分布式数据库高可用方案对比与分析
高可用是数据库系统的基本需求,也是数据库技术实现的难点之一。
高可用不仅要求数据库在正常的场景下不间断的提供稳定服务,而且需要能够在出现故障的情况下快速恢复并迅速提供服务,使用户难以感知到异常,保证业务的连续性。
作为一款云原生分布式数据仓库,HashData在传统架构的MPP数据库基础上,对存储层、计算层、元数据等多方面进行了改进和优化,进一步提升系统的可用性。相比传统MPP架构的数据库,HashData能够提供接近“零停机”的服务,大幅降低数据库运维成本。
数据高可用
传统架构的MPP数据库,计算和存储是紧耦合的,用户数据和元数据都存储在本地磁盘。
当系统出现故障时,传统架构的MPP数据库主要采用多个副本的方式,来保证系统的可用性。为确保数据库在异常运行过程中能及时从主节点切换到备节点,传统架构的MPP数据库会通过WAL replication的方式,将xlog从主节点复制到备用节点。
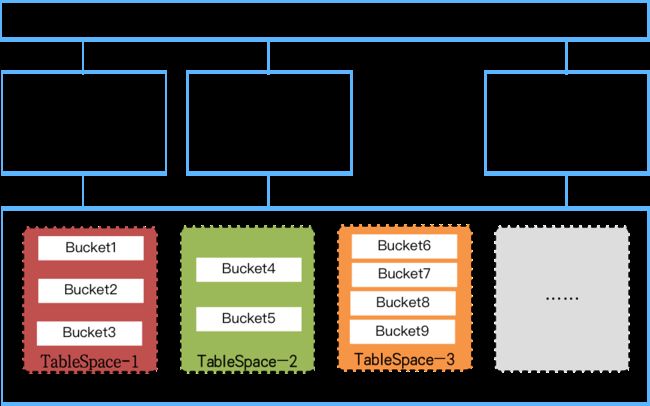 HashData云原生数据库采用“存算分离”的架构,架构上分为三个层次,依次是元数据服务层、计算层以及数据存储层,每层之间完全解耦。持久化数据由数据存储层提供,中间的计算层则实现了完全无状态化,并且能够独立地扩容,很大程度上解决了传统MPP架构的许多局限。
HashData云原生数据库采用“存算分离”的架构,架构上分为三个层次,依次是元数据服务层、计算层以及数据存储层,每层之间完全解耦。持久化数据由数据存储层提供,中间的计算层则实现了完全无状态化,并且能够独立地扩容,很大程度上解决了传统MPP架构的许多局限。
HashData的共享存储层采用对象存储技术,用于保存表数据、临时数据等各类用户数据和结果数据,供所有计算集群访问。借助对象存储,HashData可以提供近乎无限扩展能力,同时通过混合存储、压缩算法、Bucket等多种优化技术,实现共享存储IO能力隔离和流量控制,保证了数据的高效访问。
为提高访问性能,HashData在共享存储上,数据分片保存在不同的文件,供计算集群各节点并行访问。分片数量在元数据集群创建时设定,一般按照计算集群最大规模设定数据分片数量(2的幂次方),将每张表的数据按照Hash或random算法均匀分布到不同数据分片存储。
得益于存算分离的架构,HashData通过一致性哈希算法,将每个计算节点对应一个或多个数据分片,计算节点均匀存储(缓存)、计算对应数据分片,避免了数据重新逻辑分组和重新物理分布,可以实现集群的秒级自动扩缩容。
应用高可用
数据高可用并不意味着应用高可用,因为数据高可用只是确保数据不会丢失,但是能否对外提供数据库服务则是另一个问题。
传统架构的MPP数据库在运行时,通常会引入监控机制或者故障检测机制。当发现系统发生故障时,需要立即进行主从切换。
切换的方式一般有两种:一种是手动切换,需要DBA的参与,反应时间上无法得到保障。
另一个方案是自动切换,由程序去监控数据库的健康状态,在检测到故障之后,程序自动执行切换。
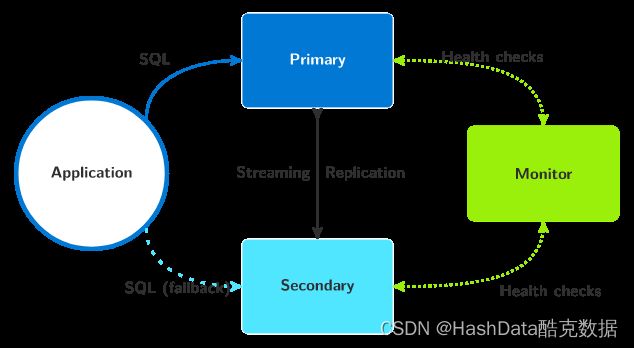 如上图所示,目前较为常见方式是在主节点和备节点之外建立 monitor 节点。当monitor 节点检测到 primary 发生故障后,就会把Secondary节点切换成主节点。
如上图所示,目前较为常见方式是在主节点和备节点之外建立 monitor 节点。当monitor 节点检测到 primary 发生故障后,就会把Secondary节点切换成主节点。
这样做的代价是,首先要确保 monitor 节点本身的高可用。其次,备节点切换成主节点后,部署该节点的机器上可能会有多个主节点在同时运行,对系统性能造成影响。
同时,新节点的数据恢复时间一般比较长,运维压力相对较大。另外,如果一个数据节点只有一个从/备节点,当发生主从/备切换后,该节点处于单点状态,不再具备高可用性。如若在发生故障后仍然要求系统保持高可用,还必须引入新的从/备节点。
与传统架构的MPP数据库相比,HashData云数仓可以物理主机部署或者云环境部署,无论是哪种部署方式,都可以实现故障自愈的高可用。
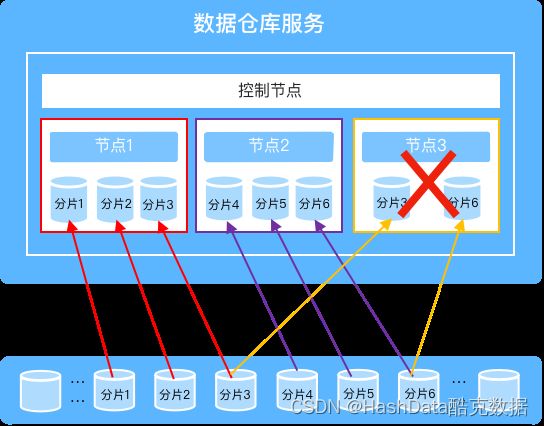 为解决数据同步的问题,HashData云数仓将数据存储在共享存储内,计算节点与数据块的对应关系可以实现动态调整,不涉及到数据的搬迁,也不存在备用节点,因而能够实现分钟级新节点恢复,整个过程不需要任何的人工干预。
为解决数据同步的问题,HashData云数仓将数据存储在共享存储内,计算节点与数据块的对应关系可以实现动态调整,不涉及到数据的搬迁,也不存在备用节点,因而能够实现分钟级新节点恢复,整个过程不需要任何的人工干预。
面对企业与日俱增的数据应用和管理需求,HashData提供了管理组件Cloudmanager,通过对各类云平台资源的统一管理,整合数据库集群的监控、运维、管理等功能,建立统一的数字化管理运维平台,实现图形化、自动化操作,达到“所见即所得”的效果,极大地降低了数据仓库集群的运维管理成本。
不同于开源数据库监控管理工具,Cloudmanager 既可以提供数据库的基础管理监控,同时又能实现对数据库集群节点的弹性扩容、缩容,增强集群的计算能力与可用性。
元数据高可用
传统MPP架构数据库用户数据和元数据是紧耦合的,在增加数据节点进行扩容的同时,也复制一份了元数据。此时数据库系统有多份元数据需要同步,同步元数据也会增加系统开销和复杂性。
在使用过程中,随着数据量的增长,传统MPP架构数据库每个集群的数据都保存在计算节点本地磁盘,集群之间的数据无法做到有效共享,形成“数据孤岛”现象。同时,大量数据拷贝操作,造成数据严重冗余。
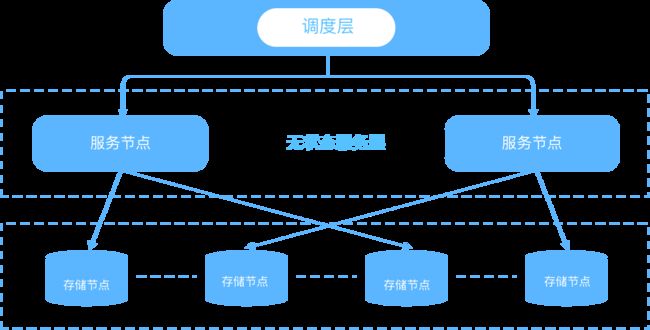 HashData元数据服务层是独立存储的,分成三个层次:调度层、无状态服务层和持久化存储层 。
HashData元数据服务层是独立存储的,分成三个层次:调度层、无状态服务层和持久化存储层 。
调度层主要解决两类问题。第一是帮助计算集群去找到元数据节点。调度层需要把元数据节点以及它的角色发布到ETCD ,然后计算集群通过订阅ETCD上这些角色位置的变更信息,它们可以自动地去找到更新的catalog,为不同的角色提供了不同的服务。
计算集群在计算的应用层来通过服务发现找到服务对象,尽可能地避免所有的节点去访问同一个catalog。
调度层还具有服务负载均衡的功能。调度层在 catalog 上会同时就一个角色注册多个入口,又可以允许计算机去通过 catalog 推送给调度层的负载情况,避免某些 catalog 出现热点。
元数据服务层为所有计算集群提供统一的元数据管理服务,保证多个计算集群面对统一的数据视图,进行一致性访问。同时,用户可以通过云管平台实现超大规模的元数据集群操作。
持久化存储层使用的是FoundationDB,这款由苹果公司开源的数据库,经过大规模的商用验证,具备高度可用性。其最有名的两个应用场景是支持iCloud云服务和Snowflake的元数据服务。
由于采用云原生架构,HashData云数仓多个集群共享统一的元数据、统一的数据存储,集群间不竞争CPU、内存和IO资源,可以根据业务需求无限地创建集群。为了提高并发数量,只需要增加计算集群,来满足弹性、高并发的要求,系统可用性显著增加,同时进一步降低性能开销。