docker部署cAdvisor + Prometheus + Grafana + Alertmanager
1.在Docker中部署cAdvisor
如果想监控Docker容器,可以安装cAdvisor
#这里因为cAdvisor启动有时候会报错,所以需要输入以下两条指令
sudo mount -o remount,rw '/sys/fs/cgroup'
sudo ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
docker run -v /:/rootfs:ro \
-v /var/run:/var/run:rw \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
-p 8090:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest
访问http://XXX:8090可以看container的详细信息(打开过程可能会比较慢)

2.在Docker中部署Prometheus
#先把镜像拉下来启动起来,进去把配置文件copy到宿主机
docker run -d -p 9090:9090 --name prometheus --net=host prom/prometheus
sudo mkdir /home/prometheus
sudo chmod 777 /home/prometheus
sudo docker cp prometheus:/etc/prometheus/prometheus.yml /home/prometheus/prometheus.yml
docker rm -f prometheus
#这里先不改配置文件启动,挂载的报警触发规则文件alert.yml可以先不要
docker run -d -p 9090:9090 \
-v /home/prometheus/:/etc/prometheus/ \
##这里可以先不配置 -v /home/alertmanager/:/etc/prometheus/ \
--name prometheus --net=host --restart=always \
prom/prometheus --config.file=/etc/prometheus/prometheus.yml \
--web.enable-lifecycle
#在浏览器打开http://IP:9090打开Prometheus的UI,点击status--targets这里能够查看到我们各个监控项,默认暂时只监控自己,也在graph选项通过promQL查询监控数据。
#关于热加载
容器启动增加参数--web.enable-lifecycle,配置在最后,必须同时指定--config.file,发送post请求进行触发热加载: curl -XPOST localhost:9090/-/reload
解释一下prometheus.yml
cat /home/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # 多久 收集 一次数据
evaluation_interval: 15s # 多久评估一次 规则
# Alertmanager相关的配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 规则文件, 可以使用通配符
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 收集数据 配置 列表
scrape_configs:
# 必须配置, 自动附加的job labels, 必须唯一
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
# 使用job名作为label的 静态配置目录的列表 默认是http 后缀默认是/metrics
static_configs:
- targets: ['localhost:9090']
打开 http://XXXX:9090/targets 查看prometheus是否启动成功

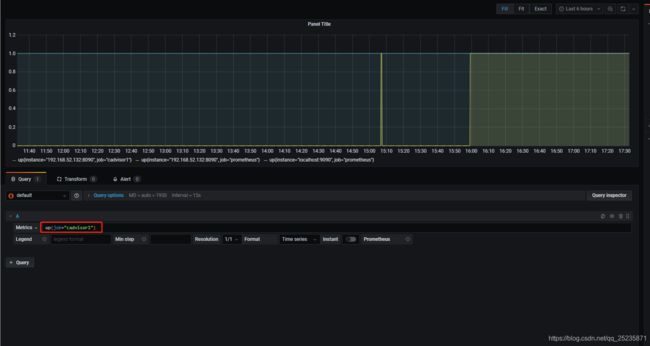
修改prometheus.yml,添加cAdvisor监控
- job_name: cadvisor1
static_configs:
- targets: ['XXXX:8090'] #XXXX最好用真实的IP,不然可能会出问题
使用热部署更新curl -XPOST localhost:9090/-/reload,然后查看

3.在Docker中部署Grafana
docker run -d -p 3000:3000 --name=grafana grafana/grafana
打开Grafana控制台 http://XXXX:3000 账号密码都是admin ,需要登录两次,不知道为啥

添加prometheus数据源



然后添加模板,这里我们用网站自动获取的,需要填入id就行了,具体可以去https://grafana.com/dashboards 查看
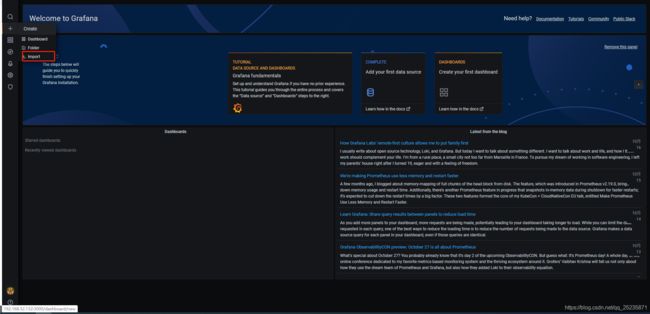

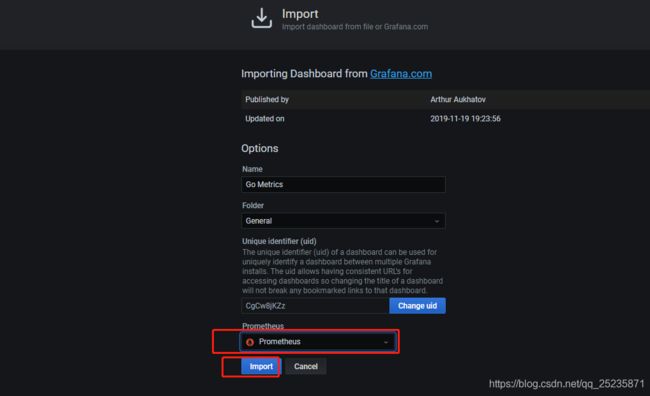
最后效果图就出来拉

4.在Docker中部署Alertmanager
利用Alertmanager 来接受 Prometheus 发送过来的报警信息,并执行各种方式的告警。同样以 Docker 方式启动AlertManager,最简单的启动命令如下:
//随便运行一个容器,其目的就是将容器中服务的配置文件拿到本地
docker run -d --name alertmanager -p 9093:9093 prom/alertmanager
//创建本地目录并给与权限
sudo mkdir /home/alertmanager
sudo chmod 777 alertmanager/
//将docker里面的yml文件拷贝到本机目录中,便于以后修改配置
docker cp alertmanager:/etc/alertmanager/alertmanager.yml /home/alertmanager
docker rm -f alertmanager
vim /home/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: 'xxx@163.com' #邮箱账号
smtp_smarthost: 'smtp.163.com:25'
smtp_auth_username: 'darrytao@163.com' #邮箱账号
smtp_auth_password: 'xxxxxxxx' #邮箱授权码,获取方法这里不做演示,可以百度一下,很简单的
smtp_hello: '163.com'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '546473731@qq.com' #触发条件时发送的邮箱地址,也就是收件人
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
上面vim保存配置可能会报个错误,Enter键确认就行了
简单说明一下配置:
- global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
- route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
- receivers: 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
- inhibit_rules: 抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)。
//重新启动alertmanager,挂载目录文件
docker run -d --name alertmanager -p 9093:9093 -v /home/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager
访问http://192.168.52.132:9093/#/status看看是否成功,不成功的话可能是你配置文件哪里写错了,检查一下
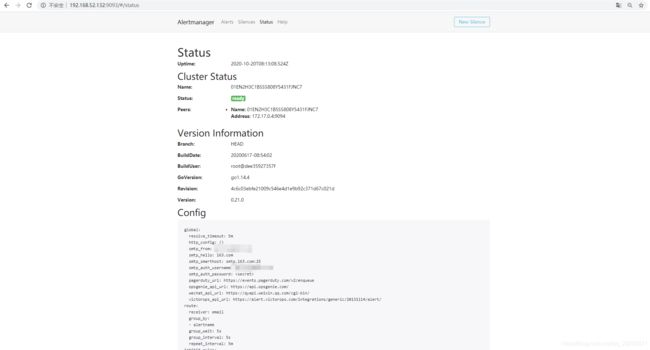
这里他是需要配合Prometheus使用,所以我们需要配置Prometheus的规则文件
mkdir -p /home/prometheus/rules
> sudo vim /home/prometheus/rules/node-up.rules //编写规则
groups:
- name: node-up ##自定义名称
rules:
- alert: node-up
expr: up{job="prometheus"} == 0
## job的名称必须和prometheus配置文件中的 - job_name: 'prometheus'对应
for: 15s ##15秒没有心跳就触发
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s!"
> sudo vim /home/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.52.132:9093 ####这里写上你自己的alertmanager地址端口
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.rules" #######这里写上规则文件的位置,如果按我上面的来,可以不改
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090','192.168.52.132:8090'] ####为了测试,我把cadvisor地址也加上去了,等会会关闭
- job_name: cadvisor1
static_configs:
- targets: ['192.168.52.132:8090'] #XXXX最好用真实的IP,不然可能会出问题
//刷新配置
curl -X POST localhost:9090/-/reload
访问http://192.168.52.132:9090/alerts看效果
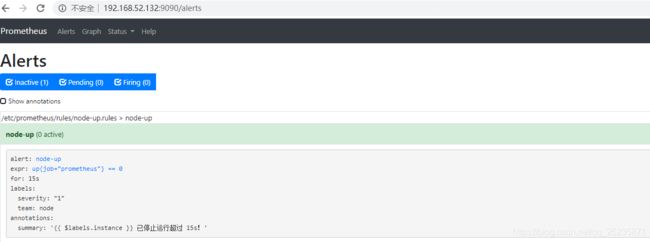
//接下来我们把cadvisor关闭,过一阵子(大于十五秒)看看效果
docker rm -f cadvisor
访问http://192.168.52.132:9090/alerts 和http://192.168.52.132:9093/#/alerts


这里触发了,所以只要邮箱没有配置错误,就应该收到邮件了。
Grafana 邮件通知
上面是用alertmanager邮件通知,grafana也具备这样的功能,触发条件是在控制台去设置,这里演示一个最简单的例子
//首先复制grafana配置文件出来
sudo mkdir /home/grafana
sudo chmod 777 /home/grafana
docker cp grafana:/etc/grafana/grafana.ini /home/grafana/
修改ini文件,配置邮箱信息
> vim /home/grafana/grafana.ini
##找到其中的[smtp]标签,大概在中间位置,很长,要翻一下,也可以查找
[smtp]
# 开启邮箱配置
enabled = true
# 邮箱 host
host = smtp.163.com:25
# 邮箱 username
user = darrytao@163.com
# 邮箱 password
password = ZJINNVVSTVXQXHLI
skip_verify = true
# 来源地址
from_address = darrytao@163.com
# 来源名字
from_name = Grafana
//删除容器
docker rm -f grafana
//重新启动,挂载配置文件
docker run -d -p 3000:3000 -v /home/grafana/grafana.ini:/etc/grafana/grafana.ini --name=grafana grafana/grafana
访问http://xxx.xxx.xxx.xxx:3000/



此时你应该收到一封测试邮件,(如果多个邮件,用逗号隔开)如果没收到邮件就去看看日志,docker logs grafana ,接下来就是配置

参数说明:
name:alert名称
Evaluate every:触发频率
Conditions:触发条件 注:WHEN下面有很多函数,可以根据自己需求选择对应的函数
OF下面的query三个参数含义:第一个是选择你所需要触发监控的对应sql,这个会自动列出来你当前监控有哪些sql,第二个,第三个是监控的区间,如图是当前时间24小时内的数据进行监控
IS ABOVE:也是下拉选项,也可以根据自己需求选择对应的函数 ,如图的含义就是超过设定的阈值200时会发送邮件
邮件内容设置, send to 就是刚才配置的信息,可以自动带出来,Message是邮件内容
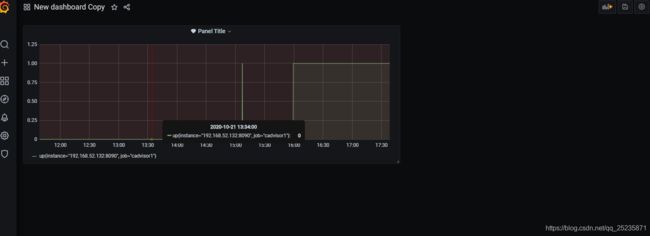
我这里设置的是平均值少于2就会触发,先等五分钟让他检测,然后。每隔十秒就会发送邮件哦。
qq邮箱的话有时候有点问题,本人是公司网络不允许,所以大家可以试试
最后特别提醒,记得关闭alertmanager和grafana哦,不然邮箱一直收到邮件…