爬虫学习:正则表达式
爬虫学习:正则表达式
文章目录
- 爬虫学习:正则表达式
-
- 一、前言
- 二、正则表达式是什么?
- 三、在Python中使用正则表达式
-
- 1、match函数方法
- 2、search函数方法
- 3、findall函数方法
- 4、sub函数方法
- 5、compile函数方法
- 四、最后我想说
一、前言
距离上次更新博客已经过去两个月之久,后续暑假的时间里,我会继续更新我学习爬虫的一些知识总结,好啦,废话不多说,正文开始。
二、正则表达式是什么?
正则表达式是一种文本模式,包括普通字符(例如,a到z之间的字母)和特殊的字符,正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式是繁琐的,但它是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感。
在Python爬虫学习的过程中,学习并使用正则表达式非常重要,对于爬虫来说,有了它,从网页爬取的HTML里面提取我们想要的信息的就非常的方便了。
OK,抛开爬虫,我们首先去一个正则表达式在线测试工具网站去看看,正则表达式是如何使用的,进入到这个在线正则表达式测试网站,然后输入待匹配的文本。然后选择常用的正则表达式,就可以得出想要的匹配结果了,例如我们输入以下文本信息:
Hello,my school number is 2020-122145 and email is beitian@gmail.com, and my website is https://baidu.com
然后再网页的右侧选择“匹配Email地址”,就可以看见下方已经出现了文本中的E-mail。
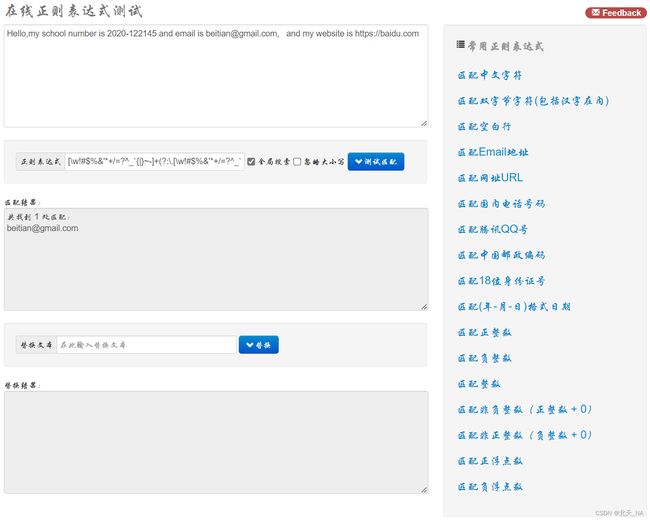
感兴趣的同学可以自行去尝试一下,在这里我就不做过多的演示。
正则表达式看上去虽然是各种字母和符号的组合,乱七八糟,但是其中是有特定的语法规则的,接下来我现在列出一些常用的匹配规则,更多的规则同学们可以往后遇见之后再自行上网翻阅资料。
| 模式 | 描述 |
|---|---|
| \w | 匹配字母、数字以及下划线 |
| \W | 匹配不是字母、数字以及下划线 |
| \s | 匹配任意空白字符 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开头 |
| \Z | 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符 |
| \z | 匹配字符串结尾,如果存在换行,同时匹配换行符 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配一行字符串的开头 |
| $ | 匹配一行字符串的结尾 |
| . | 匹配任意字符,除了换行符,如果re.DOTALL标记被指定时,可以匹配包括换行符的任意字符 |
| […] | 用来表示一组字符,单独列出 |
| [^…] | 匹配不在[]中的字符 |
| * | 匹配0个或多个表达式 |
| + | 匹配1个或多个表达式 |
| ? | 匹配0个或1个前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面的表达式 |
| {n,m} | 匹配n到m次由前面正则表示定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| () | 匹配括号内的表达式,也表示一个组 |
三、在Python中使用正则表达式
在Python中使用正则表达式非常的方便,因为Python的re库提供了整个正则表达式的实现,利用这个库,我们就可以非常方便的在Python中使用它。接下来我们去了解一些常用的方法。
1、match函数方法
match函数方法会尝试从字符串的起始位置开始匹配正则表达式,如果匹配,就返回匹配成功的结果,如果不匹配,就返回None。
它的函数语法格式为:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
我们来尝试一下:
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
print(result.group())
print(result.span())
它运行的结果是:
<re.Match object; span=(0, 25), match='Hello 123 4567 World_This'>
Hello 123 4567 World_This
(0, 25)
在match函数方法中,第一个参数是传入的正则表达式,第二个参数是传入了要匹配的字符串,该对象包含两个方法:
| 方法 | 说明 |
|---|---|
| group | 输出匹配到的内容 |
| span | 输出匹配的范围 |
在match中匹配目标,可以使用()将想提取的子字符括起来,被标记的每个子表达式依次对应每个分组,可以通过group方法传入分组,再通过对应的索引获取对应的结果。
import re
content = 'Hello 1234567 World_This is a Regex Demo'
# 匹配目标
result = re.match('^Hello\s(\d+)\sWorld', content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())
它运行的结果是:
<re.Match object; span=(0, 19), match='Hello 1234567 World'>
Hello 1234567 World
1234567
(0, 19)
其实,上面的正则表达式算是比较复杂的,工作量比较大,我们完全可以使用.*来替换,有了它我们就不用挨个匹配字符了。
修改过后如下:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
# 通用匹配
result = re.match('^Hello.*Demo$', content)
print(result)
print(result.group())
print(result.span())
它运行的结果是:
<re.Match object; span=(0, 41), match='Hello 123 4567 World_This is a Regex Demo'>
Hello 123 4567 World_This is a Regex Demo
(0, 41)
但是,这样写又出现了一个新的问题,那就是,.*匹配到的内容有时候并不是我们想要的结果,举个例子:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('He.*(\d+).*Demo', content)
print(result)
print(result.group(1))
它运行的结果是:
<re.Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>
7
显而易见,我们想要匹配字符串中的那一串数字,但它只匹配到了一个7,并没有匹配完全,在这里,就要涉及到贪婪匹配和非贪婪匹配问题了,在贪婪匹配下, 会匹配尽可能多的字符,正则表达式中的.*后面是\d+,也就是至少一个数字,而且没有指定具体几个数字,因此它会匹配尽可能多的字符,这里就把前面的123456全部匹配了,只给\d+留下一个可满足条件的数字7,所以最好得到的内容就只有7.
这样的结果并不是我们想要的,所以我们需要使用非贪婪匹配来进行匹配,非贪婪匹配的写法是.*?,我们来看一下它的效果;
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
print(result)
print(result.group(1))
它运行的结果是;
<re.Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>
1234567
现在就得到了我们想要的结果了,所以说,以后再做匹配的时候,字符串中间尽量使用非贪婪匹配,但是如果要匹配的结果在字符串结尾呢?这个时候就应该使用贪婪匹配了,我们举个例子看看效果:
import re
content = 'http://weibo.com/comment/kEraCN'
result1 = re.match('http.*?comment/(.*?)', content)
result2 = re.match('http.*?comment/(.*)', content)
print('result1的结果是:', result1.group(1))
print('result2的结果是:', result2.group(1))
它运行的结果是:
result1的结果是:
result2的结果是: kEraCN
在正则表达式中,可以用一些可选标志修饰符来控制匹配的模式,举个例子:
import re
content = '''Hello 1234567 World_This
is a Regex Demo
'''
result = re.match('^He.*?(\d+).*?Demo$', content)
print(result.group(1))
相比于上面的,我们添加了换行符,正则表达式都是一样的,但是却报错了:
AttributeError: 'NoneType' object has no attribute 'group'
这是因为匹配的内容是除换行符之外的任意字符,当遇到换行符时,就不能匹配了,在这里只需要添加一个修饰符re.S就可以了。
import re
content = '''Hello 1234567 World_This
is a Regex Demo
'''
result = re.match('^He.*?(\d+).*?Demo$', content, re.S)
print(result.group(1))
它运行的结果是:
1234567
不止re.S这个修饰符,还有其他很多修饰符,在这里我列举几个常用的修饰符给你们:
| 修饰符 | 说明 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 实现本地化识别匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使匹配内容包括换行符在内的所有字符 |
| re.U | 根据Unicode字符集解析字符 |
| re.X | 给予更灵活的格式,以便将正则表示熟悉的更易于理解 |
我们知道正则表达式中定义了许多匹配模式,但是,如果目标字符串里面就包含这些字符该怎么办呢?这个时候就需要用到转义匹配了,举个例子:
import re
content = '(谷歌) www.google.com'
result = re.match('\(谷歌\) www\.google\.com', content)
print(result)
它运行的结果是:
<re.Match object; span=(0, 19), match='(谷歌) www.google.com'>
可以看到,现在成功匹配到了原字符串。
2、search函数方法
search函数方法是扫描整个字符串并返回第一个成功的匹配。
它的函数语法格式为:
re.search(pattern, sting, flags=0)
函数参数说明:
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式 |
举个有关HTML的例子:
import re
html = '''
'''
result = re.search('(.*?)' , html, re.S)
if result:
print(result.group(1), result.group(2))
它运行的结果是:
刘大壮 一吻天荒
这个结果是怎么来的呢?首先我们先观察我们需要提取信息的HTML源码,可以发现ul节点里面有许多li列表节点,有的li节点里面又包括a节点,a节点里面存放着我们需要提取的信息——超链接、歌手名和歌名,首先,我们尝试提取class为active的li节点内部的超链接包含的歌手名和歌名,也就是说需要提取第三个li节点下a节点的singer属性和文本信息。
OK,我们来试着提取一下这个信息,首先正则表达式可以以li开头,然后寻找一个标识符,这个标识符就是li节点的属性active,中间部分可以用.*?来匹配,接下来,因为要提取singer这个属性值,所以还需要写入
singer=“(.*)”
这里把需要提取的部分用括号括起来方便使用group方法提取出来,小括号的两侧边界时双引号,然后还需要匹配a节点中的文本信息,此文本的左边界是>,有边界是,然后目标内容依然用(.*?)来匹配,最后就变成了:
<li.*?active.*?singer="(.*?)">(.*?)</a>
如果把属性值active去掉的化,search方法就会从字符串开头开始搜索,返回第一个符合条件的匹配目标了。
3、findall函数方法
findall函数在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
**注意:**match 和 search 是匹配一次,而findall 匹配所有。
它的函数语法格式为:
findall(string[, pos[, endpos]])
函数参数说明:
| 参数 | 说明 |
|---|---|
| string | 待匹配的字符串 |
| pos | 可选参数,指定字符串的起始位置,默认为 0 |
| endpos | 可选参数,指定字符串的结束位置,默认为字符串的长度 |
承接上面search方法使用过的那个HTML,如果我们想要获取所有a节点的超链接、歌手和歌名,就可以将search方法换成findall方法,这个方法返回的结果是列表类型,需要通过遍历来依次获取每组内容。
import re
html = '''
'''
results = re.findall('(.*?)' , html, re.S)
print(results)
print(type(results))
for result in results:
print(result)
print(result[0], result[1], result[2])
它运行的结果是:
[('/2.mp3', '队长', '那里都是你'), ('/3.mp3', '刘大壮', '一吻天荒'), ('/4.mp3', '陈奕迅', '孤勇者'), ('/5.mp3', '李润祺', '茫'), ('/6.mp3', '张远', '嘉宾')]
<class 'list'>
('/2.mp3', '队长', '那里都是你')
/2.mp3 队长 那里都是你
('/3.mp3', '刘大壮', '一吻天荒')
/3.mp3 刘大壮 一吻天荒
('/4.mp3', '陈奕迅', '孤勇者')
/4.mp3 陈奕迅 孤勇者
('/5.mp3', '李润祺', '茫')
/5.mp3 李润祺 茫
('/6.mp3', '张远', '嘉宾')
/6.mp3 张远 嘉宾
可以看出,如果想要获取匹配到的第一个字符串,可以用search方法,如果需要提取多个内容,可以用findall方法。
4、sub函数方法
sub方法可以用于替换字符串中的匹配项,例如用于修改文本或者去掉某一字符。
它的函数语法格式是:
re.sub(pattern, repl, string, count=0, flags=0)
函数参数说明:
| 参数 | 说明 |
|---|---|
| pattern | 正则中的模式字符串 |
| repl | 替换的字符串,也可为一个函数 |
| string | 要被查找替换的原始字符串 |
| count | 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配 |
举个例子:
import re
content = '54aK54yr5oiR54ix5L2g'
content = re.sub('\d+', '', content)
print(content)
它的运行结果是:
aKyroiRixLg
我们再利用上面上面的HTML文本举个例子,如果想要获取所有li节点的歌名,直接使用正则表达式会显得繁琐,这个时候我们就可以使用sub方法先将a节点去掉,留下文本,然后再利用findall方法提取就行:
import re
html = '''
'''
html = re.sub('|' , '', html)
results = re.findall('(.*?)' , html, re.S)
for result in results:
print(result.strip())
它运行的结果是;
水星记
那里都是你
一吻天荒
孤勇者
茫
嘉宾
5、compile函数方法
compile 函数用于编译正则表达式,生成一个正则表达式对象,供 match() 和 search() 这两个函数使用。
它的函数语法格式为:
re.compile(pattern[, flags])
在这里就不做多的说明函数参数了,直接举个例子:
import re
content1 = '2022-7-7 12:00'
content2 = '2022-7-8 19:00'
content3 = '2022-7-9 23:00'
pattern = re.compile('\d{2}:\d{2}')
result1 = re.sub(pattern, '', content1)
result2 = re.sub(pattern, '', content2)
result3 = re.sub(pattern, '', content3)
print(result1)
print(result2)
print(result3)
它运行的结果是:
2022-7-7
2022-7-8
2022-7-9
另外,compile还可以传入修饰符,这样在后面search、findall等方法中就不用再额外的传入了,所以可以说compile方法是给正则表达式做了一层封装,让我们能更方便的使用。
四、最后我想说
在Python中正则表达式的基本用法就差不多这些了,基本用法也讲完了,在后续实战训练的时候会反复使用的。
因为正则表达式不关Python中可以使用,其他很多语言同样可以使用,如果同学们还想继续深入的了解学习正则表达式,我可以向你们推荐一本书,它叫《学习正则表达式》,这本书是图灵程序设计丛书,非常值得去学习的。