pandas-cut 函数
前言
数值数据在数据分析中很常见。 通常,您拥有连续的、非常大的比例或高度偏斜的数值数据。有时,将这些数据分成离散的区间会更容易。 当值被划分为有意义的类别时,这有助于执行描述性统计。例如,我们可以将确切的年龄划分为幼儿、儿童、成人和老年人。
Pandas 内置的 cut() 函数是将数值数据转换为分类数据的好方法。
参数及解释
pandas.cut(x, bins, right=True, labels=None, retbins=False,\
precision=3, include_lowest=False, duplicates='raise', \
ordered=True)x : 是我们要传入和切分的一维数组,可以是列表,也可以是dataFrame的一列
bins : 代表切片的方式,可以自定义传入列表[a,b,c],表示按照a-b,b-c的区间来切分,也可以是数值n,直接指定分为n组
right : True/False,为True时,表示分组区间是包含右边,不包含左边,即(]; False,代表[)
labels : 标签参数,比如[低、中、高]
retbins : True/False, True返回bin的具体范围值,当bins是单个数值时很有用。(因为bin是数字的话, 划分组具体数值我们是不知道的)
precision : 存储和显示 bin 标签的精度。默认为3
include_lowest : True/False, 第一个区间是否应该是左包含的
duplicates : raise/drop, 如果bin列表里有重复,报错/直接删除至保留一个
ordered : 标签是否有序。 适用于返回的类型 Categorical 和 Series(使用 Categorical dtype)。 如果为 True,则将对生成的分类进行排序。 如果为 False,则生成的分类将是无序的(必须提供标签)
各参数:
bin=number
import pandas as pd
df = pd.DataFrame({'age': [2, 67, 40, 32, 4, 15, 82, 99, 26, 30]})
df['age_group'] = pd.cut(df['age'], 3)
这些区间值的开头有一个圆括号,结尾有一个方括号,例如 (1.903, 34.333]。
这基本上意味着圆括号一侧的任何值都不包含在区间中,而包括方括号的一侧(在数学中称为开闭区间)
df['age_group']
0 (1.903, 34.333]
1 (66.667, 99.0]
2 (34.333, 66.667]
3 (1.903, 34.333]
4 (1.903, 34.333]
5 (1.903, 34.333]
6 (66.667, 99.0]
7 (66.667, 99.0]
8 (1.903, 34.333]
9 (1.903, 34.333]
Name: age_group, dtype: category
Categories (3, interval[float64, right]): [(1.903, 34.333] < (34.333, 66.667] < (66.667, 99.0]]
显示类型为:category, 3个标签名(1.903, 34.333] 、 (34.333, 66.667] 、 (66.667, 99.0], 这些符号通过"<"来连接,计算方式如下:
interval = (max_value — min_value) / num_of_bins
= (99 - 2) / 3
= 32.33333
(<--32.3333-->] < (<--32.3333-->] < (<--32.3333-->]
(1.903, 34.333] < (34.333, 66.667] < (66.667, 99.0]#这里再解释下开区间数值是怎么来的。我们先看下左闭右开,即right=False
pd.cut(df['age'], 3, right=False)
0 [2.0, 34.333)
1 [66.667, 99.097)
2 [34.333, 66.667)
3 [2.0, 34.333)
4 [2.0, 34.333)
5 [2.0, 34.333)
6 [66.667, 99.097)
7 [66.667, 99.097)
8 [2.0, 34.333)
9 [2.0, 34.333)
Name: age, dtype: category
Categories (3, interval[float64, left]): [[2.0, 34.333) < [34.333, 66.667) < [66.667, 99.097)]闭区间所在("[]"),即最小值和最大值。但是开区间是有差异的。
计算方式源代码:${pkg}/pandas/core/reshape/tile.py 第266行
adj = (mx - mn) * 0.001 # 0.1% of the range
if right: #左开右闭
bins[0] -= adj #2-(99-2)*0.001 = 1.903
else: #左闭右开
bins[-1] += adj #99 + (99-2)*0.001 = 99.097你...学废了吗?
bin传入指定的列表
df['age_group'] = pd.cut(df['age'], bins=[0, 12, 19, 61, 100])
df['age_group']
0 (0, 12]
1 (61, 100]
2 (19, 61]
3 (19, 61]
4 (0, 12]
5 (12, 19]
6 (61, 100]
7 (61, 100]
8 (19, 61]
9 (19, 61]
Name: age_group, dtype: category
Categories (4, interval[int64, right]): [(0, 12] < (12, 19] < (19, 61] < (61, 100]]此时的左开右闭区间为:(0, 12] < (12, 19] < (19, 61] < (61, 100]
#sort_values
df.sort_values('age_group')
#对每个Categories进行计数
df['age_group'].value_counts().sort_index()
(0, 12] 2
(12, 19] 1
(19, 61] 4
(61, 100] 3
Name: age_group, dtype: int64添加label
bins=[0, 12, 19, 61, 100]
labels=['<12', 'Teen', 'Adult', 'Older']
df = pd.DataFrame({'age': [2, 67, 40, 32, 4, 15, 82, 99, 26, 30]})
df['age_group'] = pd.cut(df['age'], bins, labels=labels)
#这时候age_group不再是显示一个区间了,而是具体的标签了
#sort
#df['age_group'].value_counts().sort_index()
include_lowest
假设将上述年龄值划分为 2-12、12-19、19-60、61-100。
将bin设置为 [2, 12, 19, 61, 100] 时,第一个数字将不包含在内,将得到包含 NaN 的结果。
df['age_group'] = pd.cut(df['age'], bins=[2, 12, 19, 61, 100],\
include_lowest=True)
当然,我们也可以为bin传入IntervalIndex
bins = pd.IntervalIndex.from_tuples([(0, 12), (19, 61), (61, 100)])
bins
输出:
IntervalIndex([(0, 12], (19, 61], (61, 100]], dtype='interval[int64, right]')
df['age_group'] = pd.cut(df['age'], bins)
df
#从而可以将我们不需要的部分删除掉,或者做其他处理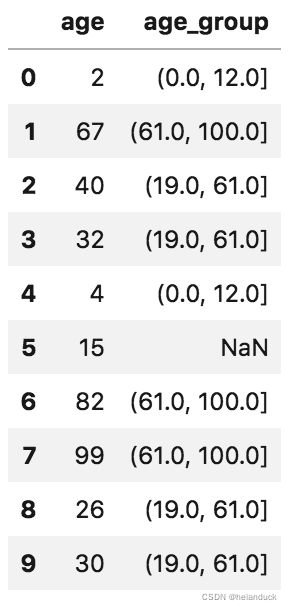
返回bins
使用retbins=True将生成的bins返回
result, bins = pd.cut(
df['age'],
bins=4, # A single number value
retbins=True
)