RabbitMQ 在python中的使用
原文地址:https://blog.51cto.com/10983441/2434053
一、RabbitMQ介绍
1、python的Queue和RabbitMQ
python消息队列:
线程queue(同一进程之间进行交互)
进程queue(父子进程进行交互或同一个进程下的多个子进程进行交互)
两个完全独立的python程序:
是不能用上面的queue进行交互的,或者和其他语言交互的方式有哪些呢?
1.Disk:可以把数据写入磁盘
2.Socket通信
3.消息中间件:RabbitMQ,ZeroMQ,ActiveMQ等。2、消息队列的应用场景
2.1、异步处理
场景说明:
用户注册后,需要发送注册右键和注册短信。
传统方式有两种:
1.串行方式
2.并行方式串行方式:
将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。
以上三个任务全部完成后,返回给客户端
并行方式:
将注册消息写入数据库成功后,发送注册邮件的同时,发送注册短信。
以上三个任务完成后,返回给客户端。
与串行的差别是,并行的方式可以提高处理的时间。
假设三个业务节点每个使用50ms,不考虑网络等其他开销,串行的方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。
则串行方式1秒内可处理的请求量是7次(1000/150)。
并行方式处理的请求量是10次(1000/100)。
小节:
传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决呢?引入消息队列:
改造后的架构如下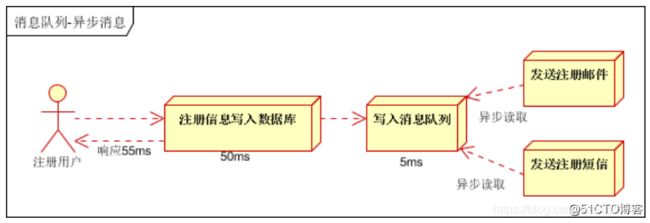
按照上图,用户的响应时间相当于注册信息写入数据库的时间,也就是50毫秒。
注册邮件,发送短信写入消息队列后,直接返回。因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。
因此架构改变后,系统的吞吐量提高到美妙20QPS。比串行提高了3倍,比并行提高了2倍。2.2、应用解耦
场景说明:
用户下单后,DD系统需要通知KC系统。传统的做法是,DD系统调用KC系统的接口。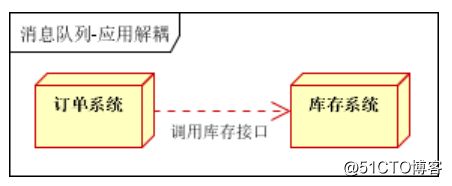
传统方式的缺点:
加入KC系统无法访问,则DD库存将失败,从而导致DD失败,两统耦合。
使用消息队列后:
订单系统:
用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户下单成功。
库存系统:
订阅下单的消息,获取下单信息,库存系统根据下单信息,进行库存操作。
假如:
在下单时库存系统不能使用,也不会影响下单,因为下单后,订单系统写入消息队列后,就不再关心其他的后续操作了。
实现了订单系统与库存系统的应用解耦。2.3、流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
应用场景:
秒杀活动,一般会以为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
1.可以控制活动的人数。
2.可以缓解短时间内高流量压垮应用
用户的请求,服务器接收后,首先写入消息队列。
假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
秒杀业务根据消息队列中的请求信息,再做后续处理。2.4、消息通讯

二、RabbitMQ基本示例
1、单发送单接收 - 生产者消费者模型
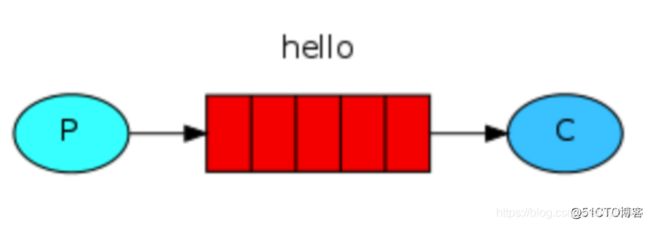
生产者send.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
# 创建凭证,使用rabbitmq用户密码登录 # 去邮局取邮件,必须得验证身份
credentials = pika.PlainCredentials("admin","123456")
# 新建连接,这里localhost可以更换为服务器ip # 找到这个邮局,等于连接上服务器
connection = pika.BlockingConnection(pika.ConnectionParameters(‘10.0.0.61‘,credentials=credentials))
# 创建频道 # 建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接
channel = connection.channel()
# 声明一个队列,用于接收消息,队列名字叫“水许传”
channel.queue_declare(queue=‘SH‘)
# 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=‘‘),
# 它允许我们精确的指定发送给哪个队列(routing_key=‘‘),参数body值发送的数据
channel.basic_publish(exchange=‘‘, routing_key=‘SH‘, body=‘武松又去打老虎啦2‘)
print("已经发送了消息")
# 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接
connection.close()
生产者发送完消息,就结束了,就可以处理其他程序了
消费者receive.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("admin","123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(‘10.0.0.61‘,credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="SH")
def callback(ch,method,properties,body):
print("消费者接收到了任务:%r"%body.decode("utf8"))
# 有消息来临,立即执行callback,没有消息则夯住,等待消息
# 老百姓开始去邮箱取邮件啦,队列名字是水许传
# def basic_consume(self,
# queue,
# on_message_callback,
# auto_ack=False,
# exclusive=False,
# consumer_tag=None,
# arguments=None):
# 这个参数的调用有所改动
# 第一个参数是队列
# 第二个是回调函数
# 第三个这是auto_ack=True
channel.basic_consume("SH",callback,True)
# 开始消费,接收消息
channel.start_consuming()
消费者会阻塞在这里,一直等待消息,队列中有消息了,就执行回调函数

停掉消费者端,发送多个消息,再次查看



2、rabbitmq消息确认之ack
默认情况下,auto_ack=True,
生产者发送数据给队列,消费者取出消息后,数据将会被删除。
特殊情况,如果消费者处理过程中,出现错误,数据处理没有完成,那么该数据将从队列中丢失。
ACK机制用于保证消费者如果拿了队列的消息,客户端处理时出错了,那么队列中仍然存在这个消息,提供下一位消费者继续取
不确认机制:
即每次消费者接收到数据后,不管是否处理完成,rabbitmq-server都会把这个消息标记完成,从队列中删除。send.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("admin", "123456")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters("10.0.0.61", credentials=credentials))
# 创建频道
channel = connection.channel()
# 新建一个队列,用于接收消息
channel.queue_declare(queue="SH2")
# 注意,在rabbitmq中,消息要发送给队列,必须经过交换(exchange)
# 可以使用空字符串交换(exchange="")
# 精确的指定发送给哪个队列(routing_key=""),参数body值发送的数据
channel.basic_publish(exchange="",
routing_key="SH2",
body="SH2 来啦来啦!")
print("消息发送完成")
connection.close()
receive.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
# 拿到消息必须给rabbitmq服务端回复ack,否则消息不会被删除。防止客户端出错,数据丢失
import pika
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("admin","123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(‘10.0.0.61‘,credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="SH2")
def callback(ch,method,properties,body):
print("消费者接收到了任务:%r"%body.decode("utf8"))
# 演示报错,消息仍然存在,取消下面的int注释。
# int("qwqwqwq")
# 有消息来临,立即执行callback,没有消息则夯住,等待消息
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume("SH2",callback,False)
# 开始消费,接收消息
channel.start_consuming()



这里只剩下一个队列了,是因为刚刚电脑没电,重启了,重启后所有的队列,消息都没有了。。
这个是刚刚新建的。啦啦啦啦。。。。。。。。。。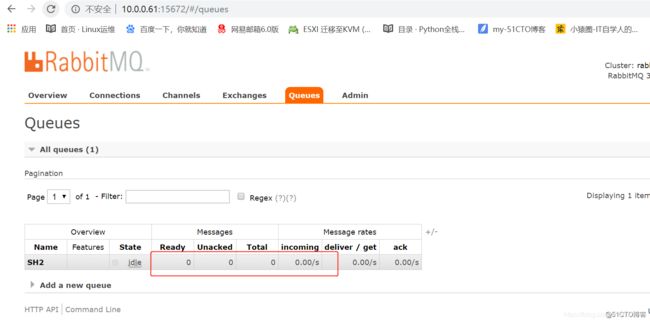
3、RabbitMQ消息持久化(durable,properties)
上面我们看到,我重启后,队列全部没有了。
为了保证RabbitMQ在退出或者异常情况下数据没有丢失,需要将queue,exechange和Message都持久化。
持久化步骤:
1.队列持久化
每次声明队列的时候,都加上durable,注意每个队列都要写,客户端和服务端声明的时候都要写。
#在管道里声明
queue channel.queue_declare(queue=‘hello2‘, durable=True)
2.消息持久化
发送端发送消息时,加上properties
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
)
send.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("admin", "123456")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters("10.0.0.61", credentials=credentials))
# 创建频道
channel = connection.channel()
# 新建一个队列,用于接收消息
# 默认情况下,此队列不支持持久化,如果服务挂掉,数据丢失
# durable=True开启持久化,必须新开启一个队列,原本的队列已经不支持持久化了
channel.queue_declare(queue="SH3", durable=True)
# delivery_mode=2代表消息持久化
channel.basic_publish(exchange="",
routing_key="SH3",
body="SH3 持久化 来啦来啦!",
# 数据持久化
properties=pika.BasicProperties(delivery_mode=2))
print("消息发送完成")


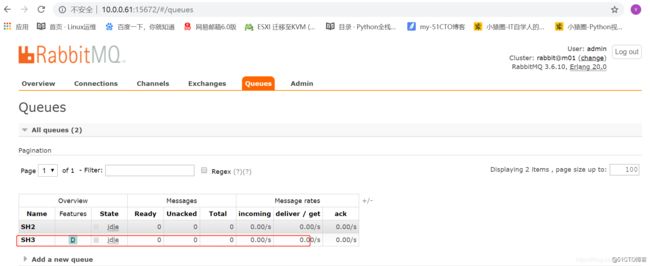

4、RabbitMQ广播模式(exchange)----消息订阅发布 Publish\Subscribe(消息发布\订阅)
前面的效果都是一对一发,如果做一个广播效果可不可以,这时候需要用到exchange了。
exchange必须明确的知道,收到的消息要发送给谁。
exchange的类型决定了怎么处理。类型有以下几种
1.fanout:exchange将消息发送给和该exchange连接的所有queue;也就是所谓的广播模式;此模式下忽略routing_key
2.direct:通过routingKey和exchange决定的那个唯一的queue可以接收消息,只有routing_key为"black"时才可以将其发送到队列queue_name;
3.topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
exchange type 过滤类型
fanout = 广播
direct = 组播
topic = 规则播
header = 略过。。。
注意:广播是实时的,没有客户端接收,消息就没有了,不会保存下来,不会等待客户端启动时接受消息。类似收音机。
所以在发送消息前,要先启动客户端,准备接受消息,然后启动服务端发送消息。
4.1、fanout纯广播/all
需要queue和exchange绑定,因为消费者不是和exchange直连的,消费者连接在queue上,queue绑定在exchange上,消费者只会在queue里读取消息。
send.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("admin", "123456")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters("10.0.0.61", credentials=credentials))
# 创建频道
channel = connection.channel()
# 这里是广播,不需要声明queue
channel.exchange_declare(exchange="log", # 声明广播管道
exchange_type="fanout")
# delivery_mode=2代表消息持久化
channel.basic_publish(exchange="log",
routing_key="", # 此处为空,必须有
body="fanout 持久化 来啦来啦!")
print("消息发送完成")
connection.close()
client.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("admin","123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(‘10.0.0.61‘,credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="log", exchange_type="fanout")
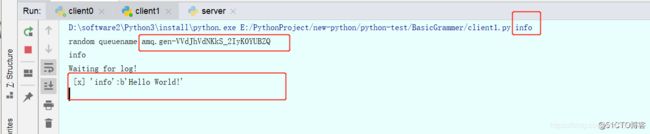
# 不指定queue名字,rabbit会随机分配一个名字
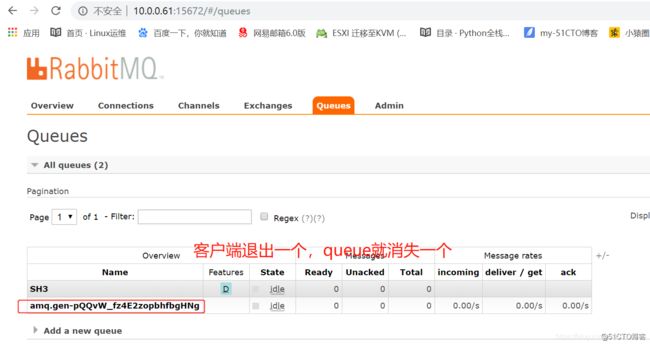
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(queue="", exclusive=True)
# 获取随机的queue名字
queue_name = result.method.queue
print("random queuename", queue_name)
channel.queue_bind(exchange="log", # queue绑定到转发器上
queue=queue_name)
print("Waiting for log!")
def callback(ch,method,properties,body):
print("消费者接收到了任务:%r"%body.decode("utf8"))
# auto_ack设置为False
channel.basic_consume(queue_name,callback,True)
# 开始消费,接收消息
channel.start_consuming()





4.2、direct有选择的接受消息
路由模式,通过routing_key将消息发送给对应的queue;
如下面这句话,可以设置exchange为direct模式,只有routing_key为"black"时才将其发送到队列queue_name;
channel.queue_bind(exchange=exchange_name,queue=queue_name,routing_key=‘black‘)
上图中,Q1和Q2可以绑定同一个key,如绑定routing_key="KeySame";
那么受到routing_key为KeySame的消息时,将会同时发送给Q1和Q2,退化为广播模式。send.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("admin", "123456")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters("10.0.0.61", credentials=credentials))
# 创建频道
channel = connection.channel()
# 这里是广播,不需要声明queue
channel.exchange_declare(exchange="direct_logs", # 声明广播管道
exchange_type="direct")
# 重要程度级别,这里默认定义为 info
severity = sys.argv[1] if len(sys.argv) > 1 else ‘info‘
message = ‘ ‘.join(sys.argv[2:]) or ‘Hello World!‘
channel.basic_publish(exchange="direct_logs",
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
client.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
import sys
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("admin","123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(‘10.0.0.61‘,credentials=credentials))
channel = connection.channel()
# 生产者和消费者端都要声明队列,以排除生成者未启动,消费者获取报错的问题
channel.exchange_declare(exchange="direct_logs", exchange_type="direct")
# 不指定queue名字,rabbit会随机分配一个名字
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(queue="", exclusive=True)
# 获取随机的queue名字
queue_name = result.method.queue
print("random queuename", queue_name)
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
# 循环列表去绑定
for severity in severities:
print(severity)
channel.queue_bind(exchange=‘direct_logs‘, queue=queue_name, routing_key=severity)
print("Waiting for log!")
def callback(ch,method,properties,body):
print(" [x] %r:%r" % (method.routing_key, body))
# auto_ack设置为False
channel.basic_consume(queue_name,callback,True)
# 开始消费,接收消息
channel.start_consuming()




4.3、topic规则播
topic模式类似于direct模式,只是其中的routing_key变成了一个有“.”分隔的字符串,“.”将字符串分割成几个单词,
每个单词代表一个条件;
话题类型,可以根据正则进行更精确的匹配,按照规则过滤。
exchange_type="topic"。
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入"路由值"和"关键字"进行匹配,匹配成功,将数据发送到指定队列。
#表示可以匹配0个或多个单词
*表示只能匹配一个单词5、关键字发布
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,
即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
send.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("admin", "123456")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters("10.0.0.61", credentials=credentials))
# 创建频道
channel = connection.channel()
# 这里是广播,不需要声明queue
channel.exchange_declare(exchange=‘m2‘, exchange_type=‘direct‘)
channel.basic_publish(exchange="m2",
routing_key="vita",
body="vita send message")
print("消息发送完成")
connection.close()
client0.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
import sys
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("admin","123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(‘10.0.0.61‘,credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="m2", exchange_type="direct")
# 不指定queue名字,rabbit会随机分配一个名字
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(queue="", exclusive=True)
# 获取随机的queue名字
queue_name = result.method.queue
print("random queuename", queue_name)
# 让exchange和queque进行绑定.
channel.queue_bind(exchange=‘m2‘,queue=queue_name,routing_key=‘vita‘)
def callback(ch,method,properties,body):
print(" [x] %r:%r" % (method.routing_key, body))
# auto_ack设置为False
channel.basic_consume(queue_name,callback,True)
# 开始消费,接收消息
channel.start_consuming()

client1.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
import sys
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("admin","123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(‘10.0.0.61‘,credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="m2", exchange_type="direct")
# 不指定queue名字,rabbit会随机分配一个名字
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(queue="", exclusive=True)
# 获取随机的queue名字
queue_name = result.method.queue
print("random queuename", queue_name)
# 让exchange和queque进行绑定.
channel.queue_bind(exchange=‘m2‘,queue=queue_name,routing_key=‘lili‘)
channel.queue_bind(exchange=‘m2‘,queue=queue_name,routing_key=‘vita‘)
def callback(ch,method,properties,body):
print(" [x] %r:%r" % (method.routing_key, body))
# auto_ack设置为False
channel.basic_consume(queue_name,callback,True)
# 开始消费,接收消息
channel.start_consuming()
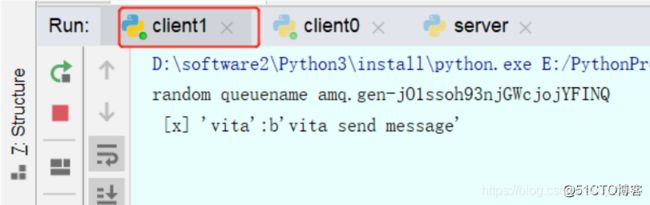
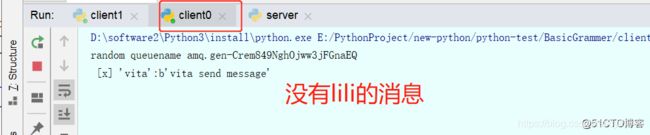
send.py中
routing_key="lili",
则只有绑定这个歌routing_key的客户端能收到消息
3.RPC
上面的所有例子中,队列都是单向的,一端发送,一端接收。
如果发送端想接收消费端处理的数据,怎么办呢,这就需要RPC(remote procedure call)远程过程调用了。
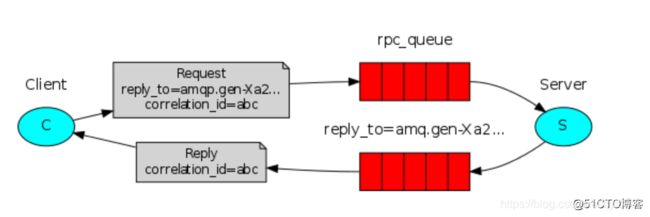
如图我们可以看出生产端client向消费端server请求处理数据,他会经历如下几次来完成交互。
1.生产端 生成rpc_queue队列,这个队列负责把消息发给消费端。
2.生产端 生成另外一个随机队列callback_queue,这个队列是发给消费端,消费者用这个队列把处理好的数据发送给生产端。
3.生产端 生成一组唯一字符串UUID,发送给消费者,消费者会把这串字符作为验证在发给生产者。
4.当消费端处理完数据,发给生产端,会把处理数据与UUID一起通过随机生产的队列callback_queue发回给生产端。
5.生产端,会使用while循环 不断检测是否有数据,并以这种形式来实现阻塞等待数据,来监听消费端。
6.生产端获取数据调用回调函数,回调函数判断本机的UUID与消费端发回UID是否匹配,由于消费端,可能有多个,且处理时间不等所以需要判断,判断成功赋值数据,while循环就会捕获到,完成交互。
send.py
import queue
import pika
import uuid
import time
class FibRpcClient(object):
def __init__(self):
credentials = pika.PlainCredentials("admin", "123456")
# 1.创建连接
self.connection = pika.BlockingConnection(pika.ConnectionParameters("10.0.0.61", credentials=credentials))
self.channel = self.connection.channel()
# 2.生成随机queue
# exclusive = True,消费者端断开连接,队列删除
result = self.channel.queue_declare(queue="", exclusive=True)
# 随机获取queue名字,发送数据给消费端
self.callback_queue = result.method.queue
# self.on_response回调函数:只要收到消息就调用这个函数
# 声明收到消息后,收queue=self.callback_queue内的消息
self.channel.basic_consume(self.callback_queue, self.on_response, True)
def on_response(self, ch, method, props, body):
"""
收到消息就调用该函数
:param ch: 管道内存对象
:param method: 消息发送给哪个queue
:param props:
:param body: 数据对象
:return:
"""
# 判断随机生成的ID与消费者端发过来的ID是否相同,
if self.corr_id == props.correlation_id:
# 将body值给self.response
print("接收到客户端发送的信息:", body)
self.response = body
def call(self, n):
# 赋值变量,一个循环值
self.response = None
# 随机生成唯一的字符串
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange="",
routing_key="rpc_queue",
properties=pika.BasicProperties(
# 告诉消费端,执行命令成功后把结果返回给该队列
reply_to=self.callback_queue,
# 生成UUID,发送给消费端
correlation_id=self.corr_id,
),
# 发的消息,必须传入字符串,不能传数字
body=str(n))
# 没有数据就循环接收数据
while self.response is None:
# 非阻塞版的start_consuming()
# 没有消息不会阻塞
self.connection.process_data_events()
print("client does not send data")
time.sleep(1)
# 接收到了消费端的结果,返回
return int(self.response)
fib_rpc = FibRpcClient()
print("[x] Requesting fib(6)")
response = fib_rpc.call(6)
print(" [.] Got %r" % response)

receive.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
import subprocess
import time
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("admin", "123456")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters("10.0.0.61", credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="rpc_queue")
def fib(n):
"""
斐波那契数列
:param n:
:return:
"""
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange="",
# 数据发送到生产端随机生成的queue
routing_key=props.reply_to,
# 同时把correlation_id值设置为生产端传过来的值。
properties=pika.BasicProperties(
correlation_id=props.correlation_id,
),
# 把fib()的结果返回给生产端
body=str(response))
# 确保任务完成
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume("rpc_queue", on_request)
print(" [x] Awaiting RPC requests")
channel.start_consuming()
