常用归一化/正则化层:InstanceNorm1d、InstanceNorm2d、
归一化
- 零、前言
-
- 1.官网链接
- 2.归一化公式
- 3.介绍
- 一、InstanceNorm1d
-
- 1. 介绍
- 2.实例
- 二、InstanceNorm2d
-
- 1. 介绍
- 2.实例
- 三、BatchNorm1d
-
- 1.介绍
- 2.实例
- 四、BatchNorm2d
-
- 1.介绍
- 2.实例
零、前言
1.官网链接
https://pytorch.org/docs/stable/nn.html#normalization-layers
2.归一化公式
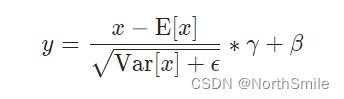
函数内部实现其实就是严格完成上面图中的公式,其中E(x)表示均值或者期望,而Var(x)则表示对应的方差。
3.介绍
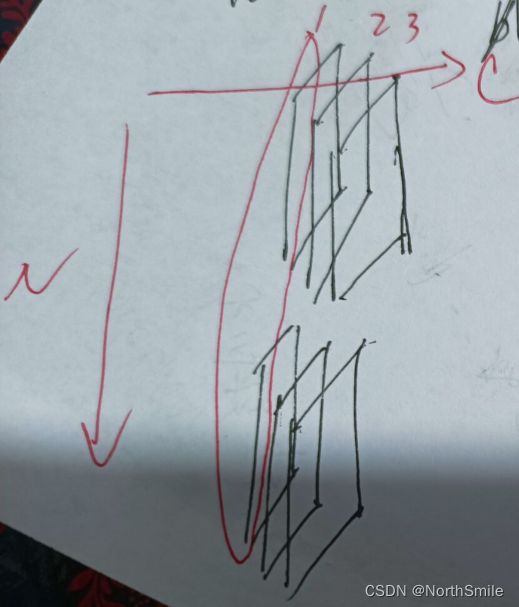
批量归一化与实例归一化的最大区别在于计算均值及方差的依据不同,实例归一化是对每个样本沿着通道方向独立对各个通道进行计算,而批量归一化则是对所有样本沿着batch的方向对各个通道分别进行计算。
比如:
输入特征图形状为:(2,3,256,512),表示有两个256×512的特征图,特征图通道数为3,假设为RGB三个通道
1)实例归一化:
- 依次对样本1,样本2分别计算R、G、B三个通道的均值、方差,每次计算其实是对256×512个元素值记性计算;
- 依据计算出的均值和方差,对各通道的元素实现图中的公式;

2)批量归一化:
- 对整个批次的样本,对各个通道分别求出均值和方差,每次计算其实是对2×256×512个元素值记性计算;
- 依据计算出的均值和方差,对各通道的元素实现图中的公式;
一、InstanceNorm1d
1. 介绍
一维实例归一化:对一个批次中每个样本,依次按照通道计算对应的均值及均方差。
torch.nn.InstanceNorm1d(
num_features,# 与输入特征的通道数保持一致
eps=1e-05,
momentum=0.1,
affine=False,
track_running_stats=False,
device=None,
dtype=None)
Input: (N, C, L)
Output: (N, C, L)
2.实例
import torch
import math
epsilon=1e-5
N,C,L=2,3,5
inp=torch.randint(5,size=(N,C,L),dtype=torch.float32)
print(inp)
print("-"*25)
# 方法一:手动实现
# 对每个样本计算各个通道的均值
mean_list=[]
for b in range(N):
for c in range(C):
mean_list.append(torch.sum(inp[b,c,:])/L)
# 对每个样本计算各个通道的方差
var_list=[]
for b in range(N):
for c in range(C):
# var_list.append(torch.var(inp[b,c,:]*(L-1)/L))
var_list.append(torch.var(inp[b,c,:]))
print(mean_list)
print(var_list)
# 归一化
out=torch.zeros_like(inp)
# print(len(inp[0,0,:]))
# print(out.shape)
for b in range(N):
for c in range(C):
index=b*C+c
out[b,c,:]=(inp[b,c,:]-mean_list[index])/math.sqrt(var_list[index]+epsilon)
# print(out.shape)
print(out)
print("-"*25)
# 方法二:调用函数
out1=torch.nn.InstanceNorm1d(C)(inp)
print(out1)
二、InstanceNorm2d
1. 介绍
二维实例归一化:计算过程及调用方式同一维实例归一化,二者区别主要在于输入特征形状的变化。
torch.nn.InstanceNorm2d(
num_features, # 与输入特征的通道数保持一致
eps=1e-05,
momentum=0.1,
affine=False,
track_running_stats=False,
device=None,
dtype=None)
Input: (N, C, H, W)
Output: (N, C, H, W)
2.实例
import torch
import math
# shape=(N,C,H,W),N表示样本批次大小,H/W表示该特征图高/宽,C表示每个特征元素对应几个通道
inp=torch.randn(size=(1,3,2,2))
print(inp)
print(inp.shape)
print('-'*20)
out=torch.nn.InstanceNorm2d(3)(inp)
print(out)
print(out.shape)
三、BatchNorm1d
1.介绍
一维批量归一化:其实还是实现前言中介绍的公式,但与实例归一化的最大区别在于计算均值及方差的依据不同。
torch.nn.BatchNorm1d(
num_features,
eps=1e-05,
momentum=0.1,
affine=True,
track_running_stats=True,
device=None,
dtype=None)
Input: (N,C,L), where N is the batch size, C is the number of features or channels, and L is the sequence length
Output: (N,C,L) (same shape as input)
2.实例
import torch
import math
epsilon=1e-5
N,C,L=128,3,512
inp=torch.randn(size=(N,C,L))
# 方法一:手动实现
# 沿着batch计算各个通道的均值
mean_1, mean_2, mean_3 = torch.sum(inp[:,0,:])/(N*L), torch.sum(inp[:,1,:])/(N*L), torch.sum(inp[:,2,:])/(N*L)
mean_list=[mean_1, mean_2, mean_3 ]
# 沿着batch计算各个通道的方差
var_1, var_2, var_3 = torch.var(inp[:,0,:]), torch.var(inp[:,1,:]), torch.var(inp[:,2,:])
var_list=[var_1, var_2, var_3 ]
print(mean_list,var_list)
# 归一化
out=torch.zeros_like(inp)
for c in range(C):
out[:,c,:]=(inp[:,c,:]-mean_list[c])/math.sqrt(var_list[c]+epsilon)
# print(out.shape)
# print(out)
out1=out
print("-"*25)
# 方法二:调用函数
out=torch.nn.BatchNorm1d(C)(inp)
# print(out)
# print(out.shape)
print(True in (out1==out))
四、BatchNorm2d
1.介绍
二维批量归一化:计算过程及调用方式同一维批量归一化,二者区别主要在于输入特征形状的变化。
torch.nn.BatchNorm2d(
num_features,
eps=1e-05,
momentum=0.1,
affine=True,
track_running_stats=True,
device=None,
dtype=None)
Input: (N, C, H, W)
Output: (N, C, H, W)(same shape as input)
2.实例
import torch
# shape=(N,C,H,W),N表示样本批次大小,H/W表示该特征图高/宽,C表示每个特征元素对应几个通道
inp=torch.randn(size=(2,3,5,6))
print(inp)
print(inp.shape)
print('-'*20)
out=torch.nn.BatchNorm2d(3)(inp)
print(out)
print(out.shape)