ElasticSearch7学习笔记之排序、分页遍历和对象
文章目录
- 排序
-
- 简介
- 示例
-
- 单字段排序
- 多字段排序
- text字段排序
- 排序的两种方法
- 分页与遍历
-
- 深度分页问题
- SearchAfter
- ScrollAPI
- 不同的搜索类型和使用场景
- 并发控制
- 对象、嵌套对象、文档的父子关系
-
- 对象
- 嵌套对象
- 嵌套聚合
- 父子关系
-
- 设置索引关系
- 索引父文档
- 索引子文档
- 查询
-
- 根据父文档ID查询父文档
- 根据parentID查询父文档
- hasChild查询
- hasParent查询
- get方法查询子文档
- 更新子文档
- 嵌套对象和父子文档的对比
排序
简介
es的排序是针对字段原始内容进行的,此时要用到正排索引,也就是通过文档id和字段快速得到字段原始内容
示例
单字段排序
针对单字段的排序如下
POST /kibana_sample_data_ecommerce/_search
{
"size": 5,
"query": {
"match_all": {}
},
"sort": [
{
"order_date": {
"order": "desc"
}
}
]
}
多字段排序
针对多字段的排序如下,排序优先级从上往下递减
POST /kibana_sample_data_ecommerce/_search
{
"size": 5,
"query": {"match_all": {}},
"sort": [
{
"order_date": {
"order": "desc"
}
},
{
"_doc" : {
"order": "asc"
}
},
{
"_score": {
"order": "asc"
}
}
]
}
加入id是为了保证排序的唯一性。
text字段排序
如果要对text字段进行排序,要先打开它的fielddata
#打开customer_full_name字段的fielddata
PUT /kibana_sample_data_ecommerce/_mapping
{
"properties": {
"customer_full_name": {
"type": "text",
"fielddata": "true",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
然后再按其进行排序
POST /kibana_sample_data_ecommerce/_search
{
"size": 5,
"query": {
"match_all": {}
},
"sort": [
{
"customer_full_name": {
"order": "desc"
}
}
]
}
排序的两种方法
Fielddata和DocValues(列式存储,对text无效),他们的对比如下所示
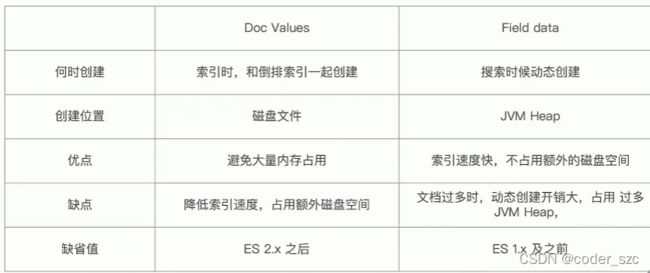
docValues也可以通过Mapping关闭,以增加索引速度、减少磁盘空间,但重新打开时就要重建索引。
分页与遍历
深度分页问题
当一个查询from=990,size=10,es会在每个分片上先都获取1000个文档,然后通过CoordinatingNode聚合所有结果,最后再通过排序选取前1000个文档,如下图所示,此时的分片又称之为分页

当页数过多时,这么做会带来巨大的内存开销,所以es中默认限制文档数为10000,可通过index.max_result_window来改变
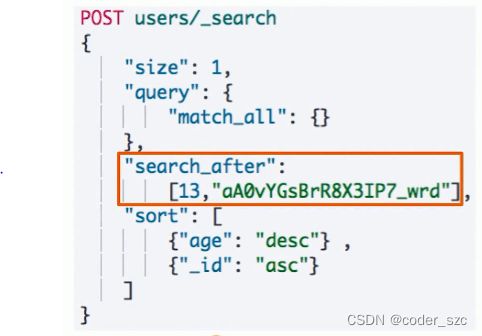
SearchAfter
SearchAfter可以避免深度分页的性能问题,实时获取下一页文档信息,但是不支持指定页数(from),而且只能往下翻。
原理是它通过唯一排序值定位,将每次要处理的文档数都控制在size数
使用时,第一步搜索需要指定sort,并且保证值是唯一的(可通过加入_id来保证),以后的查询就可以把上一次查询结果的最后一个sort值写入这次查询的search_after中,实现翻页
ScrollAPI
它的做法是创建一个快照,但会导致新数据写入后无法被查到
使用时要先创建scroll快照,指定存活时间(5分钟)
POST users/_search?scroll=5m
{
"size": 1,
"query": {
"match_all": {}
}
}
发出后会得到一个scrollId
{
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAeUsWSmhjUi1Ya3hUMnVZM1V1YlRwZlpBUQ==",
....
}
以后的查询就可以用这个的scrollId实现翻页了,页面大小由创建快照时的size值确定
POST _search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAecsWSmhjUi1Ya3hUMnVZM1V1YlRwZlpBUQ=="
}
得到的第二条数据如下
{
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAecsWSmhjUi1Ya3hUMnVZM1V1YlRwZlpBUQ==",
"took" : 1,
"timed_out" : false,
"terminated_early" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "users",
"_type" : "_doc",
"_id" : "IPCjeXMBH-WRg-nMygZ6",
"_score" : 1.0,
"_source" : {
"first_name" : "a",
"last_name" : "b"
}
}
]
}
}
不同的搜索类型和使用场景
Regular:需要实时获取顶部的部分文档,例如查询最新订单
Scroll:需要全部文档,例如导出全部数据
分页:可用From+Size,如果需要深度分页,则选用SearchAfter或ScrollAPI
并发控制
es采用的是乐观锁,假定冲突不会发生,也不会阻塞正在尝试的操作。如果数据在读写中被修改,更新就会失败,应用程序决定如何解决冲突
es中可以通过id_seq_no和if_primary_term来一起控制文档的内部版本
PUT users/_doc/1?if_seq_no=1&if_primary_term=1
{
"first_name": "a",
"last_name": "b"
}
如果使用其他数据库进行主要的数据存储,而ES只是用来查询的话,就可以使用version+version_type来控制外部版本
PUT users/_doc/1?version=1&version_type=external
{
"first_name": "a",
"last_name": "b"
}
对象、嵌套对象、文档的父子关系
es中可以用对象、嵌套对象、父子关联关系或者在应用端关联等方式来处理关联关系
对象
对象不用多说,就是多个键值对的组合,如下所示
POST my_movies/_doc/1
{
"title": "Speed",
"actors": [
{
"first_name": "Keanu",
"last_name": "Reeves"
},
{
"first_name": "Dennis",
"last_name": "Hopper"
}
]
}
事先指定my_movies索引的Mapping
PUT my_movies
{
"mappings": {
"properties": {
"actors": {
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
然后对一个不存在的演员Reeves Hopper做查询,会发现还会查到Speed电影
POST my_movies/_doc/1
{
"title": "Speed",
"actors": [
{
"first_name": "Keanu",
"last_name": "Reeves"
},
{
"first_name": "Dennis",
"last_name": "Hopper"
}
]
}
这是因为es中所有的对象都被进行了扁平化处理,没有考虑对象的边界。
这个问题可以用nestedDataType解决
嵌套对象
先看声明方法
PUT my_movies
{
"mappings": {
"properties": {
"actors": {
"type": "nested",
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
嵌套数据类型允许对象数组中的对象被独立索引,上例中使用nested和properties关键字会将所有actors索引到多个单独的文档。在内部,nested文档会被保存到两个Lucene文档中,在查询时做Join处理
插入相同数据后,再进行嵌套查询,这次先查Keanu Reeves,嵌套查询里得指定嵌套对象的path,也就是需要对哪个字段进行嵌套,一般就是nested字段
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Reeves"
}
}
]
}
}
}
}
]
}
}
}
会得到电影生死时速,如果换成Keanu Hopper就不行了
嵌套聚合
嵌套聚合时,也要对嵌套字段声明为nested,并且指明path
POST my_movies/_search
{
"size": 0,
"aggs": {
"actors": {
"nested": {
"path": "actors"
},
"aggs": {
"actor_name": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
}
}
父子关系
对象和嵌套对象有个局限:每次更新时,需要重新索引整个对象(包括根对象和嵌套对象)。而es提供了类似关系型数据库中join的实现,使用join数据类型可以通过维护父子关系,分离两个对象。
父文档和子文档是两个独立的文档,因袭更新父文档不必重新索引子文档,子文档的增删改也不会影响到父文档和其他子文档
定义父子关系的几个步骤:
1)、设置索引的Mapping
2)、索引父文档
3)、索引子文档
4)、查询文档
设置索引关系
设置索引Mapping方法如下
PUT my_blogs
{
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "text"
}
}
}
}
其中join类型字段就是声明了父子文档的关系,此处blog为父文档,comment为子文档
索引父文档
然后索引两个父文档
PUT my_blogs/_doc/blog1
{
"title": "Learning ElasticSearch",
"content": "Learning ELK",
"blog_comments_relation": {
"name": "blog"
}
}
PUT my_blogs/_doc/blog2
{
"title": "Learning Hadoop",
"content": "learning Hadoop",
"blog_comments_relation": {
"name": "blog"
}
}
其中blog_comments_relation声明这个文档是blog文档,也就是父文档
索引子文档
然后索引两个子文档,分别和两个父文档对应
PUT my_blogs/_doc/comment1?routing=blog1
{
"comment": "I`m learning ELK",
"username": "szc",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
PUT my_blogs/_doc/comment2?routing=blog2
{
"comment": "I`m learning Hadoop",
"username": "zeceng",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
参数routing用来保证父子文档索引到相同的分片,因为为了确保join的性能,父子文档必须在相同的分片上
blog_comments_relation字段用来声明这个文档是子文档,以及它的父文档
查询
最后进行一些查询,先查询所有
POST my_blogs/_search
{
"query": {"match_all": {}}
}
可以看到所有父子文档都会被查出来
"hits" : [
{
"_index" : "my_blogs",
"_type" : "_doc",
"_id" : "blog1",
"_score" : 1.0,
"_source" : {
"title" : "Learning ElasticSearch",
"content" : "Learning ELK",
"blog_comments_relation" : {
"name" : "blog"
}
}
},
{
"_index" : "my_blogs",
"_type" : "_doc",
"_id" : "blog2",
"_score" : 1.0,
"_source" : {
"title" : "Learning Hadoop",
"content" : "learning Hadoop",
"blog_comments_relation" : {
"name" : "blog"
}
}
},
{
"_index" : "my_blogs",
"_type" : "_doc",
"_id" : "comment1",
"_score" : 1.0,
"_routing" : "blog1",
"_source" : {
"comment" : "I`m learning ELK",
"username" : "szc",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog1"
}
}
},
{
"_index" : "my_blogs",
"_type" : "_doc",
"_id" : "comment2",
"_score" : 1.0,
"_routing" : "blog2",
"_source" : {
"comment" : "I`m learning Hadoop",
"username" : "zeceng",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog2"
}
}
}
]
根据父文档ID查询父文档
再根据父文档id对父文档进行普通查询
GET my_blogs/_doc/blog1
会发现不会查到相应的子文档
"_source" : {
"title" : "Learning ElasticSearch",
"content" : "Learning ELK",
"blog_comments_relation" : {
"name" : "blog"
}
}
根据parentID查询父文档
换成根据parentId查就不一样了
POST my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog1"
}
}
}
会看到子文档被查出来了
"hits" : [
{
"_index" : "my_blogs",
"_type" : "_doc",
"_id" : "comment1",
"_score" : 0.6931471,
"_routing" : "blog1",
"_source" : {
"comment" : "I`m learning ELK",
"username" : "szc",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog1"
}
}
}
]
hasChild查询
hasChild查询会根据子文档的类型和条件返回父文档
POST my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"match": {
"username": "szc"
}
}
}
}
}
结果如下
"hits" : [
{
"_index" : "my_blogs",
"_type" : "_doc",
"_id" : "blog1",
"_score" : 1.0,
"_source" : {
"title" : "Learning ElasticSearch",
"content" : "Learning ELK",
"blog_comments_relation" : {
"name" : "blog"
}
}
}
]
而hasParent则相反,根据父文档的类别和条件查子文档
hasParent查询
POST my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query": {
"match": {
"title": "Hadoop"
}
}
}
}
}
结果如下
"hits" : [
{
"_index" : "my_blogs",
"_type" : "_doc",
"_id" : "comment2",
"_score" : 1.0,
"_routing" : "blog2",
"_source" : {
"comment" : "I`m learning Hadoop",
"username" : "zeceng",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog2"
}
}
}
]
get方法查询子文档
使用get方法查询子文档时,要加上routing参数,否则不会有结果
GET my_blogs/_doc/comment2?routing=blog2
返回结果如下
"_source" : {
"comment" : "I`m learning Hadoop",
"username" : "zeceng",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog2"
}
}
更新子文档
更新子文档和索引子文档一样,需要在子文档id后面加上routing参数,值为父文档id
PUT my_blogs/_doc/comment2?routing=blogs
{
"comment": "I like Hadoop!",
"username": "zeceng",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
嵌套对象和父子文档的对比
两者的优缺点和适用场景如下表所示
| 嵌套对象 | 父子文档 | |
|---|---|---|
| 优点 | 文档存储在一起,读取性能高 | 父子文档可以独立更新 |
| 缺点 | 更新嵌套子文档时,要更新整个文档 | 需要额外的内存维护关系,读取性能相对差 |
| 使用场景 | 子文档偶尔更新,以查询为主 | 子文档更新频繁 |