Sentinel 实现原理——概述
引言
在前面的文章中,我已经介绍了 Sentinel 中的概念,以及所提供的各类功能如何使用。从本篇文章开始,我们将深入到源码中,自顶向下地介绍 Sentinel 整体的实现原理以及各个核心模块的实现原理。本文作为这一部分介绍的开篇,我会先介绍一下 Sentinel 的整体设计思想,以及下层包含的各个模块,后续的文章中会详细地介绍各个核心模块的实现原理。更多相关文章和其他文章均收录于贝贝猫的文章目录。
整体设计
接下来,我们会分别从数据和处理过程这两个角度介绍 Sentinel 的设计原理,首先,我们先介绍一下 Sentinel 中内部是如何组织数据的,通过对数据结构的观察,大家就能清楚地认识到 Sentinel 是如何实现链路流控、关联流控、直接流控、访问源流控这些功能的了。
数据
这里我们以一次完整的使用流程出发,展开对 Sentinel 数据部分的介绍。在下面的例子中,我们先定义代码执行的 Context,然后调用 SphU.entry 入口函数,在执行完正常业务逻辑后,我们从 entry 中退出,如果期间出现了异常,则通过 Tracer.trace 统计异常。
// 处理 HTTP 请求
public String handleHttpRequest(String originIp) {
ContextUtil.enter("HTTPResource1Entrance", originIp);
return doSomeThing();
}
// 处理 RPC
public String handleRPC(String consumerName) {
ContextUtil.enter("RPCResource1Entrance", consumerName);
return doSomeThing();
}
public String doSomeThing(String param, String origin) {
Entry entry1 = null;
try {
entry1 = SphU.entry("Resource1");
// do some thing
doOtherThing();
return "Result";
} catch (BlockException e) {
return "System busy";
} catch (Exception ex) {
Tracer.trace(ex);
} finally {
if (entry1 != null) {
entry1.exit();
}
}
}
public void doOtherThing(String param) {
Entry entry2 = null;
try {
entry2 = SphU.entry("Resource2");
// do other thing
} catch (BlockException e) {
throw e;
} catch (Exception ex) {
Tracer.trace(ex);
} finally {
if (entry2 != null) {
entry2.exit();
}
}
}
在上面的例子中,主要涉及到了 Sentinel 中几个核心的概念,Resource, Entry,Context。
- Resource: 资源是 Sentinel 对所保护的内容的抽象,任何您想保护的代码、函数等都可以通过
SphU.entry接口将其定义为一个资源,SphU.entry接口的第一个参数描述了该资源的名称。Sentinel 会创建一些和该资源相关的统计节点,它们肩负着保存各类统计量的责任(QPS, Exception数量等)。这里大家可能会有疑问:为什么一个资源需要多个统计节点呢?因为 Sentinel 所支持的限流维度很多,比如针对访问源的针对链路的等等,这每一个维度都需要一个独立的统计节点,就比如上例中,我将doSomeThing这个函数定义为一个名为Resource1的资源,那么当执行了doSomeThing后,Sentinel 内部就会有和Resource1相关的各类统计节点,这也就意味着后续只要我们添加了针对Resource1资源的流控规则,就能限制doSomeThing这个函数的调用。 - Node: Sentinel 里面的各种种类的统计节点:
- StatisticNode:最为基础的统计节点,是后续三种节点的父类,包含秒级和分钟级两个滑动窗口结构。
- DefaultNode:链路节点,用于统计调用链路上某个资源的数据,维持树状结构。
- ClusterNode:簇点,用于统计每个资源全局的数据(不区分调用链路),以及存放该资源的按来源区分的调用数据
- EntranceNode:入口节点,特殊的链路节点,对应某个 Context 入口的所有调用数据。
- Entry: 又称为调用点,这里面保存着和某一特定资源的某一次调用相关的信息,比如这次调用的起始执行时间,结束时间,是否抛出异常,调用链路中的父子关系,该调用点对应资源的处理链(ProcessorSlotChain),还保存了该调用点所对应的资源统计节点
- Context: Context 代表调用链路上下文,贯穿一次调用链路中的所有 Entry,每次调用链路开始时,都会创建一个新的 Context 实例,Context 名称即为调用链路入口名称,Context 是保存调用链路元数据的容器,这里所说的元数据主要包括:
- 当前调用树的根节点,通过这个根节点,我们可以用来区分不同的调用链路,比如上述的
HTTPResource1Entrance和RPCResource1Entrance就是两个不同的根节点,ContextUtil.enter接口的第一个参数描述了该调用链路的根节点的名称,如果没有显式地调用ContextUtil.enter接口,那么 Sentinel 会以sentinel_default_context作为默认根节点,Sentinel 会保证每个名称的根节点实例是唯一的 - 调用源 origin,通过
ContextUtil.enter接口的第二个参数指定,一般会将 Consumer name 或者 consumer IP 地址设定为调用源 - 当前的执行点 Entry,因为 Context 是保存在 ThreadLocal 中的,所以当前线程每到一个执行点,就会将其记录在 Context 中
- 当前调用树的根节点,通过这个根节点,我们可以用来区分不同的调用链路,比如上述的
在下面这张图中,大家可以看到上例中 Context, Entry, Resource 数据之间是如何组织的,其中 Context 主要用来保存当前调用树的 Origin,调用树根节点,以及当前执行到的调用点。而整个调用链路是通过 Entry 的父子指针来描述的,同时 Entry 中还会保存相同根节点下访问当前资源的统计节点(我称之为 DefaultNode),Sentinel 的链路模式流控功能就是通过这个统计节点实现的。为了统计某一资源的所有访问量,Sentinel 中还对上述统计量进行了聚合,聚合后的统计节点会包含某一资源在不同入口下的所有访问量(我称之为 ClusterNode),Sentinel 直接模式和关联模式流控功能就是通过这个统计节点实现的。最后,Sentinel 为了能够根据访问源进行流控还会针对每一个资源的每一类访问源分别进行流量统计(我称之为 OriginNode)。
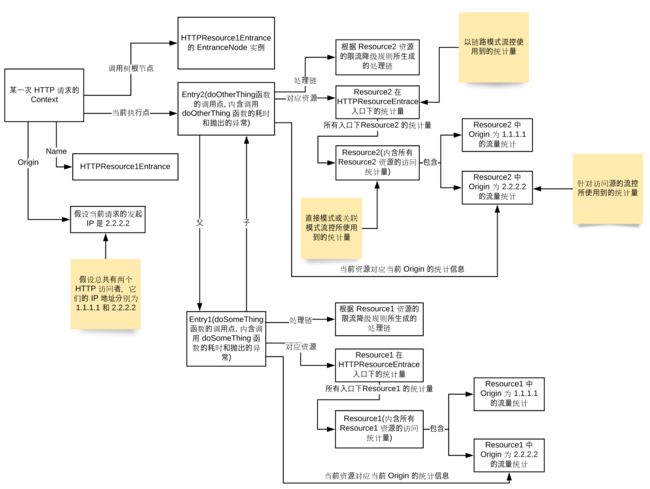
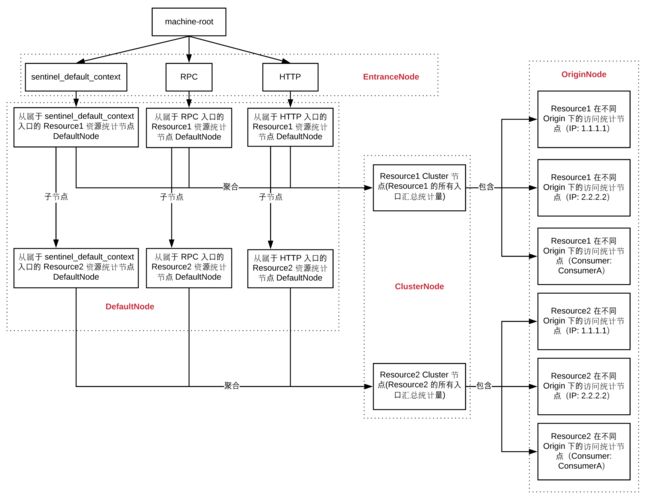
上面的图中,旨在介绍 Context,Entry,和 Resource 各个统计节点之间的关系,而且各个统计节点(EntranceNode, DefaultNode, ClusterNode, OriginNode)之间的的关系并没有完整的展示出来。下面我将统计节点之间的关系单独抽了出来,通过下图大家应该能够更加清晰地理解各个统计节点之间的关系。
那么,上述的这些数据是通过什么方式组织在一起的呢?接下来我们就来介绍一下这个部分。
数据的处理
首先,在调用 ContextUtil.enter(xxx) 时,会创建对应的 EntranceNode 节点并保存在 ThreadLocal 的 Context 中。如果没有显式地调用 ContextUtil.enter(xxx) 的话,它会在 SphU.entry 接口中被自动调用,生成一个默认的 Context。
当执行到 SphU.entry 接口时,就到了 Sentinel 的核心骨架——处理链(ProcessorSlotChain)了,Sentinel 将不同的 Slot 按照顺序串在一起(责任链模式),从而将不同的功能(限流、降级、系统保护)组合在一起。Slot Chain 其实可以分为两部分:统计数据构建部分(statistic)和判断部分(rule checking)。其核心结构如下:
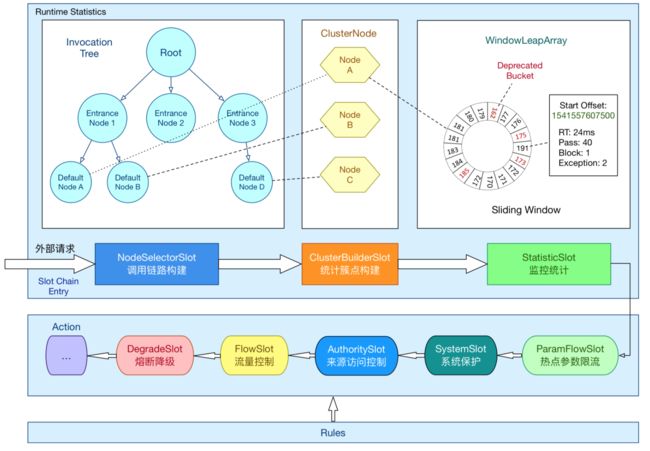
上图仅作为设计思想的展示,图中 Slot 的顺序已和最新版 Sentinel Slot Chain 顺序不一致,目前每一个 Resource 都会有一个对应的 ProcessorSlotChain,各个 Resource 的 ProcessorSlotChain 是隔离的。
上图中很明确的展示了各个 Slot 如何组织数据:
- NodeSelectorSlot:根据 context 创建 DefaultNode,然后维护整个调用树的父子关系,然后将相关数据保存在 Context 中。
- ClusterBuilderSlot:首先根据 resourceName 创建 ClusterNode,并将其引用保存在 defaultNode中,然后再根据 origin 创建来源节点(类型为 StatisticNode),并将源节点保存在当前的调用点 Entry 中。
- StatisticSlot:先调用后续 Slot 的检查过程,如果检查通过增加各个维度的计数器
- entry 过程:依次执行后面的判断 slot。每个 slot 触发流控的话会抛出异常(BlockException 的子类)。若有 BlockException 抛出,则记录 block 数据;若无异常抛出则算作可通过(pass),记录 pass 数据。
- exit 过程:若无 error(无论是业务异常还是流控异常),记录 complete(success)以及 RT,线程数-1。
- 后续各个检查 Slot: 根据定义的规则,结合统计节点的数据判断是否通过,如果通过则执行下一个 Slot 的处理过程,否则抛出相应的异常
最后,总结一下各个统计节点的数据规模:
- ClusterNode 的规模是 resource count
- DefaultNode 的规模是 resource count * context count,存在每个 NodeSelectorSlot 的 map 里面
- EntranceNode 的规模是 context count,存在 ContextUtil 类的 contextNameNodeMap 里面
- OriginNode(类型为 StatisticNode)的维度是 resource count * origin count,存在每个 ClusterNode 的 originCountMap 里面
代码结构
Sentinel 的整个项目结构都很清晰,下面我简单地介绍一下项目中各个模块的职责,在后续的文章中,我们会对主要的模块进行源码实现介绍。
- sentinel-core: 核心模块,限流、降级、系统保护等都在这里实现
- sentinel-dashboard: 控制台模块,可以对连接上的sentinel客户端实现可视化的管理
- sentinel-transport: 传输模块,提供了基本的监控服务端和客户端的API接口,以及一些基于传输方式的实现(Netty,HTTP)
- sentinel-extension: 扩展模块,主要对 DataSource、注解支持、热点参数流控进行了部分扩展实现
- sentinel-adapter: 适配器模块,主要实现了对一些常见框架的适配
- sentinel-demo: 样例模块,介绍了如何使用sentinel进行限流、降级等
- sentinel-benchmark: 基准测试模块,对核心代码的精确性提供基准测试
- sentinel-cluster: 提供集群流控的支持,主要包括令牌服务器的 Server 端和 Client 端实现
- sentinel-logging: 提供 Logger 实现的拓展能力
参考内容
[1] Sentinel GitHub 仓库
[2] Sentinel 官方 Wiki
[3] Sentinel 1.6.0 网关流控新特性介绍
[4] Sentinel 微服务流控降级实践
[5] Sentinel 1.7.0 新特性展望
[6] Sentinel 为 Dubbo 服务保驾护航
[7] 在生产环境中使用 Sentinel
[8] Sentinel 与 Hystrix 的对比
[9] 大流量下的服务质量治理 Dubbo Sentinel初涉
[10] Alibaba Sentinel RESTful 接口流控处理优化
[11] 阿里 Sentinel 源码解析
[12] Sentinel 教程 by 逅弈
[13] Sentinel 专题文章 by 一滴水的坚持
