Linux内核机制总结进程管理之进程启动和进程退出(三)
文章目录
-
- 1. 进程启动
-
- 1.1 创建新进程
- 1.2 装载程序
- 2. 进程退出
-
- 2.1 线程组退出
- 2.2 中止进程
- 2.3 查询子进程终止原因
- 重要:本系列文章内容摘自
1. 进程启动
当我们在shell进程里面执行命令"/sbin/hello.elf &"以启动程序“hello”时,shell进程首先创建子进程,然后子进程装载程序“hello.elf”,其代码如下:
ret = fork();
if (ret > 0) {
/* 父进程继续执行 */
} else if (ret == 0) {
/* 子进程装载程序 */
ret = execve(filename, argv, envp);
} else {
/* 创建子进程失败 */
}
1.1 创建新进程
在Linux内核中,新进程是从一个已经存在的进程复制出来的。内核使用静态数据构造出0号内核线程,0号内核线程分叉生成1号内核线程和2号内核线程(kthreadd线程)。1号内核线程完成初始化以后装载用户程序,变成1号进程,其他进程都是1号进程或者它的子孙进程分叉生成的;其他内核线程是kthreadd线程分叉生成的。
3个系统调用可以用来创建新的进程:
- fork(分叉)
子进程是父进程的一个副本,采用了写时复制的技术。 - vfork
用于创建子进程,之后子进程立即调用execve以装载新程序的情况。为了避免复制物理页,父进程会睡眠等待子进程装载新程序。现在fork采用了写时复制的技术,vfork失去了速度优势,已经被废弃。 - clone(克隆)
可以精确地控制子进程和父进程共享哪些资源。这个系统调用的主要用处是可供pthread库用来创建线程。
clone是功能最齐全的函数,参数多,使用复杂,fork是clone的简化函数。
系统调用fork内核定义如下:
SYSCALL_DEFINE0(fork)
展开后是:
asmlinkage long sys_fork(void)
“SYSCALL_DEFINE”后面的数字表示系统调用的参数个数,“SYSCALL_DEFINE0”表示系统调用没有参数,“SYSCALL_DEFINE6”表示系统调用有6个参数,如果参数超过6个,使用宏“SYSCALL_DEFINEx”。
“asmlinkage”表示这个C语言函数可以被汇编代码调用。如果使用C++编译器,“asmlinkage”被定义为extern “C”;如果使用C编译器,“asmlinkage”是空的宏。
系统调用的函数名称以“sys_”开头。
创建新进程的进程p和生成的新进程的关系有3种情况。
- 新进程是进程p的子进程。
- 如果clone传入标志位CLONE_PARENT,那么新进程和进程p拥有同一个父进程,是兄弟关系。
- 如果clone传入标志位CLONE_THREAD,那么新进程和进程p属于同一个线程组。
创建新进程的3个系统调用在文件“kernel/fork.c”中,它们把工作委托给函数_do_fork。
函数do_fork原型如下:
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls);
参数如下:
- 参数clone_flags是克隆标志,最低字节指定了进程退出时发给父进程的信号,创建线程时,该参数的最低字节是0,表示线程退出时不需要向父进程发送信号。
- 参数stack_start只在创建线程时有意义,用来指定新线程的用户栈的起始地址。
- 参数stack_size只在创建线程时有意义,用来指定新线程的用户栈的长度。这个参数已经废弃。
- 参数parent_tidptr只在创建线程时有意义,如果参数clone_flags指定了标志位CLONE_PARENT_SETTID,那么调用线程需要把新线程的进程标识符写到参数parent_tidptr指定的位置,也就是新线程保存自己的进程标识符的位置。
- 参数child_tidptr只在创建线程时有意义,存放新线程保存自己的进程标识符的位置。如果参数clone_flags指定了标志位CLONE_CHILD_CLEARTID,那么线程退出时需要清除自己的进程标识符。如果参数clone_flags指定了标志位CLONE_CHILD_SETTID,那么新线程第一次被调度时需要把自己的进程标识符写到参数child_tidptr指定的位置。
- 参数tls只在创建线程时有意义,如果参数clone_flags指定了标志位CLONE_SETTLS,那么参数tls指定新线程的线程本地存储的地址。
- 函数
_do_fork的执行流程如下:

- 调用函数copy_process以创建新进程。
- 如果参数clone_flags设置了标志CLONE_PARENT_SETTID,那么把新线程的进程标识符写到参数parent_tidptr指定的位置。
- 调用函数wake_up_new_task以唤醒新进程。
- 如果是系统调用vfork,那么当前进程等待子进程装载程序
- 函数
copy_process的执行流程如下:
创建新进程的主要工作由函数copy_process实现
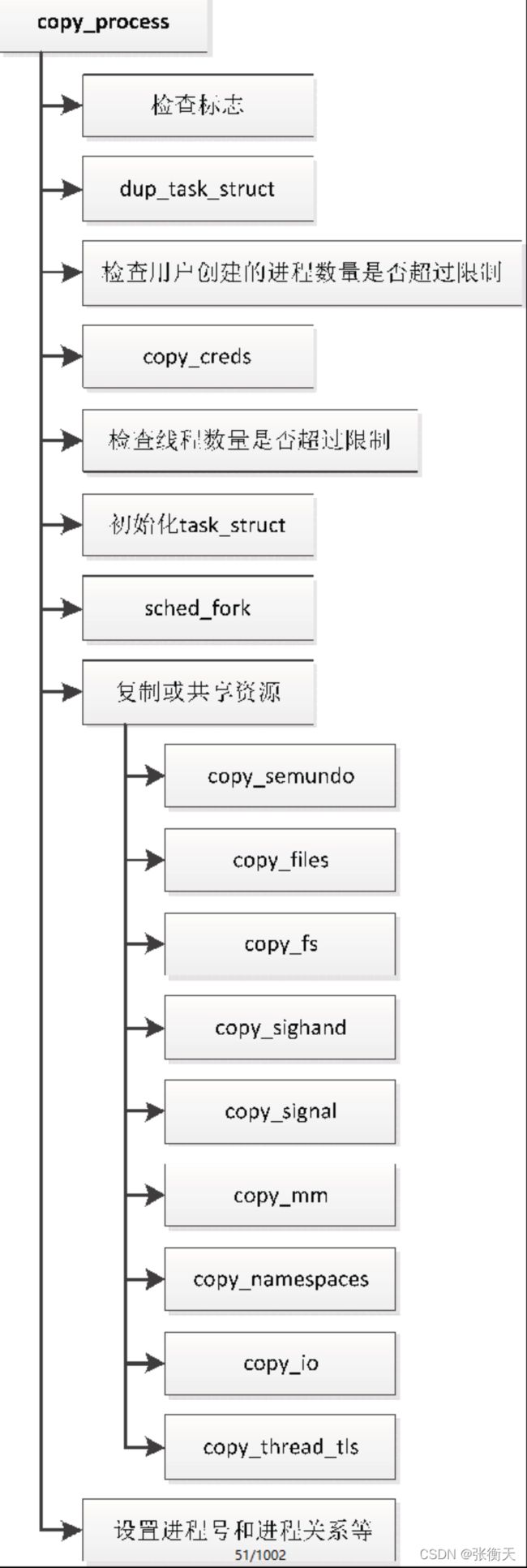
-
检查标志:以下标志组合是非法的
- 同时设置CLONE_NEWNS和CLONE_FS,即新进程属于新的挂载命名空间,同时和当前进程共享文件系统信息。
- 同时设置CLONE_NEWUSER和CLONE_FS,即新进程属于新的用户命名空间,同时和当前进程共享文件系统信息。
- 设置CLONE_THREAD,未设置CLONE_SIGHAND,即新进程和当前进程属于同一个线程组,但是不共享信号处理程序。
- 设置CLONE_SIGHAND,未设置CLONE_VM,即新进程和当前进程共享信号处理程序,但是不共享虚拟内存。
- 新进程想要和当前进程成为兄弟进程,并且当前进程是某个进程号命名空间中的1号进程。这种标志组合是非法的,说明1号进程不存在兄弟进程。
- 新进程和当前进程属于同一个线程组,同时新进程属于不同的用户命名空间或者进程号命名空间。这种标志组合是非法的,说明同一个线程组的所有线程必须属于相同的用户命名空间和进程号命名空间。
-
函数dup_task_struct:函数dup_task_struct为新进程的进程描述符分配内存,把当前进程的进程描述符复制一份,为新进程分配内核栈。
进程描述的成员stack指向内核栈:

内核栈定义如下:#includeunion thread_union { #ifndef CONFIG_THREAD_INFO_IN_TASK struct thread_info thread_info; #endif unsigned long stack[THREAD_SIZE/sizeof(long)]; }; 内核栈有两种布局:
- 结构体thread_info占用内核栈的空间,在内核栈顶部,成员task指向进程描述符。
- 结构体thread_info没有占用内核栈的空间,是进程描述符的第一个成员。
两种布局的区别是结构体thread_info的位置不同。如果选择第二种布局,需要打开配置宏CONFIG_THREAD_INFO_IN_TASK。ARM64架构使用第二种内核栈布局。第二种内核栈布局的好处是:thread_info结构体作为进程描述符的第一个成员,它的地址和进程描述符的地址相同。当进程在内核模式运行时,ARM64架构的内核使用用户栈指针寄存器SP_EL0存放当前进程的thread_info结构体的地址,通过这个寄存器既可以得到thread_info结构体的地址,也可以得到进程描述符的地址。
内核栈的长度是THREAD_SIZE,它由各种处理器架构自己定义,ARM64架构定义的内核栈长度是16KB。
结构体thread_info存放汇编代码需要直接访问的底层数据,由各种处理器架构定义,ARM64架构定义的结构体如下:
<arch/arm64/include/asm/thread_info.h> struct thread_info { unsigned long flags; /*底层标志位*/ mm_segment_t addr_limit; /*地址限制 */ #ifdef CONFIG_ARM64_SW_TTBR0_PAN u64 ttbr0; /* 保存的寄存器 TTBR0_EL1 */ #endif int preempt_count; /* 0表示可抢占,小于0是缺陷 */ };- flags:底层标志,常用的标志是_TIF_SIGPENDING和_TIF_NEED_RESCHED,前者表示进程有需要处理的信号,后者表示调度器需要重新调度进程。
- addr_limit:进程可以访问的地址空间的上限。对于进程,它的值是用户地址空间的上限;对于内核线程,它的值是内核地址空间的上限。
- preempt_count:抢占计数器。
-
检查用户的进程数量限制:如果拥有当前进程的用户创建的进程数量达到或者超过限制,并且用户不是根用户,也没有忽略资源限制的权限(CAP_SYS_RESOURCE)和系统管理权限(CAP_SYS_ADMIN),那么不允许创建新进程。
-
函数copy_creds:函数copy_creds负责复制或共享证书,证书存放进程的用户标识符、组标识符和访问权限。
如果设置了标志CLONE_THREAD,即新进程和当前进程属于同一个线程组,那么新进程和当前进程共享证书。
-
检查线程数量限制:如果线程数量达到允许的线程最大数量,那么不允许创建新进程。
全局变量nr_threads 存放当前的线程数量;max_threads存放允许创建的线程最大数量,默认值是MAX_THREADS。 -
函数sched_fork:函数sched_fork为新进程设置调度器相关的参数。
-
复制或者共享资源如下
- UNIX系统5信号量。只有属于同一个线程组的线程之间才会共享UNIX系统5信号量。函数copy_semundo处理UNIX系统5信号量的共享问题。
- 打开文件表。只有属于同一个线程组的线程之间才会共享打开文件表。函数copy_files复制或者共享打开文件表。
- 文件系统信息。进程的文件系统信息包括根目录、当前工作目录和文件模式创建掩码。只有属于同一个线程组的线程之间才会共享文件系统信息。函数copy_fs复制或者共享文件系统信息。
- 信号处理程序。只有属于同一个线程组的线程之间才会共享信号处理程序。函数copy_sighand复制或者共享信号处理程序。
- 信号结构体。只有属于同一个线程组的线程之间才会共享信号结构体。函数copy_signal复制或共享信号结构体。
- 虚拟内存。只有属于同一个线程组的线程之间才会共享虚拟内存。函数copy_mm复制或共享虚拟内存。
- 命名空间。函数copy_namespaces创建或共享命名空间。
- I/O上下文。函数copy_io创建或者共享I/O上下文。
- 复制寄存器值。调用函数copy_thread_tls复制当前进程的寄存器值,并且修改一部分寄存器值。进程有两处用来保存寄存器值:从用户模式切换到内核模式时,把用户模式的各种寄存器保存在内核栈底部的结构体pt_regs中;进程调度器调度进程时,切换出去的进程把寄存器值保存在进程描述符的成员thread中。因为不同处理器架构的寄存器不同,所以各种处理器架构需要自己定义结构体pt_regs和thread_struct,实现函数copy_thread_tls。
-
设置进程号和进程关系。函数copy_process的最后部分为新进程设置进程号和进程关系。
-
- 唤醒新进程
函数wake_up_new_task负责唤醒刚刚创建的新进程 - 新进程第一次运行
新进程第一次运行,是从函数ret_from_fork开始执行。函数ret_from_fork是由各种处理器架构自定义的函数,ARM64架构定义的ret_from_fork函数如下:
在介绍函数copy_thread时,说过:如果新进程是内核线程,寄存器x19存放线程函数的地址,寄存器x20存放线程函数的参数;如果新进程是用户进程,寄存器x19的值是0。arch/arm64/kernel/entry.S 1 tsk .req x28 //当前进程的thread_info结构体的地址 2 3 ENTRY(ret_from_fork) 4 bl schedule_tail 5 cbz x19, 1f /* 如果寄存器x19的值是0,说明当前进程是用户进程,那么跳转到标号1 */ 6 mov x0, x20 /* 内核线程:x19存放线程函数的地址,x20存放线程函数的参数 */ 7 blr x19 /* 调用线程函数 */ 8 1: get_thread_info tsk /* 用户进程:x28 = sp_el0 = 当前进程的thread_info结构体的地址 */ 9 b ret_to_user /* 返回用户模式 */ 10 ENDPROC(ret_from_fork)
函数schedule_tail负责为上一个进程执行清理操作,是新进程第一次运行时必须最先做的事情
1.2 装载程序
当调度器调度新进程时,新进程从函数ret_from_fork开始执行,然后从系统调用fork返回用户空间,返回值是0。接着新进程使用系统调用execve装载程序。
Linux内核提供了两个装载程序的系统调用:
int execve(const char *filename, char *const argv[], char *const envp[]);
int execveat(int dirfd, const char *pathname, char *const argv[], char *const envp[], int flags);
两个系统调用的主要区别是:如果路径名是相对的,那么execve解释为相对调用进程的当前工作目录,而execveat解释为相对文件描述符dirfd指向的目录。如果路径名是绝对的,那么execveat忽略参数dirfd。
参数argv是传给新程序的参数指针数组,数组的每个元素存放一个参数字符串的地址,argv[0]应该指向要装载的程序的名称。
参数envp是传给新程序的环境指针数组,数组的每个元素存放一个环境字符串的地址,环境字符串的形式是“键=值”。
argv和envp都必须在数组的末尾包含一个空指针。
如果程序的main函数被定义为下面的形式,参数指针数组和环境指针数组可以被程序的main函数访问:
int main(int argc, char *argv[], char *envp[])
可是,POSIX.1标准没有规定main函数的第3个参数。根据POSIX.1标准,应该借助外部变量environ访问环境指针数组。
两个系统调用最终都调用函数do_execveat_common,其执行流程如下:

-
调用函数do_open_execat打开可执行文件。
-
调用函数sched_exec。装载程序是一次很好的实现处理器负载均衡的机会,因为此时进程在内存和缓存中的数据是最少的。选择负载最轻的处理器,然后唤醒当前处理器上的迁移线程,当前进程睡眠等待迁移线程把自己迁移到目标处理器。
-
调用函数bprm_mm_init创建新的内存描述符,分配临时的用户栈。
临时用户栈的长度是一页,虚拟地址范围是[STACK_TOP_MAX−页长度,STACK_TOP_MAX),bprm->p指向在栈底保留一个字长(指针长度)后的位置:

-
调用函数prepare_binprm设置进程证书,然后读文件的前面128字节到缓冲区。
-
依次把文件名称、环境字符串和参数字符串压到用户栈:

-
调用函数exec_binprm。函数exec_binprm调用函数search_binary_handler,尝试注册过的每种二进制格式的处理程序,直到某个处理程序识别正在装载的程序为止。
-
二进制格式
在Linux内核中,每种二进制格式都表示为下面的数据结构的一个实例:include/linux/binfmts.h struct linux_binfmt { struct list_head lh; struct module *module; int (*load_binary)(struct linux_binprm *); int (*load_shlib)(struct file *); int (*core_dump)(struct coredump_params *cprm); unsigned long min_coredump; /* 核心转储文件的最小长度 */ }每种二进制格式必须提供下面3个函数:
- load_binary用来加载普通程序。
- load_shlib用来加载共享库。
- core_dump用来在进程异常退出时生成核心转储文件。程序员使用调试器(例如GDB)分析核心转储文件以找出原因。min_coredump指定核心转储文件的最小长度。
每种二进制格式必须使用函数register_binfmt向内核注册。
下面介绍常用的二进制格式:ELF格式和脚本格式。
-
装载ELF程序
ELF文件:ELF(Executable and Linkable Format)是可执行与可链接格式,主要有以下4种类型:- 目标文件(object file),也称为可重定位文件(relocatable file),扩展名是“.o”,多个目标文件可以链接生成可执行文件或者共享库。
- 可执行文件(executable file)。
- 共享库(shared object file),扩展名是“.so”。
- 核心转储文件(core dump file)。
ELF文件分成4个部分:ELF首部、程序首部表(program header table)、节(section)和节首部表(section header table)。实际上,一个文件不一定包含全部内容,而且它们的位置也不一定像下面中这样安排,只有ELF首部的位置是固定的,其余各部分的位置和大小由ELF首部的成员决定:
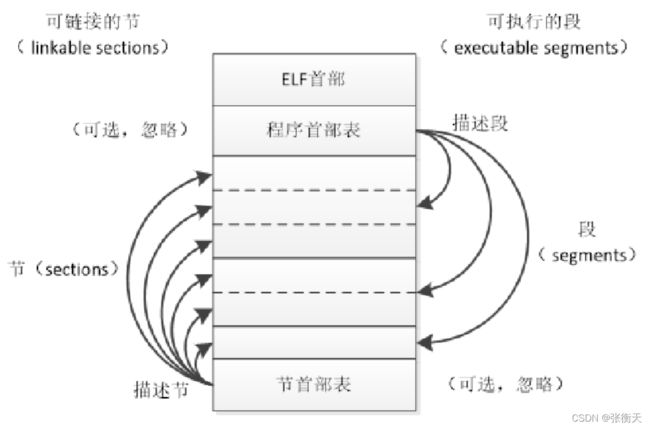
程序首部表就是我们所说的段表(segment table),段(segment)是从运行的角度描述,节(section)是从链接的角度描述,一个段包含一个或多个节。在不会混淆的情况下,我们通常把节称为段,例如代码段(text section),不称为代码节。32位ELF文件和64位ELF文件的差别很小,这里只介绍64位ELF文件的格式:
ELF首部的成员 说明 unsigned char e_ident[EI_NIDENT]; 16字节的魔幻数
前4字节是ELF文件的标识符,第1字节是0x7F(即删除的ASCII编码),第2~4字节是ELF
第5字节表示ELF文件类别,1表示32位ELF文件,2表示64位ELF文件
第6字节表示字节序第7字节表示版本第8字节表示应用二进制接口(ABI)的类型
其他字节暂时不需要,用0填充Elf64_Half e_type; ELF文件类型,1表示可重定位文件(目标文件),2表示可执行文件,3表示动态库,4表示核心转储文件 Elf64_Half e_machine; 机器类别,例如EM_ARM(40)表示ARM 32位,EM_AARCH64(183)表示ARM 64位 Elf64_Word e_version; 版本,用来区分不同的ELF变体,目前的规范只定义了版本1 Elf64_Addr e_entry; 程序入口的虚拟地址 Elf64_Off e_phoff; 程序首部表的文件偏移 Elf64_Off e_shoff; 节首部表的文件偏移 Elf64_Word e_flags; 处理器特定的标志 Elf64_Half e_ehsize; ELF首部的长度 Elf64_Half e_phentsize; 程序首部表中表项的长度,单位是字节 Elf64_Half e_phnum; 程序首部表中表项的数量 Elf64_Half e_shentsize; 节首部表中表项的长度,单位是字节 Elf64_Half e_shnum; 节首部表中表项的数量 Elf64_Half e_shstrndx; 节名称字符串表在节首部表中的索引 程序首部表中每条表项的成员及说明:
程序首部表中每条表项的成员 程序首部表中每条表项的成员 Elf64_Word p_type; 段的类型,常见的段类型如下。
(1)可加载段(PT_LOAD,类型值为1)——表示一个需要从二进制文件映射到虚拟地址空间的段,例如程序的代码和数据
(2)解释器段(PT_INTERP,类型值为3)——指定把可执行文件映射到虚拟地址空间以后必须调用的解释器,解释器负责链接动态库和解析没有解析的符号。解释器通常是动态链接器,即ld共享库,负责把程序依赖的动态库映射到虚拟地址空间Elf64_Word p_flags; 段的标志,常用的3个权限标志是读、写和执行 Elf64_Off p_offset; 段在文件中的偏移 Elf64_Addr p_vaddr; 段的虚拟地址 Elf64_Addr p_paddr; 段的物理地址 Elf64_Xword p_filesz; 段在文件中的长度 Elf64_Xword p_memsz; 段在内存中的长度 Elf64_Xword p_align; 段的对齐值 节首部表中每条表项的成员及说明:
节首部表中每条表项的成员 说明 Elf64_Word sh_name; 节名称在节名称字符串表中的偏移 Elf64_Word sh_type; 节的类型 Elf64_Xword sh_flags; 节的属性 lf64_Addr sh_addr; 节在执行时的虚拟地址 Elf64_Off sh_offset; 节的文件偏移 Elf64_Xword sh_size; 节的长度 Elf64_Word sh_link; 引用另一个节首部表表项,指定该表项的索引 Elf64_Word sh_info; 附加的节信息 lf64_Xword sh_addralign; 节的对齐值 Elf64_Xword sh_entsize; 如果节包含一个表项长度固定的表,例如符号表,那么这个成员存放表项的长度 重要的节及说明如表:
节名称 说明 .text 代码节(也称文本节),通常称为代码段,包含程序的机器指令 .data 数据节,通常称为数据段,包含已经初始化的数据,程序在运行期间可以修改 .rodata 只读数据 .bss 没有初始化的数据,在程序开始运行前用零填充(bss的全称是“Block Started by Symbol”,表示以符号开始的块) .interp 保存解释器的名称,通常是动态链接器,即ld共享库 .shstrtab 节名称字符串表 .symtab 符号表。符号包括函数和全局变量,符号名称存放在字符串表中,符号表存储符号名称在字符串表里面的偏移。可以执行命令“readelf --symbols ”查看符号表 .strtab 字符串表,存放符号表需要的所有字符串 .init 程序初始化时执行的机器指令 .fini 程序结束时执行的机器指令 .dynamic 存放动态链接信息,包含程序依赖的所有动态库,这是动态链接器需要的信息。可以执行命令“readelf --dynamic ”来查看 .dynsym 存放动态符号表,包含需要动态链接的所有符号,即程序所引用的动态库里面的函数和全局变量,这是动态链接器需要的信息。可以执行命令“readelf --dyn-syms ”查看动态符号表 .dynstr 这个节存放一个字符串表,包含动态链接需要的所有字符串,即动态库的名称、函数名称和全局变量的名称。“.dynamic”节不直接存储动态库的名称,而是存储库名称在该字符串表里面的偏移。动态符号表不直接存储符号名称,而是存储符号名称在该字符串表里面的偏移 可以使用程序“readelf”查看ELF文件的信息。
1)查看ELF首部:readelf -h。
2)查看程序首部表:readelf -l。
3)查看节首部表:readelf -S。
内核负责解析ELF程序源文件:
| 源文件 | 说明 |
|---|---|
| fs/binfmt_elf.c | 解析64位ELF程序,和处理器架构无关 |
| fs/compat_binfmt_elf.c | 在64位内核中解析32位ELF程序,和处理器架构无关。注意:该源文件首先对一些数据类型和函数重命名,然后包含源文件“binfmt_elf.c” |
主要步骤如下:
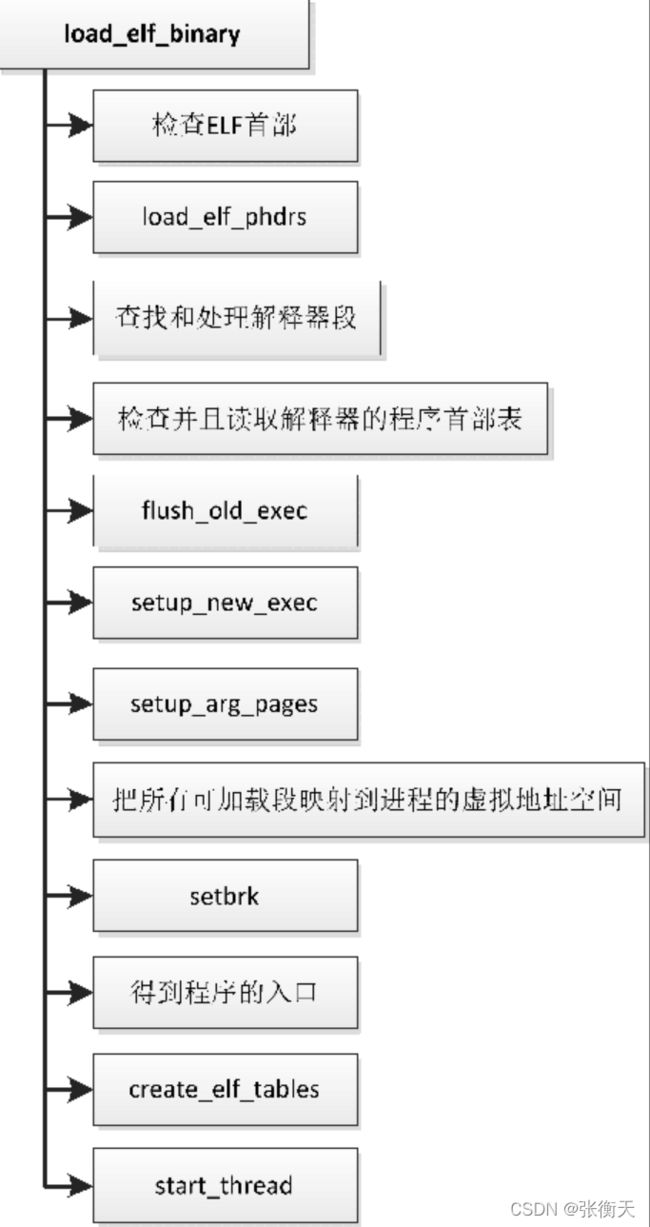
- 检查ELF首部。检查前4字节是不是ELF魔幻数,检查是不是可执行文件或者共享库,检查处理器架构。
- 读取程序首部表。
- 在程序首部表中查找解释器段,如果程序需要链接动态库,那么存在解释器段,从解释器段读取解释器的文件名称,打开文件,然后读取ELF首部。
- 检查解释器的ELF首部,读取解释器的程序首部表。
- 调用函数flush_old_exec终止线程组中的所有其他线程,释放旧的用户虚拟地址空间,关闭那些设置了“执行execve时关闭”标志的文件。
- 调用函数setup_new_exec。函数setup_new_exec调用函数arch_pick_mmap_layout以设置内存映射的布局,在堆和栈之间有一个内存映射区域,传统方案是内存映射区域向栈的方向扩展,另一种方案是内存映射区域向堆的方向扩展,从两种方案中选择一种。然后把进程的名称设置为目标程序的名称,设置用户虚拟地址空间的大小。
- 以前调用函数bprm_mm_init创建了临时的用户栈,现在调用函数set_arg_pages把用户栈定下来,更新用户栈的标志位和访问权限,把用户栈移动到最终的位置,并且扩大用户栈。
- 把所有可加载段映射到进程的虚拟地址空间。
- 调用函数setbrk把未初始化数据段映射到进程的用户虚拟地址空间,并且设置堆的起始虚拟地址,然后调用函数padzero用零填充未初始化数据段。
- 得到程序的入口。如果程序有解释器段,那么把解释器程序中的所有可加载段映射到进程的用户虚拟地址空间,程序入口是解释器程序的入口,否则就是目标程序自身的入口。
- 调用函数create_elf_tables依次把传递ELF解释器信息的辅助向量、环境指针数组envp、参数指针数组argv和参数个数argc压到进程的用户栈。
- 调用函数start_thread设置结构体pt_regs中的程序计数器和栈指针寄存器。当进程从用户模式切换到内核模式时,内核把用户模式的各种寄存器保存在内核栈底部的结构体pt_regs中。因为不同处理器架构的寄存器不同,所以各种处理器架构必须自定义结构体pt_regs和函数start_thread,ARM64架构定义的函数start_thread如下:
arch/arm64/include/asm/processor.h
static inline void start_thread_common(struct pt_regs *regs, unsigned long pc)
{
memset(regs, 0, sizeof(*regs));
regs->syscallno = ~0UL;
regs->pc = pc; /* 把程序计数器设置为程序的入口 */
}
static inline void start_thread(struct pt_regs *regs, unsigned long pc,
unsigned long sp)
{
start_thread_common(regs, pc);
regs->pstate = PSR_MODE_EL0t; /* 把处理器状态设置为0,其中异常级别是0 */
regs->sp = sp; /*设置用户栈指针 */
}
- 装载脚本程序
脚本程序的主要特征是:前两字节是“#!”,后面是解释程序的名称和参数。解释程序用来解释执行脚本程序。
如下,源文件“fs/binfmt_script.c”定义的函数load_script负责装载脚本程序,主要步骤如下:
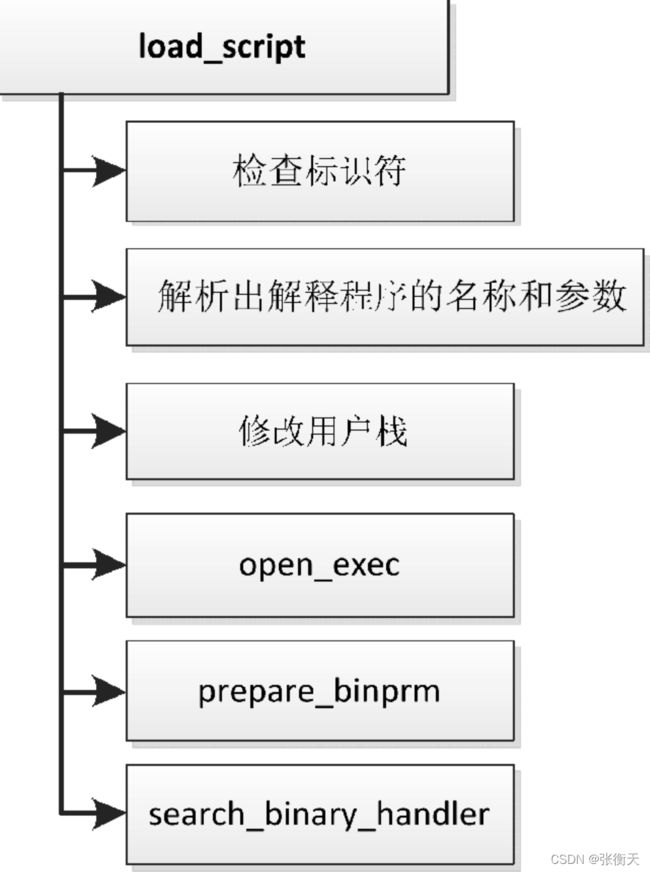
- 检查前两字节是不是脚本程序的标识符。
- 解析出解释程序的名称和参数。
- 从用户栈删除第一个参数,然后依次把脚本程序的文件名称、传给解释程序的参数和解释程序的名称压到用户栈。
- 调用函数open_exec打开解释程序文件。
- 调用函数prepare_binprm设置进程证书,然后读取解释程序文件的前128字节到缓冲区。
- 调用函数search_binary_handler,尝试注册过的每种二进制格式的处理程序,直到某个处理程序识别解释程序为止。
2. 进程退出
进程退出分两种情况:进程主动退出和终止进程。
Linux内核提供了以下两个使进程主动退出的系统调用。
- exit用来使一个线程退出。
void exit(int status); - Linux私有的系统调用exit_group用来使一个线程组的所有线程退出。
void exit_group(int status);
glibc库封装了库函数exit、_exit和_Exit用来使一个进程退出,这些库函数调用系统调用exit_group。库函数exit和_exit的区别是exit会执行由进程使用atexit和on_exit注册的函数。
注意:我们编写用户程序时调用的函数exit,是glibc库的函数exit,不是系统调用exit。
终止进程是通过给进程发送信号实现的,Linux内核提供了发送信号的系统调用。
- kill用来发送信号给进程或者进程组。
int kill(pid_t pid, int sig); - tkill用来发送信号给线程,参数tid是线程标识符。
int tkill(int tid, int sig); - tgkill用来发送信号给线程,参数tgid是线程组标识符,参数tid是线程标识符。
int tgkill(int tgid, int tid, int sig);
tkill和tgkill是Linux私有的系统调用,tkill已经废弃,被tgkill取代。
当进程退出的时候,根据父进程是否关注子进程退出事件,处理存在如下差异。
- 如果父进程关注子进程退出事件,那么进程退出时释放各种资源,只留下一个空的进程描述符,变成僵尸进程,发送信号SIGCHLD(CHLD是child的缩写)通知父进程,父进程在查询进程终止的原因以后回收子进程的进程描述符。
- 如果父进程不关注子进程退出事件,那么进程退出时释放各种资源,释放进程描述符,自动消失。
进程默认关注子进程退出事件,如果不想关注,可以使用系统调用sigaction针对信号SIGCHLD设置标志SA_NOCLDWAIT(CLD是child的缩写),以指示子进程退出时不要变成僵尸进程,或者设置忽略信号SIGCHLD。
怎么查询子进程终止的原因?Linux内核提供了3个系统调用来等待子进程的状态改变,状态改变包括:子进程终止,信号SIGSTOP使子进程停止执行,或者信号SIGCONT使子进程继续执行。这3个系统调用如下。
- pid_t waitpid(pid_t pid, int *wstatus, int options);
- int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
- pid_t wait4(pid_t pid, int *wstatus, int options, struct rusage *rusage);
注意:wait4已经废弃,新的程序应该使用waitpid和waitid。
子进程退出以后需要父进程回收进程描述符,如果父进程先退出,子进程成为“孤儿”,谁来为子进程回收进程描述符呢?父进程退出时需要给子进程寻找一个“领养者”,按照下面的顺序选择领养“孤儿”的进程。
- 如果进程属于一个线程组,且该线程组还有其他线程,那么选择任意一个线程。
- 选择最亲近的充当“替补领养者”的祖先进程。进程可以使用系统调用prctl(PR_SET_CHILD_SUBREAPER)把自己设置为“替补领养者”(subreaper)。
- 选择进程所属的进程号命名空间中的1号进程。
2.1 线程组退出
系统调用exit_group实现线程组退出,执行流程如图2.17所示,把主要工作委托给函数do_group_exit,执行流程如下:

- 如果线程组正在退出,那么从信号结构体的成员group_exit_code取出退出码。
- 如果线程组未处于正在退出的状态,并且线程组至少有两个线程,那么处理如下:
- 关中断并申请锁。
- 如果线程组正在退出,那么从信号结构体的成员group_exit_code取出退出码。
- 如果线程组未处于正在退出的状态,那么处理如下:
- 把退出码保存在信号结构体的成员group_exit_code中,传递给其他线程。
- 给线程组设置正在退出的标志。
- 向线程组的其他线程发送杀死信号,然后唤醒线程,让线程处理杀死信号。
- 释放锁并开中断
- 当前线程调用函数do_exit以退出。
假设一个线程组有两个线程,称为线程1和线程2,线程1调用exit_group使线程组退出,线程1的执行过程如下:
- 把退出码保存在信号结构体的成员group_exit_code中,传递给线程2。
- 给线程组设置正在退出的标志。
- 向线程2发送杀死信号,然后唤醒线程2,让线程2处理杀死信号。
- 线程1调用函数do_exit以退出。
线程2退出的执行流程如下所示,线程2准备返回用户模式的时候,发现收到了杀死信号,于是处理杀死信号,调用函数do_group_exit,函数do_group_exit的执行过程如下:
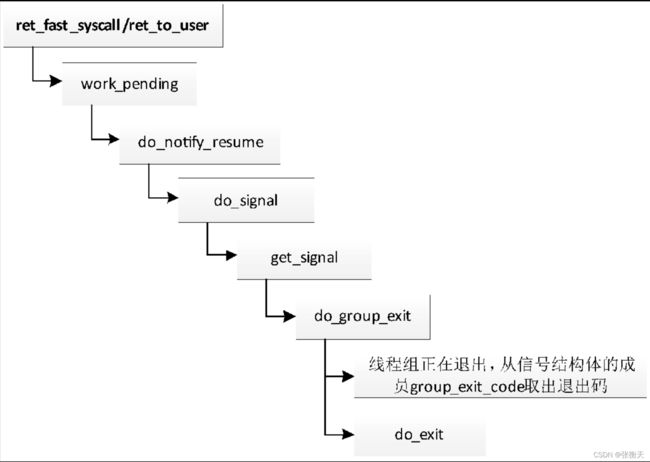
- 因为线程组处于正在退出的状态,所以线程2从信号结构体的成员group_exit_code取出退出码。
- 线程2调用函数do_exit以退出。
线程2可能在以下3种情况下准备返回用户模式:
- 执行完系统调用。
- 被中断抢占,中断处理程序执行完。
- 执行指令时生成异常,异常处理程序执行完
函数do_exit的执行过程如下:
- 释放各种资源,把资源对应的数据结构的引用计数减一,如果引用计数变成0,那么释放数据结构。
- 调用函数exit_notify,先为成为“孤儿”的子进程选择“领养者”,然后把自己的死讯通知父进程。
- 把进程状态设置为死亡(TASK_DEAD)。
- 最后一次调用函数__schedule以调度进程
2.2 中止进程
系统调用kill(源文件“kernel/signal.c”)负责向线程组或者进程组发送信号,执行流程如下:
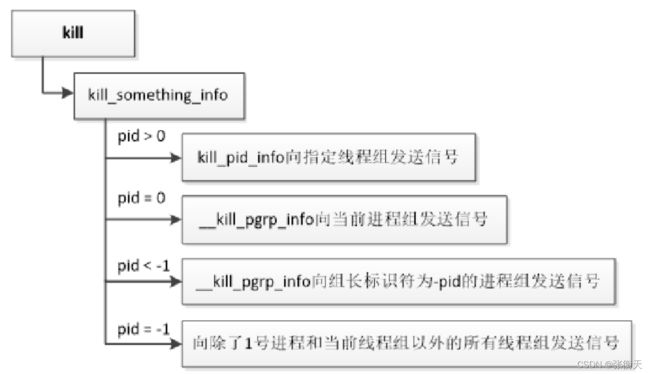
- 如果参数pid大于0,那么调用函数kill_pid_info来向线程pid所属的线程组发送信号。
- 如果参数pid等于0,那么向当前进程组发送信号。
- 如果参数pid小于−1,那么向组长标识符为-pid的进程组发送信号。
- 如果参数pid等于−1,那么向除了1号进程和当前线程组以外的所有线程组发送信号
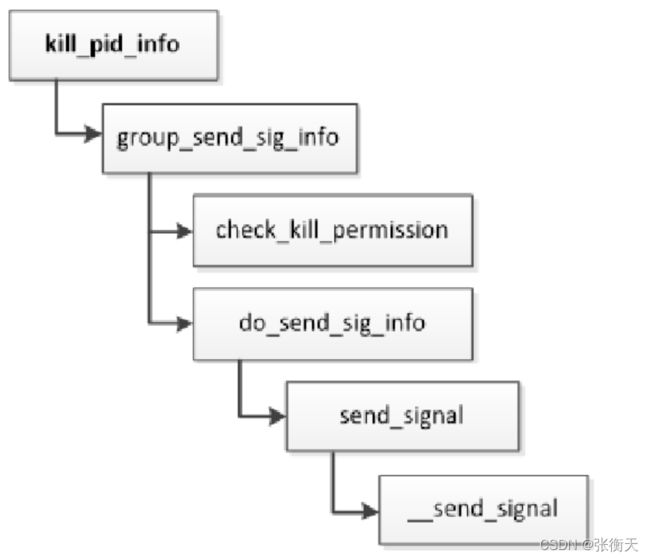
函数kill_pid_info负责向线程组发送信号,执行流程如下所示,函数check_kill_permission检查当前进程是否有权限发送信号,函数__send_signal负责发送信号:
2.3 查询子进程终止原因
系统调用waitid的原型如下:
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
参数idtype指定标识符类型,支持以下取值:
- P_ALL:表示等待任意子进程,忽略参数id。
- P_PID:表示等待进程号为id的子进程。
- P_PGID:表示等待进程组标识符是id的任意子进程
参数options是选项,取值是0或者以下标志的组合:
- WEXITED:等待退出的子进程。
- WSTOPPED:等待收到信号SIGSTOP并停止执行的子进程。
- WCONTINUED:等待收到信号SIGCONT并继续执行的子进程。
- WNOHANG:如果没有子进程退出,立即返回。
- WNOWAIT:让子进程处于僵尸状态,以后可以再次查询状态信息。
系统调用waitpid的原型是:
pid_t waitpid(pid_t pid, int *wstatus, int options);
系统调用wait4的原型是:
pid_t wait4(pid_t pid, int *wstatus, int options,struct rusage *rusage);
参数pid的取值如下。
- 大于0,表示等待进程号为pid的子进程。
- 等于0,表示等待和调用进程属于同一个进程组的任意子进程。
- 等于−1,表示等待任意子进程。
- 小于−1,表示等待进程组标识符是pid的绝对值的任意子进程。
参数options是选项,取值是0或者以下标志的组合。
- WNOHANG:如果没有子进程退出,立即返回。
- WUNTRACED:如果子进程停止执行,但是不被ptrace跟踪,那么立即返回。
- WCONTINUED:等待收到信号SIGCONT并继续执行的子进程。
以下选项是Linux私有的,和使用clone创建子进程一起使用。
- __WCLONE:只等待克隆的子进程。
- __WALL:等待所有子进程。
- __WNOTHREAD:不等待相同线程组中其他线程的子进程。
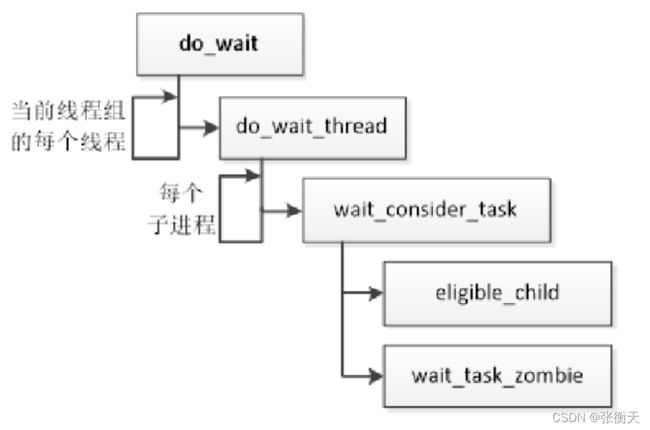
系统调用waitpid、waitid和wait4把主要工作委托给函数do_wait,函数do_wait的执行流程如下所示,遍历当前线程组的每个线程,针对每个线程遍历它的每个子进程,如果是僵尸进程,调用函数eligible_child来判断是不是符合等待条件的子进程,如果符合等待条件,调用函数wait_task_zombie进行处理。
函数wait_task_zombie的执行流程如下。
- 如果调用者没有传入标志WEXITED,说明调用者不想等待退出的子进程,那么直接返回。
- 如果调用者传入标志WNOWAIT,表示调用者想让子进程处于僵尸状态,以后可以再次查询子进程的状态信息,那么只读取进程的状态信息,从线程的成员exit_code读取退出码。
- 如果调用者没有传入标志WNOWAIT,处理如下。
- 读取进程的状态信息。如果线程组处于正在退出的状态,从线程组的信号结构体的成员group_exit_code读取退出码;如果只是一个线程退出,那么从线程的成员exit_code读取退出码。
- 把状态切换到死亡,释放进程描述符。