Flink运行时架构(一)

分布式状态快照包括checkpoint和savepoint,其中checkpoint是为出错恢复服务的,而savapoitn主要是用于作业的维护,包括升级和迁移等等。
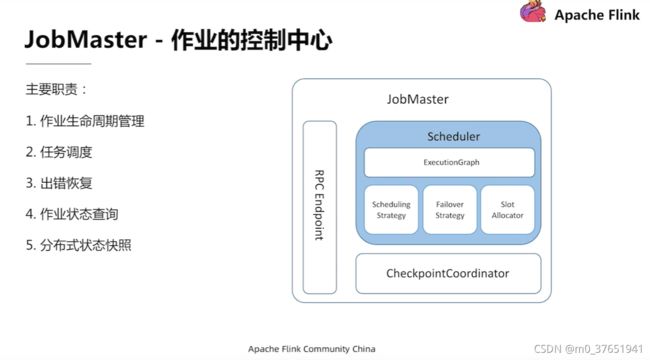
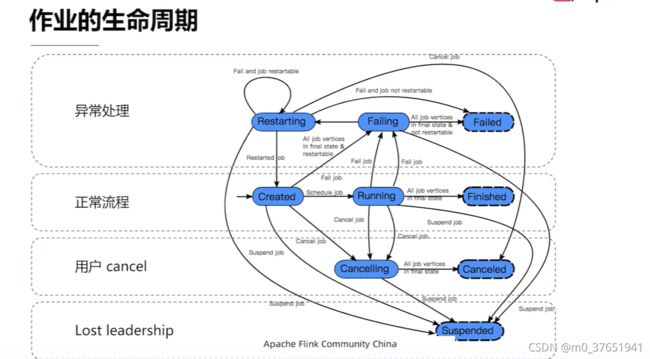
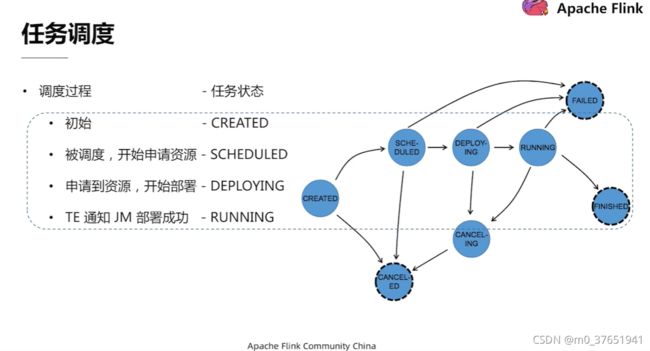
JobMaster中的核心组件是Scheduler,作业的声明周期管理,作业的状态维护,任务的调度,出错恢复都是由Scheduler完成的。
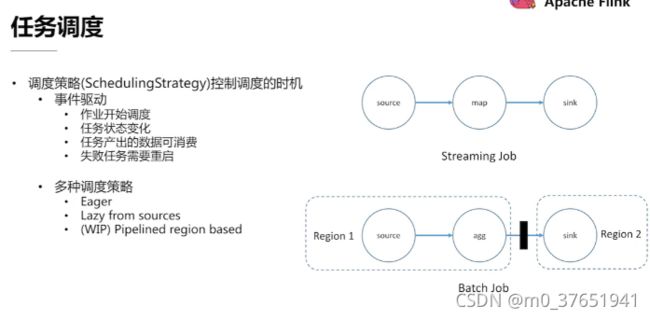
Eager用于调度流式处理作业,Lazy from sources用于批处理作业,因为批处理作业中存在blocking shuffle这种数据交换的模式,在这种模式下,需要等到上游产出的数据完全产出之后,下游才能去消费这部分数据集。 预先把下游的子任务调度起来,只会空转浪费资源。


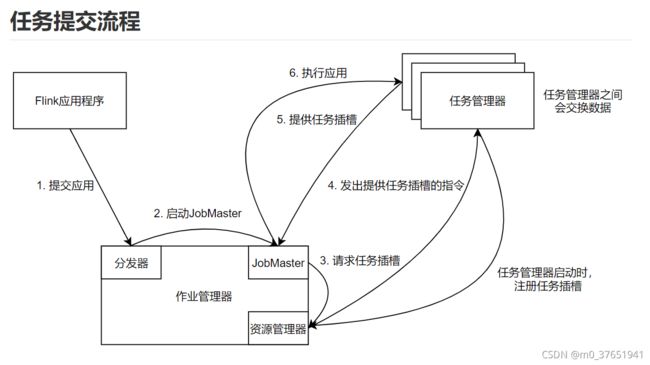
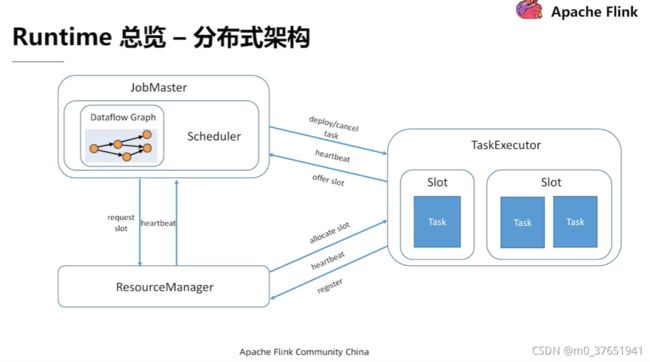
主从架构:一个JobManager(作业管理器)和多个TaskManager(任务管理器)
JobManager进程中包含三种线程;
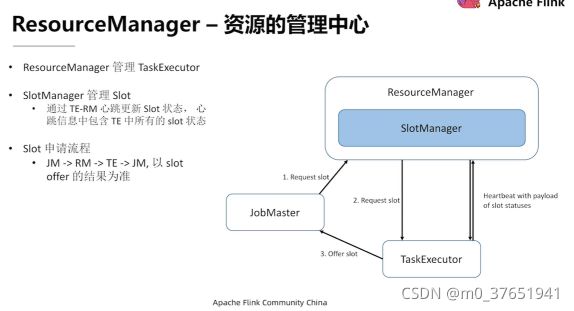
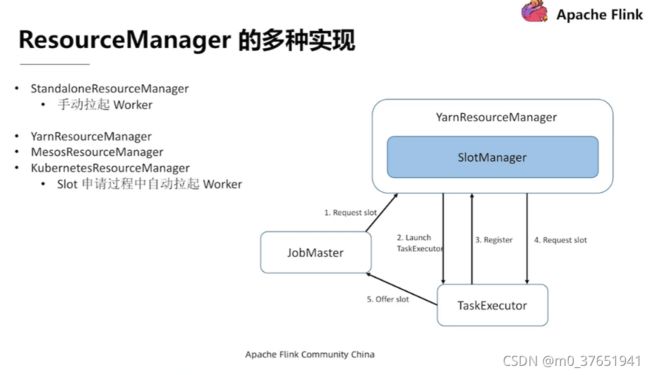
1)ResourceManager(资源管理器),管理TaskManager中的Task Slot(任务插槽)
2)Dispatcher(分发器,WebUI) 提价任务和监控集群和任务
3)JobMaster 负责管理单个JobGraph的执行,调度任务,将DAG部署到任务管理器
TaskManager(任务管理器)
1)Task Slot(任务插槽):是一个物理分区
2)不同的任务插槽就是不同的物理分区
3)每个任务插槽是一个内存分片
4) 内存的本质:字节数组
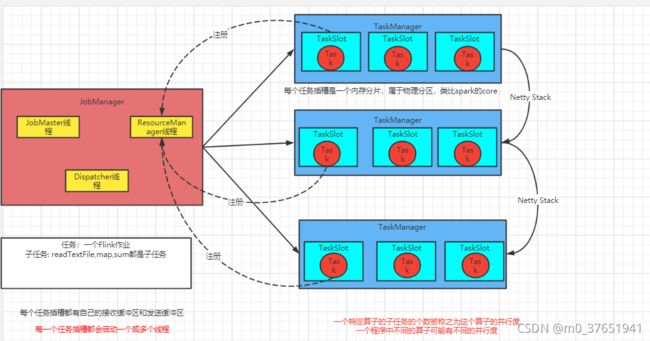
关于任务,子任务,并行子任务
任务:一个Flink作业
子任务:readTextFile,map,sum都是子任务
并行子任务:每个算子可能会有多个并行子任务 .print().setParallelism(2)
并行度的优先级:
1.任务管理器的配置文件里面 flink-conf.yaml~ parallelism.default:1
2.在命令行提交任务时设置并行度 ./bin/flink run xxx.jar -p 16
3.全局并行度 env.setParallelism(1)
4.针对算子设置并行度 .print().setParallelism(1)
并行度注意事项:
1) 不要设置全局并行度 因为没法在命令行动态扩容
2)针对某些算子设置并行度 例如数据源,为了不改变数据的顺序
3)在命令行设置可以动态扩容
4)任务插槽中的数量在配置文件中写死了,但并行度可以动态配置,但并行度的大小不能超过任务插槽的数量
任务插槽:
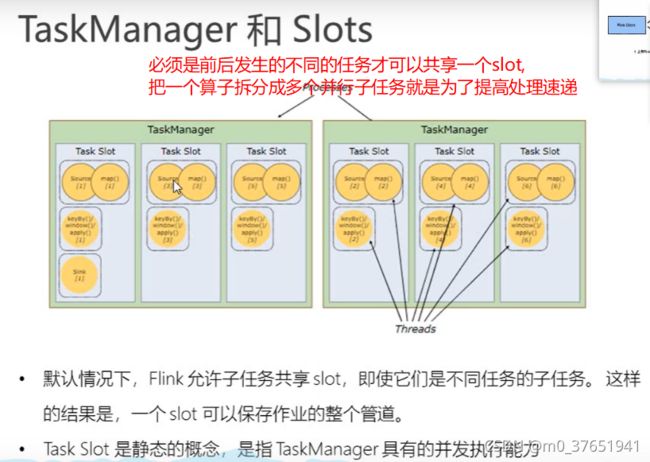
1)Flink中每一个 TaskManager 都是一个 JVM 进程,每一个任务插槽都会启动一个或者多个线程,它可能会在独立的线程上执行一个或多个 subtask,每一个子任务占用一个任务插槽(Task Slot)。
2)为了控制一个 TaskManager 能接收多少个 Task,TaskManager 通过 Task Slot 来进行控制(一个TaskManager 至少有一个 Slot,flink-conf.yaml)。
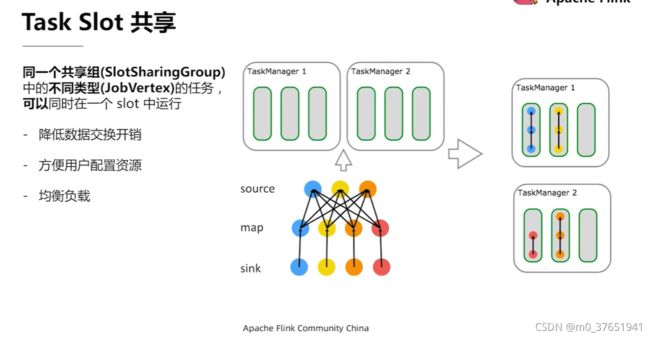
3)默认情况下,Flink 允许子任务共享 Slot 。这样的结果是,一个 Slot 可以保存作业的整个管道
4)Task Slot是静态的概念,是指 TaskManager 具有的并发执行能力


slotSharingGroup共享组 设置共享组后不同的共享组必须占用不同的slot,组内的子任务则可以共享slot
如果没设置则默认跟前一步的子任务的共享组是一致的。
第一个子任务即读取数据源的子任务的共享组的名字默认是“default”
一个特定算子的子任务的个数被称之为这个算子的并行度,一个程序中不同的算子可能有不同的并行度
一般情况下,一个stream的并行度,可以认为就是其所有算子中最大的并行度。
如果设置共享组的话,一个stream的并行度就是所有不同的共享组的并行度之和。
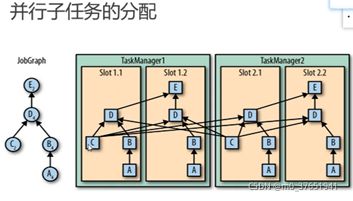
计算的并行性和数据并行性:数据并行性指一个子任务可以有多个并行子任务分布在不同的Slot中, 计算的并行性是指多个子任务可以一个相同的slot中以多线程的方式并发执行。
slot共享的优点:
1)一个slot可以保存作业的整个管道,即作业的一系列子任务可以在一个slot中完成,不会设计跨slot或者跨taskmanager(如果没有shuffle操作的话) 而且假如别的slot或者taskmanager故障时只需要降低并行度就可以依靠一个slot保障整个作业执行完毕 健壮性和效率都会提升
2)子任务分布在不同的slot中,此时有的子任务简单(如source,map操作等)有的子任务复杂(keyBy,window等),就会造成不同的slot处理的工作量远远不同
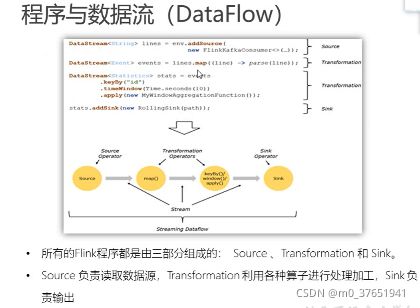
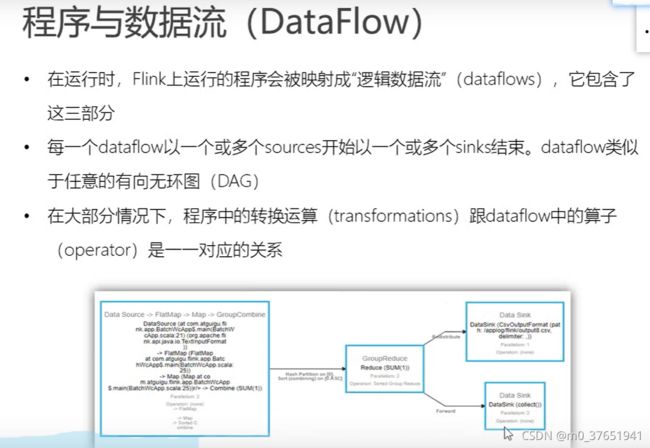



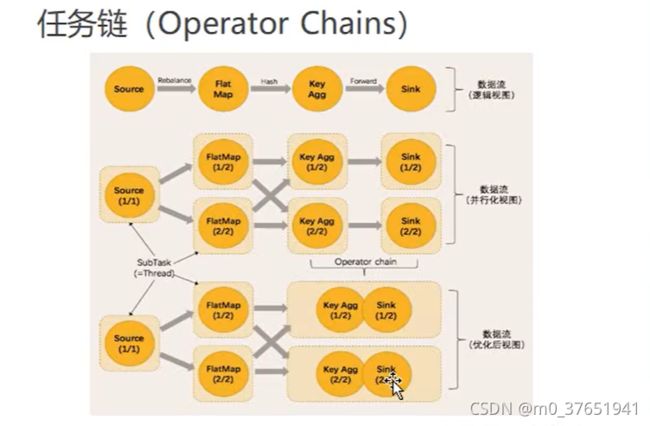
某个算子前后都不会参与任务链的合并

某个算子前面不会参与任务链的合并,但可能会与后面的算子产生任务链的合并:
![]()
某个任务中所有的算子都不会参与任务链的合并:

任务提交流程: