设计数据密集型应用(四),DDIA
六、第9章节-一致性与共识
构建容错系统的最好方法,是找到一些带有实用保证的通用抽象,实现一次,然后让应用依赖这些保证。比如通过使用事务这个抽象,应用可以假装没有崩溃(原子性),没有其他人同时访问数据库(隔离性),存储设备是完全可靠的(持久性)。即使发生崩溃,竞态条件和磁盘故障,事务抽象隐藏了这些问题,因此应用不必担心它们
同样的分布式系统最重要的抽象之一就是共识(consensus):其非正式定义是让所有的节点对某件事达成一致
分布式一致性模型和事务的特性ACID中的一致性 ,隔离级别的区别❓
ACID一致性的概念是,对数据的一组特定陈述必须始终成立。即不变量(invariants)
分布式一致性主要是关于:面对延迟和故障时,如何协调副本间的状态
事务隔离的目的是为了,避免由于同时执行事务而导致的竞争状态
6.1-线性一致性
多数的数据库提供了最终一致性的保证(数据是最终收敛的)。最终一致性的问题是:如果你在同一个时刻问2个副本同样一个问题,可能得到不同的答案,线性一致性尝试提供只有一个副本的假象,即提供新鲜度保证(一个客户端完成写操作,所有client可以必须能看到最新的答案)
线性一致性和可序列化的区别❓
可序列化是事务的隔离性,它确保事务的执行是特定的顺序
线性一致性是读取和写入寄存器(单个对象)的新鲜度保证,它不会将多个操作组合为事务
一个数据库可以提供可串行性和线性一致性,这种组合称之为,单副本强可串行性(strong-1SR),基于2阶段锁的可串行化实现,通常是线性一致的,可重复读不是线性一致的
35.1-线性一致性的作用
️ 单主复制的系统中,领导选取(只有一个节点持有锁)
️ 唯一性约束(只有一个对象持有该id)
35.2-实现线性一致的系统
1️⃣ 单主复制:可能线性一致
2️⃣ 共识算法:线性一致
3️⃣ 多主复制:非线性一致
6.2-CAP
有一种说法是: 一致性、可用性、分区容错性,三者只能选择其二,这种说法有一定的误导性。这里的P指的是网络分区1,网络分区是一种故障,是一定会(概率事件)存在的,P不是一个可选项而是一个必选项,那么就有了
️ CP : 在网络分区下一致但不可用 。若应用需要线性一致性,某些副本和其他副本断开连接,那么这些副本掉线时不能处理请求(单主复制+同步),请求必须等到网络问题解决,或直接返回错误。无论哪种方式,服务都不可用(unavailable)
️ AP : 在网络分区下可用但不一致 。应用不需要线性一致性,那么某个副本即使与其他副本断开连接,也可以独立处理请求(例如多主复制)。在这种情况下,应用可以在网络问题前保持可用,但其行为不是线性一致的
6.3-全序 vs 偏序
6.3.1-因果顺序不是全序的
自然数集是全序的,如1,2,3;数学集合是偏序的,比如{a,b} 和 {b,c} 是没有办法比较大小的。线性一致是全序的,不存在任何并发,所有的操作在一条时间线上。而因果关系是偏序的,存在着并发,线性一致性强于因果一致性,但是性能不如因果一致性
6.3.2-序列号顺序
显示跟踪所有已读数据确保因果关系意味着巨大的额外开销,可以使用序列号或时间戳来排序事件,时间戳并不一定来自时钟,可以是一个逻辑时钟(自增计数器),单主复制的数据库中,主库为每个操作自增一个计数器,从库按照复制日志的顺序来应用写操作,那么从库的状态始终是因果一致的
6.3.3-非因果序列号生成器
对于无主复制或者多主复制,如何生成序列号呢?有下面三种方式:
1️⃣ 每个节点生成自己独立的一组序列号,如有2个节点,一个奇数一个偶数
2️⃣ 将物理时钟附加到每个操作上,也许可以提供一个全序关系
3️⃣ 预先分配序列区块号,如节点A是1-1000区块的所有权;节点B是1001-2000区块的所有权
三种共同的问题是:生成的序列号与因果关系不一致。兰伯特时间戳可以产生与因果关系一致的时间戳
6.3.4-兰伯特时间戳
(计数器,节点ID) ( c o u n t e r , n o d e I D ) (counter, node ID) (counter,nodeID) 组成兰伯特时间戳,每个节点和每个客户端跟踪迄今为止所见到的最大计数器值,并在每个请求中包含这个最大计数器值。当一个节点收到最大计数器值大于自身计数器值的请求或响应时,它立即将自己的计数器设置为这个最大值。下面2条规则去判断:
️ 如果你有两个时间戳,则计数器值大者是更大的时间戳
️ 如果计数器值相同,则节点ID越大的,时间戳越大
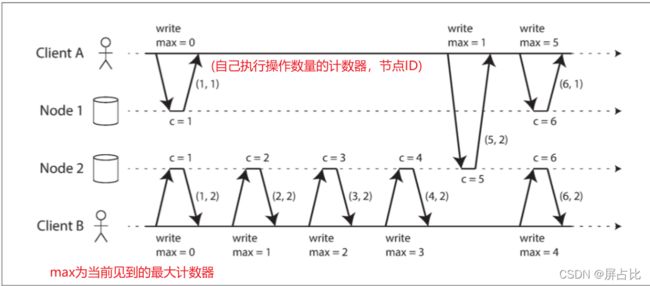
其中客户端 A 从节点2 接收计数器值 5 ,然后将最大值 5 发送到节点1 。此时,节点1 的计数器仅为 1 ,但是它立即前移至 5 ,所以下一个操作的计数器的值为 6 。虽然兰伯特时间戳定义了一个与因果一致的全序,但它还不足以解决分布式系统中的许多常见问题,比如确保用户名能唯一标识用户帐户的系统,你得搜集所有相同用户名的兰伯特时间戳,才能比较他们的时间戳,节点无法马上决定当前请求失败还是成功。所以仅知道全序是不够的,还需要知道全序何时结束
6.4-全序广播(原子广播)
全序广播通常被描述为在节点间交换消息的协议。 非正式地讲,它要满足两个安全属性:
1️⃣ 可靠交付(reliable delivery): 没有消息丢失:如果消息被传递到一个节点,它将被传递到所有节点
2️⃣ 全序交付(totally ordered delivery): 消息以相同的顺序传递给每个节点
正确的全序广播算法必须始终保证可靠性和有序性,即使节点或网络出现故障。当然在网络中断的时候,消息是传不出去的,但是算法可以不断重试,以便在网络最终修复时,消息能及时通过并送达
可以使用全序广播来实现可序列化的事务,由于具备上述2个安全属性,数据库的分区和副本就可以相互保持一致。节点得到了共识
️ 全序广播等于共识
️ 线性一致的CAS等于共识
6.5-分布式事务与共识
共识的目标只是让几个节点达成一致(get serveral nodes to agree on something)。节点达成一致(共识)的应用场景:
️ 领导选取:如在单主复制中,如果有2个以上领导就会有发生脑裂情况,脑裂时2主都会接收写入,导致数据不一致或数据丢失
️ 原子提交:在跨多节点或跨多分区事务的数据库中,所有节点必须就:一个事务是否成功这件事达成一致(要不都成功;要不都失败)
2PC是一个最简单的共识算法,更好的一致性算法比如ZooKeeper(Zab)和etcd(Raft)中使用的算法
区分普通事务和两种的不同的分布式事
0️⃣ 普通事务是相对单个节点而言的多对象操作;而分布式事务涉及多个节点
1️⃣ 数据库内部的分布式事务, 一些分布式数据库(即在其标准配置中使用复制和分区的数据库)支持数据库节点之间的内部事务,比如MySQL Cluster的NDB存储引擎就有这样的内部事务支持。此情形下,所有参与事务的节点都运行相同的软件
2️⃣ 异构分布式事务:在异构事务中,参与者是2者或者以上的技术,比如来自不同供应商的2个数据库/消息代理,跨系统的分布式事务需要保证原子提交
6.6-原子提交和2PC
对于多对象事务及维护次级索引的数据库,原子提交可以防止失败的事务搅乱数据库,避免数据库陷入半成品结果和半更新状态;对于单对象的原子性一般都由数据库(存储引擎)本身保证。**两阶段提交(two-phase commit)**是一种用于实现跨多个节点的原子事务提交的算法,即确保所有节点提交或所有节点中止
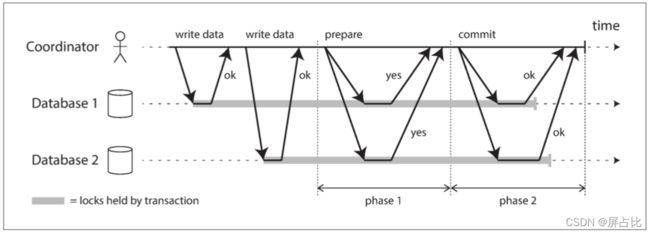
2PC使用一个通常不会出现在单节点事务中的新组件:协调者(coordinator)(也称为事务管理器(transaction manager))。2PC事务以应用在多个数据库节点(参与者(participants))上读写数据开始。当应用准备提交时,协调者开始阶段1:它发送一个**准备(prepare)**请求到每个节点,询问它们是否能够提交,然后协调者会跟踪参与者的响应:
- 如果所有参与者都回答“是”,表示它们已经准备好提交,那么协调者在阶段2发出**提交(commit)**请求,然后提交真正发生
- 如果任意一个参与者回复了“否”,则协调者在阶段2 中向所有节点发送**中止(abort)**请求
2PC具体的流程如下:
1️⃣ 当应用想要启动一个分布式事务时,它向协调者请求一个事务ID。此事务ID是全局唯一的
2️⃣ 应用在每个参与者上启动单节点事务,并在单节点事务上捎带上这个全局事务ID
3️⃣ 当应用准备提交时,协调者向所有参与者发送一个准备请求,并打上全局事务ID的标记。如果任意一个请求失败或超时,则协调者向所有参与者发送针对该事务ID的中止请求
4️⃣ 参与者收到准备请求时,需要确保在任意情况下都可以提交事务。这包括将所有事务数据写入磁盘(出现故障,电源故障,或硬盘空间不足都不能是稍后拒绝提交的理由)以及检查是否存在任何冲突或违反约束。通过向协调者回答“是”,节点承诺,只要请求,这个事务一定可以不出差错地提交。换句话说,参与者放弃了中止事务的权利,但没有实际提交
5️⃣ 当协调者收到所有准备请求的答复时,会就提交或中止事务作出明确的决定(只有在所有参与者投赞成票的情况下才会提交)。协调者必须把这个决定写到磁盘上的事务日志中,如果它随后就崩溃,恢复后也能知道自己所做的决定。这被称为提交点(commit point)
6️⃣一旦协调者的决定落盘,提交或放弃请求会发送给所有参与者。如果这个请求失败或超时,协调者必须永远保持重试,直到成功为止。没有回头路:如果已经做出决定,不管需要多少次重试它都必须被执行。如果参与者在此期间崩溃,事务将在其恢复后提交——由于参与者投了赞成,因此恢复后它不能拒绝提交
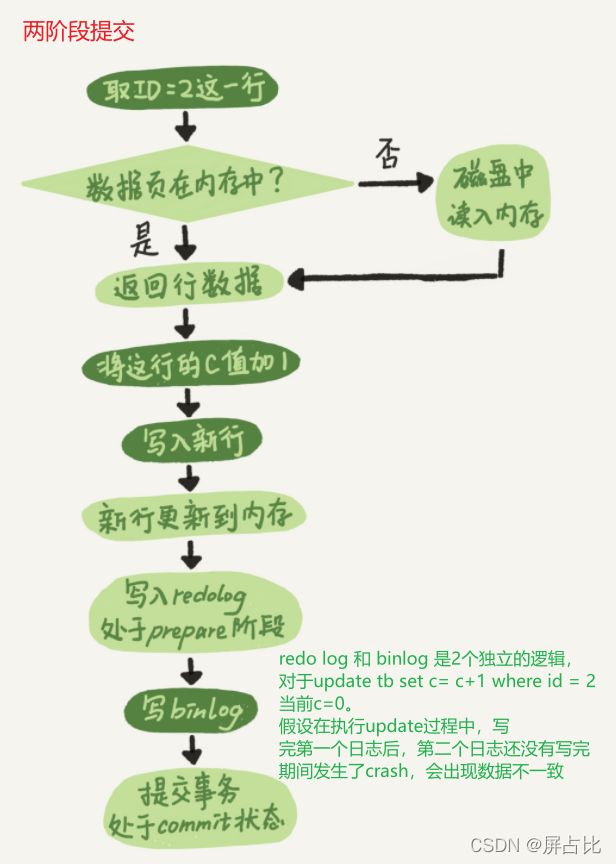
下图是MySQL的两阶段提交过程,该过程保证bin-log和redo-log一致
6.7-协调者失效
上述第3️⃣步中协调者发送“准备”请求之前失败,参与者可以安全的终止事务;在第5️⃣ 步中如果任何提交和终止请求失败,协调者将无条件重试,但是协调者崩溃,参与者就什么也做不了只能等待。参与者的这这种事务状态称为:存疑或者不确定
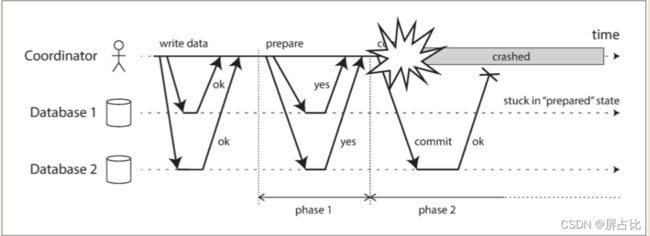
上图中:协调者实际上决定提交,数据库2收到提交请求,但是协调者在将提交请求发送到数据库1之前发生崩溃,因此数据库1不知道是否提交或中止。这里即便超时, 也是没用的:
- 如果数据库1 在超时后单方面中止,它将最终与执行提交的数据库2 不一致
- 单方面提交也是不安全的,因为另一个参与者可能已经中止了
此时完成2PC的唯一方法是等待协调者恢复,因此,协调者必须在向参与者发送提交/中止请求之前,将其提交/中止决定写入磁盘上的事务日志,协调者恢复后,通过读取其事务日志来确定所有存疑事务的状态,任何在协调者日志中没有提交记录的事务都会中止
6.8-恰好一次的消息处理
异构的分布式事务能够集成两种不同的系统,比如当用于处理消息的数据库事务成功提交后,消息队列中的一条消息可以被认为已处理。如果消息或者数据库事务任意一个失败,2者都会终止,而消息代理可能会在稍后安全的重传消息。通过这种方式,可以确保消息被有效地恰好处理一次
6.9-XA事务
扩展架构(eXtended Architecture)是跨异构技术实现两阶段提交的标准。许多关系型数据库(PostgresSQL、MySQL、SQL Server、Oracle))和消息代理(ActiveMQ,HornetQ,MSMQ和IBM MQ)都支持XA
6.10-容错共识
共识的定义:一个或多个节点可以**提议(propose)某些值,而共识算法决定(decides)**采用其中的某个值
共识算法需要满足以下性质:
1️⃣ 一致同意:没有2个节点的决定不同
2️⃣ 完整性:没有节点决定2次
3️⃣ 有效性:如果一个节点决定了值
v,则v由某个节点所提议4️⃣ 终止 : 由所有未崩溃的节点来最终决定值
终止属性形成了容错的思想,该属性是一个活性属性,而另外三个是安全属性。如果不关心容错,仅仅满足前三个属性就OK,因为你可以将其中一个节点硬编码为leader,让该节点做出所有的决定,但是节点一旦失效,系统无法就无法做出决定了。比如2PC就能够满足,但是2PC的问题是,协调者失效,存疑的参与者无法决定是提交还是终止,故2PC不满足终止属性的要求
绝大多数共识算法实际上并不直接使用1️⃣2️⃣3️⃣4️⃣形式化模型,而是使用全序广播代为实现
6.11-共识算法和全序广播
最著名的容错共识算法是视图戳复制(VSR, viewstamped replication),Paxos,Raft 以及 Zab。视图戳复制,Raft和Zab直接实现了全序广播,因为这样做比重复**一次一值(one value a time)**的共识更高效,因为全序广播的要求是:
1️⃣ 可靠交付(reliable delivery): 没有消息丢失:如果消息被传递到一个节点,它将被传递到所有节点
2️⃣ 全序交付(totally ordered delivery): 消息以相同的顺序传递给每个节点
可以发现,全序广播等于进行了重复多轮共识
在单主复制中,将所有的写入操作都交给主库,并以相同的顺序将他们应用到从库,从而使副本保持在最新状态,这里其实是一种**“独裁类型”**的共识算法,领导者是运维指定的,一旦故障必须人为干预,它无法满足共识算法的终止属性
6.12-时代编号和法定人数
共识协议一般会定义1个时代编号(epoch number),在Paxos中称为投票编号(ballot number),视图戳复制中的视图编号(view number),以及Raft中的任期号码(term number),并确保在每个时代中,领导者都是唯一的。每次领导者被认为挂掉的时候,会产生全序且单调递增的新的时代编号,更高时代编号的领导才真的领导。节点在做出决定之前对提议进行投票的过程是一种同步复制,这是共识的局限性
6.13-总结:
很多问题都可以归结为共识问题,并且彼此等价(从这个意义上来讲,如果你有其中之一的解决方案,就可以轻易将它转换为其他问题的解决方案)。这些等价的问题包括:
1️⃣ 线性一致性的CAS寄存器: 寄存器需要基于当前值是否等于操作给出的参数,原子地决定是否设置新值
2️⃣ 原子事务提交 : 数据库必须决定是否提交或中止分布式事务
3️⃣ 全序广播: 消息系统必须决定传递消息的顺序
4️⃣ 锁和租约: 当几个客户端争抢锁或租约时,由锁来决定哪个客户端成功获得锁
5️⃣ 成员/协调服务: 给定某种故障检测器(例如超时),系统必须决定哪些节点活着,哪些节点因为会话超时需要被宣告死亡
6️⃣ 唯一性约束: 当多个事务同时尝试使用相同的键创建冲突记录时,约束必须决定哪一个被允许,哪些因为违反约束而失败
如果你只有一个节点,或者你愿意将决策权分配给单个节点,所有这些事都很简单。这就是在单领导者数据库中发生的事情:所有决策权归属于领导者,这就是为什么这样的数据库能够提供线性一致的操作,唯一性约束,完全有序的复制日志等。但如果该领导者失效,或者如果网络中断导致领导者不可达,这样的系统就无法取得任何进展。应对这种情况可以有三种方法:
1️⃣等待领导者恢复,接受系统将在这段时间阻塞的事实。许多XA/JTA事务协调者选择这个选项。这种方法并不能完全达成共识,因为它不能满足终止属性的要求:如果领导者续命失败,系统可能会永久阻塞
2️⃣ 人工故障切换,让人类选择一个新的领导者节点,并重新配置系统使之生效,许多关系型数据库都采用这种方方式。这是一种来自“天意”的共识 —— 由计算机系统之外的运维人员做出决定。故障切换的速度受到人类行动速度的限制,通常要比计算机慢得多
3️⃣ 使用算法自动选择一个新的领导者。这种方法需要一种共识算法,使用成熟的算法来正确处理恶劣的网络条件是明智之举
以上是《设计数据密集型应用》读书笔记的第4部分,欢迎吐槽,欢迎关注公众号 stackoverflow
网络分区区别于分区,分区是一种中将数据集划分为多块,以此来提升并发读写能力; 而网络分区是指节点彼此断开但是仍然活跃。 ↩︎