Java中Object类的各种方法详解
文章目录
-
- 1.registerNatives()
- 2.getClass()
- 3.hashCode()
- 4.equals(Object obj)
- 5.clone()
- 6.toString()
- 7.notify()、notifyAll()
- 8.wait(long timeout)、wait(long timeout, int nanos)、wait()
- 9.finalize()
1.registerNatives()
源码:
private static native void registerNatives();
static {
registerNatives();
}
我对这个方法暂时还不太理解,后面我补回来!这个跟JNI有关,而我工作中会用到JNI,虽然现在还不会用,哈哈哈!!
2.getClass()
源码:
public final native Class<?> getClass();
首先,这个方法是被final 修饰的,你平时写一个类,可以通过那个类的对象调用Object的这个方法,所以说,被final修饰的方法,是可以被继承的,但是不能被重写。
方法注释是这么说的:
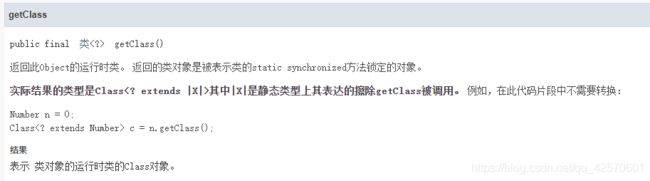
什么是运行时类?
我们通过eclipse写一段代码,不调试和运行,把它保存起来,会变成一个后缀为 .java 的文件,我们把它叫做源文件,里面的东西就我们自己写的能看懂的代码。这个类就是编译时类。
我们都知道C语言的源文件,要经过编译,才可以生成一个后缀为 .exe 的可执行文件。Java和C的道理是一样的,只不过Java的源文件经过编译后,会生成一个后缀为 .class 的文件,这些 .class文件很明显是不能直接运行的,它不像C语言(编译cpp后生成exe文件直接运行),这些 .class文件是交由JVM来解析运行。这个 .class 文件,就是运行时类。
当我们调用getClass()方法的时候,返回的正是这个类的 .class 文件。这个方法,是我们反射的三种方式之一。
3.hashCode()
源码:
public native int hashCode();
首先这个方法的返回值是int类型,所以hashcode算出来的hash值都是int范围内的值:-2^31 ~ 2^31 - 1
默认的hashCode是将内存地址转换为hash值,重写过后才会是自定义的计算方式;你也可以通过调用System.identityHashCode(Object)来返回原本的hashCode。所以说这个方法如果不在子类重写,就失去了他本身存在的作用与意义。
方法注释是这么说的:
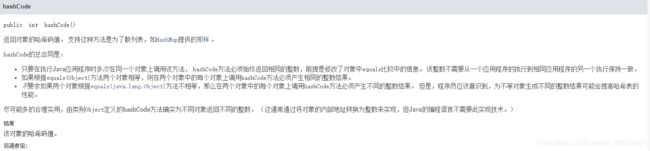
现在我们来看这样一个问题(我秋招时被问到过,嗯嗯,问我的这个人现在是我领导,哈哈哈):
有一个Student类,里面就一个构造方法和一个String属性,你现在一顿操作写了下面的代码:
HashMap<Object, String> map = new HashMap<Object, String>();
map.put(new Student("学生"), "学生");
过了一会你想把它取出来,于是你就map.get(new Student("学生"))这样又来一顿操作。那么问题来了,你能不能得到预期的结果?为什么?
答案是否定的,当你将一个对象作为hashmap的键值的时候,虚拟机会调用该对象的hashcode方法,返回一个hash值,以此来作为映射中的唯一标识。但是Student类并没有重写Object类中的hashcode方法,所以他的对象调用的还是默认的hashcode,默认的hashcode方法是将内存地址转换为hash值,所以上面那个问题,map.put(new Student("学生"), "学生");时new了一个对象,map.get(new Student("学生"))时又new了一个对象,这两个对象看似一样,实际上他们在堆内存中被分配在不同的内存块上,所以通过默认的hashcode返回的两个hash值是不一样,也就不能得到预期的结果。
那我们应该怎么操作,才能得到呢?
重写hashcode方法就能做到:
@Override
public int hashCode() {
Object[] a = Stream.of(s).toArray();
int result = 1;
for (Object element : a) {
result = 31 * result + (element == null ? 0 : element.hashCode());
}
return result;
}
上面我们重写时为什么要用result = 31 * result + (element == null ? 0 : element.hashCode());呢?
因为你阅读源码就会发现,String类、Arrays类等很多类都是这么写的。
那为什么他们要这么写呢?
比较靠谱的解释是:result * 31 = (result<<5) - result,JVM底层可以自动做优化为位运算,效率很高;还有因为31计算的hashCode冲突较少,利于hash桶位的分布。
4.equals(Object obj)
源码:
public boolean equals(Object obj) {
return (this == obj);
}
方法注释:

这个方法就没有那么多的五五六六七七了,看源码就知道,如果不重写,默认的equals方法和==的功能是一样的,==比较的是两个对象的地址是否相同。
Student c1 = new Student("学生");
Student c2 = new Student("学生");
//没重写equals方法时
System.out.println(c1.equals(c2));// false
System.out.println(c1 == c2);// false
//重写了equals方法时:
System.out.println(c1.equals(c2));// true
System.out.println(c1 == c2);// false
那应该如何重写equals方法?
@Override
public boolean equals(Object obj) {
// 先判断是否为同一对象
if (this == obj) {
return true;
}
// 再判断目标对象是否为当前类或者当前类的子类的实例对象
if (!(obj instanceof Student)) {
return false;
}
// 这一步强转是必须的
Student o = (Student) obj;
return o.s.equals(this.s);
}
为什么要重写呢?
因为如果不重写equals方法,当将自定义对象放到map或者set中时;如果这时两个对象的hashCode相同,就会调用equals方法进行比较,这个时候会调用Object中默认的equals方法,而默认的equals方法只是比较了两个对象的引用是否指向了同一个对象,显然大多数时候都不会指向,这样就会将重复对象存入map或者set中。这就破坏了map与set不能存储重复对象的特性,会造成内存溢出。
5.clone()
源码:
protected native Object clone() throws CloneNotSupportedException;
方法注释:
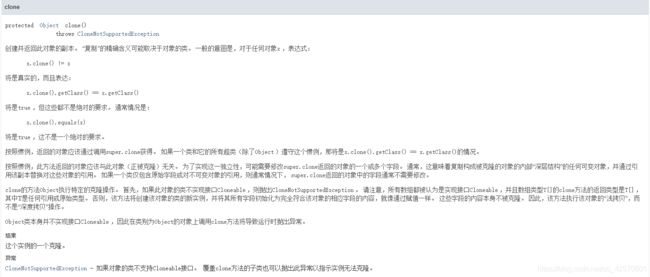
此方法返回当前对象的一个副本,但需要实现Cloneable接口,如果没有实现,虽可以重写,但是当调用object.clone()方法,会抛出CloneNotSupportedException;如果没有重写,则无法调用。Cloneable接口只是一个标记接口,里面啥都没有,所以虽然实现了Cloneable接口,但是重写的方法依旧是Object中的方法。
克隆(复制),他有浅克隆和深克隆,如果一个类的属性只有基本类型,那深克隆和浅克隆是一样的,如果有引用类型,就能体现出他们的不同,看着下面代码理解深克隆和浅克隆的概念:
- 浅克隆:拷贝的是引用。
- 深克隆:新开辟内存空间,进行值拷贝。
Student类有两个属性,age是基本类型,stu是引用类型。对于基本类型,深浅克隆都是值拷贝,基本类型就没有引用拷贝这么一说!对于引用类型,浅克隆是引用拷贝,深克隆是值拷贝。
浅克隆拷贝:
public static void main(String[] args) throws CloneNotSupportedException {
Student c = new Student(18);
Student c1 = new Student(18, c);
Student c2 = (Student) c1.clone();
System.out.println(c1 == c2);// false
System.out.println(c1.toString());// [age = 18,stu.age = 18]
System.out.println(c2.toString());// [age = 18,stu.age = 18]
c.age = 20;// 重点在这里,注意理解下面的stu.age
System.out.println(c1.toString());// [age = 18,stu.age = 20]
System.out.println(c2.toString());// [age = 18,stu.age = 20]
}
//-----------------------------------------------------------------------------
public class Student implements Cloneable {
public int age;
public Student stu;
public Student(int i) {
super();
this.age = i;
}
public Student(int age, Student student) {
super();
this.age = age;
this.stu = student;
}
@Override
public String toString() {
return "[age = " + age + ",stu.age = " + stu.age + "]";
}
@Override
protected Object clone() throws CloneNotSupportedException {
// TODO Auto-generated method stub
return super.clone();
}
}
深克隆拷贝:
public static void main(String[] args) throws CloneNotSupportedException {
Student c = new Student(18);// false
Student c1 = new Student(18, c);
Student c2 = (Student) c1.clone();
System.out.println(c1 == c2);
System.out.println(c1.toString());// [age = 18,stu.age = 18]
System.out.println(c2.toString());// [age = 18,stu.age = 18]
c.age = 20;
System.out.println(c1.toString());// [age = 18,stu.age = 20]
System.out.println(c2.toString());// [age = 18,stu.age = 18]
}
//------------------------------------------------------------------------
@Override
protected Object clone() throws CloneNotSupportedException {
Student clone = (Student) super.clone();
clone.stu = new Student(age);
return clone;
}
6.toString()
源码:
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
方法注释:

从源码上就可以直接看出来,默认的toString方法,只是将当前类的全限定性类名+@+十六进制的hashCode值。一般情况下,我们都是要重写这个方法的,不然返回的那玩意没啥用,那怎么写呢?肯定是写一些对我们来说有用的东西,打印当前对象的类属性值什么的。
@Override
public String toString() {
return "[s = " + s + "]";
}
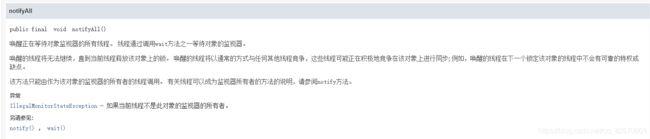
7.notify()、notifyAll()
源码:
public final native void notify();
public final native void notifyAll();
方法注释:
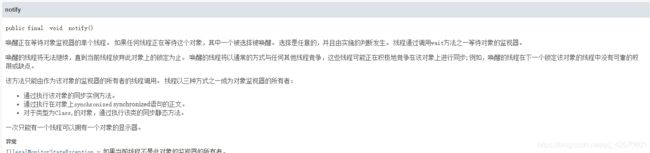
8.wait(long timeout)、wait(long timeout, int nanos)、wait()
这部分主要和多线程的操作有关,包括上面的notify方法,直接进这里传送门:https://blog.csdn.net/qq_42570601/article/details/100182420
9.finalize()
源码:
protected void finalize() throws Throwable { }
方法注释:
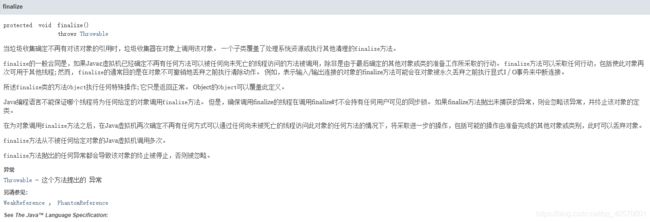
这个方法理解的过程曾让我觉得我的中文理解能力有问题,Java编程思想第四版,感觉这个书翻译过来后读起来好拗人啊!哎,我太难了!最后还是从网上零七八碎的看懂了些。
finalize()方法总结起来具有下面4个特点,编程思想上面基本都说到了:
- 永远不要主动调用某个对象的finalize()方法,该方法由垃圾回收机制自己调用;
- finalize()何时被调用,是否被调用具有不确定性;
- 当JVM执行可恢复对象的finalize()可能会将此对象重新变为可达状态;
- 当JVM执行finalize()方法时出现异常,垃圾回收机制不会报告异常,程序继续执行。
下面的内容是从网上直接搬过来的https://blog.csdn.net/liuc0317/article/details/6149578
我们先看一个对象在内存中的状态有哪些情况吧! 当一个对象在堆内存中运行时,根据它被引用变量所引用的状态,可以所它所处的状态分成三种:
- 激活状态:当一个对象被创建后,有一个或一个以上的引用变量引用它,则这个对象在程序中处于激活状态,程序可以通过引用变量来调用该对象的方法和属性。
- 去活状态:如果程序中某个对象不再有任何引用变量引用它,它就进入了去活状态,在这个状态下,系统的垃圾回收机制准备 回收该对象所占用的内存空间,在回收该对象之前,系统会调用所有对象的finalize方法进行资源的清理,如果系统在调用finalize方法重新让一个引用变量引用该对象,则这个对象会再次变为激活状态,否则该 对象状进入死亡状态。
- 死亡状态:当对象与所有引用变量的关联都被切继,且系统已经调用所有对象的finalize方法依然没有该对象变成激活状态,那这个对象将永久性地失去引用,最后变成死亡状态,只有当一个对象处于死亡状态时统才会真正回收该对象所占有的资源。