操作系统底层工作原理
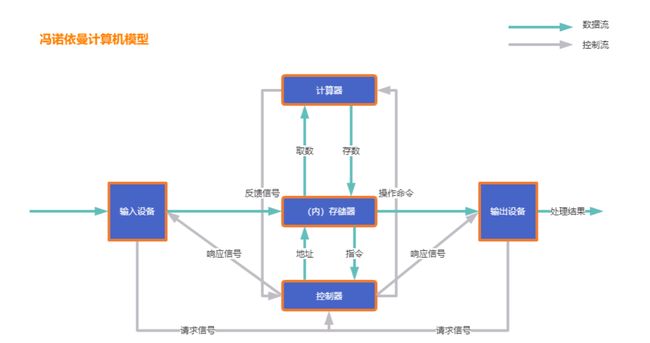
冯诺依曼计算机模型
名词解释
1.控制器(Control):是整个计算机的中枢神经,其功能是对程序规定的控制信息进行解释,根据其要求进行控制,调度程序、数据、地址,协调计算机各部分工作及内存与外设的访问等。
2.运算器(Datapath):运算器的功能是对数据进行各种算术运算和逻辑运算,即对数据进行加工处理。
3.存储器(Memory):存储器的功能是存储程序、数据和各种信号、命令等信息,并在需要时提供这些信息。
4.输入(Inputsystem):输入设备是计算机的重要组成部分,输入设备与输出设备合你为外部设备,简称外设,输入设备的作用是将程序、原始数据、文字、字符、控制命令或现场采集的数据等信息输入到计算机。常见的输入设备有键盘、鼠标器、光电输入机、磁带机、磁盘机、光盘机等。
5.输出(Output system):把计算机的中间结果或最后结果、机内的各种数据符号及文字或各种控制信号等信息输出出来。微机常用的输出设备有显示终端CRT、打印机、激光印字机、绘图仪及磁带、光盘机等。
硬件结构

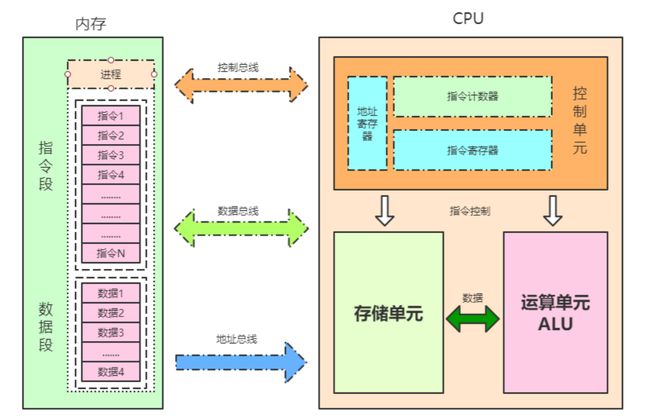
CPU内部结构
名词解释
控制单元:
是整个CPU的指挥控制中心,由指令寄存器IR(InstructionRegister)、指令译码器ID(InstructionDecoder)和操作控制器OC(OperationController)等组成,对协调整个电脑有序工作极为重要。它根据用户预先编好的程序,依次从存储器中取出各条指令,放在指令寄存器IR中,通过指令译码(分析)确定应该进行什么操作,然后通过操作控制器OC,按确定的时序,向相应的部件发出微操作控制信号。操作控制器OC中主要包括:节拍脉冲发生器、控制矩阵、时钟脉冲发生器、复位电路和启停电路等控制逻辑。
运算单元:
是运算器的核心。可以执行算术运算(包括加减乘数等基本运算及其附加运算)和逻辑运算(包括移位、逻辑测试或两个值比较)。相对控制单元而言,运算器接受控制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来指挥的,所以它是执行部件。
存储单元:
包括CPU片内缓存Cache和寄存器组,是CPU中暂时存放数据的地方,里面保存着那些等待处理的数据,或已经处理过的数据,CPU访问寄存器所用的时间要比访问内存的时间短。寄存器是CPU内部的元件,寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快。采用寄存器,可以减少CPU访问内存的次数,从而提高了CPU的工作速度。寄存器组可分为专用寄存器和通用寄存器。专用寄存器的作用是固定的,分别寄存相应的数据;而通用寄存器用途广泛并可由程序员规定其用途。
内存管理

内存分段

分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量
● 段选择因子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
● 虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
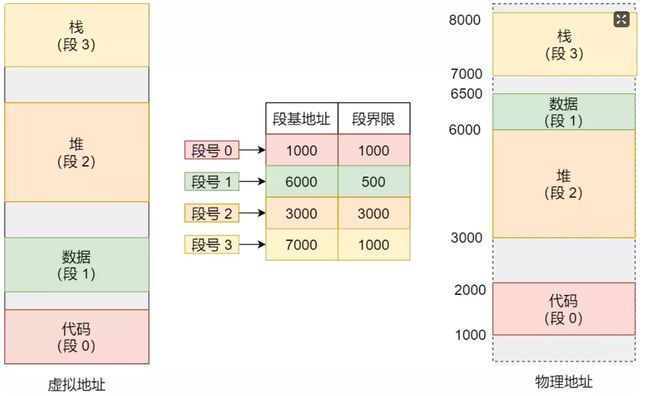
虚拟地址是通过段表与物理地址进行映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址
如果要访问段 3 中偏移量 500 的虚拟地址,我们可以计算出物理地址为,段 3 基地址 7000 + 偏移量 500 = 7500
内存分段不足之处

● 内存碎片的问题
● 内存交换的效率低的问题
我们可以把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。不过读回来的时候,我们不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的 512MB 内存后面。这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。
内存分页

分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页,在 Linux 下,每一页的大小为 4KB,虚拟地址与物理地址之间通过页表来映射
页表实际上存储在 CPU 的内存管理单元 (MMU) 中,于是 CPU 就可以直接通过 MMU,找出要实际要访问的物理内存地址。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行
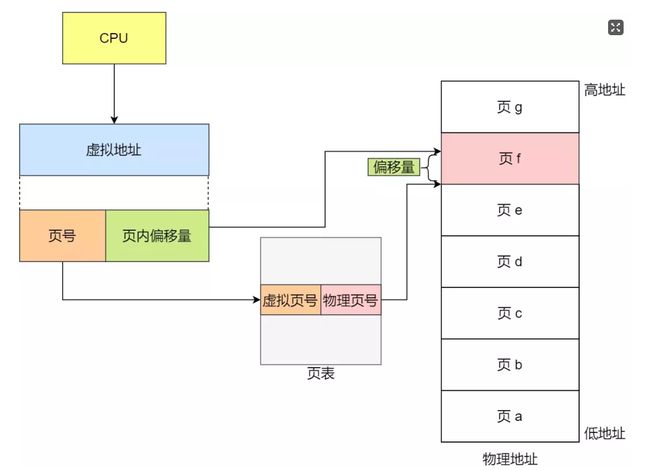
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址
内存地址转换
● 把虚拟内存地址,切分成页号和偏移量;
● 根据页号,从页表里面,查询对应的物理页号;
● 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
分页怎么解决分段的内存碎片、内存交换效率低的问题

由于内存空间都是预先划分好的,也就不会像分段会产生间隙非常小的内存,这正是分段会产生内存碎片的原因。而采用了分页,那么释放的内存都是以页为单位释放的,也就不会产生无法给进程使用的小内存。
如果内存空间不够,操作系统会把其他正在运行的进程中的「最近没被使用」的内存页面给释放掉,也就是暂时写在硬盘上,称为换出(Swap Out)。一旦需要的时候,再加载进来,称为换入(Swap In)。所以,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。
分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去
分页有什么缺陷呢?
因为操作系统是可以同时运行非常多的进程的,那这不就意味着页表会非常的庞大。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
多级页表

我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个表(二级页表)中包含 1024 个「页表项」,形成二级分页。
从页表的性质来看,保存在内存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部虚拟地址空间,不分级的页表就需要有 100 多万个页表项来映射,而二级分页则只需要 1024 个页表项(此时一级页表覆盖到了全部虚拟地址空间,二级页表在需要时创建)
内存管理

操作系统有用户空间与内核空间两个概念,目的也是为了做到程序运行安全隔离与稳定
从0x00000000到0xc0000000(PAGE_OFFSET)的线性地址可由用户代码和内核代码进行引用(即用户空间)。从0xc0000000(PAGE_OFFSET)到0xFFFFFFFFF的线性地址只能由内核代码进行访问(即内核空间)
进程与线程只能运行在用户方式(usermode)或内核方式(kernelmode)下。用户程序运行在用户方式下,而系统调用运行在内核方式下。在这两种方式下所用的堆栈不一样:用户方式下用的是一般的堆栈(用户空间的堆栈),而内核方式下用的是固定大小的堆栈(内核空间的对战,一般为一个内存页的大小),即每个进程与线程其实有两个堆栈,分别运行与用户态与内核态
KLT

CPU调度的基本单位线程,也划分为:
1、内核线程模型(KLT)
2、用户线程模型(ULT)
内核线程(KLT):系统内核管理线程(KLT),内核保存线程的状态和上下文信息,线程阻塞不会引起进程阻塞。在多处理器系统上,多线程在多处理器上并行运行。线程的创建、调度和管理由内核完成,效率比ULT要慢,比进程操作快。
ULT

用户线程(ULT):用户程序实现,不依赖操作系统核心,应用提供创建、同步、调度和管理线程的函数来控制用户线程。不需要用户态/内核态切换,速度快。内核对ULT无感知,线程阻塞则进程(包括它的所有线程)阻塞
jvm是采用的哪一种线程模型? 评论区告诉我哦!