千人千面、用户画像的设计、技术选型与架构实现
用户画像的目的是为产品筛选出目标客户
目前,越来越多的企业,在大数据应用上,都会选择用户画像这一主题,为什么呢?因为用户画像相对于做推荐以及机器学习等简单容易的多,做画像,更多是就是对用户数据的整合,然后做一些用户聚类、用推荐算法,比如基于用户的推荐和基于商品的推荐,获取用户或者进行商品营销应用。
我们的画像的维度和设计原则都是紧紧跟着业务需求去推动。换句话说,对于数据的应用就是基于业务来做的,业务和数据双向驱动。
审核通过的画像才可以在“数据仓库”中流转;之后会通过用户信息、订单、行为等等进行信息采集,采集的目标是明确的、海量的、无序的。根据用户信息、订单、行为等等推测出其喜好,再针对性的给出产品可以极大提升用户感受,能避免用户被无故打扰的不适感。同时针对不同画像的用户提供个性化的服务
一、用户画像设计
1、项目架构
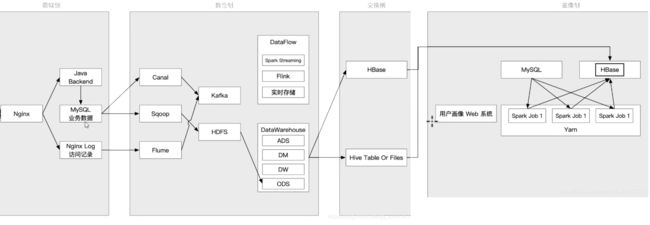
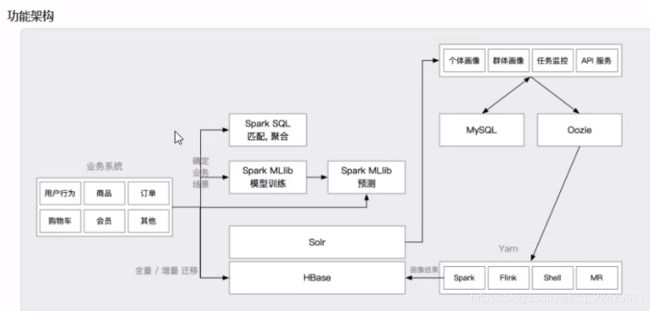
一、数据源
1. ODS,贴源层,做数据的存储,当出现问题的时候不再二次抽取
2. DW,数仓层,维度建模,简化查询
3. DM,集市层,小型数仓,为每个部分服务
4. ADS,应用层,对应数据应用的需求,例如便于报表访问等
金融企业内部的信息分布在不同的系统中,一般情况下,人口属性信息主要集中在客户关系管理系统,信用信息主要集中在交易系统和产品系统之中,也集中在客户关系管理系统中,消费特征主要集中在渠道和产品系统中。
兴趣爱好和社交信息需要从外部引入,例如引入银联和电商的信息来丰富消费特征信息,手机号/身份证号的MD5数值匹配是一种好的方法,可以进行唯一匹配。
保险行业DMP用户画像的业务场景都是围绕保险产品进行的,简单的应用场景可以是。
A 依据自身数据(个人属性)+外部养车App活跃情况,为保险公司找到车险客户。
B 依据自身数据(个人属性)+移动设备位置信息,为保险企业找到商旅人群,推销意外险和保障险。
C 依据自身数据(家人数据)+人生阶段信息,为用户推荐理财保险,寿险,保障保险,养老险,教育险。
D 依据自身数据+外部数据,为高端人士提供财产险和寿险。
二、数据分类,找到同业务场景强相关数据
用户画像需要坚持三个原则,分别是人口属性和信用信息为主,强相关信息为主,定性数据为主。下面就分别展开进行解释和分析。
1、人口属性信息:包含姓名、性别,电话号码,邮件地址,家庭住址等信息。这些信息可以帮助金融企业联系客户,将产品和服务推销给客户。
2、信用信息:用于描述用户收入潜力和收入情况,支付能力。客户职业、收入、资产、负债、学历、信用评分等都属于信用信息。
3、消费特征
行为数据:访问时间、浏览路径等用户在网站的行为日志数据
用于描述客户主要消费习惯和消费偏好,用于寻找高频和高价值客户。帮助企业依据客户消费特点推荐相关金融产品和服务,转化率将非常高。为了便于筛选客户,可以参考客户的消费记录将客户直接定性为某些消费特征人群,例如差旅人群,境外游人群,旅游人群,餐饮用户,汽车用户,母婴用户,理财人群等。
4、兴趣爱好
用于描述客户具有哪方面的兴趣爱好,在这些兴趣方面可能消费偏好比较高。帮助企业了解客户兴趣和消费倾向,定向进行活动营销。兴趣爱好的信息可能会和消费特征中部分信息有重复,区别在于数据来源不同。消费特征来源于已有的消费记录,但是购买的物品和服务不一定是自己享用,但是兴趣爱好代表本人的真实兴趣。例如户外运动爱好者,旅游爱好者,电影爱好者,科技发烧友,健身爱好者,奢侈品爱好者等。兴趣爱好的信息可能来源于社交信息和客户位置信息。
用户画像的纬度信息不是越多越好,只需要找到这五大类画像信息强相关信息,同业务场景强相关信息,同产品和目标客户强相关信息即可。根本不存在360度的用户画像信息,也不存在丰富的信息可以完全了解客户,另外数据的实效性也要重点考虑。
三、对数据进行分类和标签化(定量 > 定性)
将定量信息归纳为定性信息,并依据业务需求进行标签化,有助于金融企业找到目标客户,并且了解客户的潜在需求,为金融行业的产品找到目标客户,进行精准营销,降低营销成本,提高产品转化率。另外金融企业还可以依据客户的消费特征、兴趣爱好、社交信息及时为客户推荐产品,设计产品,优化产品流程。提高产品销售的活跃率,帮助金融企业更好地为客户设计产品。
0.6以上的相关系数就应该定义为强相关信息,例如在其他条件相同的前提下,35岁左右人的平均工资高于平均年龄为30岁的人,计算机专业毕业的学生平均工资高于哲学专业学生,从事金融行业工作的平均工资高于从事纺织行业的平均工资,上海的平均工资超过海南省平均工资。从这些信息可以看出来人的年龄、学历、职业、地点对收入的影响较大,同收入高低是强相关关系。简单的讲,对信用信息影响较大的信息就是强相关信息,反之则是弱相关信息。
用户其他的信息,例如用户的身高、体重、姓名、生日等信息,很难从概率上分析出其对消费能力的影响,这些弱相关信息,这些信息就不应该放到用户画像中进行分析,对用户的信用消费能力影响很小,不具有较大的商业价值。
定量信息转化为定性信息,通过信息类别来筛选人群。
例如可以将年龄段对客户进行划分,18岁-25岁定义为年轻人,25岁-35岁定义为中青年,36-45定义为中年人等。可以参考个人收入信息,将人群定义为高收入人群,中等收入人群,低收入人群。参考资产信息也可以将客户定义为高、中、低级别。定性信息的类别和方式方法,金融可以从自身业务出发,没有固定的模式。
例如可以将客户按照年龄区间分为学生,青年,中青年,中年,中老年,老年等人生阶段。源于各人生阶段的金融服务需求不同,在寻找目标客户时,可以通过人生阶段进行目标客户定位。企业可以利用客户的收入、学历、资产等情况将客户分为低、中、高端客户,并依据其金融服务需求,提供不同的金融服务。可以参考其金融消费记录和资产信息,以及交易产品,购买的产品,将客户消费特征进行定性描述,区分出电商客户,理财客户,保险客户,稳健投资客户,激进投资客户,餐饮客户,旅游客户,高端客户,公务员客户等。利用外部的数据可以将定性客户的兴趣爱好,例如户外爱好者,奢侈品爱好者,科技产品发烧友,摄影爱好者,高端汽车需求者等信息。
常用的离散化方法有等宽法,等频法以及一维聚类法等。机器学习1— 决策树 & 随机森林 文中有介绍离散化方法
四、对数据进行加工处理
金融企业集中了所有信息之后,依据业务需求,对信息进行加工整理,需要对定量的信息进行定性,方便信息分类和筛选。
这部分工作建议在数据仓库进行,不建议在大数据管理平台(DMP)里进行加工。
客户画像数据主要分为五类,人口属性、信用信息、消费特征、兴趣爱好、社交信息。这些数据都分布在不同的信息系统,金融企业都上线了数据仓库(DW),所有画像相关的强相关信息都可以从数据仓库里面整理和集中,并且依据画像商业需求,利用SparkSql跑批作业,加工数据,生成用户画像的原始数据。
数据仓库(DW)成为用户画像数据的主要处理工具,依据业务场景和画像需求将原始数据进行分类、筛选、归纳、加工等,生成用户画像需要的原始数据。
DMP(大数据管理平台)在整个用户画像过程中起到了一个数据变现的作用。
从技术角度来讲,DMP将画像数据进行标签化,利用机器学习算法来找到相似人群,同业务场景深度结合,筛选出具有价值的数据和客户,定位目标客户,触达客户,对营销效果进行记录和反馈。大数据管理平台DMP过去主要应用在广告行业,在金融行业应用不多,未来会成为数据商业应用的主要平台。
DMP可以帮助信用卡公司筛选出未来一个月可能进行分期付款的客户,电子产品重度购买客户,筛选出金融理财客户,筛选出高端客户(在本行资产很少,但是在他行资产很多),筛选出保障险种,寿险,教育险,车险等客户,筛选出稳健投资人,激进投资人,财富管理等方面等客户,并且可以触达这些客户,提高产品转化率,利用数据进行价值变现。DMP还可以了解客户的消费习惯、兴趣爱好、以及近期需求,为客户定制金融产品和服务,进行跨界营销。利用客户的消费偏好,提高产品转化率,提高用户黏度。
DMP还作为引入外部数据的平台,将外部具有价值的数据引入到金融企业内部,补充用户画像数据,创建不同业务应用场景和商业需求,特别是移动大数据、电商数据、社交数据的应用,可以帮助金融企业来进行数据价值变现,让用户画像离商业应用更加近一些,体现用户画像的商业价值。
数据整理:
1、数据指标的的梳理来源于各个系统日常积累的日志记录系统,通过sqoop导入hdfs,也可以用代码来实现,比如spark的jdbc连接传统数据库进行数据的cache。还有一种方式,可以通过将数据写入本地文件,然后通过sparksql的load或者hive的export等方式导入HDFS。
2、通过hive编写UDF 或者sparksql 根据业务逻辑拼接ETL,使用户对应上不同的用户标签数据(这里的指标可以理解为为每个用户打上了相应的标签),生成相应的源表数据,以便于后续用户画像系统,通过不同的规则进行标签宽表的生成。
2、计算的框架选用Spark ,这里Spark的主要用途有两种,一种是对于数据处理与上层应用所指定的规则的数据筛选过滤,(通过Scala编写spark代码提交至spark submit)。一种是服务于上层应用的SparkSQL 。 Hadoop的应用主要在于对于标签数据的打分,比如利用协同过滤算法等各种推荐算法对数据进行各方面评分。
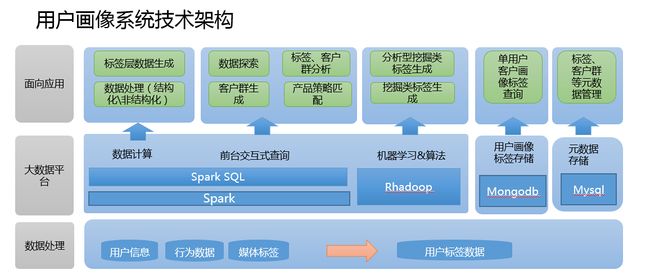
面向应用
1、从刚才的数据整理、数据平台的计算,都已经将服务于上层应用的标签大宽表生成。(用户所对应的各类标签信息)。那么前台根据业务逻辑,勾选不同的标签进行求和、剔除等操作,比如本月流量大于200M用户(标签)+本月消费超过100元用户(标签)进行和的操作,通过前台代码实现sql的拼接,进行客户数目的探索。这里就是通过jdbc的方式连接spark的thriftserver,通过集群进行HDFS上的大宽表的运算求count。(这里要注意一点,很多sql聚合函数以及多表关联join 相当于hadoop的mapreduce的shuffle,很容易造成内存溢出,相关参数调整可参考本博客spark栏目中的配置信息) 这样便可以定位相应的客户数量,从而进行客户群、标签的分析,产品的策略匹配从而精准营销。
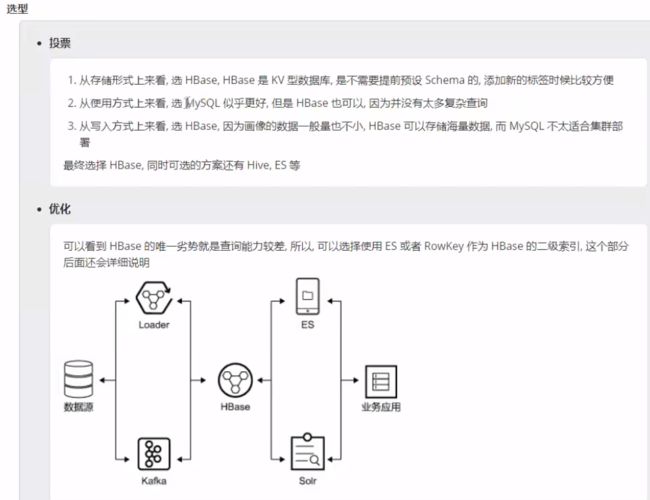
三、不同数据库存储(Mysql/Hbase/Elasticserch)
1. 基于Hbase的用户画像或者 Hbase+Solr
Hbase:存储线上推荐给用户的实时性较强的数据
直观的表达就是用Hbase集群来存储用户的数据,使用rowkey快速检索方式来构建查询。
博主曾经接触过一个项目,rowkey基于用户身份证号码设计(或者rowkey:姓名_证件类型_证件号码,MD5加密或者别的加密),因为每个人的身份证就是独一无二的,在根据用户不同维度的信息给用户打标签,做分类到最后做画像。
2. 基于Elasticserch的用户画像
Elasticsearch:人群计算、人群多维透视分析
大部分场景都是通过单个用户获取用户画像,但部分营销场景则需要满足特定画像的用户群体,比如获取年龄大于30岁、消费能力强、有亲子偏好的女性。这种情况下会返回大量用户,此时就需要借助批量查询工具。经过多次技术选型,我们决定采用elasticsearch作为批查询的平台,封装成API后很好的支持上述场景。
直观的表达就是用ES集群来存储用户的数据,使用ES快速检索方式来构建查询。
---------------------
原文:用户画像2种数据存储的方式_Soyoger的博客-CSDN博客_hbase 用户画像
3、Mysql的作用在于针对上层应用标签规则的存储,以及页面信息的展现。
后台的数据宽表是与spark相关联,通过连接mysql随后cache元数据进行filter,select,map,reduce等对元数据信息的整理,再与真实存在于Hdfs的数据进行处理。
MySQL:存储一些数量级较少的标签。MySQL的读写不用跑mapreduce作业,对于小量的数据读写速度很快。用于存储元数据、标签量级的监控、一些表加工结果的状态位、业务系统中读取的一些数据;
三、 同步Hive数据到Hbase
1、Hive与Hbase映射表
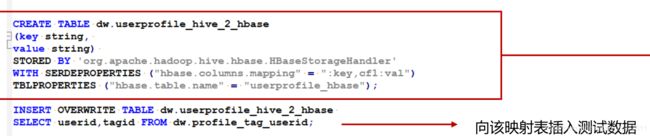
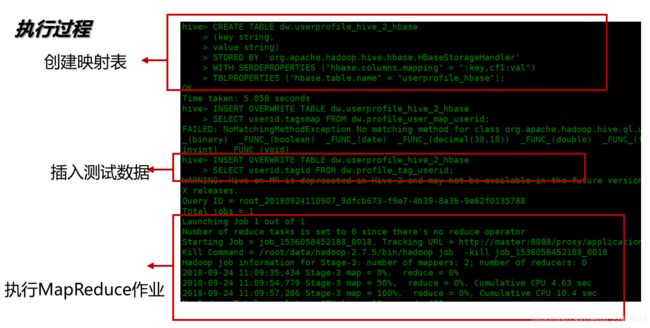
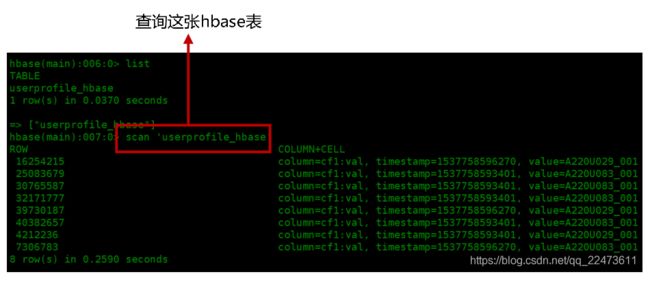
2、hive到hbase同步数据注意问题
因为灌入到hbase中的数据一般直接应用到线上,反馈到用户那里。所以在hive数据同步hbase数据的时候,需要做一些校验机制来保障结果的准确性,防止在同步数据的过程中出现问题(比如hive中数据5000万条,同步到hbase后才1000万条)
在开发过程中,可以尝试两种解决方案:
1、hive到hbase同步数据后,现在hbase中建立一个temp临时表,然后校验hbase的这个临时表和对应hive表的数量差异,如果在可接受范围内,则将hbase的该临时表进行重命名为正式表;
2、hive到hbase同步数据后,直接将数据写入正式表,同时在hbase中建立一张状态表,用于标志状态位。当校验hbase的这张正式表和hive的数量差异在可接受范围内时,写入对应的状态表中。接口请求时,只读取状态位这张表中,最近日期的那张表(所以如果hbase的数据同步异常,不会写入状态表中,也不会影响线上数据的读取;)
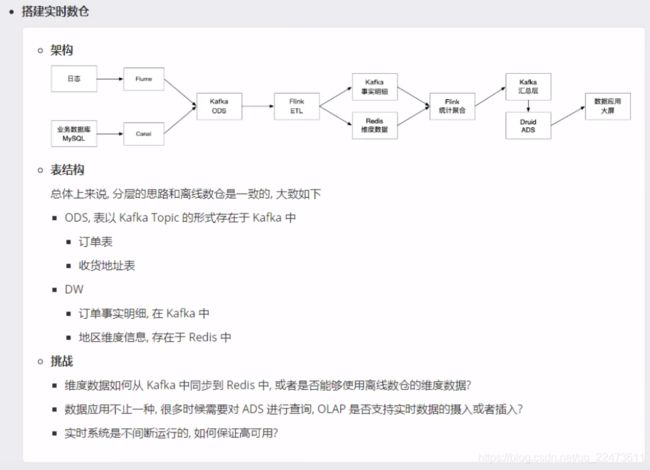
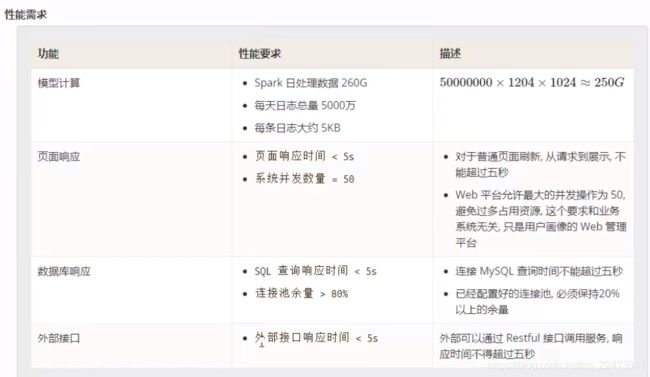
五、户画像数据存储与快速检索
标签查询—视图
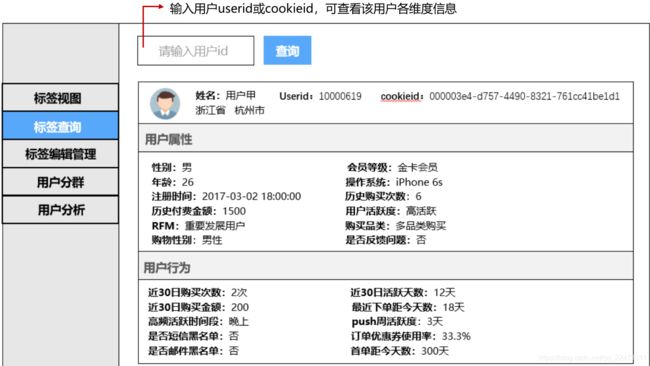
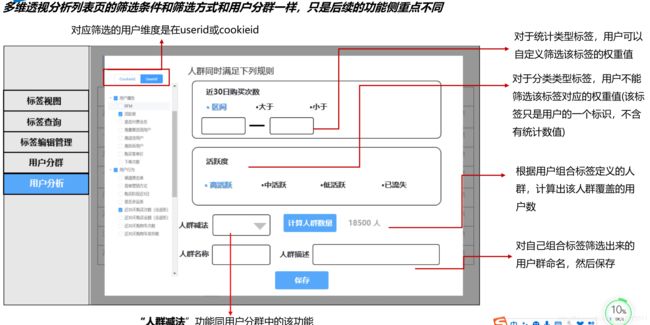
本篇文章,并不过多介绍用户画像如果去做,而是去解决用户画像数据存储与快速检索的痛点,如果想仔细了解用户画像,推荐一篇博客:用户画像构建策略及应用实践 用户画像构建策略及应用实践_顺顺顺子的博客-CSDN博客
在实际的项目中,常用的用户画像数据存储除了常规关系型数据块外,应用比较多的是Hbase和Elasticsearch集群的快速检索。所以在实际使用时,如果选型,要根据具体的业务来选择。下面说说着种方式:
- 为了保证输出数据的一致性,用户画像所使用的所有数据都来源于数据仓库。
- 使用SPARK集群作为计算引擎,使用SparkSQL作为开发语言。
- 为了让大家都能方便使用用户画像数据,用户画像结果数据同时存储到Hdfs文件、Hive数据仓库和Hbase中。(hive增量更新,每天执行,按照年月日分区,因为Hive只能增加,所以会有重复数据,将Hive数据去重插入Hbase,同时也可以方便查找,响应速度快,给别的系统调用接口,反回json类型方便解析)
六、用户画像用到哪些算法
1、决策树
决策树算法的构建分为3个部分:特征的选择,决策树的生成,决策树的剪枝;(主要参考李航的《统计学习方法》第五章)
a、特征的选择----选择使信息增益最大的特征;即选择一个分类特征必须是分类确定性更高,此特征才是更好的;
b、决策树的生成---ID3,C4.5,CART算法,此时用迭代的方式构建决策树;注意此时的决策树,因为每次选的都是局部最优解,所以是过拟合的;
c、决策树的剪枝---决策树剪枝是为了防止过拟合,根据全局cost function ,如果剪掉一个数支,cost function 会变小,那么剪掉这个树枝;
很多,svm,支撑向量机,通过找到样本空间中的一个超平面,实现样本的分类,也可以作回归,
lr,逻辑回归,本质也是线性回归,通过拟合拟合样本的某个曲线,然后使用逻辑函数进行区间缩放,但是一般用来分类,主要用在ctr预估、等;
nn,神经网络,通过找到某种非线性模型拟合数据,主要用在图像等;
nb,朴素贝叶斯,通过找到样本所属于的联合分步,然后通过贝叶斯公式,计算样本的后验概率,从而进行分类,主要用来文本分类;
dt,决策树,构建一棵树,在节点按照某种规则(一般使用信息熵)来进行样本划分,实质是在样本空间进行块状的划分,主要用来分类,也有做回归,但更多的是作为弱分类器,用在model embedding中;
rf,随进森林,是由许多决策树构成的森林,每个森林中训练的样本是从整体样本中抽样得到,每个节点需要进行划分的特征也是抽样得到,这样子就使得每棵树都具有独特领域的知识,从而有更好的泛化能力;
gbdt,梯度提升决策树,实际上也是由多棵树构成,和rf不同的是,每棵树训练样本是上一棵树的残差,这体现了梯度的思想,同时最后的结构是用这所有的树进行组合或者投票得出,主要用在、相关性等;
knn,k最近邻,应该是最简单的ml方法了,对于未知标签的样本,看与它最近的k个样本(使用某种距离公式,马氏距离或者欧式距离)中哪种标签最多,它就属于这类;