【Java基础】集合处理 Stream的使用与正则表达式过滤
目录
-
- json编码与解析
- List内部去重 / List转Set的方法
- 两个List的元素去重后合并
- 正则表达式软过滤字符
- 参考
json编码与解析
依赖:
com.alibaba
fastjson
1.2.47
实现:
public static void fun18() {
List group1 = new ArrayList<>();
group1.add("aaa");
group1.add("bbb");
group1.add("ccc");
// json编码
String s = JSON.toJSONString(group1);
System.out.println(s);
// json解码
List list = JSON.parseObject(s, new TypeReference>(){});
System.out.println(list);
for (String s1 : list) {
System.out.println(s1);
}
}
public static void main(String[] args) {
fun18();
}
这里JSON.toJSONString()是将对象转为JSON字符串
JSON.parseObject(jsonString, new TypeReference<我是对象^_^>(){})是将 JSON字符串 jsonString 转为对象我是对象^_^
运行:
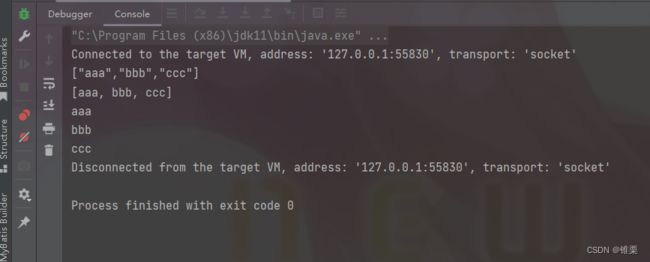
List内部去重 / List转Set的方法
实现:
public static void fun24() {
List group1 = new ArrayList<>();
group1.add("aaa");
group1.add("bbb");
group1.add("ccc");
group1.add("ccc");
System.out.println(group1);
Set collect = group1.stream().collect(Collectors.toSet());
System.out.println(collect);
}
public static void main(String[] args) {
fun24();
}
group1.stream()以序列为基础转stream流
group1.stream().collect(Collectors.toSet())将stream流重新转为set集合,利用集合的元素唯一性实现list内部去重。
运行:
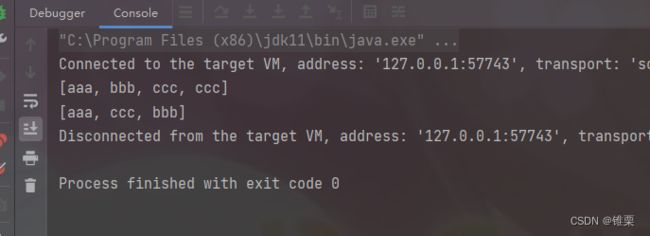
两个List的元素去重后合并
实现
public static void fun17() {
List group1 = new ArrayList<>();
group1.add("aaa");
group1.add("bbb");
group1.add("ccc");
List group2 = new ArrayList<>();
group2.add("ccc");
group2.add("ddd");
group2.add("eee");
List group = Stream.of(group1, group2).flatMap(Collection::stream).distinct().collect(Collectors.toList());
System.out.println(group);
}
public static void main(String[] args) {
fun17();
}
这里Stream.of(group1, group2)是将两组List合并为一组List并以Stream类格式返回:Stream
.flatMap()则是将Stream中的每个元素通过.flatMap()中的映射函数处理。
Stream.of(group1, group2).flatMap(Collection::stream)则是对StreamCollection::stream 处理,得到:Stream
.distinct()如其名所属,每个元素只保留唯一一个,也就是去重。
.collect(Collectors.toList())则是将Stream重新转为List格式
输出有:
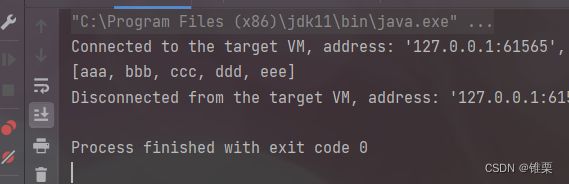
正则表达式软过滤字符
软过滤这个说法是我自己瞎起的,我把错误输入直接抛出异常的情况叫硬过滤,把错误输入转为有效输入的情况叫软过滤
实现:
public static void fun22() {
String input = "爱莎萨*()!@#!%#^&*_=--~`@¥%%……(#DS116194亅7,;';;;'''^[\\u4E00-\\u9FA5]+";
System.out.println(input);
System.out.println();
String s = charSoftFiltering(input);
System.out.println(s);
}
public static String charSoftFiltering(String input) {
// 正则表达式,只允许中文
String pattern = "^[\\u4E00-\\u9FA5]+";
// 匹配当前正则表达式
Matcher matcher = Pattern.compile(pattern).matcher(input);
// 定义输出
String output = "";
// 判断是否可以找到匹配正则表达式的字符
if (matcher.find()) {
// 将匹配当前正则表达式的字符串即文件名称进行赋值
output = matcher.group();
}
return output;
}
public static void main(String[] args) {
fun22();
}
其中Pattern.compile(pattern)将给定的正则表达式编译为模式Pattern。
这里.matcher(input)将给定的输入与模式相匹配。
matcher.find()查找与模式匹配的输入序列的下一个子序列,如果匹配成功,则可以通过开始start、结束end和分组group方法获得更多信息。
matcher.group()返回与上一个匹配项匹配的输入子序列,对于具有输入序列s的匹配器matcher,表达式matcher.group()和s.substring(matcher.start(),matcher.end())等价。
运行:
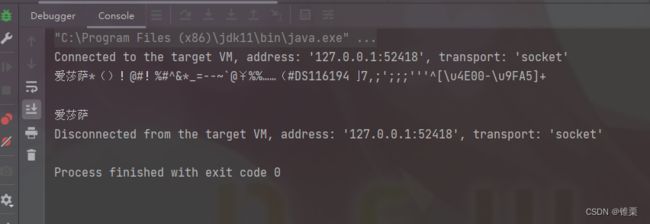
可以看到成功提取了中文,但是过滤了各种乱码。
参考
https://blog.csdn.net/fzy629442466/article/details/84629422
https://blog.csdn.net/genggeonly/article/details/127767804?ops_request_misc=&request_id=&biz_id=102&utm_term
https://blog.csdn.net/mu_wind/article/details/109516995?ops_request_misc=