Flink 搭建 单点、HA、ON YARN与提交作业方法
Hadoop与Flink HA架构图

Flink 1.15和1.14区别(5.16)
flink 1.15 要用java11且只支持java11不支持java8(可以jdbc落盘oracle),flink 1.14 用java 8或者 java 11都行(但jdbc连接不了oracle)
配置flink 1.15需要修改配置文件 vim conf/flink-conf.yaml
# 注释以下配置
#jobmanager.bind-host: localhost
#taskmanager.bind-host: localhost
#taskmanager.host: localhost
#rest.address: localhost
#rest.bind-address: localhost注意:在flink 1.15中不注掉上面几项会访问不了web UI界面
其余配置项和1.14一样按下面操作即可。
Flink 环境
(1).环境简介
Flink 是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。
需要准备 3台及以上 Linux 机器。具体要求如下:
⚫ 系统环境为 SUSE Linux Enterprise Server 12 SP5 版本。
⚫ 安装 Java 8。
⚫ 安装 Hadoop 集群,Hadoop 建议选择 Hadoop 2.7.5 以上版本。
⚫ 配置集群节点服务器间时间同步以及免密登录,关闭防火墙。
三台服务器的具体设置如下:
⚫ 节点服务器 1,IP 地址为 AIP地址
⚫ 节点服务器 2,IP 地址为 BIP地址
⚫ 节点服务器 3,IP 地址为 CIP地址
⚫ 节点服务器 4,IP 地址为 DIP地址
(2).解压
下载Flink: Apache Flink: 下载
执行解压命令,解压至指定目录
linux>tar zxvf flink-1.14.4-bin-scala2.12.taz -C /opt/install/flink/(3).进入软件目录
linux>Cd /home/oracle/debezium/flink-1.14.41.搭建Standalone 集群 单节点
(1).设置主 修改masters(flinkconf目录下)
linux>Vi conf/masters
删除掉localhost:8081
设置配置:AIP地址:8081(2).设置从 修改workers(flinkconf目录下)
linux>Vi conf/workers
删除掉localhost
设置配置: BIP地址
CIP地址
DIP地址(3).设置主配文件 修改 flink-conf.yaml(flinkconf目录下)
linux>Vi conf/ flink-conf.yaml
jobmanager.rpc.address: AIP地址 #设置jobManager的IP地址
#设置HA高可用
taskmanager.numberOfTaskSlots:2 #任务管理器数量任务插槽数默认是1,可以根据情况来设定
parallelism.default:1 #并行度,默认是1(4).下发文件
linux>Scp -r flink-1.14.4/ BIP地址: /opt/install/flink/
linux>Scp -r flink-1.14.4/ CIP地址: /opt/install/flink/
linux>Scp -r flink-1.14.4/ DIP地址: /opt/install/flink/(5).启动
linux>bin/start-cluster.sh //启动集群
linux>bin/stop-cluster.sh //停止集群(6)访问
打开浏览器输入 AIP地址:8081 访问flink
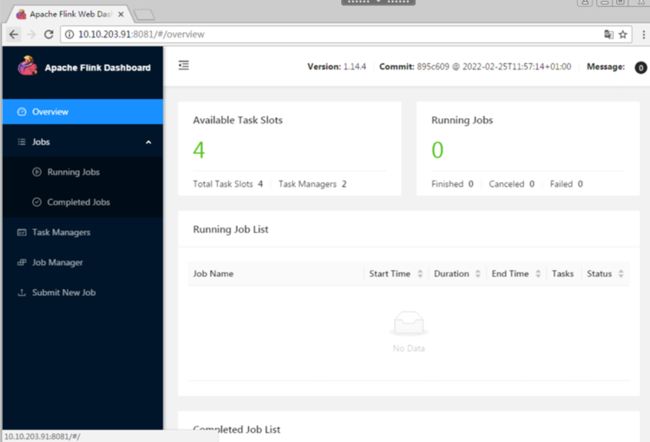
2.搭建Standalone 集群 HA
(1).设置主 修改masters(flinkconf目录下)
linux>Vi conf/masters
删除掉localhost:8081
设置配置:AIP地址:8081
BIP地址:8081 (2).设置从 修改workers(flink conf目录下)
linux>Vi conf/workers
删除掉localhost
设置配置: BIP地址
CIP地址
DIP地址(3).设置主配文件 修改 flink-conf.yaml(flinkconf目录下)
linux>Vi conf/ flink-conf.yaml
jobmanager.rpc.address: AIP地址 #设置jobManager的IP地址
#设置HA高可用
taskmanager.numberOfTaskSlots:2 #任务管理器数量任务插槽数默认是1,可以根据情况来设定
parallelism.default:1 #并行度,默认是1
high-availability:zookeeper #使用zookeeper搭建高可用
high-availability.storageDir:hdfs:///flink/ha/ # 存储JobManager的元数据到HDFS
high-availability.zookeeper.quorum:BIP地址:2181,CIP地址:2181,DIP地址:2181 # 配置ZK集群地址(4).下发文件
linux>Scp -r flink-1.14.4/conf BIP地址: /opt/install/flink/flink-1.14.4/conf
linux>Scp -r flink-1.14.4/conf CIP地址: /opt/install/flink/flink-1.14.4/conf
linux>Scp -r flink-1.14.4/conf DIP地址: /opt/install/flink/flink-1.14.4/conf(5).启动
linux>bin/start-cluster.sh //启动集群
linux>bin/stop-cluster.sh //停止集群(6)访问
打开浏览器输入AIP地址:8081 或者BIP地址:8081 访问flink
3.搭建Flink On Yarn 集群 HA
YARN 模式的高可用和独立模式(Standalone)的高可用原理不一样。
Standalone 模式中, 同时启动多个 JobManager, 一个为“领导者”(leader),其他为“后备”
(standby), 当 leader 挂了, 其他的才会有一个成为 leader。 而 YARN 的高可用是只启动一个 Jobmanager, 当这个 Jobmanager 挂了之后, YARN 会再次
启动一个, 所以其实是利用的 YARN的重试次数来实现的高可用。
(1).在 yarn-site.xml 中配置。(Hadoop/conf 下的配置文件)
linux>vi yarn-site.xml
yarn.resourcemanager.am.max-attempts
4
The maximum number of application masterexecution attempts.
注意: 配置完不要忘记分发, 和重启 YARN。
(2).在 flink-conf.yaml 中配置(flink conf目录下)
linux>Vi conf/ flink-conf.yaml
jobmanager.rpc.address: AIP地址 #设置jobManager的IP地址
#设置HA高可用
high-availability:zookeeper #使用zookeeper搭建高可用
high-availability.storageDir:hdfs:///flink/ha/ # 存储JobManager的元数据到HDFS
high-availability.zookeeper.quorum:BIP地址:2181,CIP地址:2181,DIP地址:2181 # 配置ZK集群地址
#设置yarn
yarn.application-attempts:3 #尝试3次(3).启动 yarn-session。 (flink conf目录下)
linux> bin/yarn-session.sh -nm test //测试yarn session(4).杀死 JobManager, 查看复活情况。
注意: yarn-site.xml 中配置的是 JobManager 重启次数的上限, flink-conf.xml 中的次数应该
小于这个值
(5).yarn-session可用参数解读:
常用参数: -d
$ bin/yarn-session.sh -nmtest(名称) -d
⚫ -d:分离模式,如果你不想让 FlinkYARN 客户端一直前台运行,可以使用这个参数,
即使关掉当前对话窗口,YARN session 也可以后台运行。
⚫-jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。 ⚫ -nm(--name):配置在 YARNUI 界面上显示的任务名。
⚫ -qu(--queue):指定 YARN 队列名。
⚫-tm(--taskManager):配置每个 TaskManager 所使用内存。
注意:Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定TaskManager 数量和 slot 数量,
YARN 会按照需求动态分配 TaskManager 和 slot。所以从这个意义上讲,YARN 的会话模式也
不会把集群资源固定,同样是动态分配的。
YARN Session 启动之后会给出一个 web UI 地址以及一个 YARN applicationID,
用户可以通过 web UI 或者命令行两种方式提交作业。
向集群提交作业
1. 程序打包
(1)设置maven
为方便自定义结构和定制依赖,可以引入插件 maven-assembly-plugin进行打包。
在 FlinkTutorial 项目的 pom.xml 文件中添加打包插件的配置,具体如下:
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
(2)插件配置完毕后,可以使用IDEA 的 Maven 工具执行 package 命令
打 包 完 成 后 , 在 target 目 录 下 即 可 找 到 所 需 JAR 包 , JAR 包 会 有 两 个 ,
FlinkTutorial-1.0-SNAPSHOT.jar和 FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因
为集群中已经具备任务运行所需的所有依赖,所以建议使用 FlinkTutorial-1.0-SNAPSHOT.jar。
2. 在 Web UI 上提交作业
(1)任务打包完成后,打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New
Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包,如图所示。
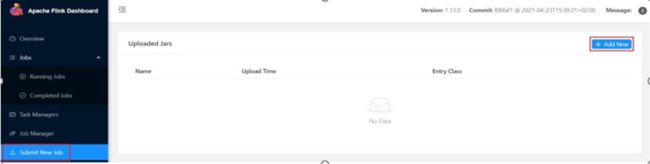

此图JAR 包上传完成
(2)点击该 JAR 包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点
路径等,如图 1-1所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
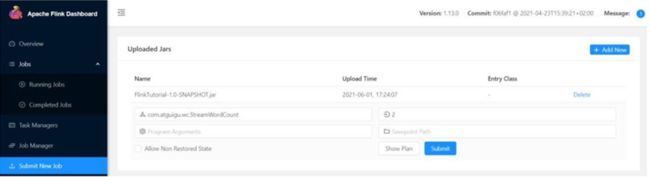
图 1-1 任务提交参数配置
(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况,
如图 1-2 所示。
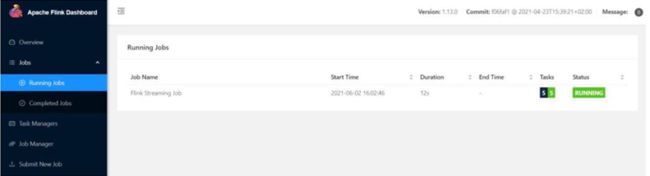
图 1-2 任务运行列表
(4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任
务运行,如图 1-3所示
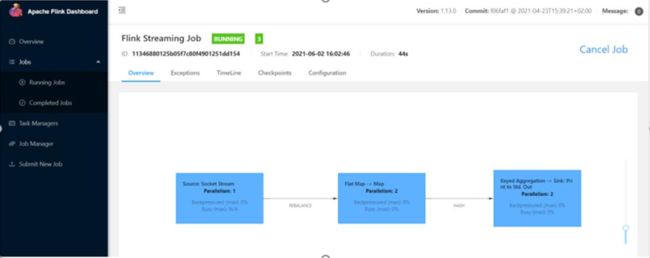
图 1-3 任务运行具体情况查看
3. 命令行提交作业
除了通过 WEB UI 界面提交任务之外,也可以直接通过命令行来提交任务
(1)首先需要启动集群。
linux> bin/start-cluster.sh(2)在其中一台下执行以下命令启动 netcat
linux> nc -lk 7777(3)进入到 Flink 的安装路径下,在命令行使用 flink run 命令提交作业
linux> bin/flink run -yd -m yarn-cluster -cjar包内类名 -yDyarn.provided.lib.dirs="hdfs:///flink依赖位置" jar包位置这里的参数 –m 指定了提交到的 JobManager,-c 指定了入口类
(4)在浏览器中打开 Web UI,http://IP:8081 查看应用执行情况,如图 1-4 所示

图 1-4 Web UI 界面查看任务运行状况
用 netcat 输入数据,可以在 TaskManager 的标准输出(Stdout)看到对应的统计结果。
(5)在 log 日志中,也可以查看执行结果,需要找到执行该数据任务的 TaskManager 节点
查看日志。
4.flink on yarn 提交作业
(1)通过 Web UI 提交作业
这种方式比较简单,与上文所述 Standalone 部署模式基本相同。
(2)通过命令行提交作业
① 将 Standalone 模式讲解中打包好的任务运行 JAR 包上传至集群
② 执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行。
linux> bin/flink run -c com.atguigu.wc.StreamWordCountFlinkTutorial-1.0-SNAPSHOT.jar客户端可以自行确定 JobManager 的地址,也可以通过-m 或者-jobmanager 参数指定
JobManager 的地址,JobManager 的地址在 YARN Session 的启动页面中可以找到。
③ 任务提交成功后,可在 YARN 的 Web UI 界面查看运行情况。
http://AIP地址:8088/cluster 访问yarn

图 1-5 YARN 的 Web UI 界面
如图 1-5 所示,从图中可以看到创建的 Yarn-Session 实际上是一个 Yarn 的
Application,并且有唯一的Application ID。
④也可以通过 Flink 的 Web UI 页面查看提交任务的运行情况,如图1-6 所示。
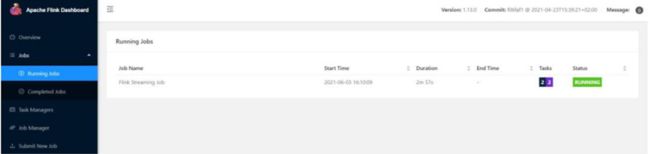
图 1-6 Flink 的 Web UI 页面
![]()
命令行提交作业例子:
linux>flink run -yd -m yarn-cluster -cLocalHostTest.AC_SUB_REGIST_INFO -yDyarn.provided.lib.dirs="hdfs:///flink/lib" /root/packet/FlinkTest-1.0-SNAPSHOT.jar