c语言深度理解(指针与数组)
文章目录
-
- 指针与指针变量
- 指针与数组
- 强制类型转换
- 多维数组与多级指针
- 函数指针
指针与指针变量
指针是地址,指针变量用来存储地址。指针变量由两部分组成。
左值:存储数据的空间(空间)
右值:指针变量中存储的地址(内容)
对指针变量解引用时,使用的是指针变量的内容,里面的地址。解引用代表的是指针所指向的目标
cpu的基本寻址单位是字节,在32位机器下内存有4GB,为了提高寻址效率,cpu需要指针。
我们常说一个变量的地址,有的变量占用的空间不止一个字节,可地址是以字节为单位的,此时取地址取出的是该变量使用的地址中最低的一个地址。
为了安全,防止对内存直接访问的操作发生,出现了栈随机化与”金丝雀“这样的技术。
每次定义变量的地址都是不同的:栈随机化;”金丝雀“则是对数组越界访问的禁止,比较一些此次操作不会被使用的空间前后的数据有无变化,如果变化则非法访问内存,报错。

所以,我们只能使用系统给我们的空间。

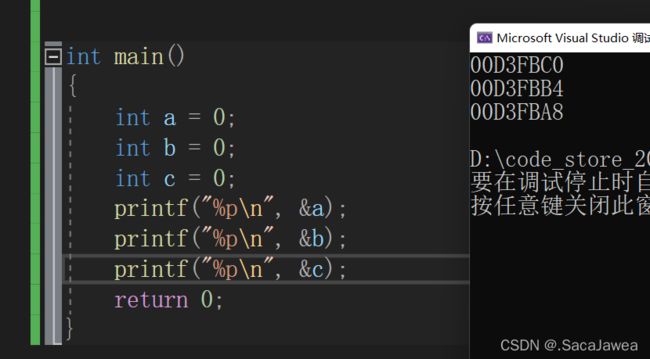
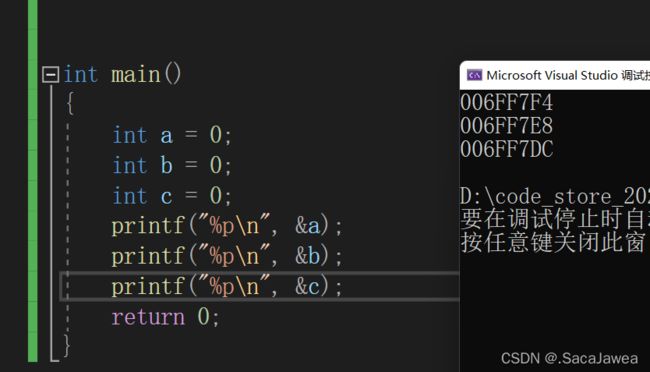
可以看出栈的随机化,也能理解栈区的空间是向低地址使用,后定义的变量地址都小于先定义的变量。
指针与数组
数组是相同类型数据的集合。
数组开辟空间时,先开辟整个数组所需要的空间(整体开辟)。任何在这块空间中,变量是从低地址向高地址使用。总之数组线性连续且成员地址依次递增。所以使用下标访问数组元素时总是++
数组的地址与数组首元素地址在数值上是相同的(数组整体开辟,首元素是整体开辟空间中地址最小的,该地址同时也是整个数组的地址)

两种储存字符串的方式。用数组保存字符串,字符串保存在栈区,总是可以修改数组中的字符串的。但是指针str指向的字符串保存在字符常量区,不能被修改。
两者的访问也是不同的。数组的访问,通过数组名(首元素的地址)找到首元素。而指针的访问,需要先找到指针,再通过指针中的内容(数组首元素的地址)找到数组首元素。
c中可以用[ ]访问数组,也能用指针。为什么要这样设计?
函数传参时,形参作为实参的一份临时拷贝,如果数组太大,在开辟空间创建形参是对空间的浪费,通过指针,通过地址就能很好的访问数组。这种现象叫做数组传参时发生降维,降维成一个指向数组成员类型的指针
通过数组指针,得知数组的元素个数也是数组的一部分
强制类型转换
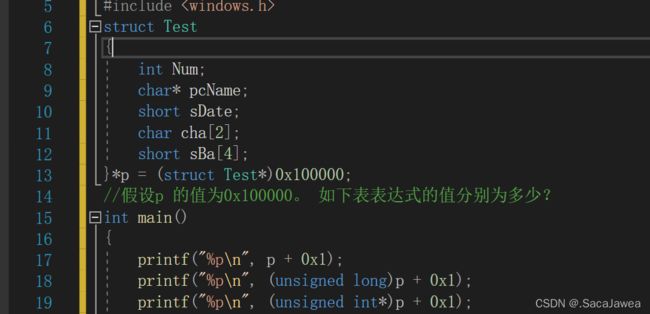
强制类型转换实际是改变对数据的看待方式
多维数组与多级指针
不管几维的数组都能看成一维数组。数组是类型相同的数据集合,所以数组中能存储数组。二维数组就是用数组存储一维数组,三维数组是用数组存储二维数组,以此类推。多维数组在内存上同样是连续且递增,那多维数组我们能通过一次循环完成遍历。
多维数组的数组名同样是首元素的地址,二维数组的数组名是一个一维数组的地址,可以理解成一个指向一维数组的指针。类型是int(*)[4]指向一个数组,数组元素有4个。
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a)); //48
printf("%d\n", sizeof(a[0][0]));//4
printf("%d\n", sizeof(a[0])); //16,数组有3个成员,每个成员是4个整形的数组
//a[0]是第一个成员,也能看成一维数组的数组名
printf("%d\n", sizeof(a[0] + 1)); //4
printf("%d\n", sizeof(*(a[0] + 1))); //4
printf("%d\n", sizeof(a + 1)); //4
printf("%d\n", sizeof(*(a + 1))); //16
printf("%d\n", sizeof(&a[0] + 1)); //4
printf("%d\n", sizeof(*(&a[0] + 1)));//16
printf("%d\n", sizeof(*a)); //16
printf("%d\n", sizeof(a[3])); //16
}
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("a_ptr=%p,p_ptr=%p\n", &a[4][2], &p[4][2]);
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
指针(地址)减指针(地址)得到的是两者之间相差的元素个数。
数组进行函数传参时要发生降维,二维数组传参,降维成一个指向一维数组的指针。int arr[][4] 与 int (*arr) [4]等价。
函数指针
程序在运行时需要加载代码到内存中,函数属于代码的一部分,函数也会被加载到内存区中,所以函数也会有地址,函数名就是其地址,可以不用&。
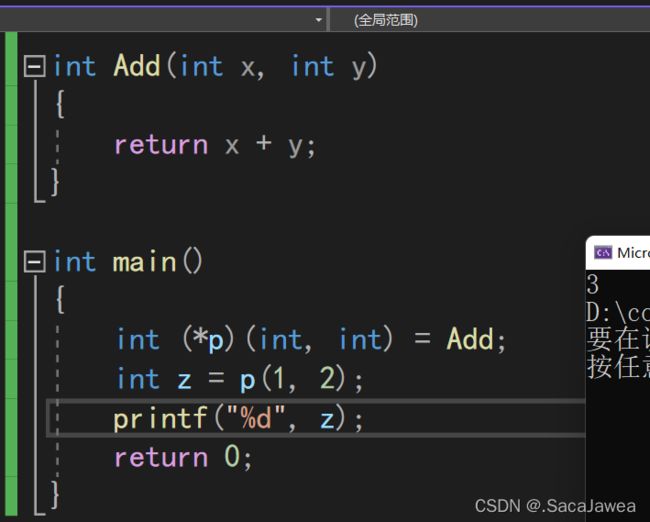
可以把指针变量名当作函数名来调用函数。
本质:函数作为代码的一部分存储在内存中,函数指针记录函数在代码中存储的地址,调用时便执行该地址上的代码。