Spark读写JDBC调优
Spark读写JDBC
目录
总结
写
读
调优
总结
参数
1. 基本参数
val JDBC_URL = newOption("url")val JDBC_TABLE_NAME = newOption("dbtable")val JDBC_DRIVER_CLASS = newOption("driver")
2. 调优参数
val JDBC_PARTITION_COLUMN = newOption("partitionColumn")val JDBC_LOWER_BOUND = newOption("lowerBound")val JDBC_UPPER_BOUND = newOption("upperBound")val JDBC_NUM_PARTITIONS = newOption("numPartitions")
这4个参数用于读jdbc调优
val JDBC_BATCH_FETCH_SIZE = newOption("fetchsize")可用于大数据集时候优先取(显示)前多少条
val JDBC_TRUNCATE = newOption("truncate")用于jdbc写数时候是否truncate目标表
val JDBC_CREATE_TABLE_OPTIONS = newOption("createTableOptions")val JDBC_CREATE_TABLE_COLUMN_TYPES = newOption("createTableColumnTypes")这两个参数用于jdbc写数建表操作
val JDBC_BATCH_INSERT_SIZE = newOption("batchsize")val JDBC_TXN_ISOLATION_LEVEL = newOption("isolationLevel")jdbc批量写数调优,isolationLevel设置事务隔离级别
val JDBC_CUSTOM_DATAFRAME_COLUMN_TYPES = newOption("customSchema")逗号分隔的字段定义val JDBC_SESSION_INIT_STATEMENT = newOption("sessionInitStatement")从目标库获取数据前先执行这个sql(相当于前置sql或者钩子)写
Api入口:
![]()
org.apache.spark.sql.DataFrameWriter#jdbc
通过jdbc将DataFrame的内容保存到外部数据库表中,为防止表在外部数据库中已存在,会根据Mode不同表现出不同行为,若使用默认default会抛出异常
TIPS:
-
不要创建太多并行分片,否则会crash外部数据库系统
-
为避免失败,用户可以关闭 truncate 选项,使用DROP TABLE。由于DBMS中“TRUNCATE TABLE”的行为不同,使用它并不总是安全的。MySQLDialect、DB2Dialect、MsSqlServerDialect、DerbyDialect和oraclealect支持此功能而PostgresDialect和defaultjdbcdirect没有。对于未知和不支持的JDBCDirect,
忽略用户选项“truncate”。
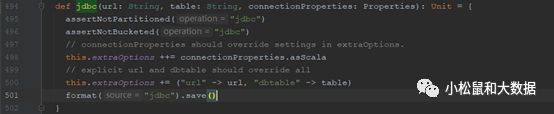
参数说明:
传入jdbc链接,表名,properties属性即可,property属性的key来自
org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions

org.apache.spark.sql.DataFrameWriter#save
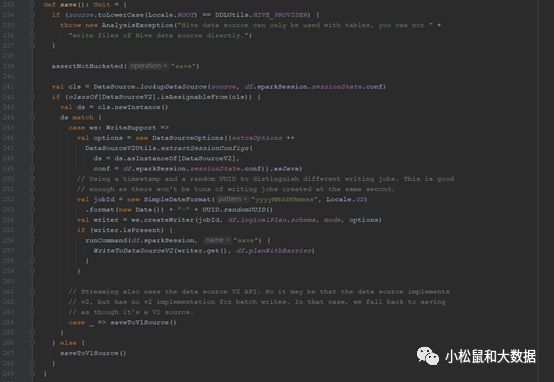
org.apache.spark.sql.DataFrameWriter#saveToV1Source
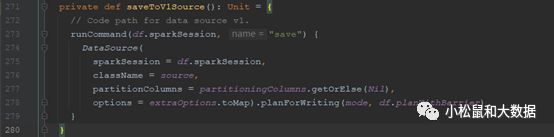
org.apache.spark.sql.execution.datasources.DataSource#planForWriting

org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider#createRelation
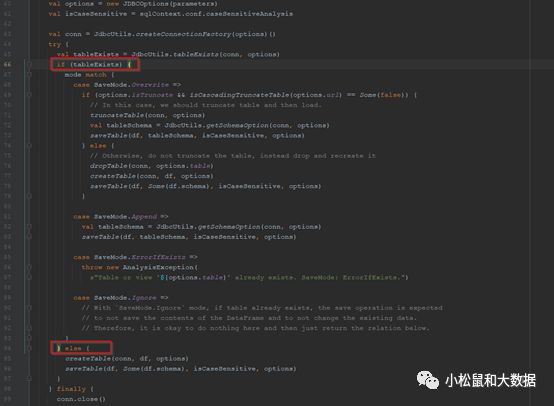
这里会根据传参进行控制处理
代码首先根据传入的表名去数据库中查询,若查询成功就表示表存在
根据表是否存在,进行处理
| 大前提 |
SaveMode模式 |
行为模式 |
| 表存在 |
SaveMode.Overwrite |
见下方: |
| 表存在 |
SaveMode.Append |
直接存数据 |
| 表存在 |
SaveMode.ErrorIfExists |
抛出AnalysisException异常 表示表或者视图已存在 |
| 表存在 |
SaveMode.Ignore |
不保存DataFrame数据,不改变已有数据,什么都不做 |
| 表不存在 |
建表,存数据 |
对于表已存在,且SaveMode.Overwrite时
若truncate参数值为true,且TRUNCATE TABLE causes cascading为false时,先truncate表,然后存数据
下表为spark已支持数据库的TRUNCATETABLE causes cascading的值
| DB2Dialect |
false |
| MsSqlServerDialect |
false |
| MySQLDialect |
false |
| OracleDialect |
false |
| PostgresDialect |
false |
否则:删表、建表、存数.
建表:可以传入建表参数
org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions#JDBC_CREATE_TABLE_OPTIONSorg.apache.spark.sql.execution.datasources.jdbc.JDBCOptions#JDBC_CREATE_TABLE_COLUMN_TYPES
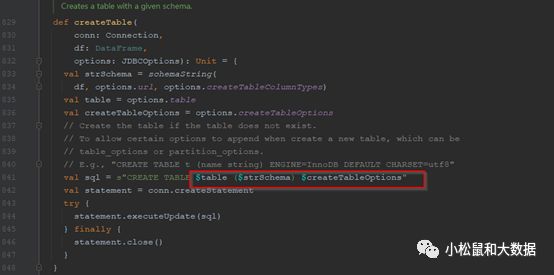
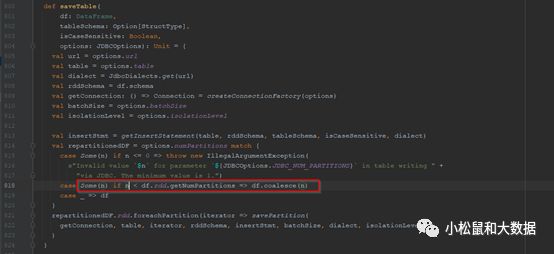
保存数据:org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils#saveTableTIPS:batchsize可用于批次写入调优org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils#savePartition
TIPS:保存DataFrame的一个分区到数据库,这个是在一个数据库事务中处理的,若isolation level设置为NONE,则可能导致数据重复插入
读
入口
org.apache.spark.sql.DataFrameReader#loadorg.apache.spark.sql.DataFrameReader#loadV1Source
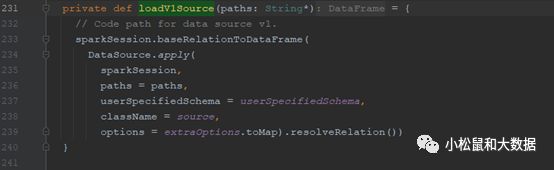
org.apache.spark.sql.execution.datasources.DataSource#resolveRelation
org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider#createRelation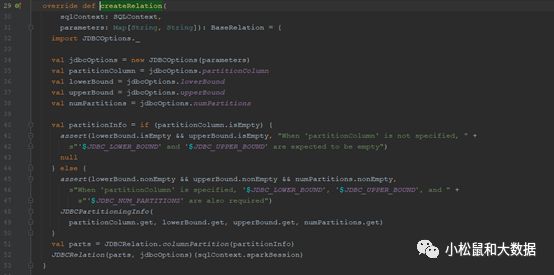
TIPS
未声明partitionColumn时,jdbcOptions.lowerBound和jdbcOptions.upperBound应该为空
若声明了partitionColumn,jdbcOptions.lowerBound、jdbcOptions.upperBound和jdbcOptions.numPartitions都必须给值
分区列建议是整数类型,因为会对上限值和下限值进行减法、比较等操作
调优
jdbc参数调优前面已经说到,对于读取数据,spark调参会要求必须是整数,那么非整数,数据量又比较大,我们也会希望能够切片读取,如何实现呢?
其实很简单,实现自己的JdbcRelationProvider即可
实现示例如下:
在自己项目创建包org.apache.spark.sql.execution.datasources.jdbc 尽量跟JdbcRelationProvider的包路径一致,这是因为类会访问限制了包权限的方法
1. 实现自定义的Provider,继承CreatableRelationProvider,实现RelationProvider和DataSourceRegister特质即可
package org.apache.spark.sql.execution.datasources.jdbcimport org.apache.spark.sql.{AnalysisException, DataFrame, SQLContext, SaveMode}import org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils.{createTable, dropTable, isCascadingTruncateTable, saveTable, truncateTable}import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, DataSourceRegister, RelationProvider}class DemoJdbcRelationProvider extends CreatableRelationProviderwith RelationProvider with DataSourceRegister {override def shortName(): String = "myjdbc"override def createRelation(sqlContext: SQLContext,parameters: Map[String, String]): BaseRelation = {import JDBCOptions._val jdbcOptions = new JDBCOptions(parameters)val partitionColumn = jdbcOptions.partitionColumnval lowerBound = jdbcOptions.lowerBoundval upperBound = jdbcOptions.upperBoundval numPartitions = jdbcOptions.numPartitions
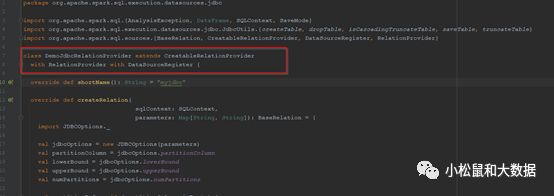
2. 开发自定义分片逻辑
重写方法
org.apache.spark.sql.execution.datasources.jdbc.DemoJdbcRelationProvider#createRelation根据源码
org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$#columnPartition可以看到,spark会根据用户传入的这4个参数,划分多个区间,以进行跑数
我们实现自己的就行,如果有参数需要传入,从spark的—conf传入,createRelation 方法的parameters参数中获取即可。注意,用spark 的—conf参数传入时候,参数名称必须以spark. 开头,不然会忽略,代码详见:
org.apache.spark.deploy.SparkSubmitArguments#ignoreNonSparkProperties
3. 使用自定义的provider,就可以愉快使用了
val df = sparkSession.read.format("org.apache.spark.sql.execution.datasources.jdbc.DemoJdbcRelationProvider").option(...
最后:
如果本文能对您有帮助,您可以在心里点个赞,也可以分享给大家,欢迎随时沟通~
我的公众号:小松鼠与大数据
