Chatgpt:原理、公式和代码,从基础走近chatgpt
原理
简单理解,ChatGPT的原理就是极其强大的语言模型作为打底(GPT系列),加上为“CHAT”而训练,平滑的多语种交互,造就了今天的chatGPT。下面的解释顺序为,语言模型,OpenAI(GPT),Googloe(BERT还是盛极一时)、ChatGPT(看看它怎么出来的)。
语言模型
定义:A language model learns to predict the probability of a sequence of words.
Language models tell us P( ~w) = P(w1 . . . wn):
How likely to occur is this sequence of words? Roughly: Is this sequence of words a “good” one in my language?
语言模型就是告诉我们一句话是不是人话。
语言模型的学习有一个特点,就是它本质上不需要标注数据。只要有大量的文本即可。所谓学习目标都是自行合理构造的。
语言模型的分类
技术原理
- Statistical Language Models: These models use traditional statistical techniques like N-grams, Hidden Markov Models (HMM) and certain linguistic rules to learn the probability distribution of words。主要是使用传统的统计技术, N-Gram, HMM以及部分语言学规则来学习序列的概率分布。
- Neural Language Models: These are new players in the NLP town and use different kinds of Neural Networks to model language。主要是使用NN来学习序列的概率分布。
以学习目标分类(参考自XLnet:https://arxiv.org/pdf/1906.08237.pdf)
- Autoregressive Language Models:当前我们可以以GPT为代表。AR language modelling seeks to estimate the probability distribution of a text corpus with an autoregressive model. Specifically, given a text sequence x = (x_1, · · · , x_T ), AR language modelling factorizes the likelihood of a forward product p(x)=∏t=1Tp(xt|x
- Autoencoder Language Models:以BERT为代表。In comparison, AE based pretraining does not perform explicit density estimation but instead aims to reconstruct the original data from corrupted input. A notable example is BERT [10], which has been the state-of-the-art pretraining approach. Given the input token sequence, a certain portion of tokens are replaced by a special symbol [MASK], and the model is trained to recover the original tokens from the corrupted version. since the predicted tokens are masked in the input, BERT is not able to model the joint probability using the product rule as in AR language modelling. In other words, BERT assumes the predicted tokens are independent of each other given the unmasked tokens, which is oversimplified as high-order, long-range dependency is prevalent in natural language
上述描述中,我们看到两种学习目标会有变化, AE在学习如何重构输入,AR本质上就在建模联合概率。对应到下游任务的时候, AE在分类系列任务中的表现就相对好,且容易学会; AR由于其单向的特点,对于很多需要双向信息的下游任务来说,想要达到同样的效果,学习难度会变高,但也由于这一点其可以支持序列生成。(思考典型的工作, MT的编码尽管可以变花样,但解码/生成过程也是单向的)
题外话:从BERT-ALBERT/Roberta;GPT-GPT3 其实我们都看到,本身有一个很重要的研究方向就是怎么样才能让模型在更多的数据上进行训练,从而收获更多知识以得到更好的效果。
从左往右的生成具有速度上的问题,可以参见 https://arxiv.org/pdf/2205.07459.pdf 字节跳动DA-transformer在生成上做到了加速。
尝试建立一个N-gram语言模型
新的技术是很好,但如果直接应用有个坏处,就是对问题的定义不够直观。旧的传统的技术虽然“落伍”,但是它对问题的定义和解释是很直观基础的。非常intuitive。
给定一句话: “I love eating apples.”
N表示我们在建模的时候要看几个单词,unigram(1-gram)表示一次就看一个单词,2-gram (or bigram)表示一次看两个,以此类推。
- Unigram: probability estimated from word frequency
- Bigram: x_i depends only on x_{i−1 }
- Trigram: x_i depends only on x_{i−2}, x_{i−1 }
unigram:
最简单最直接的一种建模思路,我们直接统计每个词出现的频率,然后作为概率来计算。
p(w)=∏t=1np(wi)
这带来的问题是:P(我爱你)=P(你爱我)
所以直觉上,我们可以认为词序是有意义的。所以就有了Bigram和Trigram,即n-gram
Bigram/Trigram
N-gram语言模型学习的目标是给定一个条件(前序word(s)),给出后面接不同词语的概率(链式法则)。
p(w1...ws) = p(w1) . p(w2 | w1) . p(w3 | w1 w2) . p(w4 | w1 w2 w3) ..... p(wn | w1...wn-1)
由于计算复杂,所以我们简化问题(马尔可夫假设),对n-gram来说,条件仅考虑前n个单词,有如下定义:
p(wk | w1...wk-1) = p(wk | wk-n, wk-1), n
p(I love eating apples) = p(I) * p(love| I) * p(eating| love) * p(apples| eating)
给出代码
n_gram_sents = [i.strip().split(' ') for i in data_text.strip().split('\n') if i]
# from nltk.corpus import reuters
from nltk import bigrams, trigrams
from collections import Counter, defaultdict
# Create a placeholder for model
model = defaultdict(lambda: defaultdict(lambda: 0))
list(trigrams(n_gram_sents[0], pad_right=True, pad_left=True)) # 观察一下
# Count frequency of co-occurance
# 统计共现的频率。trigrams将sentence变成了三元组。举例来说,The unanimous一起存在的时候,Declaration出现的次数
for sentence in n_gram_sents:
for w1, w2, w3 in trigrams(sentence, pad_right=True, pad_left=True):
model[(w1, w2)][w3] += 1
# Let's transform the counts to probabilities
# 统计分母,举例来说,The unanimous一起存在过多少次,全部加起来就是;后面跟过的每一个词出现的次数,除以The unanimous一起存在的次数即可。
for w1_w2 in model:
total_count = float(sum(model[w1_w2].values()))
for w3 in model[w1_w2]:
model[w1_w2][w3] /= total_count比如我们要利用这个模型来计算in the之后应该跟什么词好呢?可以通过下面的结果来看。

仿造一个“chatgpt”,你能区分出来么
基于上文中的训练代码,可以尝试自己生成
英文
import random
# 这只是一个随机生成数据的代码
# starting words, 必须是训练数据中有的
text = ["in", "the"]
sentence_finished = False
while not sentence_finished:
r = random.random()
accumulator = .0
for word in model[tuple(text[-2:])].keys():
accumulator += model[tuple(text[-2:])][word]
if accumulator >= r:
text.append(word)
break
# 所谓<停止>标记符号
if text[-2:] == [None, None]:
sentence_finished = True
print (' '.join([t for t in text if t]))中文
# 训练代码如下
from nltk import bigrams, trigrams
from collections import Counter, defaultdict
import random
chinese_data = """之前看过一个段子,说电影院里面大家一开始都坐着看电影,此时有一个人站起来了,慢慢的所有人都站起来了,这就是内卷。我们看到所有人都不能舒服的坐着看电影了,这可能是因为某个人因为被前面的人挡住了,看不到,所以就站起来了。
如果说有100个人考试,只能录取10个。100人学习100天,每天8h学习,8h睡觉,2h吃饭,6h锻炼、玩耍等一切。由于100人学习效率不同,最终分数=效率*时间。那么在效率一定的情况下,就会有人开始延长学习时间,压缩其他时间。最终就变成了一场时间的游戏。就卷了起来。
或许有一名学习效率比较低的运动健将就被卷成了一位普通的大学生吧。也或许,这个学生本可以研发chatgpt,但他通过努力考上了某著名高校。大家都有光明的未来!
"""
model = defaultdict(lambda: defaultdict(lambda: 0))
model
n_gram_sents = chinese_data.strip().split()
# print(n_gram_sents)
# Count frequency of co-occurance
# 统计共现的频率。trigrams将sentence变成了三元组。举例来说,The unanimous一起存在的时候,Declaration出现的次数
for sentence in n_gram_sents:
for w1, w2, w3 in trigrams(sentence, pad_right=True, pad_left=True):
model[(w1, w2)][w3] += 1
# Let's transform the counts to probabilities
# 统计分母,举例来说,The unanimous一起存在过多少次,全部加起来就是;后面跟过的每一个词出现的次数,除以The unanimous一起存在的次数即可。
for w1_w2 in model:
total_count = float(sum(model[w1_w2].values()))
for w3 in model[w1_w2]:
model[w1_w2][w3] /= total_count
# 这只是一个随机生成数据的代码
# starting words, 必须是训练数据中有的
text = ["之", "前"]
sentence_finished = False
while not sentence_finished:
r = random.random()
accumulator = .0
for word in model[tuple(text[-2:])].keys():
accumulator += model[tuple(text[-2:])][word]
if accumulator >= r:
text.append(word)
break
# 所谓<停止>标记符号
if text[-2:] == [None, None]:
sentence_finished = True
print (''.join([t for t in text if t]))
神经语言模型
NPLM
https://jmlr.org/papers/volume3/bengio03a/bengio03a.pdf;
A Neural Probabilistic Language Model是bengio在03年左右提出的模型,其利用NN学习了概率语言模型,本身是在优化n-gram的学习问题:propose to fight the curse of dimensionality by learning a distributed representation for words。学习目标依然是给定前序序列预估当前单词。论文中特别提到了 Training such large models (with millions of parameters) within a reasonable time is itself a significant challenge。
从这个时候开始,神经网络逐渐进入了NLP任务的解决方案中。
其思路很简单,和上面提到的n-gram一致,只是引入了NN。由于NN这两年烂大街,所以细节大家都清楚,我们可以看一下基础的代码如何
import numpy as np
import pandas as pd
from keras.utils import to_categorical
from keras_preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import LSTM, Dense, GRU, Embedding
from keras.callbacks import EarlyStopping, ModelCheckpoint
import re
def text_cleaner(text):
# 小写
newString = text.lower()
# 去掉标点符合,仅保留26个字母
newString = re.sub("[^a-zA-Z]", " ", newString)
# 去掉太短的单词(〉=3
long_words=[]
# remove short word
for i in newString.split():
if len(i)>=3:
long_words.append(i)
return (" ".join(long_words)).strip()
# preprocess the text
data_new = text_cleaner(data_text)
# 建模方法,我们用30个char作为context,然后要求模型来预估下一个char
def create_seq(text):
length = 30
sequences = list()
for i in range(length, len(text)):
# select sequence of tokens
seq = text[i-length:i+1]
# store
sequences.append(seq)
print('Total Sequences: %d' % len(sequences))
return sequences
# create sequences
sequences = create_seq(data_new)
# 建立一个map,将char和idx关联起来
chars = sorted(list(set(data_new)))
mapping = dict((char, idx) for idx, char in enumerate(chars))
def encode_seq(seq):
encoded_sequence_list = list()
for line in seq:
# integer encode line
encoded_seq = [mapping[char] for char in line]
# store
encoded_sequence_list.append(encoded_seq)
return encoded_sequence_list
# encode the sequences
sequences = encode_seq(sequences)
# define model
model = Sequential()
model.add(Embedding(vocab, 50, input_length=30, trainable=True))
model.add(GRU(150, recurrent_dropout=0.1, dropout=0.1))
model.add(Dense(vocab, activation='softmax'))
print(model.summary())
# compile the model
model.compile(loss='categorical_crossentropy', metrics=['acc'], optimizer='adam')
# fit the model
model.fit(X_tr, y_tr, epochs=2, verbose=2, validation_data=(X_val, y_val))
# inference
# generate a sequence of characters with a language model
def generate_seq(model, mapping, seq_length, seed_text, n_chars):
input_text = seed_text
# generate a fixed number of characters
for _ in range(n_chars):
# encode the characters as integers
encoded = [mapping[char] for char in input_text]
# truncate sequences to a fixed length
encoded = pad_sequences([encoded], maxlen=seq_length, truncating='pre')
print(encoded)
# predict character
# yhat = model.predict_classes(encoded, verbose=1)
predict_x=model.predict(encoded)
yhat =np.argmax(predict_x,axis=1)
# reverse map integer to character
out_char = ''
for char, index in mapping.items():
if index == yhat:
out_char = char
break
# append to input
input_text += char
return input_text
input_string = 'large armis of'
print(len(input_string))
print(generate_seq(model, mapping, 30, input_string.lower(), 15))其实在这篇论文之前就已经出现了word的表示学习研究与利用NN进行LM的学习相关的工作,但是由于算力以及基于统计的NLP研究在当时取得的比较大的优势,也导致这方面的工作所起到的作用没有那么火热。
Word Embedding:
和上面的NPLM类似,只是将其中的word embedding作为重点抽了出来进行学习。不仅是基于上文预估next word,也开始想要基于上下文预估中间,或者基于中间预估上下文来更好的学习到一个word表示。
Word2vec: (Mikolov et al. 2013) is a framework for learning word vectors。2013年w2v火了之后,词向量的学习训练成为了当时NLPer的一个研究方向。
这个时候有一个特点,就是它在火中,但由于其仅仅可以作为一种分布式表示(训练手段),并不能直接对什么任务起到革命性的进展,且语言有其解释性的问题,所以还没有完全火起来,我想这个也是一种阻碍NN在NLP上的发展没有像图像那边发展那么快的原因吧。
此时词向量有一个特点,就是它是一个固定的词表,其学习方式主要还是一种基于上下文来获取一种对当前词的向量表示。
这个学习有一个问题,即希望用一个向量来表示一个词语的“意思”。所以人们就各显神通,觉得维度越高,数据越多,预估词语的时候借助的上下文越长(双向,RNN->LSTM->GRU etc.),自然这个向量可以表达的意思就越多。某种程度上是对的,但怎么才能在使用这个向量的时候让这个向量表达出一个恰当的意思呢?
ELMO
Deep contextualized word representation论文提出了ELMO(Embedding from Language Models)https://arxiv.org/abs/1802.05365 NAACL best paper
两阶段:预训练+finetune
ELMO的思想是:单词的we是提前学好的,但是在使用的时候不直接用这个we,而是根据目标单词的上下文来获取一个调整后的we。
训练的阶段在当前看来没什么特别,bi-LSTM训练。在具体使用的时候,没有直接使用查词表获取word vector来给下游任务使用,而是利用一个训练好的网络,freeze 参数,需要重新将句子输入到网络中,然后再输出最后的embedding(网络设计是多层,多层embeeding最后加权和,不同类型的embedding学习的内容不同)。基于这个embedding再输入到下游任务中。
这个工作其实和bert很相似,但是他没有用transformer,在特征提取上要弱。另外就是它在使用上不如bert那么立竿见影和清晰。看起来是词向量的进阶版,有点临门差一脚的意思。
ELMO和GPT相比Bert来说,其实各有千秋,但bert有非常关键的两个点:google出品 + 使用清晰方便。PR加上强大的生态一下子就讲bert的使用研究明白了,加上bert应对的偏判别的任务也是工业界和学术界热烈研究的,这也非常合理。
相对GPT擅长的生成任务,由于没有特别好的应用场景,就会吃亏了。
ELMO、GPT和Bert基本属于同期工作,被bert吊打之后,很多人也就不会关注另外两个了。
重要参考:
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 - 知乎
https://medium.com/analytics-vidhya/a-comprehensive-guide-to-build-your-own-language-model-in-python-5141b3917d6d
到这里为止可以说NLP-DL的“上一个时代”就结束了,因为后面出现的就是GPT和BERT系列的工作,他们会用到很多之前就提出的idea,主流的工作也是BERT的变种、trans的变种、bert的新应用。还有轻量化,zero/few-shot学习等。尽管基础的任务依然存在,但很多工作逐渐有陪跑的趋势。
OpenAI工作
从GPT3开始国内follow的趋势就开始下降
GPT系列
GPT1-3 Generative Pre-Training
GPT: Improving Language Understanding by Generative Pre-Training
GPT-2: Language Models are Unsupervised Multitask Learners
GPT-3: https://arxiv.org/pdf/2005.14165.pdf
GPT就是上述NPLM的一个进阶版,在网络模型设计上完全不同,这个细节这里忽略(大致就是下图,trans,LN,Multi-attention等),但学习目标一致。训练到使用采用两阶段,与bert完全一致。
它在下游任务应用的时候,和bert是一样的,都是将原始的model进行finetune,然后根据不同的下游任务进行输入输出(层)的构造。

GPT-2相比1的变化很小,见论文2.3最后几句话,在摘要中就这样说了一句话“These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations.” 表明了当前人类世界的资料只要足够,理论上就可以cover很多NLP的经典下游任务。相比1主要的改进点如下:
- 预训练阶段增加模型size,增加(高质量)数据规模:用更多的训练数据来做预训练,更大的模型,更多的参数,意味着更高的模型容量
- 二阶段:下游任务不需要finetune,直接预估。在部分任务上获得了SOTA。
“We demonstrate this approach shows potential by highlighting the ability of language models to perform a wide range of tasks in a zero-shot setting”
这里隐含的一个现象就是这个可以直接作为SAAS使用,下游不需要做任何改动和了解。这一点就预示了GPT-3和chatgpt的当前。
模型结构不是最重要的,重要的是其不断的努力就是想要这个成为一个服务。
GPT-3在2的模型架构不变的情况下,还是在不断的扩大模型大小,数据量以及数据多样性(除了参考了Sparse Transformer),同时重点探索了怎么才能更好的利用这个模型,在下游任务取得更好的结果。
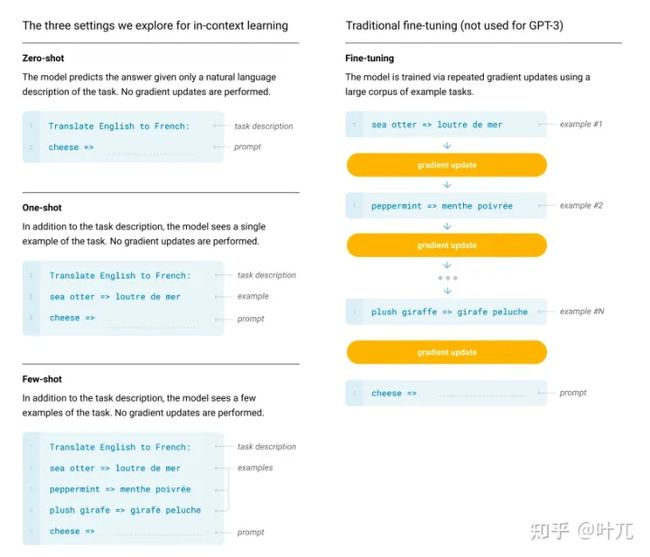
GPT3是一个非常大的实验报告,里面有详细的实验设置和在不同任务上的比较。尽管没有开源,但“理论上”我们知道它大体是怎么做的。
下面是两个非常棒的解读,不过里面有一点在当前看可以说GPT坚持AR是为了更好的生成结果,而不是没想到:
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 - 知乎 截止到bert
- 效果惊人的GPT 2.0模型:它告诉了我们什么 - 知乎 对GPT-2
Instruct-GPT
本文主要解决的是一个模型输出与人类期望之间不匹配的问题,解决方法则是将人类的反馈引入到模型训练中,并基于用户给的反馈训练一个reward模型来降低对数据的需求,提升可行性。所谓的instruct主要指的就是人类给出的反馈。
“ For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users.

- 基于现有数据,训练得到GPT-3;然后利用已经开放的API中收集到的prompt data中的一部分,加上人工生成想要的输出结果,对GPT3进行finetune。
- 让模型基于给定的prompt输出一堆结果,让人类对结果进行排序,然后训练一个reward model,学习知道什么样的结果是好的。其作用是对prompt和output这样的组合进行打分,找到和prompt最契合的结果。
- 最后,继续利用prompt中的数据,让GPT3生成答案,对应让RM进行打分,接着基于PPO对GPT3进行优化。
PPO:强化学习之PPO算法 - 知乎
Google工作
从T5开始,国内follow的趋势就开始下降。这里列一下经典工作以及影响。
Transformer
基于seq2seq的框架,引入transformer这个特征提取器(直到现在依然dominate),在NMT上取到SOTA。
BERT
基于trans,(或许也有elmo和gpt,毕竟时间差不多,不好说),仅使用encoder部分,进行自监督学习,以pretrain+finetune霸榜。与elmo典型的不同在于其整个网络架构都可以被直接用到下游任务,仅仅为不同的下游任务设计输出层或者简单的调整最后输出的计算即可,对于使用者来说更简单了。
由于Bert本身不是学习的LM(aka Auto-regressive LM),而是MLM,所以在生成任务上不适用。
自bert出现之后,对具体的下游任务的理解和构建就变得比网络结构重要了。网络改一改,不是在构造finetune数据集或者在输出层部分(或者怎么利用bert的输出)研究一下就可以取得很大的进步。
至于模型轻量化等工作也是自bert之后很火热。
T5
google希望可以用一套架构来统一所有的NLP任务,发现只要在模型的输入端,即在encoder的时候加上“任务提示”,就可以在decoder的时候得到不同的结果。这样就将所有的NLP任务统一起来了。这里要说明即便没有使用en-de,使用普通的ARLM或者prefixLM也是一样的操作方式。
本文的目的是使用一个模型解决所有问题,即所谓通用语言学习能力,测试如下下游任务的性能:
- 文本分类:GLUE & SuperGLUE,是测试通用语言理解能力的文本分类任务的集合,包括句子可接受性判断、情绪分析、释义/句子相似度、自然语言推断、指代消解、完成句子、词义消歧和问题回答。
- 机器翻译:WMT English to German, French, and Romanian translation
- 文本摘要:CNN/Daily Mail abstractive summarization
- 智能问答:SQuAD question answering
为了在上述各种任务上训练单个模型,需要在所有任务上保持一致的输入和输出格式,所以其在构建任务的时候做了额外的设计工作,也是从这里开始,NLP逐渐进入了一个模型打天下的时代。
这个工作和GPT2很相似,都是基于一个统一的模型和框架来解决所有问题。但其缺点在于效果相比bert没有飞跃成长,且刚出来的时候仅有英文模型,所以在国内不够流行。
BTW,从现在回头看,T5这样的工作某种意义上也是肯定了GPT系列的发展方向。
Prompt
基于Bert的流行,类似T5,我们有一个趋势,利用对下游任务的合理构造来激发bert的潜力。比如,如果是一个文本情感分类任务,输入:我喜欢电影,因为这个电影();可以让模型预估这里是好/不好这样的单词来利用模型。
这个介绍比较好:NLP新宠——浅谈Prompt的前世今生 - 知乎
前两年有一些研究怎么进行prompt智能生成的,还有说NLP工程师可以转成Prompt编写师。从我个人角度看,prompt和之前我们做数据增强的手段比较类似,算是提升任务效果的捷径吧,感觉研究意义还不如数据增强。
BUT,这个玩意儿有一个很重要的意义,就是在chatgpt的训练/使用中,我们会发现有一定的prompt进入了训练,在使用中基于适当的prompt会有更好的效果。所以这个或许也会成为chatgpt发展的关键。
LLM:BERT VS chatgpt
随着BERT的出现,我们有了LLM的概念。以前的时候,我们认为一个模型针对一个领域进行训练,可以成为这个领域内的专家,可以解决特定问题。
后来我们发现,单用这些领域内的知识来解决问题有时候不够。为了解决一个问题,有时候往往需要多个领域的知识。那么我们对领域的界定就会变得模糊而不清晰,甚至做扩大。随着不断扩大,就有了所谓通用大模型的意义,现在很多基于bert的微调就是这样的。
bert的做法就是,让模型finetune之后专注于某个特定任务。此时参数会有部分更新,来更加适应这个任务——某种意义上就丢失了一部分在其他任务上的泛化能力。
chatgpt的做法是,让模型的知识应用到某个领域,并不计划让模型因为任务的改变而改变,这样的优点就是保留了模型的全量知识,坏处则是要在某个领域上达到和bert一样的水平,需要更多的资源。(通才和专才,很好理解)
所以重点是这样的:
- 一个模型搞定一切任务,且效果会比单模型更好
- 模型要很大,所以得搞明白具体怎么才能跑起这样的任务来
- 数据要多且高质量
- 模型可以直接用于各种下游任务:最后,在使用的时候,few-shot给出的效果理论上会更好一点,但zero-shot也可以,总之这个模型是可以用来直接使用的,可以不经过finetune
Chat
介绍chat还是为了理解chatgpt,简单说吧,这个部分暂时不会对chatgpt的理解有太大的影响。
技术分类:
- pipeline形式:以rasa为代表
- end2end形式:当前的chatgpt
对话形式:
- 单轮:即问答,QA类型
- 多轮:可以基于之前的回答,进行当前的回答
任务类型
- Task-oriented
- Open domain
chatgpt当前我们看来可以定义为是一个多轮对话的end2end open domain对话系统。
CHATGPT
YannleCun twitter表示说chatgpt用的是既有技术的拼接组合,没有什么新奇的创新。但他认为是非常成功的工程设计和实现。
这个我的观点是他还是站在了比较high-lvl的视角来审视了这个工作,在Danqi Chen的博士毕业论文里面,有详细的描述过为了拿到一份高质量的标注数据,她是如何设计机制以获取相对置信的结果。同样的,在chatgpt这个工作上,首先将已经发表过的多个工作进行重新设计组合以实现以前没有人实现的点或者性能突破本身也是合理的,就像transformer出现之后就可以被用到多个问题领域;其次,从2003年NPLM开始,几乎每个论文都会讲到如何进行大规模的模型训练,尽量在成本可控制的情况下,即要有成功的设计且还要在可控成本下成功的执行,在当前的NLP-LLM上本身也是很难的工作(参考albert和Roberta,二者都是通过了合理的设计从而使模型可以变得更大)
从blog上看技术点如下:
- 基于instruct-GPT进行的训练,Reinforcement Learning from Human Feedback (RLHF)
- 数据收集上有所不同,blog说到将数据整理为了dialogue format.
除此以外,我们并不知道其他的消息。
尽管,从paper/blog上看,openai已经告诉了我们应该怎么做,但由于当前的工作在复现上成本很高,不确定性大,但收益却并不明显。还是很困难的。