第三周:序列模型和注意力机制
第三周:序列模型和注意力机制
- 3.1 基础模型
-
- Sequence to sequence model
- Image Captioning
- 3.2 选择最可能的句子
-
- 语言模型和机器翻译的比较:
- 3.3 束搜索(Beam Search)
-
- 例子:
- 3.4 改进Beam Search
-
- Length Normalization
- 怎么选择Beam width B?
- 3.5 束搜索的误差分析
-
- 例子
- 解决方法:
-
- Case 1: P ( y ∗ ∣ x ) > P ( y ^ ∣ x ) \mathbb{P}(y^*|x)>\mathbb{P}(\hat{y}|x) P(y∗∣x)>P(y^∣x)
- Case 1: P ( y ∗ ∣ x ) < P ( y ^ ∣ x ) \mathbb{P}(y^*|x)<\mathbb{P}(\hat{y}|x) P(y∗∣x)<P(y^∣x)
- 具体操作:
- 3.6 Bleu得分(Bilingual Evaluation Understudy)
-
- 例子:
- 一般的公式:
- Combined Bleu score 和 BP Penalty
- 3.7 注意力模型(直观理解)
-
- 例子
- 3.8 注意力模型(细节)
-
- 计算注意力权重 α t , t ′ \alpha^{t,t'} αt,t′
- 3.9 语音辨识
-
- 方法一:注意力模型
- CTC cost
- 3.10 触发字符(Trigger words)
-
- Trigger word detection algorithm
- 3.11 结论与致谢
- 第三周测试重点:
- 课程中的论文
-
- Sequence to sequence model
- Image Captioning
- Bleu Score
- Attention Model
- CTC
本文是序列模型的笔记
3.1 基础模型
Sequence to sequence model
以法语翻译成为中文为例:(encoder-decoder)

Image Captioning
CNN(AlexNet)+decoder

3.2 选择最可能的句子
语言模型和机器翻译的比较:

Rq:
- 我们注意到语言模型和机器翻译具有很大的相似性,实际上机器翻译就是把一开始随机化的向量 a < 0 > a^{<0>} a<0>改成了一个有Encoder模型得到的向量。
- 此外,我们回顾一下语言模型(或者说Decoder)的运作原理,我们是每一次是通过SoftMax预测的 y < t > y^{
} y<t>分布里面按照概率 P ( y < t > ∣ y < 1 > , … , y < t − 1 > ) \mathbb{P}(y^{}|y^{<1>},\dots,y^{ P(y<t>∣y<1>,…,y<t−1>)随机提取一个词,从而实现连词成句的。但是对于机器翻译问题我们不希望每一次的结果都是随机的,而是希望得到一个最大概率的翻译:})
a r g m a x y < 1 > , … , y < T y > P ( y < 1 > , … , y < T y > ∣ x ) argmax_{y^{<1>},\dots,y^{}} \mathbb{P}(y^{<1>},\dots,y^{ argmaxy<1>,…,y<Ty>P(y<1>,…,y<Ty>∣x)}|x)
这里x为decoder网络得到的特征向量。注意,如果这里用Greedy Search,这里有一个条件概率的问题,所以不是每次取最大值乘起来还是最大值。Sol: beam search(束搜索)
3.3 束搜索(Beam Search)
感觉是对Greedy Search的推广。当B=1其实就是Greedy Search。
- 参数:Beam width B B B,每一步中我们保留最大的B个词语,可以对应同一个词语。
例子:

Rq:
- y < 2 > = P ( y < 2 > ∣ x , y < 1 > ) = P ( y < 1 > , y < 2 > ∣ x ) P ( y < 1 > ∣ x ) y^{<2>} = \mathbb{P}(y^{<2>}|x,y^{<1>}) =\frac{\mathbb{P}(y^{<1>},y^{<2>}|x)}{\mathbb{P}(y^{<1>}|x)} y<2>=P(y<2>∣x,y<1>)=P(y<1>∣x)P(y<1>,y<2>∣x)
3.4 改进Beam Search
Length Normalization
如果有归一化,则我们引入了一个超参数 α \alpha α
- Recap:
我们的目的是 a r g m a x y Π t = 1 T y P ( y < t > ∣ x , y < 1 > , … , y < t − 1 > ) argmax_y \Pi_{t=1}^{T_y} \mathbb{P}(y^{} | x,y^{<1>},\dots,y^{ argmaxyΠt=1TyP(y<t>∣x,y<1>,…,y<t−1>),即寻找一个序列 [ y < t > ] t ∈ [ 1 , T y ] [y^{}) }]_{t\in[1,T_y]} [y<t>]t∈[1,Ty]使得 P ( y < 1 > , … , y < t > ) \mathbb{P}(y^{<1>},\dots,y^{}) P(y<1>,…,y<t>)最大。
如果直接计算会有数值下溢的问题,因为数值太小了。所以如果用这个模型来训练的话,往往会得到较为简短的结果。 - Sol:(使用log函数)
因为log函数单调,所以我们可以考虑这个问题的等价命题:
a r g m a x y ∑ t = 1 T y l o g ( P ( y < t > ∣ x , y < 1 > , … , y < t − 1 > ) ) argmax_y \sum_{t=1}^{T_y} log(\mathbb{P}(y^{} | x,y^{<1>},\dots,y^{ argmaxyt=1∑Tylog(P(y<t>∣x,y<1>,…,y<t−1>))}))
或者我们可以引入归一化Normalization,使得对一些长一点的翻译比较友好一点。(因为我们的目的是最大化这个值,又因为<1的数越乘越小,所以会倾向于选择长度更短的结果。)
1 T y α a r g m a x y ∑ t = 1 T y l o g ( P ( y < t > ∣ x , y < 1 > , … , y < t − 1 > ) ) \frac{1}{T_y^\alpha}argmax_y \sum_{t=1}^{T_y} log(\mathbb{P}(y^{} | x,y^{<1>},\dots,y^{ Tyα1argmaxyt=1∑Tylog(P(y<t>∣x,y<1>,…,y<t−1>))}))
一般来说 α = 0.7 \alpha = 0.7 α=0.7
怎么选择Beam width B?
- B大一点:
- 计算速度慢,内存消耗大,但结果可能变好。
- 一般来说在产品中B=10,在论文里B=1000
Rq:
BFS和DFS都是精确搜索最值的算法,而Beam Search是一种近似搜索最值的方法。
3.5 束搜索的误差分析
判断一个错误结果的错误原因是来自RNN还是Beam Search
例子
原文:Jane visite l’Afrique en septembre.
人工:Jane visit Africa in September. y ∗ y^* y∗
算法:Jane visit Africa last September. y ^ \hat{y} y^
解决方法:
我们可以通过比较 P ( y ∗ ∣ x ) \mathbb{P}(y^*|x) P(y∗∣x)和 P ( y ^ ∣ x ) \mathbb{P}(\hat{y}|x) P(y^∣x)来判断。
Case 1: P ( y ∗ ∣ x ) > P ( y ^ ∣ x ) \mathbb{P}(y^*|x)>\mathbb{P}(\hat{y}|x) P(y∗∣x)>P(y^∣x)
此时,因为我们希望得到的是最大值,而Beam Search得到的结果比较小。所以这里可能的原因在于Beam width B B B比较小。
Case 1: P ( y ∗ ∣ x ) < P ( y ^ ∣ x ) \mathbb{P}(y^*|x)<\mathbb{P}(\hat{y}|x) P(y∗∣x)<P(y^∣x)
原因在:RNN
具体操作:
- 使用训练好的Encoder + Decoder对 y ∗ y^* y∗和 y ^ \hat{y} y^进行输出
- 统计所有出现错误较大的结果,根据不同的Case,判断是RNN导致的错误率比较高还是Beam Search 参数比较小导致的错误比较多。从而作出相应的修改。
3.6 Bleu得分(Bilingual Evaluation Understudy)
目的:在很多翻译结果一样好的情况下评估一个机器翻译系统。
名字来源于希望能成为人工评价翻译结果的候补(Understudy)
大致想法,只要这个翻译结果和某一个人工翻译结果相似,就可以得到一个比较高的Bleu得分。
例子:
French: Le chat est sur le tapis.
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
MT output: the the the the the the the.
-
看单个元素(Unigrams):
原始的Precision:(看看机器翻译MT的每一个词是否在Reference里面。)这里因为the在Reference 里面所以为 7 7 = 1 \frac{7}{7}=1 77=1
改过的Precision:(在Reference中出现的次数最大值) C l i p p e d C o u n t C o u n t = m a x ( 2 , 1 ) 7 = 2 7 \frac{Clipped Count}{Count}=\frac{max(2,1)}{7}=\frac{2}{7} CountClippedCount=7max(2,1)=72 -
看MT output里面相邻的两个单词(二元词组,Bigrams)
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
MT output: The cat the cat on the mat.
| Bigrams | Count | CountClip |
|---|---|---|
| the cat | 2 | 1 |
| cat the | 1 | 0 |
| cat on | 1 | 1 |
| on the | 1 | 1 |
| the mat | 1 | 1 |
Precision: 4 6 \frac{4}{6} 64
一般的公式:
对于n-grams:
p n = ∑ n g r a m ∈ y ^ c o u n t c l i p ( n g r a m ) ∑ n g r a m ∈ y ^ c o u n t ( n g r a m ) p_n=\frac{\sum_{ngram\in \hat{y}}count_{clip}(ngram)}{\sum_{ngram\in \hat{y}}count(ngram)} pn=∑ngram∈y^count(ngram)∑ngram∈y^countclip(ngram)
其中 y ^ \hat{y} y^是所有n-grams构成的集合, c o u n t ( n g r a m ) count(ngram) count(ngram)是这个ngram在MT output中出现的次数, c o u n t c l i p ( n g r a m ) = m a x r ∈ R e f e r e n c e ( c o u n t ( n g r a m , r ) ) count_{clip}(ngram) = max_{r\in Reference}(count(ngram,r)) countclip(ngram)=maxr∈Reference(count(ngram,r))是ngram在每一个Reference中的最大值。
Combined Bleu score 和 BP Penalty
保证了输出的长度不会太短。
Combined Bleu score:(对1-grams到4-grams的综合考虑)
B P ∗ e 1 4 ∑ n = 1 4 p n BP*e^{\frac{1}{4}\sum_{n=1}^4p_n} BP∗e41∑n=14pn
B P = { 1 if MT_output_length > reference_output_length e x p ( 1 − M T o u t p u t l e n g t h / r e f e r e n c e o u t p u t l e n g t h ) otherwise BP=\begin{cases} 1 & \text{ if MT\_output\_length > reference\_output\_length} \\ exp(1-MT_output_length/reference_output_length) & \text{ otherwise } \end{cases} BP={1exp(1−MToutputlength/referenceoutputlength) if MT_output_length > reference_output_length otherwise
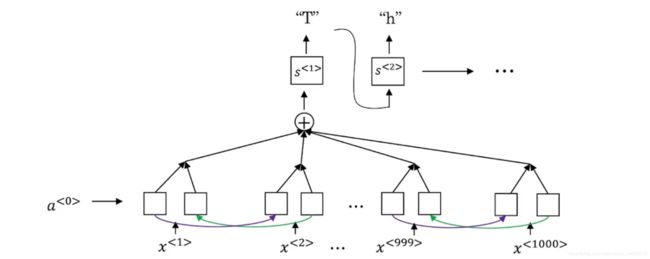
3.7 注意力模型(直观理解)
人工翻译是一部分一部分的翻译。
我们发现句子长度在20词左右翻译效果比较好,但是对于长句翻译的表现不太好。而如果我们使用了注意力模式,将改变模型在长句的表现。
例子
- 使用了BRNN(用作"encoder"),并给每一个输出一定的权重。
- 对于Decoder我们还是用RNN,跟之前的区别在于,我们不是用encoder把整个句子读完之后得到一个向量再输入到decoder里面,而是让一个输出 y < t > y^{
} y<t>只跟有限个输入有关。 - 为了避免弄混,我们对于decoder的记号为S
【图片】
3.8 注意力模型(细节)
我感觉通过查看注意力权重 α t , t ′ \alpha^{t,t'} αt,t′的最大值我们可以建立一个翻译字典。
- 记号:
- 法语句子里面用 t ′ t' t′。
- Context c c c: c < t > = ∑ t ′ α < t , t ′ > a t ′ c^{
}=\sum_{t'} \alpha^{ c<t>=∑t′α<t,t′>at′ - α < t , t ′ > \alpha^{
} y<t>应该给予“原文” a < t ′ > = ( a → < t ′ > , a ← < t ′ > ) a^{- 它应该满足权重之和为1: ∑ t ′ α < t , t ′ > a < t ′ > = 1 \sum_{t'} \alpha^{
- α < t , t ′ > = e x p ( e < t , t ′ > ) ∑ t ′ = 1 T x e x p ( e < t , t ′ > ) \alpha^{
- 它应该满足权重之和为1: ∑ t ′ α < t , t ′ > a < t ′ > = 1 \sum_{t'} \alpha^{
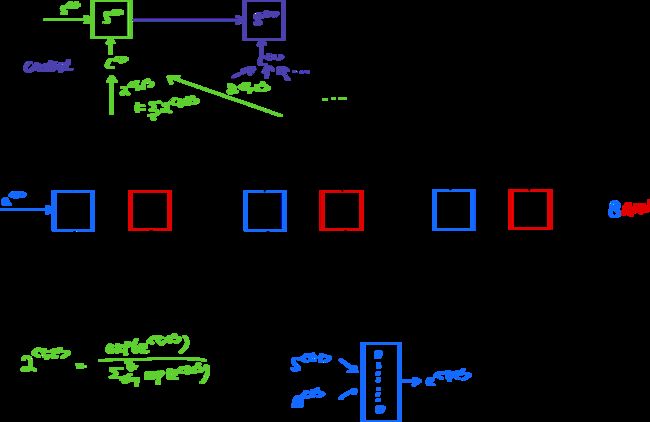
计算注意力权重 α t , t ′ \alpha^{t,t'} αt,t′
训练一个很小的神经网络用来计算 e < t , t ′ > e^{
因为我们认为 α < t , t ′ > \alpha^{
缺点:
- 算法复杂度为 ∼ N 3 \sim N^3 ∼N3
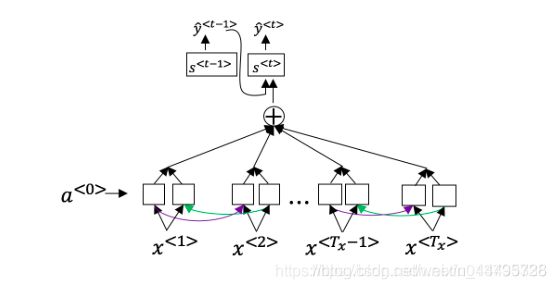
3.9 语音辨识
预处理:Spectrogram
以前使用phonemes(音素)。
方法一:注意力模型
CTC cost
Baidu
- CTC:Connectionist temporal classification

采用与音频信号一对一的模式,将每一小段音频对应到一个字符上。并引入两类字符"Blank"和"Space"。
其中我们会把两个Blank中间的相同字符给合并,所以上面的输出为“the q”。
3.10 触发字符(Trigger words)

Trigger word detection algorithm
目前还在发展
一个思路是在每个Trigger words说完之后输出1,否则输出0。但这样有一个问题是0的数量比1多太多了。
3.11 结论与致谢
Deep Learning is a super power.

第三周测试重点:
- 注意力机制❓❓❓
课程中的论文
Sequence to sequence model
Sequence to sequence learning with neural networks
Learning phrase representations using RNN encoder-decoder for statistical machine translation
Image Captioning
Deep captioning with multimodal recurrent neural networks
Show and tell: Neural image caption generator
Deep visual-semantic alignments for generating image descriptions
Bleu Score
A method for automatic evaluation of machine translation
Attention Model
Neural machine translation by jointly learning to align and translate
Show, attend and tell: Neural image caption generation with visual attention
CTC
Connectionist Temporal Classification: Labeling unsegmented sequence data with recurrent neural networks