独家 | Bamboolib:你所见过的最有用的Python库之一(附链接)

作者:Ismael Araujo
翻译:王可汗
校对:欧阳锦
本文约3200字,建议阅读5分钟
本文介绍了Python数据分析的一个利器——Bamboolib,它无需编码技能,能够自动生成pandas代码。
由Andrea Piacquadio拍摄,来源:Pexels
下面是我对这个很酷的Python库的看法,以及为什么你应该尝试一下。
我喜欢写关于Python库的文章。如果你读过我的博客,你可能知道我写过很多关于库的文章。在写之前,我测试了一些Python库,检查了它们最显著的特性,如果愿意,我还会写一些关于它们的内容。通常,我尝试在同一个博客中包含几个库来充实博客。然而,我偶尔会发现一些很酷的库,它们值得拥有自己的博客。Bamboolib就是这种库!
Bamboolib是那种会让你想:我以前怎么不知道这些?是啊,听起来有点夸张,但相信我,你会大吃一惊的。Bamboolib可以为需要一段时间才能编写的内容构建代码,比如复杂的按子句分组。让我们开始吧,因为我非常兴奋地向你们展示它是如何工作的。
Bamboolib -为初学者和专业人士
Bamboolib的卖点是,任何人都可以用Python做数据分析,而不必成为程序员或搜索语法。根据我的测试,这是真的!它不需要任何编码技能。我看到对于时间紧迫的人或者不想为简单任务输入长代码的人来说,它是多么方便。我还可以看到学习Python的人如何利用它。例如,如果您想学习如何在Python中做一些事情,您可以使用Bamboolib,检查它生成的代码,并从中学习。
不管怎样,让我们来探索一下如何使用它,你可以决定它是否对你有帮助。让我们开始吧!
安装
安装Bamboolib很简单。我在这个博客中介绍了不同的安装方法,展示了如何在安装Bamboolib之前创建一个环境。如果你没有心情创建一个新环境,你可以在你的终端中输入pipinstall upgrade bamboolib user,它会工作得很好。现在你可以通过输入importbamboolib as bam将它导入到一个Jupyter Notebook中,我们就可以开始了。现在,我们需要一个数据集。我将使用All Video Games Sales 数据集,因为它看起来很有趣,但你可以使用任何你喜欢的。下载了数据集之后,让我们导入它,然后我们就可以开始使用Bamboolib了。
第一步
还记得我说过Bamboolib不需要编码吗?我是认真的。要将数据集导入到您的Jupyter Notebook,键入bam,它将显示一个UI,您可以在其中单击三次即可导入数据集。
Type bam > Read CSV file> Navigate to your file > Choose the file name > Open CSV file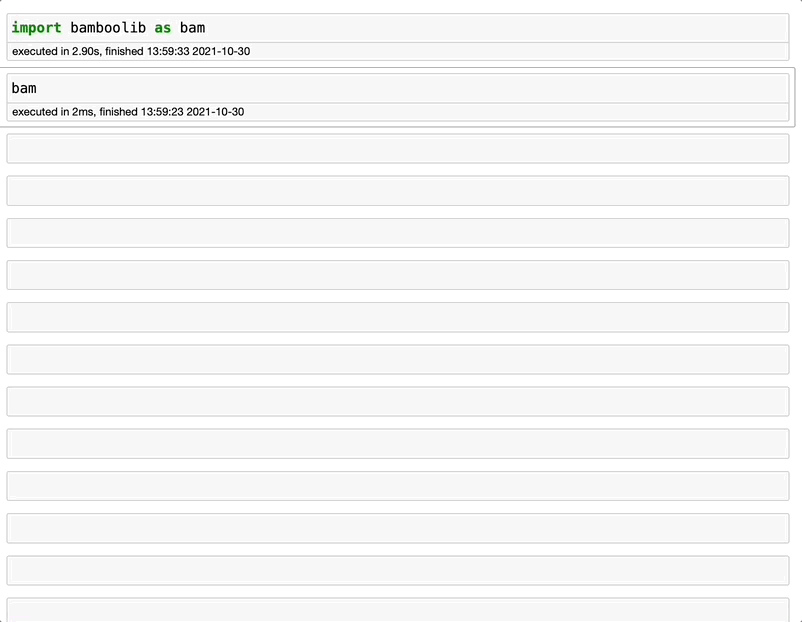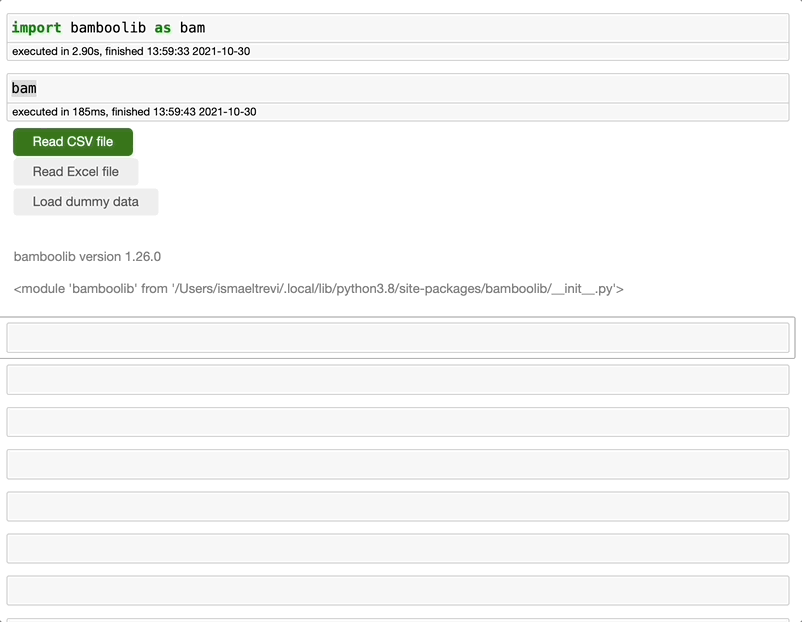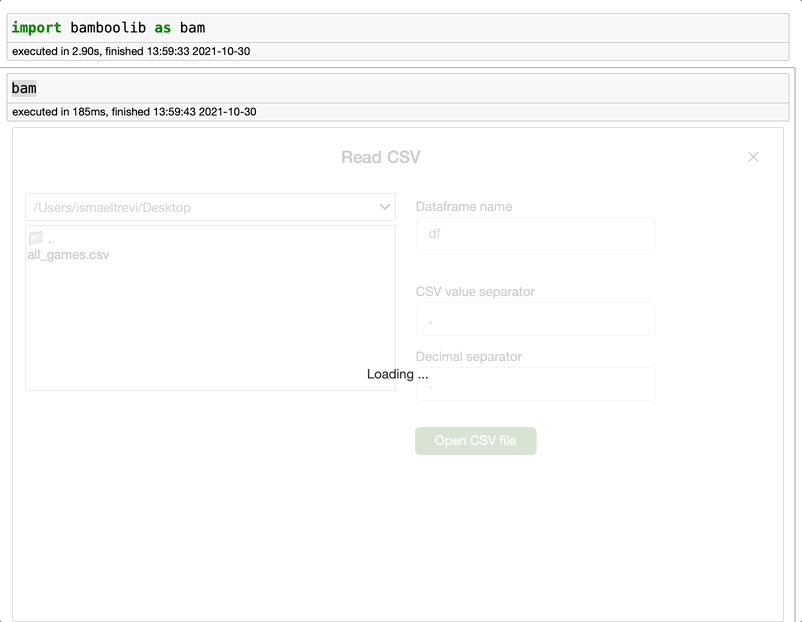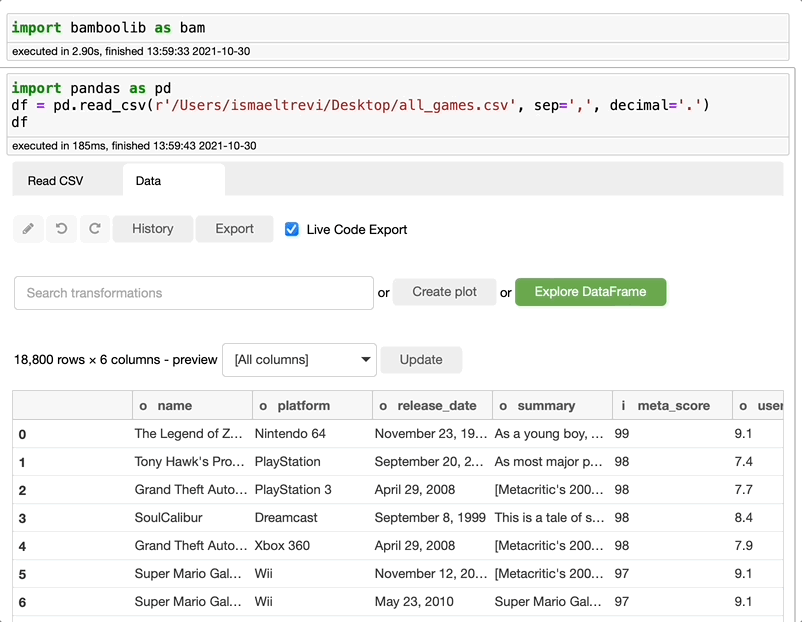
注意,Bamboolib导入了Pandas并为您创建了代码。是的,整个项目都是这样的。
数据准备
将字符串更改为datetime
您加载了数据,并意识到日期列是一个字符串。然后,单击列类型(列名称旁边的小字母),选择新的数据类型和格式,如果需要的话,可以选择一个新的名称,然后单击执行。
您是否看到单元格中也添加了更多代码?
另外,user_review列似乎是一个对象。让我们通过创建一个整数来解决这个问题。
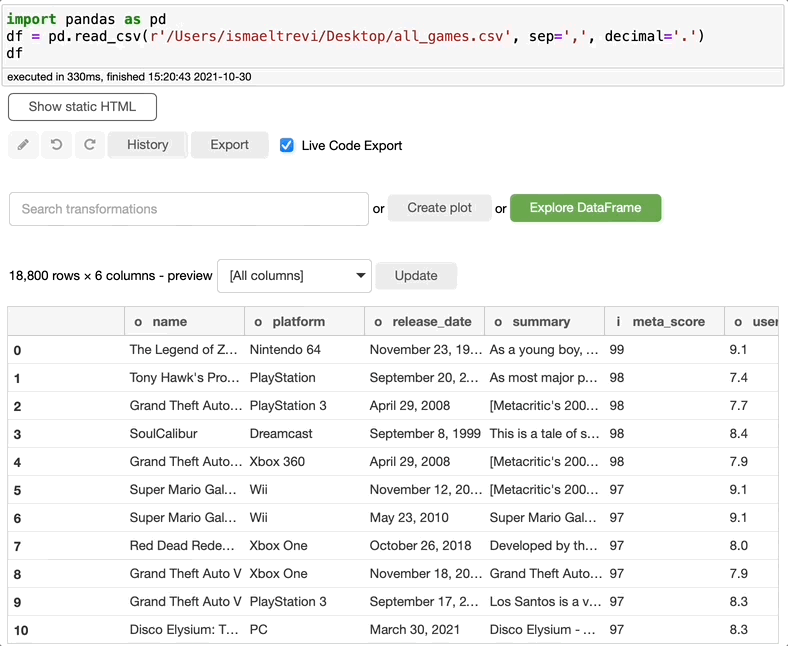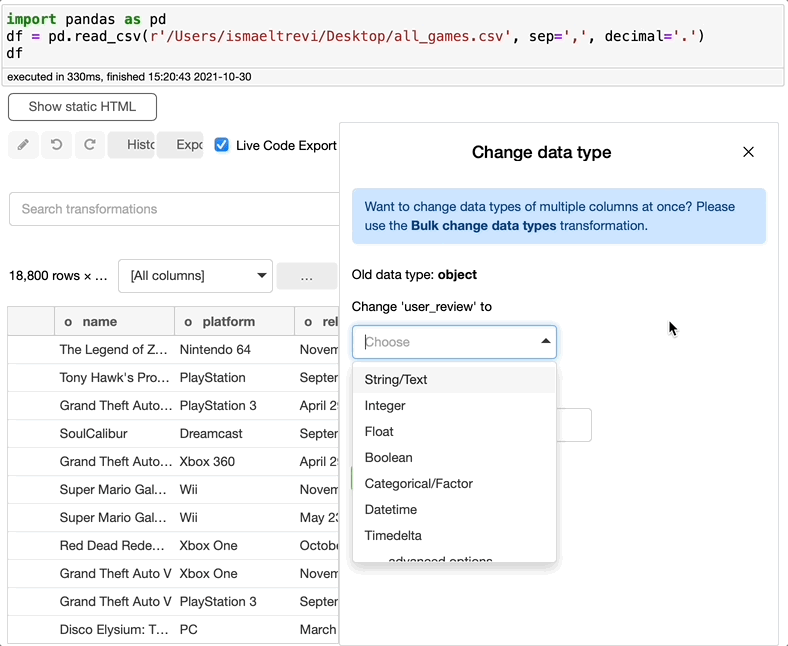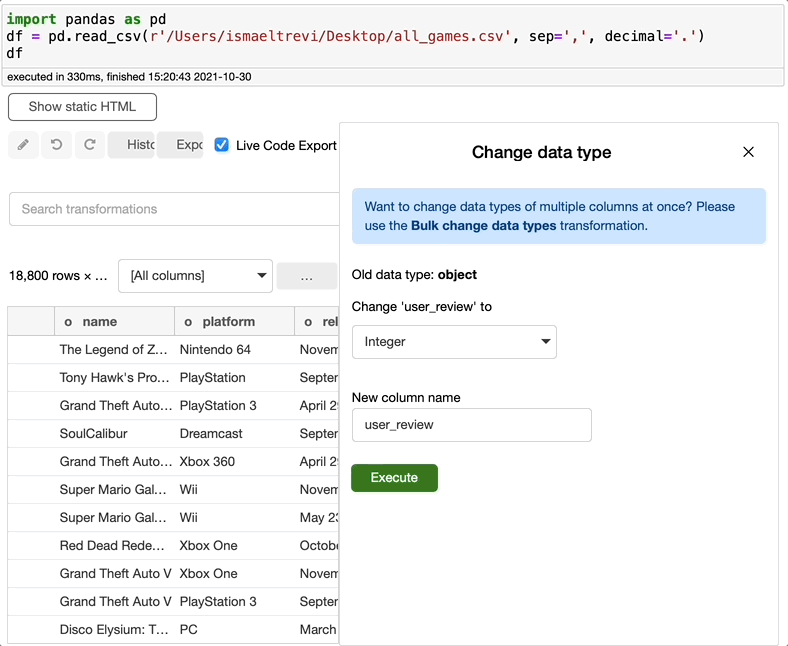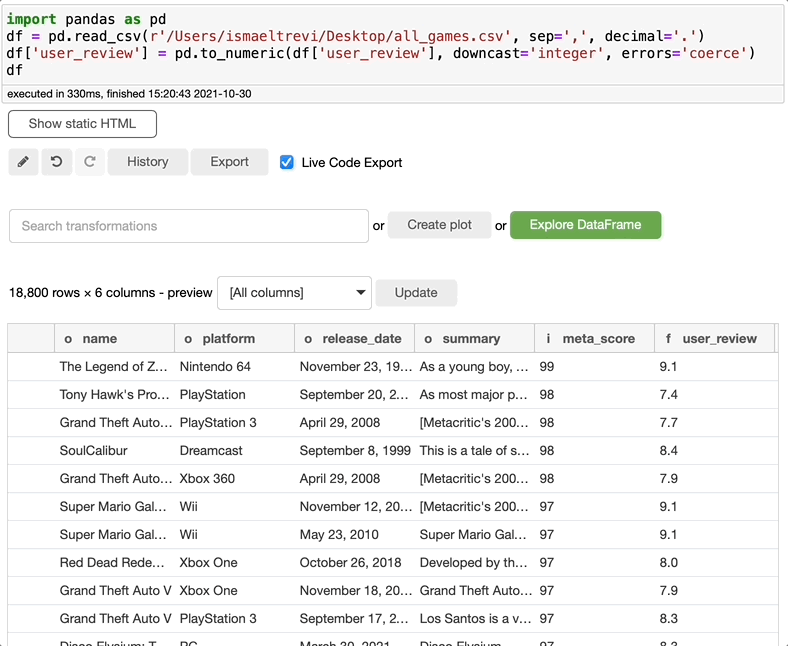
记得我说过列名旁边的小字母是列数据类型吗?如果你看旁边的字母user_review列名,你会看到一个作为整数的f而不是i,即使我改变了数据类型为整数。这是因为Bamboolib将数据类型理解为float,所以它没有抛出错误,而是为您修复了错误。
使用不同的数据类型和名称创建新列
如果您需要一个具有不同数据类型和名称的新列,而不是更改列的数据类型和名称,该怎么办?只需单击列数据类型,选择新的格式和名称,然后单击执行即可。您将立即在数据集中看到新列。
在下图中,我选择了meta_score列,将数据类型更改为float,选择了一个新名称,新列就创建了。
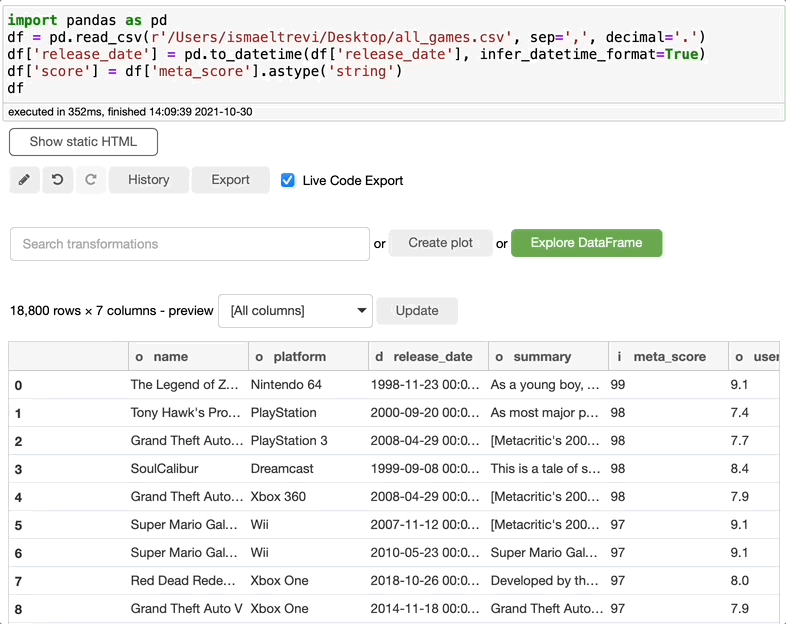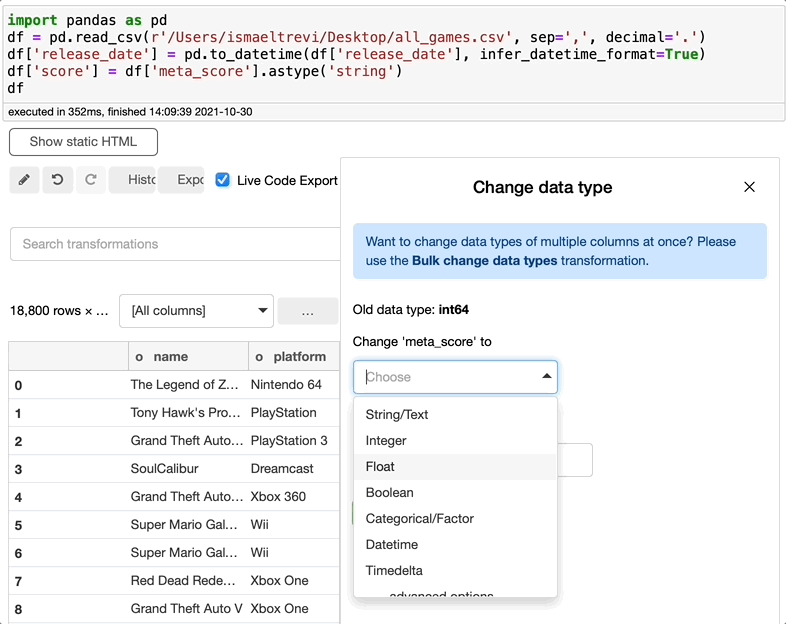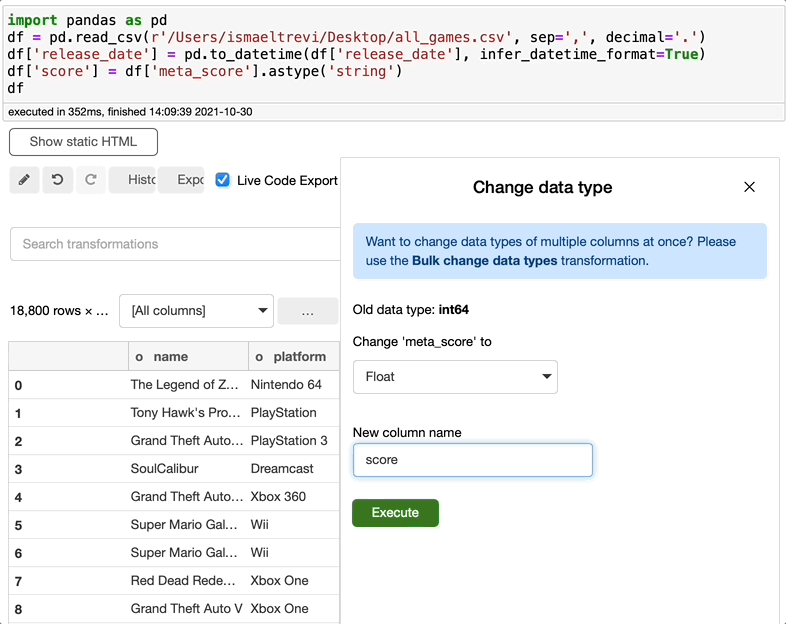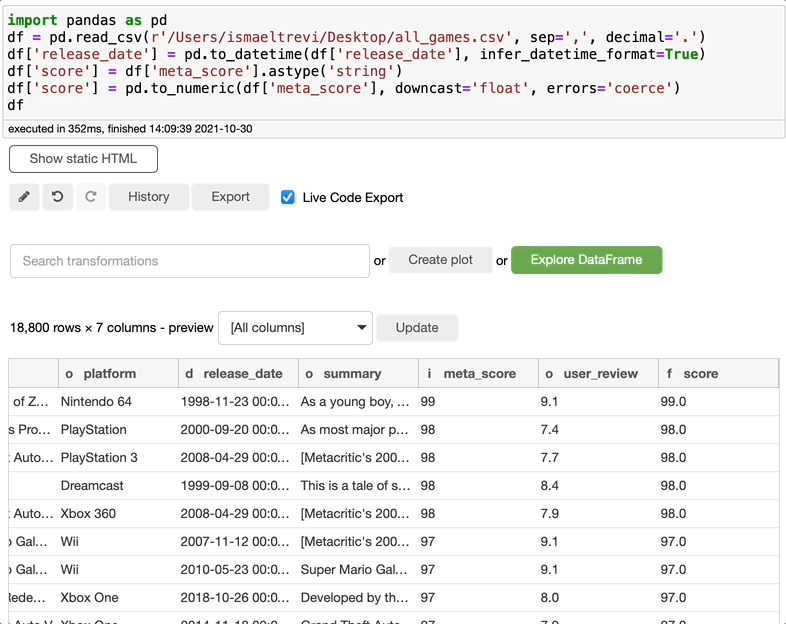
删除列
如果您意识到不需要列,只需在search转换框中搜索下拉,选择下拉,选择想要下拉的列,然后单击执行。
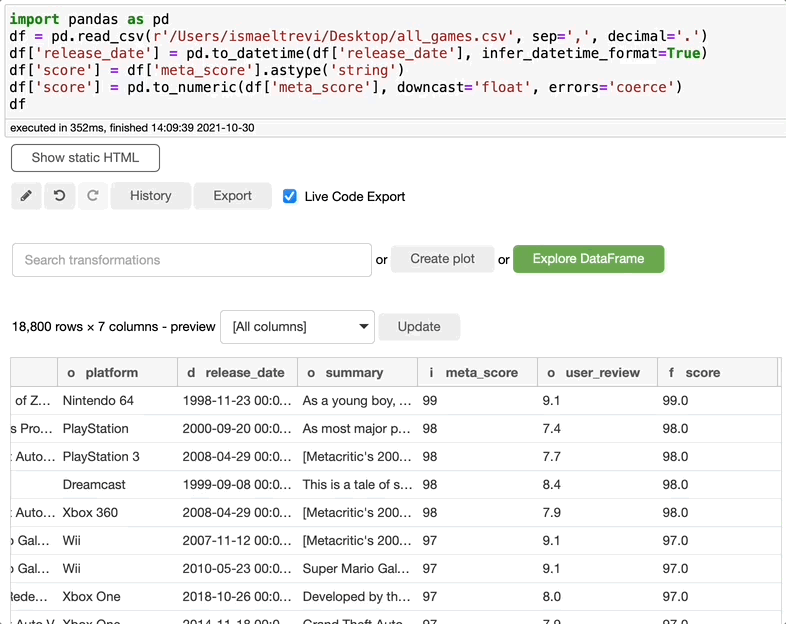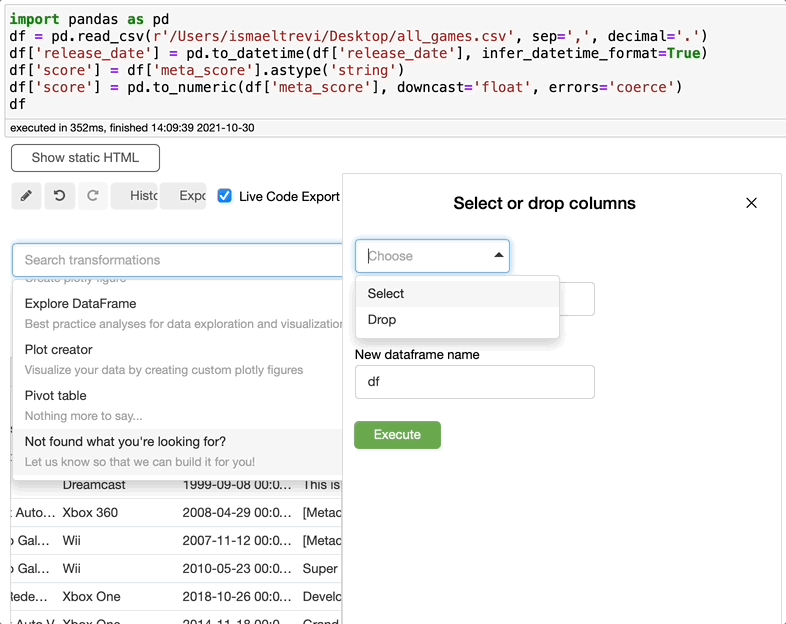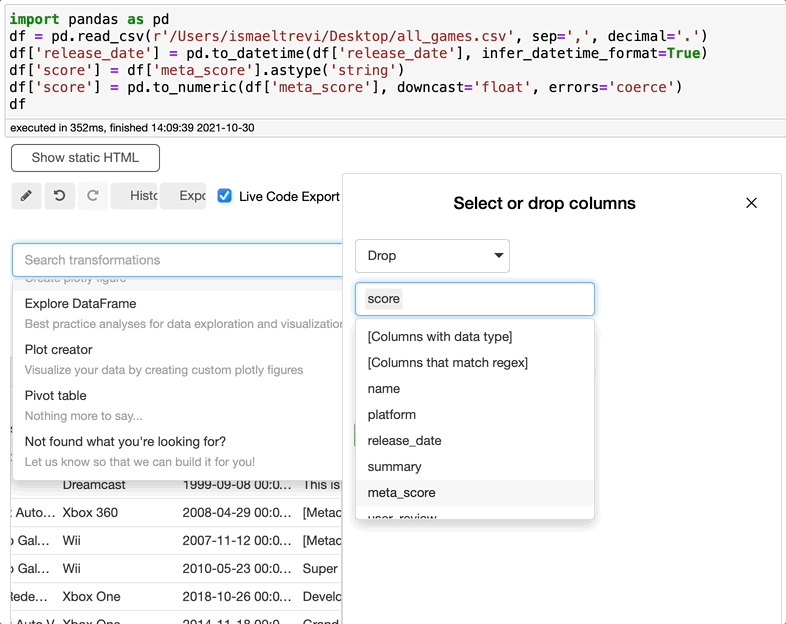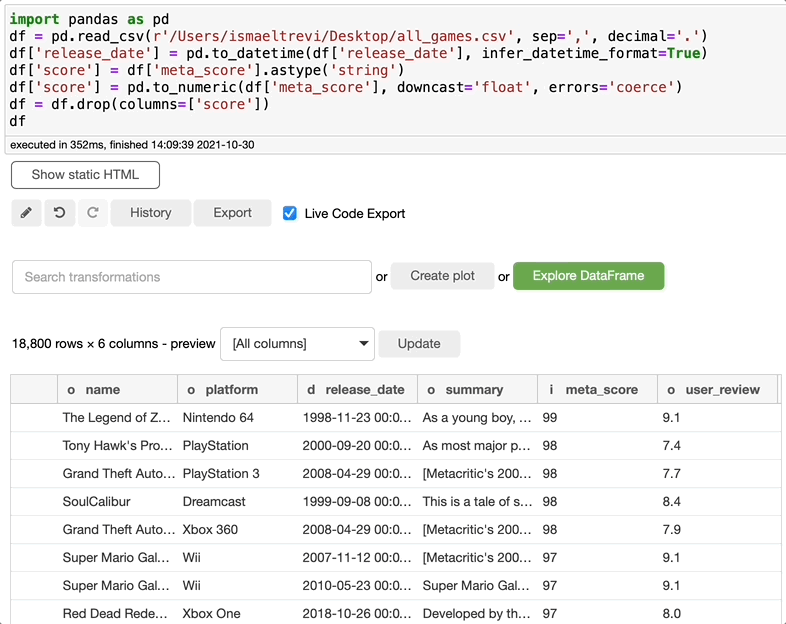
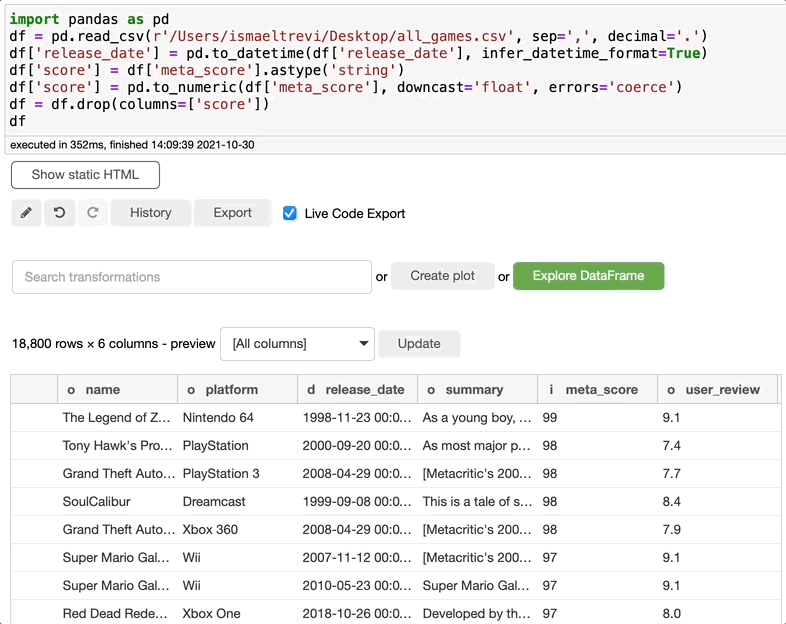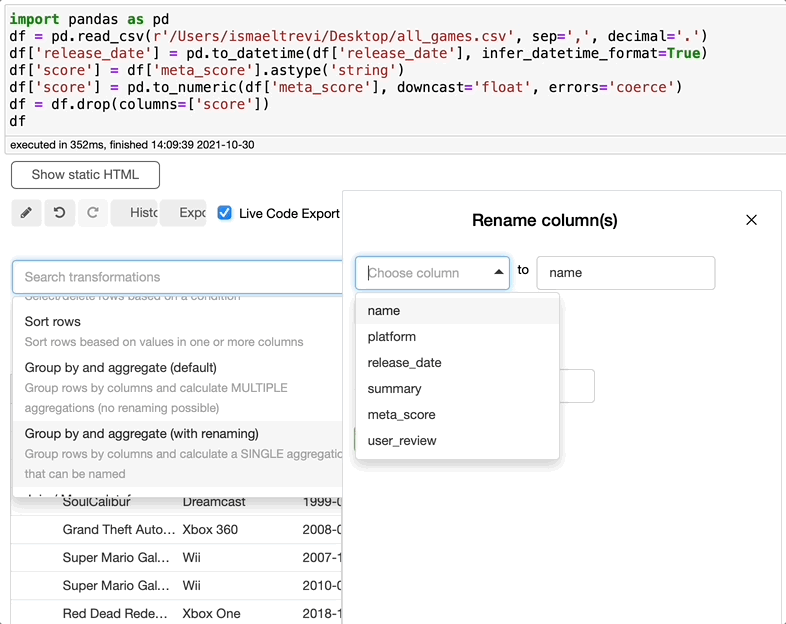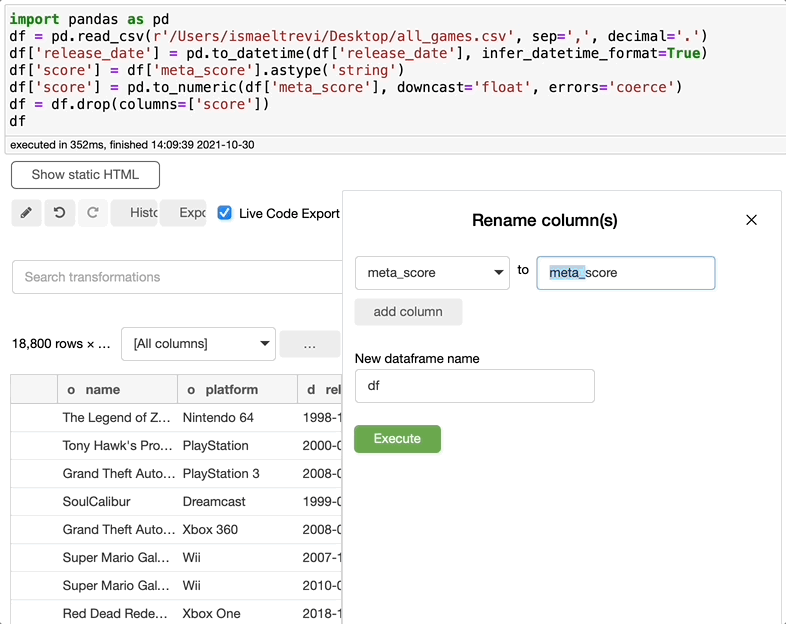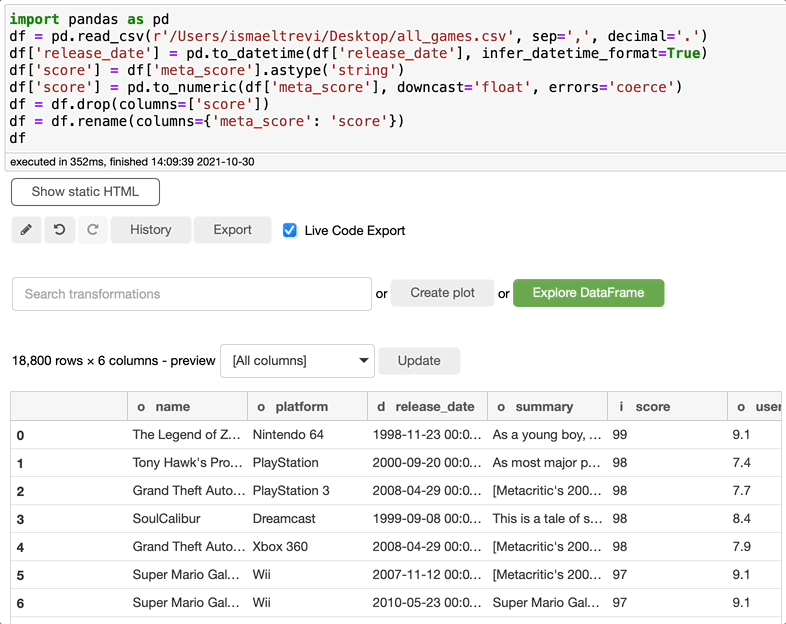
重命名列
现在您需要重命名列,这是再容易不过的了。只需搜索rename,选择要重命名的列,写入新的列名,然后单击执行。您可以选择任意多的列。
将一个字符串分割
假设您需要将一列人的名字分成两列,一列写名,另一列写姓。这很容易做到。出于演示的目的,我将游戏名称分割开来,这并没有什么意义,但你可以看到它是如何工作的。
只需在Search转换框中键入split,选择要分割的列、分隔符和你想要的列数的最大值。Boom!
由于这只是一个演示,让我们删除额外的列。搜索删除,选择要删除的列,然后单击“执行”。(您可在原文查看动图)
选择列
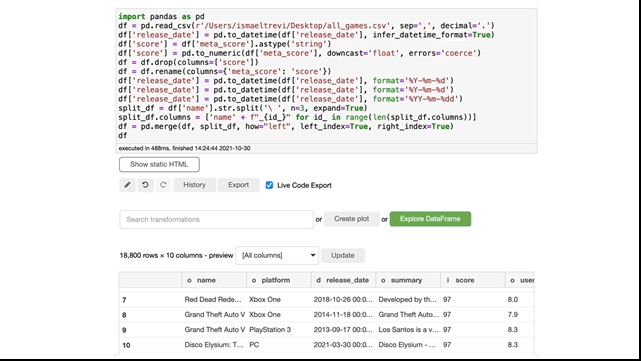
然后,我们可以选择只可视化一些列。在这里我将选择游戏名称、平台和分数。只需在Search转换框中键入select,选择要选择并执行的列。
在这些步骤的最后,Bamboolib创建了以下代码,即使没有安装Bamboolib,也可以使用这些代码。很酷,对吧?
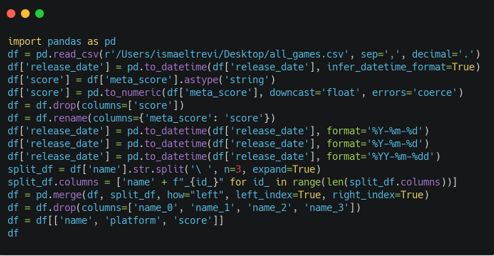
图源自作者
数据转换
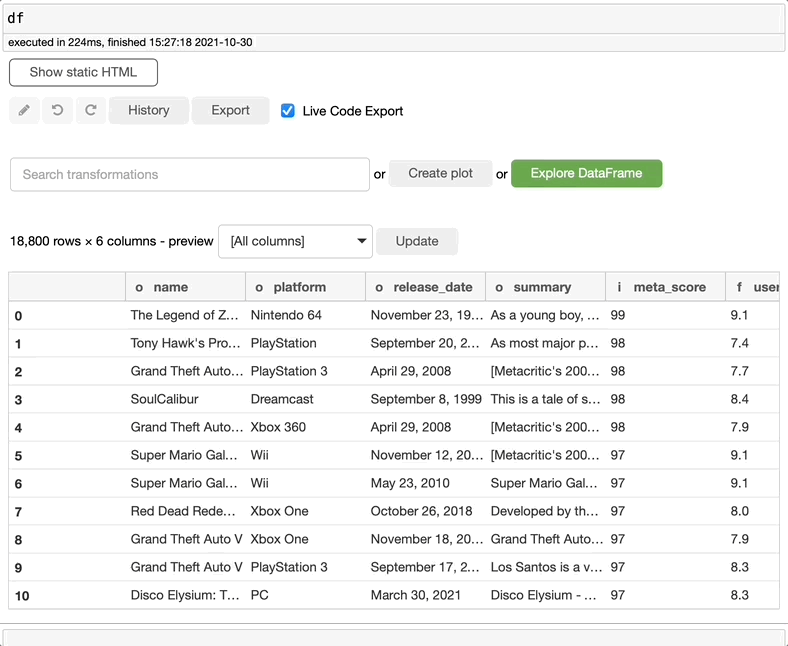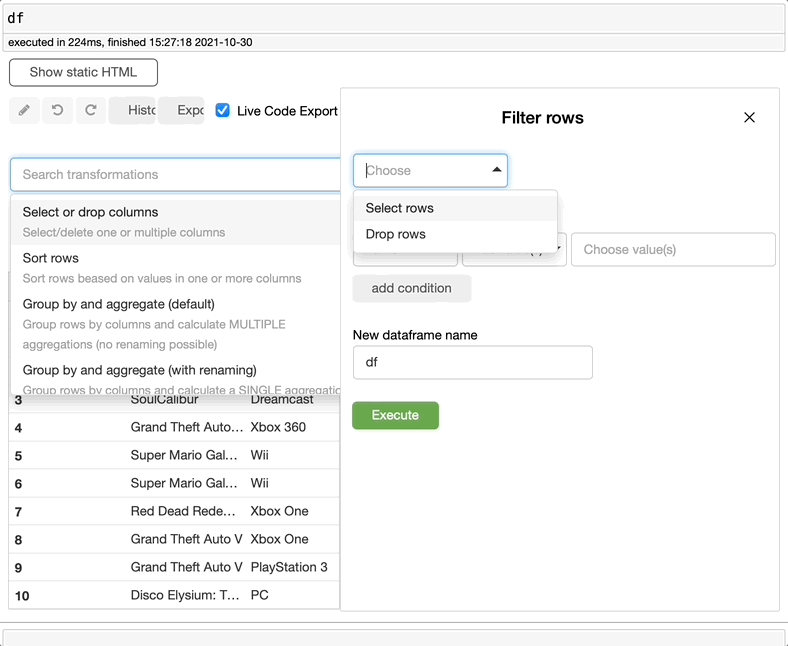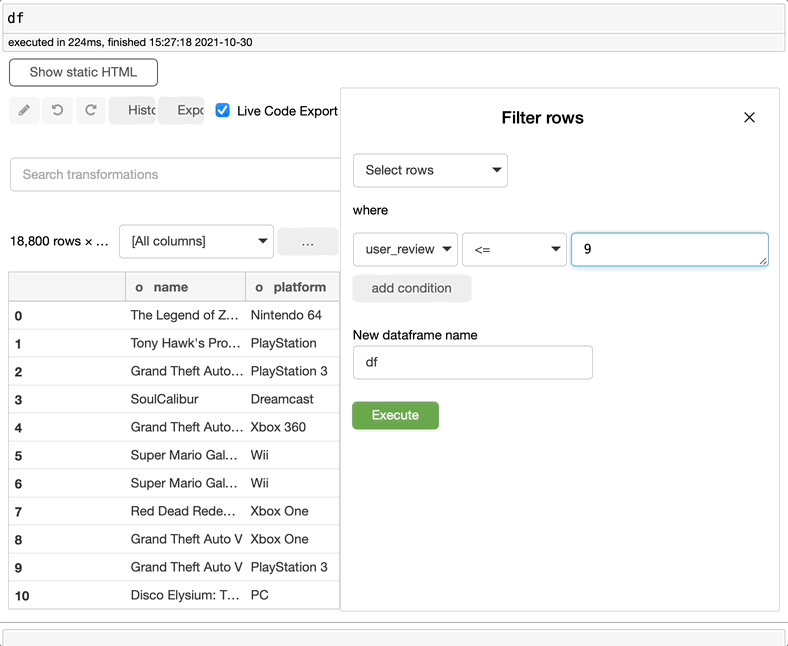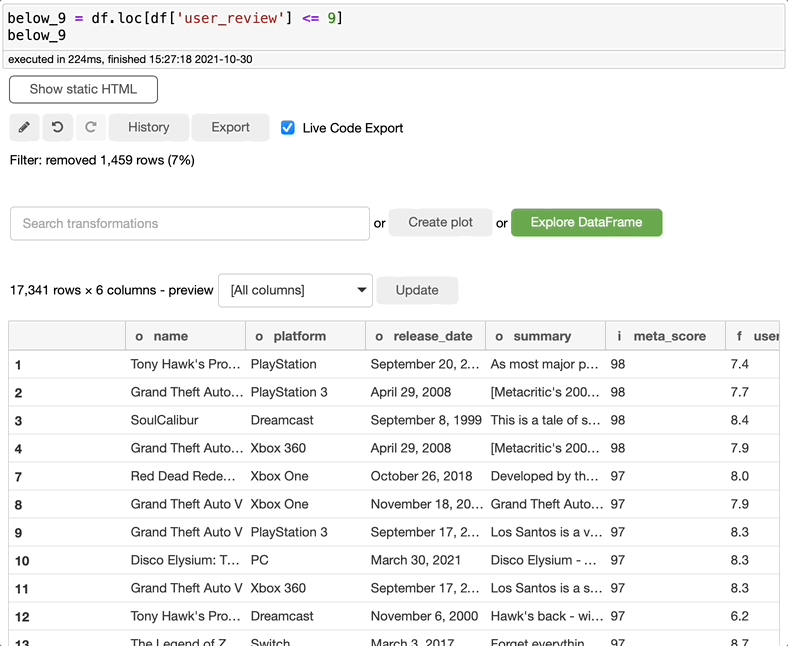
过滤数据
如果想要筛选数据集或创建一个带有筛选信息的新数据集,可以在search转换中搜索filter,选择想要筛选的内容,决定是否要创建新数据集,然后单击execute。这么简单!
合并数据
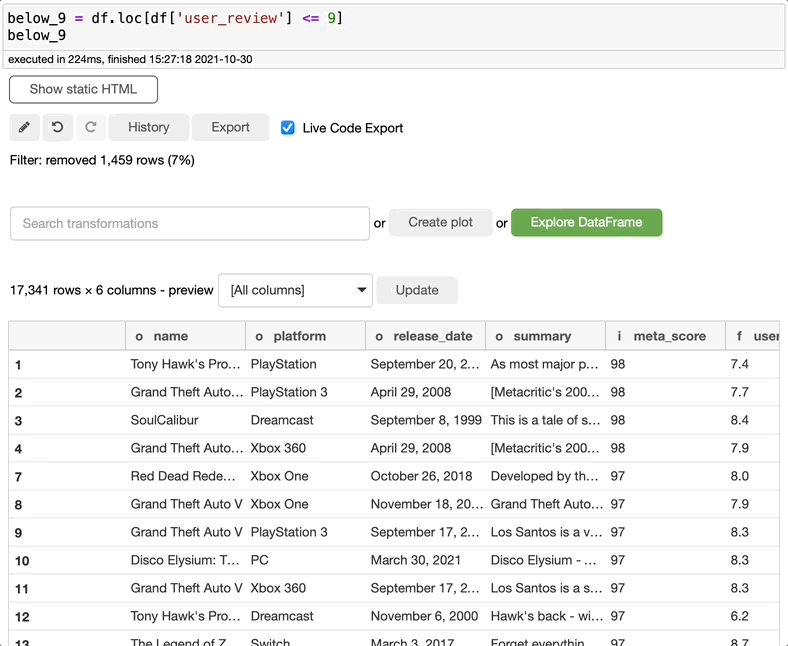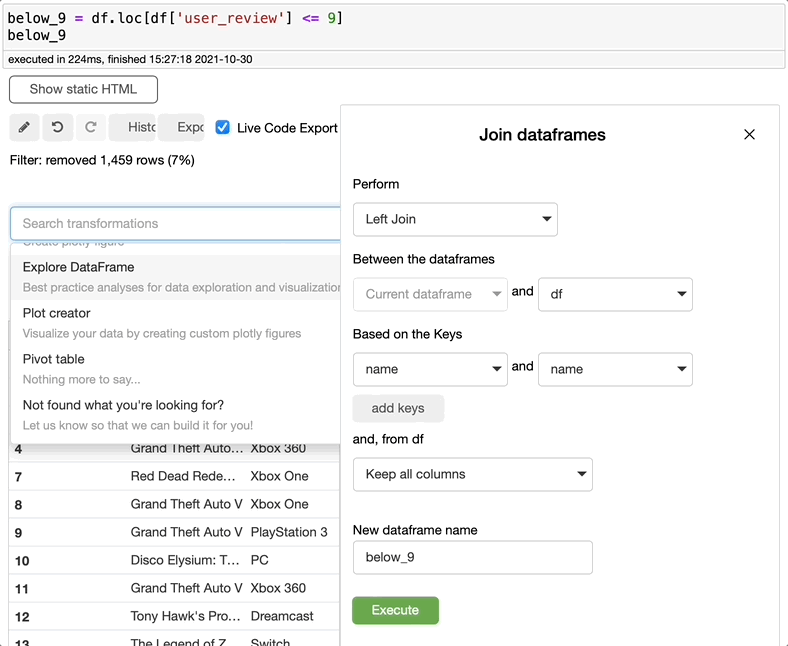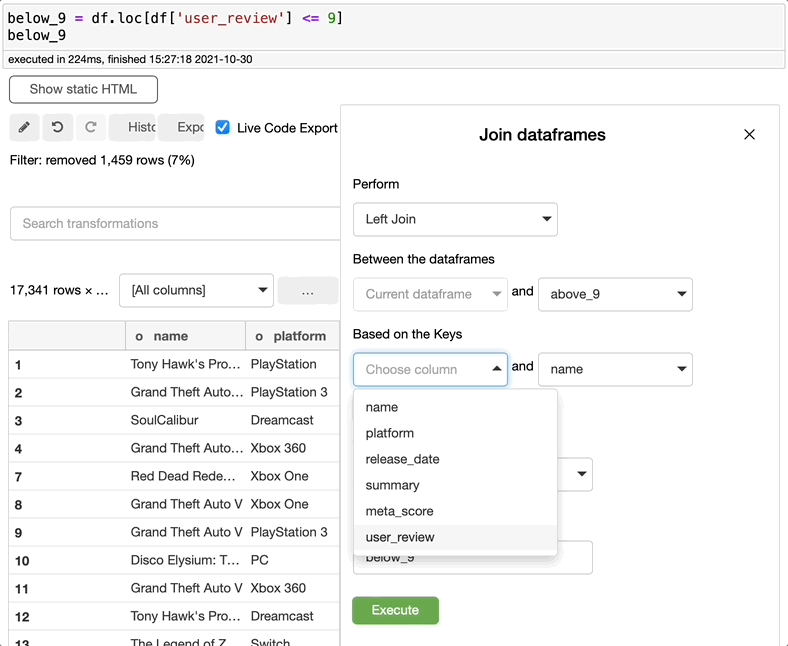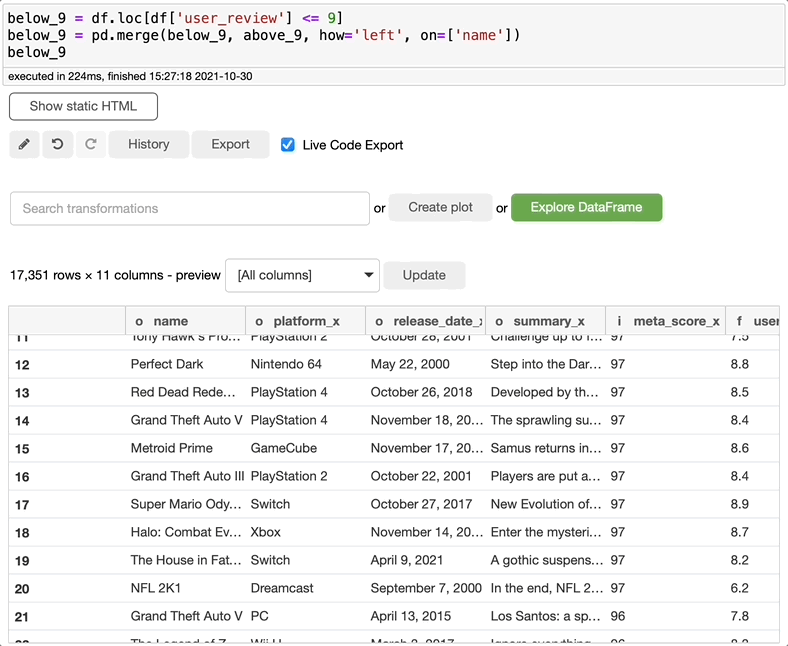
如果您需要合并两个数据集,只需搜索合并,选择要合并的两个数据集、连接的类型,和要用于合并数据集的关键列,然后单击执行。您可以创建一个新的数据集或仅仅编辑当前的数据集。
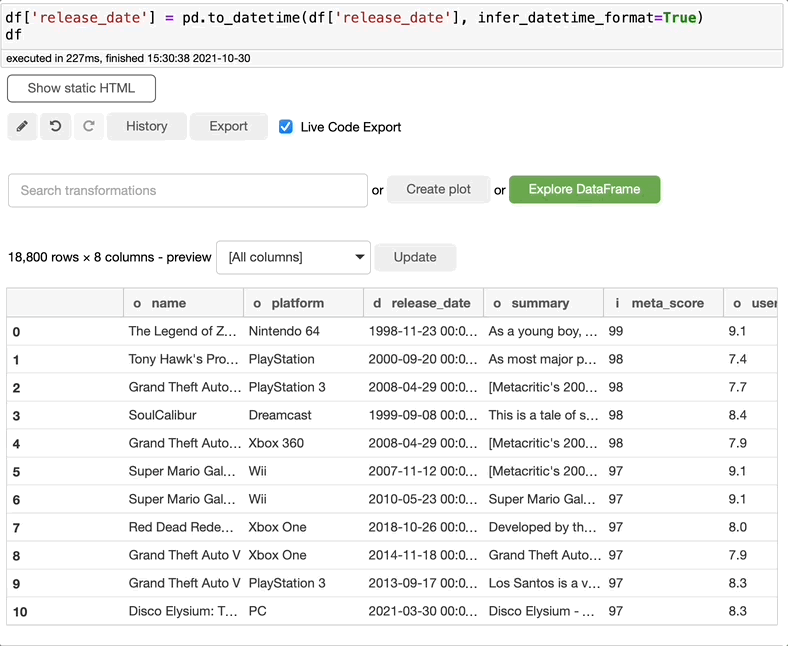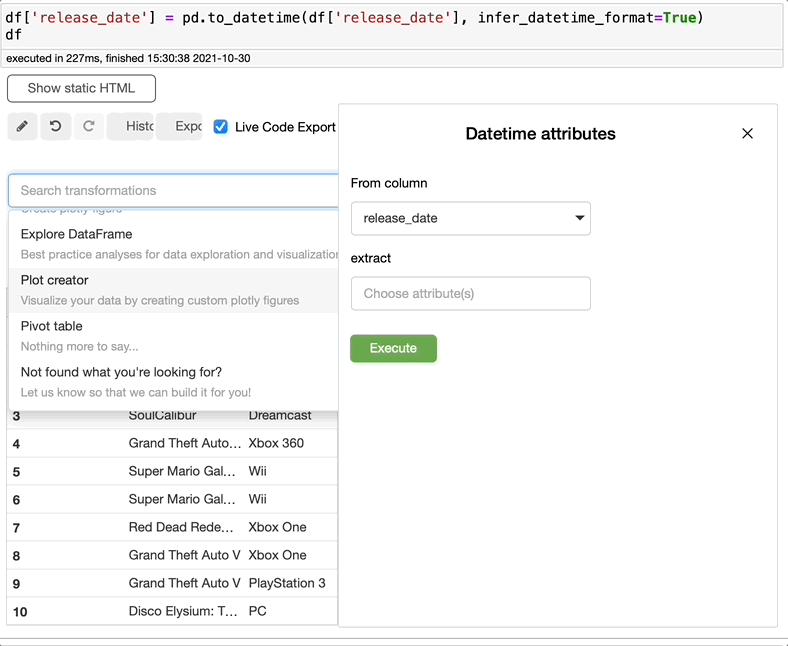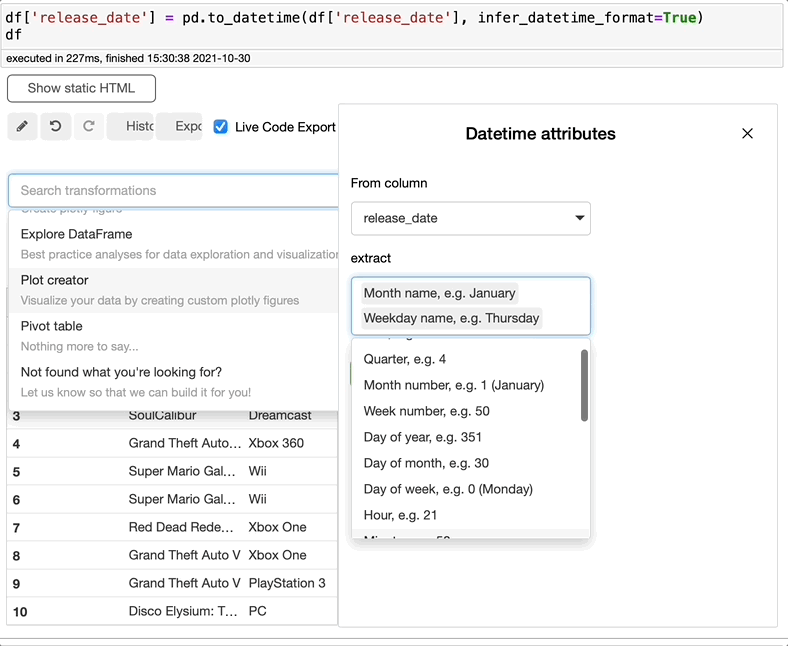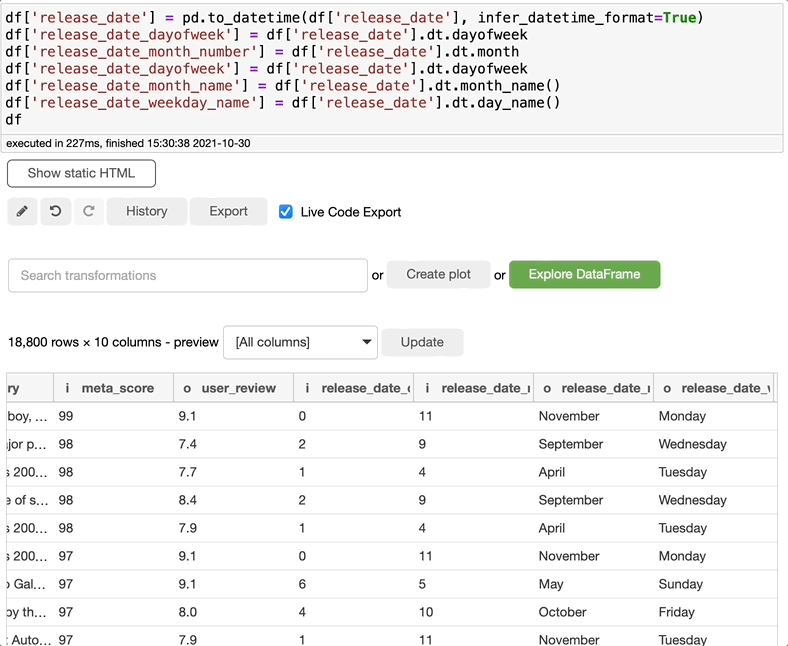
提取datetime属性
如果您想从日期列中提取一个字符串,比如星期和月份,您知道代码吗,还是必须谷歌一下?有了BambooLib,这两种都不需要。只需搜索extract datatime属性,选择日期列,并选择要提取的内容。
有多个选项供您选择。我必须承认,我不知道如何做到这一点,或者使用“Pandas”是否有可能做到这一点……我刚刚学到了一些新东西。
分组
使用group by是你可以用Pandas做的最有价值的事情之一。然而,它有时会变得非常复杂。幸运的是,Bamboolib可以通过非常直观和简单的方式制作群组。在Search转换框中搜索分组by,选择要分组的列,然后选择要查看的计算。
在这个例子中,我希望看到每个平台上的游戏数量和平均分数。我发现PlayStation 4在所有平台中得分最低。(您可在原文查看动图)
数据可视化
Bamboolib是一个创建快速数据可视化的伟大工具。例如,要创建直方图,单击create plot,选择图形类型、x轴,就差不多了。您只需点击四次就创建了一个漂亮的图表。()
或者你可以创建一个箱形图。过程是非常相似的。很简单!
有许多其他类型的图表可供探索,但所有游戏数据集并不是创造图表的最佳选择。不过,您可以使用其他数据集以测试此功能。有很多东西需要探索。
数据探索
Bamboolib使数据探索超级简单。您可以从Bamboolib中获得灵感,Bamboolib使得数据探索变得超级简单。仅仅通过点击,您就可以从您的数据集得到灵感。这很容易实现:单击Explore DataFrame,它将返回一些信息,如具有平均值、中位数、四分位数、标准偏差、观测值数量、缺失值、正负观测值的数量等统计信息。它还创建了图表,以便您能够理解数据分布。如果数据集中有DateTime数据类型,它还可以创建图表,显示数据在一段时间内如何更改。因此,与其浪费时间创建单独的图表来理解数据集,还不如使用这个功能来了解数据集。(您可在原文查看动图)
结束语
唷!我现在很满意,因为我给予了这个库应得的关注。是的,我知道这不是第一个关于Bamboolib的博客,但我想谈谈我的看法。还有很多东西需要探索。
Bamboolib有很大的潜力来改变我们分析数据的方式和我们学习的方式。我已经用Pandas好几年了,我学到了用Bamboolib可以做的新东西。感谢阅读,下一篇博客见。
原文标题:
Bamboolib:One of the Most Useful Python Libraries You Have Ever Seen
原文链接:
https://towardsdatascience.com/bamboolib-one-of-the-most-useful-python-libraries-you-have-ever-seen-6ce331685bb7
编辑:王菁
校对:林亦霖
译者简介

王可汗,清华大学机械工程系直博生在读。曾经有着物理专业的知识背景,研究生期间对数据科学产生浓厚兴趣,对机器学习AI充满好奇。期待着在科研道路上,人工智能与机械工程、计算物理碰撞出别样的火花。希望结交朋友分享更多数据科学的故事,用数据科学的思维看待世界。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”查看原文