DeformableConv(可形变卷积)理论和代码分析
DeformableConv(可形变卷积)理论和代码分析
- 代码参考:DeformableConv代码
- 理论参考:bilibili视频讲解
1.DeformableConv理论分析
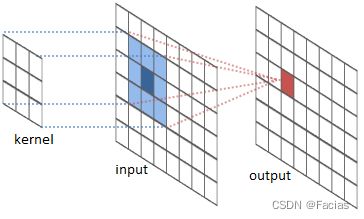
以上图为例进行讲解,在普通卷积中:
- input输入尺寸为[batch_size, channel, H, W]
- output输入尺寸也为[batch_size, channel, H, W]
- kernel尺寸为[kernel_szie, kernel_szie]
因此output中任意一点p0,对应到input中的卷积采样区域大小为kernel_szie x kernel_szie,卷积操作用公式可表示为:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n ) \mathbf{y}\left(\mathbf{p}_{0}\right)=\sum_{\mathbf{p}_{n} \in \mathcal{R}} \mathbf{w}\left(\mathbf{p}_{n}\right) \cdot \mathbf{x}\left(\mathbf{p}_{0}+\mathbf{p}_{n}\right) y(p0)=pn∈R∑w(pn)⋅x(p0+pn)
其中, p n \mathbf{p}_{n} pn代表卷积核中每一个点相对于中心点的偏移量,可用如下公式表示(3 x 3卷积核为例):
R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 0 , 1 ) , ( 1 , 1 ) } \mathcal{R}=\{(-1,-1),(-1,0), \ldots,(0,1),(1,1)\} R={(−1,−1),(−1,0),…,(0,1),(1,1)}

w ( p n ) \mathbf{w}\left(\mathbf{p}_{n}\right) w(pn)代表卷积核上对应位置的权重。 p 0 \mathbf{p}_{0} p0可以看做output上每一个点, y ( p 0 ) \mathbf{y}\left(\mathbf{p}_{0}\right) y(p0)为output上每一点的具体值。 x ( p 0 + p n ) \mathbf{x}\left(\mathbf{p}_{0}+\mathbf{p}_{n}\right) x(p0+pn)为output上每个点对应到input上的卷积采样区域的具体值。该公式整体意思就是卷积操作。
而DeformableConv的计算步骤就是在普通卷积的基础上,加一个模型自己学习的偏移量offset,公式为:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n + Δ p n ) \mathbf{y}\left(\mathbf{p}_{0}\right)=\sum_{\mathbf{p}_{n} \in \mathcal{R}} \mathbf{w}\left(\mathbf{p}_{n}\right) \cdot \mathbf{x}\left(\mathbf{p}_{0}+\mathbf{p}_{n}+\Delta \mathbf{p}_{n}\right) y(p0)=pn∈R∑w(pn)⋅x(p0+pn+Δpn)
公式中用 Δ p n \Delta \mathbf{p}_{n} Δpn表示偏移量。需要注意的是,该偏移量是针对 x \mathbf{x} x的,也就是可变形卷积变的不是卷积核,而是input。
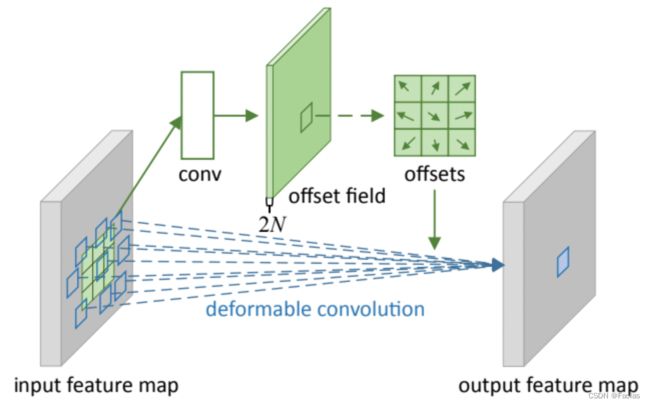
从上图可以看到,在input上按照普通卷积操作,output上的一点对应到input上的卷积采样区域是一个卷积核大小的正方形,而可变形卷积对应的卷积采样区域为一些蓝框表示的点,这就是可变形卷积与普通卷积的区别。
接下来说一下可变形卷积的具体细节,以N x N的卷积核为例。一个output上的点对应到input上的卷积采样区域大小为N x N,按照可变形卷积的操作,这N x N区域的每一个卷积采样点都要学习一个偏离量offset,而offset是用坐标表示的,所以一个output要学习2N x N个参数。一个output大小为H x W,所以一共要学习2NxN x H x W个参数。即上图的offset field,其维度为B x 2NxN x H x W,其中B代表batch_size,(上图是网络上找的,里面的N指卷积核的面积)。值得注意的两点细节是:
- input(假设维度为B x C x H x W)一个batch内的所有通道上的特征图(一共C个)共用一个offset field,即一个batch内的每张特征图用到的偏移量是一样的。
- 可变形卷积不改变input的尺寸,所以output也为H x W。
一个点加上offset之后,大概率不会得到一个整数坐标点,这时就应该进行线性插值操作,具体做法为找出和偏移后的点距离小于1且最近的四个点,将其值乘以权重(权重以距离来衡量)再进行加和操作,即为最终偏移后的点的值。
2.DeformableConv代码分析
依照上述理论,可将DeformableConv的代码实现拆解为如下流程图:

2.1初始化操作
class DeformConv2d(nn.Module):
def __init__(self,
inc,
outc,
kernel_size=3,
padding=1,
stride=1,
bias=None,
modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable
Convolution (Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, #该卷积用于最终的卷积
outc,
kernel_size=kernel_size,
stride=kernel_size,
bias=bias)
self.p_conv = nn.Conv2d(inc, #该卷积用于从input中学习offset
2*kernel_size*kernel_size,
kernel_size=3,
padding=1,
stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation #该部分是DeformableConv V2版本的,可以暂时不看
if modulation:
self.m_conv = nn.Conv2d(inc,
kernel_size*kernel_size,
kernel_size=3,
padding=1,
stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
2.2执行
def forward(self, x):
offset = self.p_conv(x) #此处得到offset
if self.modulation:
m = torch.sigmoid(self.m_conv(x))
dtype = offset.data.type()
ks = self.kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1)
m = m.unsqueeze(dim=1)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype): #求
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset