Kubernetes-1.20.15高可用集群部署
Kubernetes-1.20.15高可用集群部署
一、环境准备
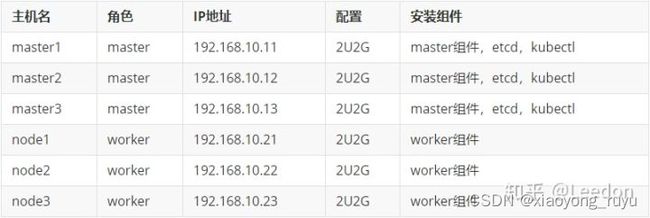
1.1 服务器规划
1.2 环境准备
下列环境在所有节点配置好
- 保证所有节点接入互联网并配置好YUM源(略)
- 关闭防火墙,selinux(略)
- 设置好主机名,做好解析(略)
- 配置好时间同步(略)
- 关闭swap
# swapoff -a
# sed -i 's/.*swap/#&/' /etc/fstab
- 配置内核参数
# vim /etc/sysctl.d/kubernetes.conf
net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_nonlocal_bind = 1 net.ipv4.ip_forward = 1 vm.swappiness=0
# sysctl --system
- 加载ipvs模块
# vim /etc/sysconfig/modules/ipvs.modules
#!/bin/bash modprobe – ip_vs modprobe – ip_vs_rr modprobe – ip_vs_wrr modprobe – ip_vs_sh modprobe – nf_conntrack_ipv4
# chmod +x /etc/sysconfig/modules/ipvs.modules
# /etc/sysconfig/modules/ipvs.modules
- 升级内核(版本较新的不需要此步)
# yum -y update kernel
# shutdown -r now
二、部署过程
- 安装配置docker # 所有节点
- 安装软件 # 所有节点
- 安装负载均衡及高可用 # 所有 Master节点
- 初台化Master1 # Master1节点
- 配置kubectl # 所有需要的节点
- 部署网络插件 # Master1节点
- 加入Master节点 # 其它 Master节点
- 加入Worker节点 # 所有 Node节点
2.1 安装配置docker
在所有节点操作
配置yum源
# curl https://gitee.com/leedon21/k8s/raw/master/docker-ce.repo -o /etc/yum.repos.d/docker-ce.repo
安装docker,建议使用19.03版
yum -y install docker-ce-19.03.15
配置docker
# mkdir /etc/docker
# vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"registry-mirrors": ["https://pf5f57i3.mirror.aliyuncs.com"]
}
启动docker
systemctl start docker
systemctl enable docker
2.2 安装软件
在所有节点安装
配置yum源
# curl https://gitee.com/leedon21/k8s/raw/master/kubernetes.repo -o /etc/yum.repos.d/kubernetes.repo
安装软件
# yum install -y kubeadm-1.20.15-0 kubelet-1.20.15-0 kubectl-1.20.15-0 ipvsadm
可用 yum list --showduplicates|egrep kubeadm 查看有哪些可用版本
设置开机启动kubelet
# systemctl enable kubelet
2.3 安装负载均衡
在所有Master节点操作
Kubernetes master 节点运行如下组件:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
kube-scheduler 和 kube-controller-manager 可以以集群模式运行,通过 leader 选举产生一个工作进程,其它进程处于阻塞模式。kube-apiserver可以运行多个实例,但对其它组件需要提供统一的访问地址,该地址需要高可用。
本次部署使用 keepalived+haproxy 实现 kube-apiserver 的VIP 高可用和负载均衡。keepalived 提供 kube-apiserver 对外服务的 VIP高可用。haproxy 监听 VIP,后端连接所有 kube-apiserver 实例,提供健康检查和负载均衡功能。kube-apiserver的端口为6443, 为避免冲突, haproxy 监听的端口要与之不同,此实验中为6444。
keepalived 周期性检查本机的 haproxy 进程状态,如果检测到 haproxy 进程异常,则触发VIP 飘移。 所有组件都通过 VIP 监听的6444端口访问 kube-apiserver 服务。
在此我们使用睿云智合相关镜像,具体使用方法请访问: https://github.com/wise2c-devops 。当然也可以手动配置haproxy以实现apiserver负载均衡,keepalived实现haproxy高可用。
创建 haproxy和 keepalived的启动脚本
# vim haproxy.sh
#!/bin/bash
MasterIP1=192.168.10.11
MasterIP2=192.168.10.12
MasterIP3=192.168.10.13
MasterPort=6443 # apiserver端口
docker run -d --restart=always --name haproxy-k8s -p 6444:6444 \
-e MasterIP1=$MasterIP1 \
-e MasterIP2=$MasterIP2 \
-e MasterIP3=$MasterIP3 \
-e MasterPort=$MasterPort wise2c/haproxy-k8s
-----------------------------------------------------------------
# vim keepalived.sh
#!/bin/bash
VIRTUAL_IP=192.168.10.100 # VIP
INTERFACE=ens33 # 网卡名称
NETMASK_BIT=24
CHECK_PORT=6444 # Haproxy端口
RID=10
VRID=160
MCAST_GROUP=224.0.0.18
docker run -itd --restart=always --name=keepalived-k8s \
--net=host --cap-add=NET_ADMIN \
-e VIRTUAL_IP=$VIRTUAL_IP \
-e INTERFACE=$INTERFACE \
-e NETMASK_BIT=$NETMASK_BIT \
-e CHECK_PORT=$CHECK_PORT \
-e RID=$RID -e VRID=$VRID \
-e MCAST_GROUP=$MCAST_GROUP wise2c/keepalived-k8s
在所有Master节点执行脚本运行这两个容器
# sh haproxy.sh
# sh keepalived.sh
测试
1).在每台机器上查看容器(haproxy, keepalived)是否都正常运行
2).在每台机器上查看6444端口是否监听
3).在有VIP的机器关闭haproxy容器或keepalived容器看看VIP能否正常飘移
2.4 初始化Master1
仅在 Master1节点操作
参考文档:https://kubernetes.io/docs/refe
在 Master1上创建初始化配置文件
[root@master1 ~]# mkdir k8s
[root@master1 ~]# cd k8s/
[root@master1 k8s]# kubeadm config print init-defaults > init.yml
根据实际环境修改初始化配置文件
[root@master1 k8s]# vim init.yml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.10.11 # 此处改为本机IP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.10.100:6444" # VIP:PORT
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 使用国内镜像仓库
kind: ClusterConfiguration
kubernetesVersion: v1.18.0 # 版本号
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # pod子网,和Flannel中要一致
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
初始化 Master1
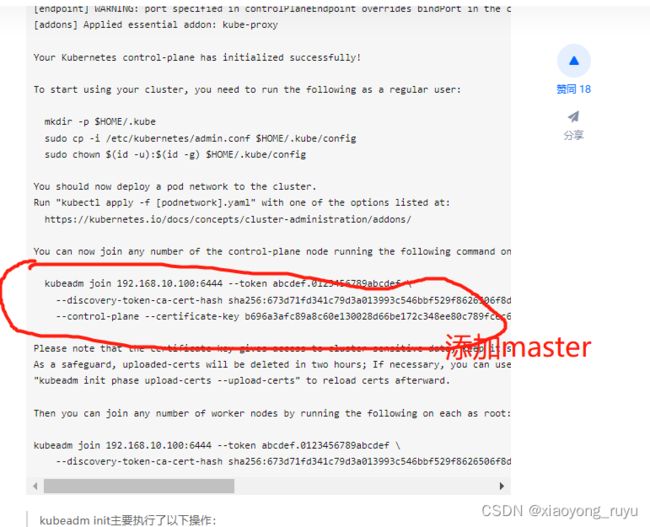
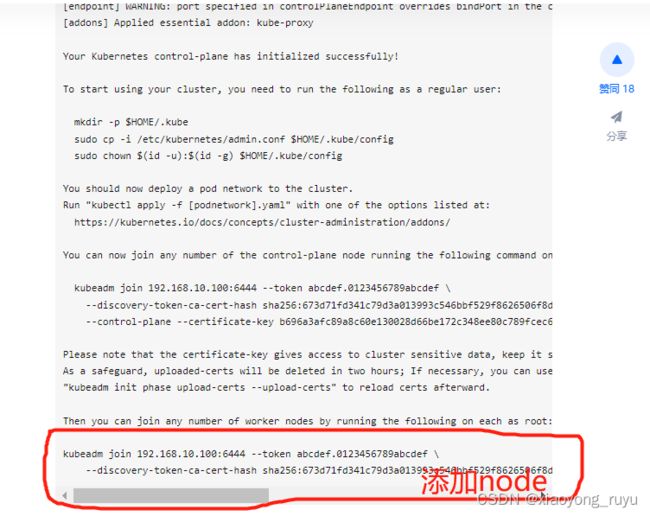
kubeadm init主要执行了以下操作: [init]:指定版本进行初始化操作 [preflight]
:初始化前的检查和下载所需要的Docker镜像文件
[kubelet-start]:生成kubelet的配置文件”“var/lib/kubelet/config.yaml”,没有这个文件kubelet无法启动,所以初始化之前的kubelet实际上启动不会成功。
[certificates]:生成Kubernetes使用的证书,存放在/etc/kubernetes/pki目录中。
[kubeconfig] :生成 KubeConfig 文件,存放在/etc/kubernetes目录中,组件之间通信需要使用对应文件。
[control-plane]:使用/etc/kubernetes/manifest目录下的YAML文件,安装 Master 组件。
[etcd]:使用/etc/kubernetes/manifest/etcd.yaml安装Etcd服务。
[wait-control-plane]:等待control-plan部署的Master组件启动。
[apiclient]:检查Master组件服务状态。 [uploadconfig]:更新配置
[kubelet]:使用configMap配置kubelet。 [patchnode]:更新CNI信息到Node上,通过注释的方式记录。
[mark-control-plane]:为当前节点打标签,打了角色Master,和不可调度标签,这样默认就不会使用Master节点来运行Pod。
[bootstrap-token]:生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
[addons]:安装附加组件CoreDNS和kube-proxy
2.5 配置kubectl
无论在master节点或node节点,要能够执行kubectl命令必须进行配置,有两种配置方式
方式一,通过配置文件
# mkdir -p $HOME/.kube
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# sudo chown $(id -u):$(id -g) $HOME/.kube/config
方式二,通过环境变量
# echo 'export KUBECONFIG=/etc/kubernetes/admin.conf' >> ~/.bashrc
# source ~/.bashrc
配置好kubectl后,就可以使用kubectl命令了
[root@master1 k8s]# kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
scheduler Healthy ok
[root@master1 k8s]# kubectl get no
NAME STATUS ROLES AGE VERSION
master1 NotReady master 2m32s v1.18.0
[root@master1 k8s]# kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7ff77c879f-965nt 0/1 Pending 0 2m24s
coredns-7ff77c879f-qmsb2 0/1 Pending 0 2m24s
etcd-master1 1/1 Running 1 2m38s
kube-apiserver-master1 1/1 Running 1 2m38s
kube-controller-manager-master1 1/1 Running 1 2m38s
kube-proxy-q847x 1/1 Running 1 2m24s
kube-scheduler-master1 1/1 Running 1 2m38s
由于未安装网络插件,coredns处于pending状态,node处于NotReady 状态
在更高版本的k8s集群中,可能会出现 scheduler、controller-manager 两个组件健康状况不正常的情况,如下:
[root@master-1 k8s]# kubectl get cs NAME STATUS
MESSAGE
ERROR controller-manager Unhealthy Get
http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: connect:
connection refused scheduler Unhealthy Get
http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect:
connection refused etcd-0 Healthy {“health”:“true”}解决方法:修改以下两个文件: /etc/kubernetes/manifests/kube-controller-manager.yaml
/etc/kubernetes/manifests/kube-scheduler.yaml注释掉: - --port=0 ,等一会即可
2.6 部署网络插件
仅在Master1节点操作
kubernetes支持多种网络方案,这里简单介绍常用的 flannel 方案.
kubectl apply -f https://gitee.com/leedon21/k8s/raw/master/kube-flannel.yml
最新版本的kube-flannel.yml文件(注意下载下来后修改里面的镜像): https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
过一会再次查看node和 Pod状态,全部OK, 所有的核心组件都起来了
[root@master1 k8s]# kubectl get po -n kube-system NAME
READY STATUS RESTARTS AGE coredns-7ff77c879f-965nt 1/1
Running 0 24m coredns-7ff77c879f-qmsb2 1/1
Running 0 24m etcd-master1 1/1
Running 1 25m kube-apiserver-master1 1/1
Running 1 25m kube-controller-manager-master1 1/1
Running 1 25m kube-flannel-ds-amd64-vvj65 1/1
Running 0 48s kube-proxy-q847x 1/1
Running 1 24m kube-scheduler-master1 1/1
Running 1 25m [root@master1 k8s]# kubectl get no NAME
STATUS ROLES AGE VERSION master1 Ready master 26m
v1.18.0
2.7 加入master节点
在另外两个节点执行
[root@master2 ~]# kubeadm join 192.168.10.100:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:673d71fd341c79d3a013993c546bbf529f8626506f8d14fc69f0be376956e56f \
--control-plane --certificate-key b696a3afc89a8c60e130028d66be172c348ee80c789fcec6f79f759142eea6b8
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Reading configuration from the cluster…
[preflight] FYI: You can look at this config file with ‘kubectl -n kube-system get cm kubeadm-config -oyaml’
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config ima
再查看集群信息
[root@master1 k8s]# kubectl get no
NAME STATUS ROLES AGE VERSION
master1 Ready master 12m v1.18.0
master2 Ready master 10m v1.18.0
master3 Ready master 3m3s v1.18.0
[root@master1 k8s]# kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7ff77c879f-r4mqp 1/1 Running 0 12m
coredns-7ff77c879f-w9nsh 1/1 Running 0 12m
etcd-master1 1/1 Running 0 13m
etcd-master2 1/1 Running 0 9m39s
etcd-master3 1/1 Running 0 3m51s
kube-apiserver-master1 1/1 Running 0 13m
kube-apiserver-master2 1/1 Running 0 11m
kube-apiserver-master3 1/1 Running 0 3m50s
kube-controller-manager-master1 1/1 Running 1 13m
kube-controller-manager-master2 1/1 Running 1 9m43s
kube-controller-manager-master3 1/1 Running 0 3m50s
kube-flannel-ds-amd64-9wn57 1/1 Running 1 11m
kube-flannel-ds-amd64-ktxpl 1/1 Running 0 12m
kube-flannel-ds-amd64-qhttx 1/1 Running 0 8m59s
kube-proxy-6hlql 1/1 Running 0 11m
kube-proxy-jbx8r 1/1 Running 0 12m
kube-proxy-l9782 1/1 Running 0 8m59s
kube-scheduler-master1 1/1 Running 2 13m
kube-scheduler-master2 1/1 Running 2 9m43s
kube-scheduler-master3 1/1 Running 0 3m49s
2.8 加入worker节点
在所有worker节点执行
[root@node1 ~]# kubeadm join 192.168.10.100:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:673d71fd341c79d3a013993c546bbf529f8626506f8d14fc69f0be376956e56f
W0330 13:19:50.191449 3623 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Reading configuration from the cluster…
[preflight] FYI: You can look at this config file with ‘kubectl -n kube-system get cm kubeadm-config -oyaml’
[kubelet-start] Downloading configuration for the kubelet from the “kubelet-config-1.18” ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file “/var/lib/kubelet/config.yaml”
[kubelet-start] Writing kubelet environment file with flags to file “/var/lib/kubelet/kubeadm-flags.env”
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap…
This node has joined the cluster:
- Certificate signing request was sent to apiserver and a response was received.
- The Kubelet was informed of the new secure connection details.
Run ‘kubectl get nodes’ on the control-plane to see this node join the cluster.
过一段时间再看集群信息
[root@master1 k8s]# kubectl get no
NAME STATUS ROLES AGE VERSION
master1 Ready master 22m v1.18.0
master2 Ready master 20m v1.18.0
master3 Ready master 13m v1.18.0
node1 Ready 4m46s v1.18.0
node2 Ready 3m24s v1.18.0
node3 Ready 2m50s v1.18.0
至此,集群部署完毕。
三、问题解决
如果安装过程中出现问题, 无论是Master还是Node, 都可以执行 kubeadm reset 命令进行重置
[root@node2 ~]# kubeadm reset
[reset] WARNING: Changes made to this host by ‘kubeadm init’ or
‘kubeadm join’ will be reverted. [reset] Are you sure you want to
proceed? [y/N]: y [preflight] Running pre-flight checks W0321
22:54:01.292739 7918 removeetcdmember.go:79] [reset] No kubeadm
config, using etcd pod spec to get data directory [reset] No etcd
config found. Assuming external etcd [reset] Please, manually reset
etcd to prevent further issues [reset] Stopping the kubelet service
[reset] Unmounting mounted directories in “/var/lib/kubelet” [reset]
Deleting contents of config directories: [/etc/kubernetes/manifests
/etc/kubernetes/pki] [reset] Deleting files:
[/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf
/etc/kubernetes/bootstrap-kubelet.conf
/etc/kubernetes/controller-manager.conf
/etc/kubernetes/scheduler.conf] [reset] Deleting contents of stateful
directories: [/var/lib/kubelet /var/lib/dockershim /var/run/kubernetes
/var/lib/cni]
reset进程没有清理CNI配置
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
reset进程没有清理iptables或IPVS表
The reset process does not reset or clean up iptables rules or IPVS tables. If you wish to reset iptables, you
must do so manually by using the “iptables” command. If your cluster
was setup to utilize IPVS, run ipvsadm --clear (or similar) to reset
your system’s IPVS tables.
reset进程没有清理kubeconfig文件
The reset process does not clean your kubeconfig files and you must remove them manually. Please, check the
contents of the $HOME/.kube/config file.