Hadoop + Hive + DolphinScheduler高可用集群部署
一、参考文档
Zookeeper-3.5.7集群安装:https://blog.csdn.net/weixin_42631782/article/details/115691252
Hadoop-3.1.3高可用集群部署
https://blog.51cto.com/simplelife/5095289
Hive-3.1.2部署文档
https://blog.51cto.com/simplelife/5100277
一文讲懂Hive高可用/HiveServer2 高可用及Metastore高可用
https://juejin.cn/post/6981353941581692936
DolphinScheudler-2.0.集群部署文档
https://blog.51cto.com/simplelife/5049665
二、 软件安装包
jdk-8u331-linux-x64.rpm JDK8安装包
mysql-connector-java-5.1.49.jar MySQL5连接器
apache-zookeeper-3.5.7-bin.tar.gz ZooKeeper安装包
hadoop-3.1.3.tar.gz Hadoop安装包
apache-hive-3.1.2-bin.tar.gz Hive安装包
apache-tez-0.10.1-bin.tar.gz Tez安装包
apache-dolphinscheduler-2.0.6-bin.tar.gz DolphinScheduler安装包
注意:除JDK8的子版本外,请严格按照给定的版本号安装。
Hive下载地址:https://archive.apache.org/dist/hive/hive-3.1.2/
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
Tez下载地址:https://archive.apache.org/dist/tez/0.10.1/
Zookeeper下载地址:https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/
Dolphinscheduler下载地址:https://www.apache.org/dyn/closer.lua/dolphinscheduler/2.0.6/apache-dolphinscheduler-2.0.6-bin.tar.gz
三、集群规划
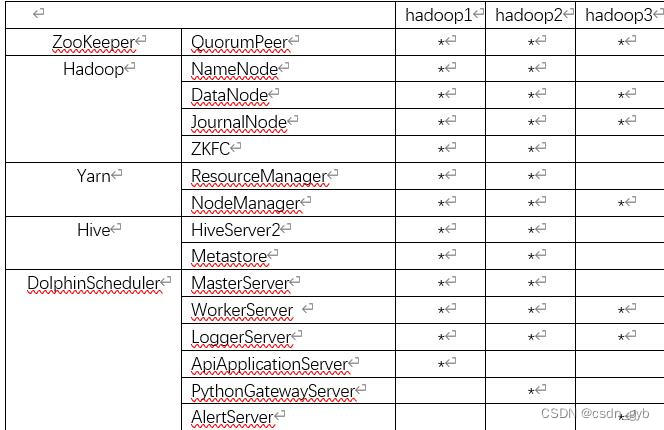
四、准备工作
操作系统为CentOS7。
集群中所有三台服务器执行以下操作:
配置hosts
:
sudo vim /etc/hosts
192.168.62.161 hadoop1
192.168.62.162 hadoop2
192.168.62.163 hadoop3
安装JDK1.8:
#安装jdk
#解压jdk到指定目录
tar -zxvf /tmp/jdk-8u181-linux-x64.tar.gz -C /usr/share/
对应路径如下(配置环境变量要用到该路径)
/usr/share/jdk1.8.0_181
#然后配置jdk环境变量(见子节点)
#然后把jdk目录复制到其他节点
sh /home/scp.sh /usr/share/jdk1.8.0_181
sh /home/scp.sh /etc/profile
安装hadoop及其配置
配置防火墙和SELINUX:
#关闭防火墙并查看状态(集群服务器)
systemctl stop firewalld
systemctl status firewalld
配置时间同步:
yum -y install ntp ntpdate
ntpdate ntp.aliyun.com
hwclock –systohc
检查时间同步:
watch -t -n 1 date +%T
新增hadoop用户:
useradd hadoop
passwd Hadoop
授权root权限:
vim /etc/sudoers
hadoop ALL=(ALL) ALL
切换用户:
su – hadoop
注意:之后的操作尽量都在hadoop用户下完成,以避免各种权限问题。如操作需要root权限则用sudo命令。
配置免密登录:
ssh-keygen -t rsa
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
创建目录:
mkdir -p /home/hadoop/data/zookeeper
mkdir -p /home/hadoop/data/journalnode
mkdir -p /home/hadoop/data/tmp
mkdir -p /home/hadoop/data/hive
mkdir -p /home/hadoop/data/dolphinscheduler
mkdir -p /home/hadoop/data/dolphinscheduler-install
#主节点上传文件分发脚本
资源如下
https://download.csdn.net/download/csdn_gyb/31849299
#主节点执行同步
五、安装ZooKeeper集群
解压安装包后修改配置文件:
cd conf
mv zoo_sample.cfg zoo.cfg
dataDir=/home/hadoop/data/zookeeper
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
cd data
vim myid
1/2/3(每台服务器不相同)
bin/zkServer.sh
export JAVA_HOME=Java安装目录
集群分发:
scp -r hadoop-3.1.3 hadoop2:/home/hadoop/
scp -r hadoop-3.1.3 hadoop3:/home/hadoop/
使用zk.sh status/start/stop来启动和管理zk集群。
六、Hadoop高可用集群部署
解压hadoop-3.1.3
sudo vim /etc/profile
配置环境变量HADOOP_HOME、PATH
#配置hadoop的环境变量
vi /etc/profile
文件末尾添加
export HADOOP_HOME=/home/hadoop-3.1.3
export PATH=P A T H : PATH:PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
Hadoop配置文件:
cd etc/hadoop
hadoop-env.sh
#指定JAVA_HOME
export JAVA_HOME= Java安装目录
#指定hadoop用户,hadoop3.x之后必须配置(我的用户名就叫hadoop)
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_ZKFC_USER=hadoop
export HDFS_JOURNALNODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
core-site.xml
<!--集群名称-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value> </property>
<!--临时目录:提前创建好-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
<!--webUI展示时的用户-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<!--高可用依赖的zookeeper的通讯地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!--用于连接hive server2(可选项)-->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!--定义hdfs集群中的namenode的ID号-->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!--定义namenode的主机名和rpc协议的端口-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop2:8020</value>
</property>
<!--定义namenode的主机名和http协议的端口-->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop2:9870</value>
</property>
<!--定义共享edits的url-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1</value>
</property>
<!--定义hdfs的客户端连接hdfs集群时返回active namenode地址-->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--hdfs集群中两个namenode切换状态时的隔离方法-->
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<value>shell(/bin/true)</value>
</property>
<!--ha的hdfs集群自动切换namenode的开关-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--hdfs集群中两个namenode切换状态时的隔离方法的秘钥-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--journalnode集群中用于保存edits文件的目录:提前创建好-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journalnode</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
<description>Enable RM high-availabilitydescription>
property>
<property>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSchedulervalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yarn_cluster1value>
<description>Name of the clusterdescription>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
<description>The list of RM nodes in the cluster when HA is enableddescription>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop1value>
<description>The hostname of the rm1description>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop2value>
<description>The hostname of the rm2description>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>hadoop1:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>hadoop2:8088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181value>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embeddedname>
<value>truevalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
<description>Whether virtual memory limits will be enforced for containersdescription>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>6value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containersdescription>
property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-env.sh
export JAVA_HOME=/usr/share/jdk1.8.0_181
hadoop-env.sh
export JAVA_HOME=/usr/share/jdk1.8.0_181
export HADOOP_HOME=/home/hadoop-3.1.3
workers
#配置workers
vim /home/hadoop-3.1.3/etc/hadoop/workers
#加入集群主机名称
hadoop1
hadoop2
hadoop3
注意:workers配置集群中每台服务器都一样,都要写上所有的worker主机
集群分发:
scp -r hadoop-3.1.3 hadoop2:/home/hadoop/
scp -r hadoop-3.1.3 hadoop3:/home/hadoop/
启动集群
#启动journalnode,在hadoop1,hadoop2,hadoop3上分别执行
hdfs --daemon start journalnode
格式化namenode,在hadoop1或者hadoop2上执行,我这在hadoop1上执行了
hdfs namenode -format
#启动namenode,在hadoop1上执行
hdfs --daemon start namenode
#在hadoop2上同步namenode数据后启动,在hadoop2上执行
hdfs namenode -bootstrapStandby
hdfs --daemon start namenode
在hadoop1上执行
hdfs zkfc -formatZK
#至此,hadoop的hdfs服务已经启动完成。yarn服务启动可执行命令:start-yarn.sh
重启hdfs
stop-dfs.sh
start-dfs.sh
重启yarn
stop-yarn.sh
start-yarn.sh
直接同时重启hdfs和yarn
stop-all.sh
start-all.sh
Hadoop文件系统命令:
hadoop fs -命令 参数
如查看根目录文件:hadoop fs -ls /
创建文件夹:hadoop fs -mkdir -p /test1/test2/test3
修改权限:hadoop fs -chmod -R 777 /test1
Hadoop管理网页:
http://hadoop1:8088
Yarn管理网页:
http://hadoop1:9870
七、Hive高可用集群部署
解压hive-3.1.2
tar -zxvf /tmp/apache-hive-3.1.2-bin.tar.gz -C /home/
sudo /etc/profile
配置环境变量HIVE_HOME、PATH
配置文件:
cd conf/
cp hive-env.sh.template hive-env.sh
HADOOP_HOME=/home/hadoop/hadoop-3.1.3
export HIVE_HOME=/home/hadoop/hive-3.1.2
export HIVE_CONF_DIR=/home/hadoop/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/home/hadoop/hive-3.1.2/lib
export METASTORE_PORT=9083
export HIVESERVER2_PORT=10000
cp hive-default.xml.template hive-site.xml
该配置文件非常大,建议在官方模板中搜索以下需要修改的项目单独修改。
hive-site.xml
配置所需的环境变量
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
# 修改metastore数据库为mysql
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
<description>
Expects one of [derby, oracle, mysql, mssql, postgres].
Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it.
</description>
</property>
# metastore远程节点(Hadoop)
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083,thrift://hadoop2:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
# metastore数据库密码(MySQL)
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456789</value>
<description>password to use against metastore database</description>
</property>
# metastore数据库地址(MySQL)
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.100.1:3307/hive?useSSL=false</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
# metastore数据库驱动(MySQL)
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
# metastore数据库用户名(MySQL)
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
# 优化填坑配置
<property>
<name>hive.optimize.sort.dynamic.partition</name>
<value>true</value>
<description>
When enabled dynamic partitioning column will be globally sorted.
This way we can keep only one record writer open for each partition value
in the reducer thereby reducing the memory pressure on reducers.
</description>
</property>
# Zookeeper集群配置
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
<description>
List of ZooKeeper servers to talk to. This is needed for:
1. Read/write locks - when hive.lock.manager is set to
org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager,
2. When HiveServer2 supports service discovery via Zookeeper.
3. For delegation token storage if zookeeper store is used, if
hive.cluster.delegation.token.store.zookeeper.connectString is not set
4. LLAP daemon registry service
5. Leader selection for privilege synchronizer
</description>
</property>
# 修正官方配置文件description中的BUG
<property>
<name>hive.txn.xlock.iow</name>
<value>true</value>
<description>
Ensures commands with OVERWRITE (such as INSERT OVERWRITE) acquire Exclusive locks for transactional tables. This ensures that inserts (w/o overwrite) running concurrently
are not hidden by the INSERT OVERWRITE.
</description>
</property>
<property>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
<description>Whether HiveServer2 supports dynamic service discovery for its clients. To support this, each instance of HiveServer2 currently uses ZooKeeper to register itself, when it is brought up. JDBC/ODBC clients should use the ZooKeeper ensemble: hive.zookeeper.quorum in their connection string.</description>
</property>
# Zookeeper注册名称
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2</value>
<description>The parent node in ZooKeeper used by HiveServer2 when supporting dynamic service discovery.</description>
</property>
# 高可用配置
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop1/hadoop2</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
lib库文件:
cd lib/
mv guava-19.0.jar guava-19.0.jar.bak
从hadoop的share/hadoop/common/lib目录复制或链接guava-27.0-jre.jar
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
解压tez-0.10.1
复制或链接根目录下的tez-api-0.10.1.jar和tez-dag-0.10.1.jar
复制mysql-connector-java-5.1.49.jar
集群分发:
scp -r hive-3.1.2 hadoop2:/home/hadoop/
初始化数据库:
新建数据库 hive
cd bin/
./schematool -initSchema -dbType mysql -verbose
启动脚本:
hv.sh
高可用JDBC连接地址:
jdbc:hive2://hadoop1:2181,hadoop2:2181,hadoop3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
命令行连接Hive数据库并测试:
cd bin/
./beeline
!connect jbdc:hive2://…
show databases;
create database testdb;
use testdb;
create table tb_test (id int, name, string);
insert into tb_test values (1, ‘zhangsan’);
select * from t_test;
管理网页:
http://hadoop1:10002
http://hadoop2:10002
八、DolphinScheudler高可用集群部署
所有服务器上安装:
sudo yum install -y psmisc
配置文件:
vim conf/env/dolphinscheduler_env.sh
修改以下项目:
export HADOOP_HOME=/home/hadoop/hadoop-3.1.3/
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.1.3/etc/hadoop
export JAVA_HOME=/usr/java/jdk1.8.0_331-amd64
export HIVE_HOME=/home/hadoop/hive-3.1.2
vim conf/config/install_config.conf
修改以下项目:
ips="hadoop1,hadoop2,hadoop3"
masters="hadoop1,hadoop2"
workers="hadoop1:default,hadoop2:default,hadoop3:default"
alertServer="hadoop3"
apiServers="hadoop1"
pythonGatewayServers="hadoop2"
installPath="/home/hadoop/data/dolphinscheduler-install"
deployUser="hadoop"
dataBasedirPath="/home/hadoop/data/dolphinscheduler"
javaHome="/usr/soft/installs/jdk1.8.0"
DATABASE_TYPE=${DATABASE_TYPE:-"mysql"}
SPRING_DATASOURCE_URL=${SPRING_DATASOURCE_URL:-"jdbc:mysql://192.168.0.47:3306/hive?useSSL=false"}
SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-"root"}
SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-"vqn6vGJ1#"}
registryPluginName="zookeeper"
registryServers="hadoop1:2181,hadoop2:2181,hadoop3:2181"
registryNamespace="dolphinscheduler"
resourceUploadPath="/dolphinscheduler"
defaultFS="hdfs://ns1:8020"
resourceManagerHttpAddressPort="8088"
yarnHaIps="hadoop1,hadoop2"
singleYarnIp="yarnIp1"
hdfsRootUser="hadoop"
复制或链接hadoop配置文件到conf目录:
cd conf/
ln -s /home/hadoop/hadoop-3.1.3/etc/hadoop/core-site.xml core-site.xml
ln -s /home/hadoop/hadoop-3.1.3/etc/hadoop/hdfs-site.xml hdfs-site.xml
lib库文件:
cd lib/
复制mysql-connector-java-5.1.49.jar
集群分发:
scp -r dolphinscheduler-2.0.6 hadoop2:/home/hadoop/
scp -r dolphinscheduler-2.0.6 hadoop3:/home/hadoop/
初始化数据库:
新建数据库 dolphinscheduler
cd /home/hadoop/dolphinscheduler-2.0.6/script/
./create-dolphinscheduler.sh
首次启动,安装根目录下:
./install.sh
之后启动/停止
cd bin/
./stop-all.sh
./start-all.sh
网页地址:
http://hadoop1:12345/dolphinscheduler
admin/dolphinscheduler123
九、查看集群服务脚本
jps-all.sh
需要将Java环境变量配置从/etc/profile拷贝到集群所有服务器的~/.bashrc下,如:
~/.bashrc
#JAVA_HOME
JAVA_HOME=/usr/soft/installs/jdk1.8.0
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH
成功部署启动集群后的示例:
[hadoop@hadoop1 ~]$ ./jps-all.sh
hadoop1所有服务
