读Ceph: A Scalable, High-Performance Distributed File System
ceph是具有良好性能、可靠性、可拓展性的分布式文件系统
ceph基于PB级存储系统本质是动态的,因此大型系统都是增量构建、节点故障是常态、负载随时间不断变化
由客户端、metadata server集群和OSD集群组成。
- 客户端通过与OSD集群直接交流来执行文件IO
- metadata server集群管理命名空间(文件名和目录),协调 security、consistency 和 coherence
- OSD集群收集了所有数据和元数据
元数据与数据分离似乎是一种用于储存领域的常见方法
客户端操作
文件IO和访问权限控制
客户端向MDS发送打开一个文件请求时,会遍历文件系统层级,将文件名翻译成文件inode信息,包括唯一的inode号、文件owner、模式、大小等。若文件存在且授予了权限就会返回inode、将文件数据映射到对象的策略,并授予客户端能力(比如授予读写能力)
在关闭之后客户端放弃能力,并返回新文件大小给MDS
这是如何判断是否有这种能力的呢?以及如何回收的呢?
是储存客户端与能力映射在MDS内存中吗?并且每次操作的时候都要验证能力吗?若是如此,那么如果是读能力,并且下次访问的时候分配到了其他MDS,那如何办呢?
还是说给客户端一个加密token储存相应能力?这样的话,怎么回收啊?
同步操作
当一个文件被多个客户端打开,这些客户端都是写操作、或有读有写时,MDS 会撤回之前授予的的任何对读进行缓存和对写进行缓冲的能力,强制客户端对这个文件的 I/O 是同步的。也就是说,每个应用的读或写操作会被阻塞,直到收到 OSD 的确认,因此有效地将更新顺序化和同步的负担交给了存储这些对象的OSD
然而这种同步操作毕竟是很增加延迟的,但要是不放松一致性就无法保障。ceph将这个选择权交给了用户,是要更高的一致性还是要更高的性能呢?
命名空间操作
ceph对最常见的metadata访问场景进行了优化
比如一般readdir之后都会对每个文件进行stat,那么就可以在readdir的时候就将这些stat进行缓存,虽然牺牲了一点一致性,但确实性能得到了比较大的提升。
另一方面,在被多个客户端进行写操作文件进行stat操作时,为了返回正确的文件大小,就会撤回所有写能力,然后收到最新的大小信息,并返回最大的大小,最后恢复原来的写能力
动态分布元数据
metadata操作经常占据了文件系统多达一半的负载,因此MDS集群对于系统整体性能非常关键
元数据储存
新元数据流式更新到预写日志
动态子树分割
主副本缓存策略使一个权威MDS负责管理缓存一致性和给定任何metadata的序列化更新
每个MDS都会使用指数时间衰退计数器,来衡量目录层级的元数据热度
每次操作时,受影响的inode都递增计数器,并随层级反映到根节点。那么MDS会定期比较负载高低,迁移目录层级中大小合适子树

流量控制
ceph利用元数据的热度信息进行必要的分散,来应对多客户端访问同一文件的情况。
被大量读的目录内容会选择性复制分散到多个MDS节点。对于写负载大的目录会通过文件名hash分散到其他节点
每个 MDS 的响应里都有更新之后的权威信息,以及相关的 inode及其祖先是否被复制到其他节点信息,这使得客户端可以了解到元数据的分割信息。接下来,对于给定的一个路径,基于已知的最深前缀 ,元数据操作就会分成两类:
- 更新操作会定向到权威
- 读操作会定向到一个随机的权威的副本
权威如何选举?以及如何应对故障呢?
对象储存流程
-
简单hash映射数据对象到PG(placement group)
hash结果的一个bit mask控制PG数量,使得每个OSD有100个PG,来平衡OSD利用率以及维护的复制相关元数据
-
CRUSH随机分布到OSD列表
-
写入分配到的OSD列表第一个状态正常的OSD(以下称之为primary OSD)
-
primary OSD给对象、PG分配新版本号,并将写请求转发其他OSD副本
-
当所有副本都更新完毕,OSD收到响应之后也应用更新,并应答client

这是典型的两阶段提交
CRUSH定位
CRUSH通过PG、OSD集群映射表来定位对象。
OSD集群映射: 对集群设备的一个紧凑、层级化的描述。和集群物理结构、逻辑结构以及潜在的故障源都是对应的。比如同一个机柜row(限制inter-row复制流量)、不同的机柜(为了最小化电源故障)。并且还维护了down和inactive设备列表以及记录映射变化的epoch number。互相合作的OSD之间会共享映射增量更新
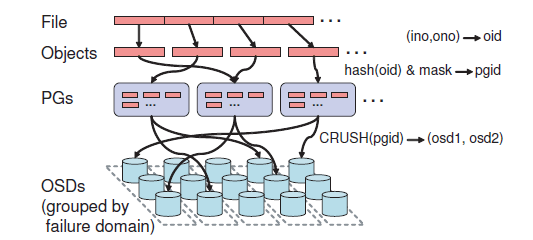
简单hash映射pg,而后pg通过CRUSH映射osd集群的过程,形成了互为primary和副本的局面
故障检测与恢复
- 对于特定类型故障,比如磁盘错误,OSD可以主动上报
- 大部分情况下可以被动证明节点状态。只有在一段时间内没有收到OSD过来的流量,才会显式发送ping包
当有故障或者恢复导致OSD集群映射变化时,受影响的OSD会递增自己在map中的版本号,然后在OSD之间通信上捎带这些信息,分发给所有pg中的OSD
OSD维护了PG版本号和最近改动的日志。
- osd1故障标记为down,osd2接管为pgA的primary
- osd1恢复后,会请求最新的OSD集群映射,monitor将该osd标记为up
- osd2收到OSD集群映射更新,知道自己不再是gpA的primary,就会将pgA版本号发给osd1
- osd1从osd2获取pgA的log,同步数据后,就开始处理新请求
一个一写多读的ceph osd集群,那么就没有必要去选举primary,而是直接固定通过集群的第一个osd作为primary。这样简单而且有效
Ref
- https://www.ssrc.ucsc.edu/media/pubs/6ebbf2736ae06c66f1293b5e431082410f41f83f.pdf