧节点都有子节点
if (isDef(oldCh) && isDef(ch)) {
//新旧子节点不同,则更新子节点
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
}
//只有新节点有子节点
else if (isDef(ch)) {
//非生产环境,检查元素key是否重复
if (process.env.NODE_ENV !== 'production') {
checkDuplicateKeys(ch)
}
//新节点没有text属性,若旧节点有text属性,则将该属性的值设置为空字符串
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
//添加节点
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
}
//只有旧节点有子节点,则删除dom中的该子节点
else if (isDef(oldCh)) {
removeVnodes(oldCh, 0, oldCh.length - 1)
}
//新节点没有text属性,而旧节点有text属性,则将元素的text设置为空串
else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '')
}
}
//新节点vnode的text属性存在
else if (oldVnode.text !== vnode.text) {
//新旧节点text不同,则将新节点的text替换旧的
nodeOps.setTextContent(elm, vnode.text)
}
if (isDef(data)) {
if (isDef(i = data.hook) && isDef(i = i.postpatch)) i(oldVnode, vnode)
}
}第四节·篇章小结
本篇研究src/core/vdom中的代码,介绍了:
①虚拟dom的定义。虚拟dom是指用JavaScript编写的伪dom。
②虚拟dom的优势。操作真实dom的开销很大,而使用虚拟dom,可以减少重排重绘,减少操作真实dom。基于性能优化的需求,选择了虚拟dom。
③虚拟dom的组成要素。虚拟dom的组成要素虚拟节点,分为组件节点、元素节点、函数组件节点、注释节点、文本节点、克隆节点,共6种。
④vue中的dom-diff过程,详细介绍了patch,patch过程干了三件事,分别是创建节点,删除节点,更新节点。
Vue源码解读:02变化侦测篇
目录
第一节·先看目录结构
本篇研究的代码位置:src/core/observer
├─observe # 实现变化观测的代码
├─array.js #实现数组类型数据变化观测的代码
├─dep.js #实现依赖管理器的代码
├─index.js #实现变化侦测的入口文件,以及实现object数据可观测的代码
├─scheduler.js #实现对watcher管理的调度代码
├─traverse.js #实现数据深层次观测的代码
├─watcher.js #实现为依赖项创建watcher实例,处理依赖收集与通知的代码第二节·变化侦测简述
observer,中文意为观察者,24中设计模式中有一种叫观察者模式,别名发布-订阅模式,我简单的联想到vue中实现变化侦测使用到了观察者模式。
变化侦测,在前端三大框架React,Angular,Vue中均有所体现,React是通过对比虚拟dom实现的,Angular是通过脏检查实现的。本文就是通过研究observer中的代码,学习Vue的变化侦测机制。
变化侦测简单理解就是对数据变化的观测。变化侦测只是一种手段,根据侦测结果去实现自己的目的才是重点。但这个手段,是实现数据驱动,实现数据双向绑定,实现数据响应式的关键之关键。
第三节·Vue中的变化侦测机制。
1.前言
实现变化侦测的关键思路就是进行数据劫持,数据劫持的目的也很明显,就是拦截重组重新包装数据,使数据变成可观测数据。这个可观测数据,要具备数据的读写操作可知,比如谁读写,什么时候读写,读写了什么这些特点。劫持的目的就是重包装,重包装的目的就是使数据的读写变得可知,实现可知的代码,就是重包装的要添加的内容。当数据的读写变得可知了,那么根据读写的变化内容,然后去主动通知视图更新,从而省去手动操作dom更新视图的工作,这就实现了操作dom变得自动化,这就是数据驱动了啊。数据驱动下实现根据数据变化主动更新视图,取代了手动操作dom更新视图,这是一个视图更新或说操作dom操作自动化的过程。而通过dom监听,根据dom变化情况,实现数据状态更新。这一来,所谓的数据双向绑定,数据响应式,就实现了啊。
变化侦测机制的应用成果包含了数据驱动的实现,数据响应式的实现等,前文也提及了变化侦测机制的重要性,这也是本文取名变化侦测篇的理由之一。
嗯,这都是文字,下来来看下vue2中的代码是如何实现变化侦测的。
2.object类数据的变化观测
①先看源码
//源码位置:src/core/observer/index.js
/**
* Observer class that is attached to each observed
* object. Once attached, the observer converts the target
* object's property keys into getter/setters that
* collect dependencies and dispatch updates.
*
* 附加后于每个观察对象的观察者类。
* 附加后,观察者将目标对象的属性键转换为getter/setter,
* 后者收集依赖项并分派更新。
*/
export class Observer {
value: any;
dep: Dep;
vmCount: number; // number of vms that have this object as root $data
constructor(value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {//使数组变得可观测的入口
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)
} else {//使非数组,即object数据变得可观测的入口
this.walk(value)//遍历object数据所有属性并将它们转换为getter/setter。
}
}
}②思路分析
从变化侦测的入口文件index.js,上面贴出的代码就可知,vue2中变化观测机制,将数据分为两类,一类是object,另一类是array数据。实现object数据可观测的主要代码就放在index.js文件中,而实现array的可观测主要代码则放在observer目录下的array.js文件中。
进入实现object数据可观测的主题,就实现而言并不难,vue中做的更多工作是更优雅的实现。它是通过Object.defineProperty()来实现的,defineProperty()是Object的一个方法,通过defineProperty()重新定义object数据,被重新定义之后的object数据就会带有get()和set(),并使用get()和set()对每一个属性的读写进行拦截,这里的拦截就是劫持,而劫持的目的,就是要在数据被读写的时候得到通知。这里有一个关键点,就是通过Object.defineProperty()重定义过后的数据,在该数据被读取时,必然会经过get(),而数据被修改时必然会经过set(),这是Object.defineProperty()带来的特性,也是选择使用defineProperty()进行数据劫持的原理,也是实现object数据可观测的关键。
使用defineProperty()重定义数据后,就实现了object数据的可观测。因为该数据被读写时,必然经过get()和set(),这样就知道了数据什么时候被读取了,什么时候被修改了。如此,数据就是可观测的数据了。看下源码是咋写的,因为代码太长,省略了许多代码。
// 源码位置:src/core/observer/index.js
/**
* Define a reactive property on an Object.
*
*将对象的属性定义为响应式(可观测)的。
*/
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
//...数据被读取时,你想要做的事
console.log('数据被读取了,我要记录下来');
return value
},
set: function reactiveSetter (newVal) {
//..数据被修改时,你想要做的事
console.log('数据被修改了,我要通知视图更新');
val = newVal
}
})
}③源码中实现object数据的关键路径
Observer 类中,调用walk()函数,walk()函数中调用defineReactive(),defineReactive函数中,使用Object.defineProperty()重定义数据,重定义之后的数据就是可观测数据,至此就实现object类型数据的可观测了。
④依赖机制
到了这里,我们知道通过Object.defineProperty(),我们可以实现数据的可观测。回过头来说,观测数据并不是我们的目标,我们的目标是通过数据观测,去做一些事情,例如实现数据驱动视图等。以驱动视图为例,当观测到某个数据变化了,要去更新视图,那么整个视图那么大,更新谁呢?怎么找对应关系,这里就引出了依赖机制。依赖表示访问数据的一方和数据本身的一种关系。在源码中专门有一个dep.js文件,就是放置依赖的文件。有了依赖记录,就可以知道数据和他的使用者们了,也就知道该通知谁更新了。
// 源码位置:src/core/observer/index.js
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
if (Dep.target) {
dep.depend()//为数据和其访问者,添加(生成)依赖
}
return value
},
set: function reactiveSetter (newVal) {
//...其他代码
dep.notify()//通知依赖更新
}
})从上面贴出的源码,可以知道,依赖是在get()被触发的时候产生的,因为访问数据必然经过get()。用一个词来表示依赖产生的过程,叫依赖收集。为每一个访问该数据的访问者,生成一个依赖,有了依赖记录,就可以知道都有谁访问了该数据。而一个数据是可以有多个访问者的,这就是一对多的关系了,为了更好地管理这些依赖,vue中创建了一个依赖管理器。
依赖收集是在get()中,而依赖更新则是在set(),此前说过可观测数据中,每一次数据的更改,都会经过set(),所以这是通知依赖更新的好时机,依赖接到更新通知后,进而通知依赖关系的使用方,比如视图。这样一步步就做到了数据变化,被观测到后通知到依赖,进而通知依赖关系方,该更新就更新了。
3.array的变化观测
object数据变化观测的实现利用了Object.defineProperty(),显然array数据是不支持这个的,defineProperty()是Object的方法。那么array数据如何观测数据呢?
在vue的开发中,我们把数据定义在data()函数里面,例如下面这样。
data(){
return{
arr:[]//在一个对象里面,定义一个数组
}
}也就是array数据的父级是object类型的数据,所以array也可以有一个对应的get(),那么array的依赖收集,也就可以取巧的和object类型的数据一样在get()中收集。有人可能会觉得那array也可以set()方法,我认为有是可以有的,但是没有意义啊。因为array数据的值改变和object是不一样的,从平时开发就知道了,我们操作数组通常是通过js提供的方法,例如push(),pop(),shift(),unshift(),splice(),sort(),reverse()等。array数据的值改变不再是必然经过set(),所以array数据的依赖更新通知,只能另寻途径。现在要求观测array数据的值改变,而array数据的值改变,我们通常是通过调用js提供的操作数据的方法进行的,那么有了,重写这些个操作数组的方法。看下源码,vue中就是通过重写可操作数组的且改变数组自身的几个方法实现的变化观测。瞅一下源码。
// 源码位置 src/core/observer/array.js
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
/**
* Intercept mutating methods and emit events
*
* 拦截重写后的方法并触发事件(事件就是更新依赖)
*/
methodsToPatch.forEach(function (method) {
// cache original method
// 缓存拷贝原来的方法,使重写后的方法具备原来的功能
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// notify change
// 通知依赖更新
ob.dep.notify()
return result
})
})所以,在vue中,array数据值变化的观测,是通过重写会改变数组自身的7个方法实现的。array的依赖更新即是在这时候。
4.深度观测
什么是深度侦测。通过实际开发经验,我们只知道,不仅数据本身的改变会被观测到,数据嵌套的子元素也是可观测的,也是响应式的。实现数据嵌套的深层次元素的可观测,就是深度侦测了。
/**
* Observer class that is attached to each observed
* object. Once attached, the observer converts the target
* object's property keys into getter/setters that
* collect dependencies and dispatch updates.
*
* 附加后于每个观察对象的观察者类。
* 附加后,观察者将目标对象的属性键转换为getter/setter,
* 后者收集依赖项并分派更新。
*/
export class Observer {
value: any;
dep: Dep;
vmCount: number; // number of vms that have this object as root $data
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {//使数组变得可观测的入口
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)//实现数组可观测的方法
} else {//使非数组,即object数据变得可观测的入口
this.walk(value)//遍历object数据所有属性并将它们转换为getter/setter。
}
}
/**
* Observe a list of Array items.
*
* 观测数组的子项列表。
* 遍历数组,将数组元素通过observe()转换为响应式可观测的
*/
observeArray (items: Array) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}
/**
* Define a reactive property on an Object.
*
*将对象的属性定义为响应式(可观测)的。
*/
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
const dep = new Dep()//创建一个依赖管理器实例
const property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
const getter = property && property.get
const setter = property && property.set
if ((!getter || setter) && arguments.length === 2) {
val = obj[key]
}
let childOb = !shallow && observe(val)//
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
if (Dep.target) {
dep.depend()
if (childOb) {
childOb.dep.depend()
if (Array.isArray(value)) {
dependArray(value)
}
}
}
return value
},
set: function reactiveSetter (newVal) {
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
// #7981: for accessor properties without setter
if (getter && !setter) return
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = !shallow && observe(newVal)
dep.notify()
}
})
}
/**
* Attempt to create an observer instance for a value,
* returns the new observer if successfully observed,
* or the existing observer if the value already has one.
*
* 尝试为一个值创建一个观察者实例,如果成功观察到,
* 则返回新的观察者,如果该值已经存在,则返回现有的观察者。
*/
export function observe (value: any, asRootData: ?boolean): Observer | void {
if (!isObject(value) || value instanceof VNode) {
return
}
let ob: Observer | void
if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) {
ob = value.__ob__
} else if (
shouldObserve &&
!isServerRendering() &&
(Array.isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue
) {
ob = new Observer(value)
}
if (asRootData && ob) {
ob.vmCount++
}
return ob
} 从上面的源码可以看到,源码中是通过observeArray ()遍历数组,observeArray ()内部调用observe()函数,observe函数返回一个观察者实例。简单地说array数据是通过observeArray ()遍历数组,实现的深度观测。
而object的深层次递归路径:Observer类调用walk()方法,walk()方法内部调用defineReactive()方法,defineReactive()方法内部,调用observe()函数,observe()函数内部new Observer(value)实例。有一点绕,简单那说就是通过递归实现的object类数据的深层次可观测。
5.了解一下Watcher
前面说到数据变成可观测数据之后,当数据变化之后,就会通知视图更新,而通过依赖我们可以知道具体上该通知谁,实际上真正通知视图的是watcher实例。在源码中,依赖管理器会为每一个依赖创建一个对应的watcher实例,或者说watcher实例是依赖的一部分,而watcher则代表依赖去做一些工作,例如调用update()方法去通知视图更新。
/**
* A dep is an observable that can have multiple
* directives subscribing to it.
*
* dep是一个可观察的,支持多个指令订阅它的对象。
*/
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array;
constructor () {
this.id = uid++
this.subs = []
}
addSub (sub: Watcher) {//依赖管理器中,添加Watcher实例的方法
this.subs.push(sub)
}
//...省略其他代码
//通知函数
notify () {
// stabilize the subscriber list first
const subs = this.subs.slice()
if (process.env.NODE_ENV !== 'production' && !config.async) {
// subs aren't sorted in scheduler if not running async
// we need to sort them now to make sure they fire in correct
// order
subs.sort((a, b) => a.id - b.id)
}
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update()//subs[i]即是依赖对应的watcher实例,它调用update方法去通知视图更新
}
}
} 6.Vue.set和Vue.delete
到这里,我们知道了,object数据通过Object.defineProperty,array数据通过拦截重写可改变自身的7个操作方法,可以实现数据的可观测。但是这个可观测是有缺点的,比如array数据,要是通过下标操作数组,或通过修改数组长度清空数组,是无法观测到数据变化的。通过Object.defineProperty()实现的object数据观测原理,只有当访问数据和设置值才能会被观测到,像给数据新增一对key/value的属性,或删除一对已有的key/value的属性,是无法被观测的。显然,vue也意识到这点,提供了两个全局API的方法,vue.set和vue.delete来解决新增和删除带来的数据变化无法被观测的问题。至于用法,这里不就不说了,不了解可以去官网看。原理嘛,在后面的篇章会说的。
第四节·篇章小结
综上,我们知道了:
①object类型数据实现数据可观测,是通过Object的defineProperty()实现的。
②array类型数据实现数据可观测,是通过拦截重写数据的7个可操作数组且会改变数组自身的方法实现的。
③依赖是一种表示数据和其使用者的关系,依赖管理器会为每一个依赖创建watcher实例。
④数据变化被观测到后,会通过代表依赖的watcher实例,调用update()方法,通知视图更新。
⑤vue提供了set和delete两个全局API,弥补部分新增和删除数据手法,无法被观测,进而影响数据响应式实现的不足。
Vue源码解读:01核心思想篇
目录

第一节·数据驱动
1.什么是数据驱动?
数据驱动是vuejs的核心思想之一,有人称其为vuejs最大的特点。所谓数据驱动就是指数据状态变化时,自主得去更新与其有依赖的视图。数据驱动的关键在于驱动,这里的驱动是自主的,生活中有一个词叫做自动化,我简单的认为数据驱动思想,是自动化思想在前端编程自动化上的一种应用,数据驱动是将对dom的手动操作,自动化了,它根据数据状态的变化,自动更新操作视图。使用过jQuery的同学应该有体会,数据驱动带来的“自动化”,其实省去了许多操作dom的工作,维护也更加方便。
我对数据驱动的定义,简单总结为以下三点:
①数据驱动是指根据数据状态变化,自主更新视图。
②数据驱动是自动化思想,在前端编程自动化上的应用。
③数据驱动使得操作dom,从手动操作,变成了自动操作,是一种自动化表现。
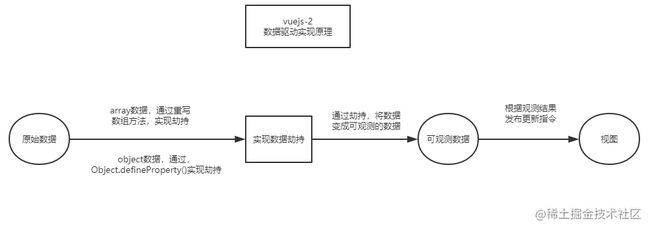
2.数据驱动的工作原理
通过源码,我们可以看到,vuejs核心(core)源码下,就6个文件夹,其中一个叫observer,这里面放置的就是实现数据驱动的主要代码,从文件夹名字,我们就可以大概猜测,它是通过观察者模式(发布-订阅模式)结合数据劫持实现的。在vue中2中实现数据劫持的方法主要是通过Object.defineProperty()将object类型的数据转变成可观测的数据,Object.defineProperty()对数组类型的数据操作是无效的,在vue2中是通过重写操作数组的7个方法实现的数据变化观测。据了解,vue3使用了新的办法实现数据劫持,它就是es5的proxy对象。
将数据变成可观测之后,那么我们就知道了数据什么时候会被读取,值什么时候发什么改变,然后此时,根据数据的变化情况,更新视图,这样就达到了数据驱动的效果。关于observer的内容后面会专门用变化侦测篇来详细记录。
第二节·组件化系统
1.什么是组件化?
vue组件是一种拓展HTML元素,将要展示的内容分成相对独立的拓展HTML元素,即分成不同组件的过程,或在设计构建视图的编码时,将相对独立的可视区域,以独立组件的形式构建的过程,就是组件化。
2.组件化的优点。
每一个组件,可以对一个viewModel(简写vm,可以是vue实例)。视图页面是组件的容器,组件化之后,我们可以任意根据需求自由嵌套组合组件,最后形成一个个完整页面。组件具有高内聚低耦合的特性,那么复用性更好,维护成本更低,提高开发效率,这些优点就呼之欲出了。
3.vue实现组件注册的原理:暂略。
4.vue中如何注册使用组件:使用搜索引擎吧。
Vue源码解读:前言篇
1.说明
①受限学识水平和实践经验,难免错漏,欢迎各位前辈同学批评指正。
②本系列文章仅从源码角度进行学习,不作 vue 基本使用和api的解释,相关需要可阅读官网。
③本系列(Vue源码剖析笔记),目前共6篇即01核心思想篇,02变化侦测篇(响应式篇)、03虚拟dom篇、04模板编译篇、05生命周期篇、06vue3探索篇,主要基于vue2.6和vue3.2版本源码库分析,共约2万字。
④本系列文章的学习目的:
a.学习如何更好的设计代码以及搭建架构。
b.深入了解vue。
2.参考资料
①阮一峰老师系列分享资料
②Vue2源码
Vue3源码
③Vue官网
Vue3官网
④Vue2Api
composition-api
⑤书籍:梁灏老师的Vue.js实战
3.总目录
4.结束语
致敬每一个开源人,热爱分享的开发者。