Flink学习笔记(三)Flink安装部署
文章目录
-
-
- 集群部署启动
- 提交作业
- 部署模式
- Yarn模式
-
集群部署启动
Flink 是典型的 Master-Slave 架构的分布式数据处理框架,其中 Master 角色对应着JobManager,Slave 角色则对应 TaskManager。
- 下载安装包并解压
进入 Flink 官网,下载 1.13.0 版本安装包 flink-1.13.0-bin-scala_2.12.tgz,注意对应 scala 版本为 scala 2.12 的安装包。
解压至/opt/moudle下
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
- 修改集群配置
(1)进入 conf 目录下,修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数为hadoop102;
# JobManager 节点地址.
jobmanager.rpc.address: hadoop102
(2)修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点,具体修改如下:
$ vim workers
hadoop103
hadoop104
(3)配置修改完毕后,使用xsync将 Flink 安装目录发给另外两个节点服务器。
(4)启动集群,在 hadoop102 节点服务器上执行 start-cluster.sh 启动 Flink 集群:
xxxxxxxxxx $ bin/start-cluster.shshell
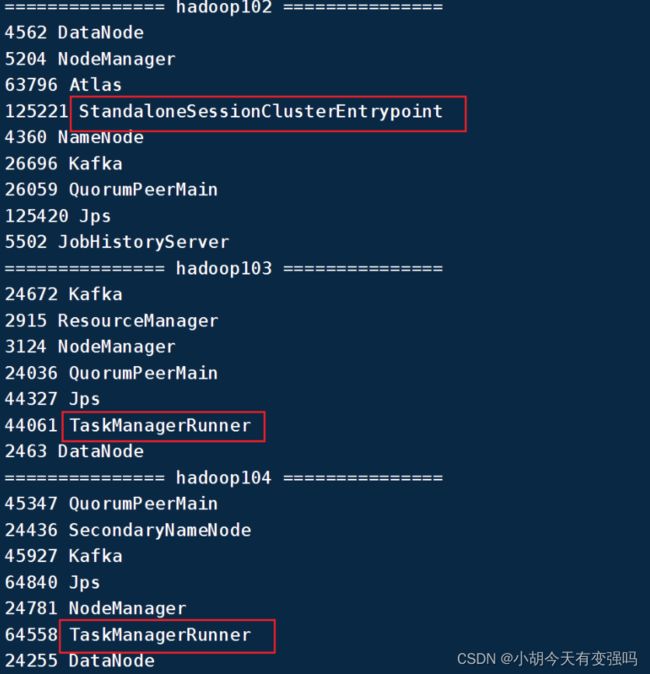
(5)关闭集群,在 hadoop102 节点服务器上执行 stop-cluster.sh 启动 Flink 集群:
$ bin/stop-cluster.sh
提交作业
1. web UI提交
打包插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.1.0version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
引入插件之后,在Maven的Lifecycle里双击package进行打包,注意如果代码写完没有运行的话,要先compile编译。

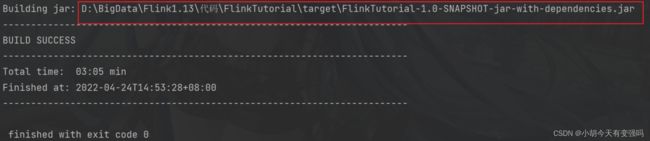
上传到Flink:
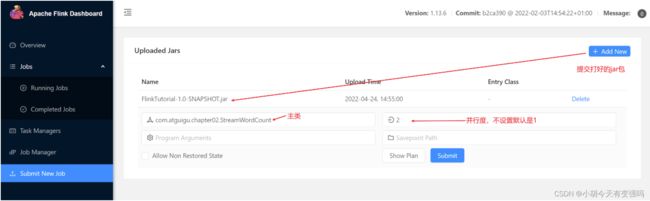
show plan: 程序的运行流程

提交后失败:
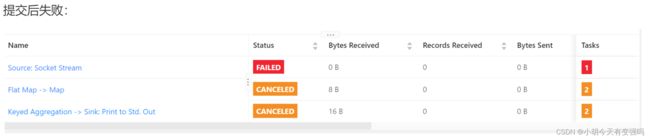
查看日志:
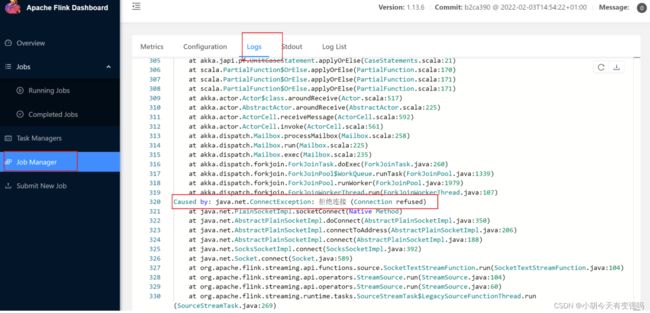
原因:hadoop102上nc没有启动
[hty@hadoop102 conf]$ nc -lk 7777
再次提交:
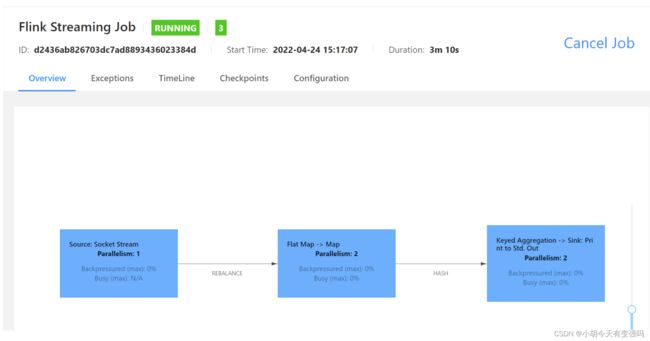
在TaskManagers中可以查看输出:
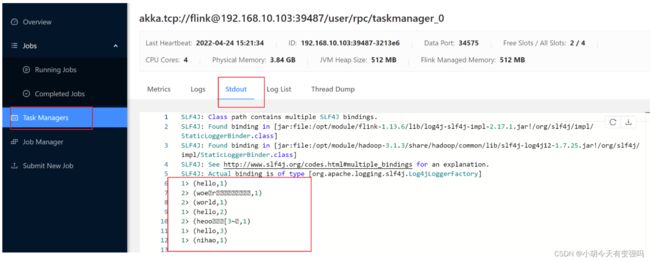
停掉Job:

2.命令行的提交
上传jar包,放到Flink的根目录下:
当前主机hadoop102被nc占用,因此在hadoop103上进行提交,需要 -m指定到底要提交到哪台主机:
bin/flink run -m hadoop102:8081 -c com.atguigu.chapter02.StreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar

提交成功:

关闭Job:
bin/flink cancel 82e029b6b487601bb6423c81048f0e1d //最后是JobID

部署模式
-
会话模式(Session Mode)
会话模式需要先启动一个集群,保持一个会话,在这个会话中 通过客户端提交作业。 -
单作业模式(Per-Job Mode)
单作业模式就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes。
-
应用模式(Application Mode)
不要客户端,直接把应用提交到 JobManger 上运行。而这也就代表着,需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这 个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了。
总结:在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。而单作业模式为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定。最后,应用模式为每个应用程序创建一个会话集群,在 JobManager 上直接调用应用程序的 main()方法。
Yarn模式
YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有 Hadoop,保证 Hadoop版本至少在 2.2 以上,并且集群中安装有 HDFS 服务。
1. 会话部署模式
1.1 启动集群
(1)启动 hadoop 集群(HDFS, YARN)。
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
bin/yarn-session.sh -nm test
可用参数解读:
-
-d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session 也可以后台运行。
-
-jm(–jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
-
-nm(–name):配置在 YARN UI 界面上显示的任务名。
-
-qu(–queue):指定 YARN 队列名。
-
-tm(–taskManager):配置每个 TaskManager 所使用内存。
YARN Session 启动之后会给出一个 web UI 地址以及一个 YARN application ID,如下所示,用户可以通过 web UI 或者命令行两种方式提交作业。

-
2 提交作业
跟上文提交相同,也是上传jar包,将任务提交到已经开启的
Yarn-Session中运行。
2. 单作业模式部署
执行命令提交作业:
bin/flink run -d -t yarn-per-job -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
可以使用命令行查看或取消作业,命令如下:
$ ./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
$ ./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
这里的 application_XXXX_YY 是当前应用的 ID,是作业的 ID。注意如果取消作业,整个 Flink 集群也会停掉。
3.应用模式部署
(1)执行命令提交作业。
$ bin/flink run-application -t yarn-application -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
(2)在命令行中查看或取消作业。
$ ./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
$ ./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>