MySQL索引原理及索引查询优化
文章目录
- 索引介绍
-
- 索引是什么
- 索引的优点和缺点
- 索引分类
- 索引使用
-
- 创建索引
- 删除索引
- 查看索引
- 索引原理
-
- 索引的存储结构
-
- B树和B+树
- 非聚集索引MylSAM
- 聚集索引InnoDB
- 索引使用场景
- 执行计划explain
-
- id
- select_type(重要)
- table
- type(重要)
- possible_keys
- key
- key_len
- ref
- rows
- extra(重要)
- 索引查询优化
索引介绍
索引是什么
索引是帮助MySQL高效获取数据的数据结构。通俗一点理解,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
索引的优点和缺点
优点:
- 可以提高数据检索的效率,降级数据库的IO成本
- 通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
缺点:
- 索引会占用磁盘空间,MySQL要保存索引文件
- 索引会提高查询效率,但是会降低表的增删改操作
索引分类
- 普通索引:加速查询
- 唯一索引:加速查询+列值唯一(可以有null)
- 主键索引:加速查询+列值唯一(不可以有null)+表中只有一个
- 组合索引:多列值组成一个索引,专门用于组合搜素,其效率大于索引合并
- 全文索引:对文本的内容进行分词,进行搜索
索引使用
创建索引
- 普通索引
CREATE INDEX index_name ON table(column(length)) ;
ALTER TABLE table_name ADD INDEX index_name (column(length)) ;
- 唯一索引
CREATE UNIQUE INDEX index_name ON table(column(length)) ;
alter table table_name add unique index index_name(column);
- 组合索引
ALTER TABLE article ADD INDEX index_title_time (title(50),time(10)) ;
- 全文索引
CREATE FULLTEXT INDEX index_name ON table(column(length)) ;
alter table table_name add fulltext index_name(column);
删除索引
DROP INDEX index_name ON table
查看索引
DROP INDEX index_name ON table
索引原理
索引的存储结构
- 索引是在存储引擎中实现的,也就是说不通的存储引擎,会使用不同的索引
- MylSAM和InnoDB存储引擎:只支持B+树索引,也就是说默认使用B树,不能够更换
InnoDB引擎中Hash索引是自适应的,存储引擎会根据表的使用情况自动为表生成哈希索引,不能人为干预是否在一张表中生成哈希索引
B树和B+树
**B树特点 **
- 每个节点不是黑色就是红色
- 根节点是黑色
- 每个叶子节点是黑色。
- 如果一个节点是红色的,则它的子节点必须是黑色的
- 从一个节点到该节点的子孙节点所有路径上包含相同数目的黑节点
B+树与B树区别
- 在B树中,可以将键和值放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
- B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
使用B+树的好处
- B+树内部只存放键,不存放值。因此,一次读取,可以在内存中获取更多的键,有利于更快地缩小查找范围。B+树的叶子节点由一条链相连,因此在范围查找的时候,B+树查找速度更快。
- B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据。
- B+树同时支持随机检索和顺序检索,B树只适合随机检索。
- B+树空间利用率更高,可以减少I/O次数,磁盘读写代价更低。
非聚集索引MylSAM
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。如图:

这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:

聚集索引InnoDB
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
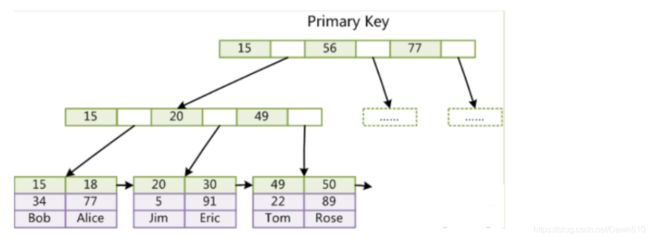
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
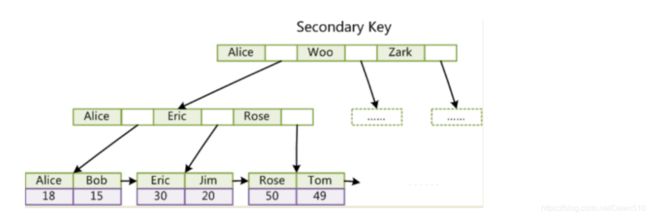
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
索引使用场景
哪些情况需要创建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 多表关联查询中,关联字段应该创建索引
- 查询中排序字段,应该创建索引
- 覆盖索引的好处?不需要回表 组合索引
- 统计或者分组字段,应该创建索引
哪些情况不需要创建索引
- 表记录太少,索引是有额外存储开销的
- 频繁更新 索引要维护
- 查询字段使用频率不高
执行计划explain
expalin出来的信息有10列,分别是:id/select_type/table/type/possible_keys/key/key_len/ref/rows/extra
id
- 每个select语句都会自动分配一个唯一标识符
- id表示查询中操作表的顺序id越大,优先级越高(如果id相同,执行顺序由上到下)
- id为null,表示这是一个结果集,不需要使用它来查询
select_type(重要)
查询类型,主要用于区别普通查询、联合查询、子查询等复杂查询
- simple:不需要UNION或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
- primary:一个需要UNION操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary,且只有一个
- subquery:除了from子句中包含的子查询外,其他地方出现的子查询都可能是subquery
- dependent subquery:这个subquery查询收到外部表查询的影响
- union:UNION连接的两个select查询,除了第一个是PRIMARY,其他的都是UNION
- dependent union:与UNION一样,出现在UNION或者UNION ALL语句中,但是这个查询收到外部查询的影响
- UNION Result:包含UNION的结果集,它不需要参与查询,所以ID为null
- derived:from子句中出现的子查询,也叫作派生表
table
- 查询的表名,如果使用了别名 这里显示的是别名
- 如果不涉及对表的操作,显示为Null
- <>括起来的表示这是个临时表,后边的N是执行计划的id
type(重要)
依次从好到差
system const eq_ref ref fulltext ref_of_null unique_subquery index_subquery range index_merge index ALL
除了ALL意外,其他的type都可以使用索引,除了index_merge之外,其他的type只可以用到一个索引。使用索引至少要到range级别
优化器会选用最优索引一个
- system:表中只有一行数据或者空表
- const:使用唯一索引或者主键,返回记录一定是1行记录
- eq_ref:连接字段 主键或者唯一性索引,对于前表的每一个结果,都只能匹配到后表的一行结果
- ref:针对非唯一索引,使用等值(=)查询。或者是使用了最左前缀规则索引的查询
- fulltex:全文索引检索,全文索引的优先级很高
- ref_or_null:与ref相似,只是增加了null值的比较
- uqinue_subquery:用于where中的in形式子查询,子查询返回不重复唯一值
- index_subquery:用于in形式查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重
- range:索引范围扫描,常见于>,<,is null,between,in,like等运算符的查询中
- index_merge:表示查询用到了两个以上的索引,最后取交集或者并集,常见and,or的条件使用了不同的索引。
- index:索引全表扫描。出现在索引树中的节点,可能没有完全匹配索引
- all:全表扫描
possible_keys
查询中可能使用到的索引,一个或多个
key
查询中真正使用到的索引,select_type为index_merge时,这里可能出现两个以上索引。
key_len
处理查询的索引长度,只计算用到的索引长度。
ref
- 如果是使用的常熟等值查询,这里会显示const
- 如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段
- 如果是条件使用了表达式或者函数,或者条件列发送了内部隐式转换,这里可能显示为func
rows
执行计划中估算你的扫描行数
extra(重要)
这个列包含不适合在其他列中显示,但非常重要的额外信息
- no tables used:不带from子句的查询
- using filesort:排序时无法使用到索引
- using index:不需要回表查询
- using temporary:使用了临时表来存储中间结果
- using where:表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤
索引查询优化
- 全值匹配:条件与索引一一对应
- 最左前缀法则:带头索引不能死,中间索引不能断
- 不在索引上做计算:计算、函数、类型转换,会导致索引失效而转向全表扫描
- 范围条件右边列失效:不能继续使用索引中范围条件(between//in等)右边的列
- 尽量使用覆盖索引,也就是索隐裂和查询列一致,减少select *
- 索引字段上不要使用不等
- 主键索引不可以判断为Null
- 索引字段使用like不以通配符开头
- 索引字段字符串要加单引号
- 索引字段不要使用or