Alluxio部署实践与性能调优
1. Alluxio基本介绍
1.1 Alluxio架构
Alluxio主要有三个角色:master、worker和client。
master
master负责管理所有的元数据,包括inode元数据、数据块元数据以及Alluxio自身的工作负载元数据等等;master还会保存文件block与worker的对应关系,并检查所有的worker状态,worker会定期向当前master发送心跳包。HA部署模式下,leader master会记录操作日志到journal中;
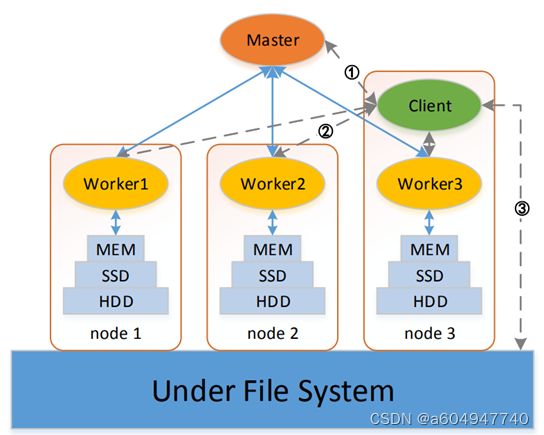
worker
worker负责管理worker所在节点的资源,如内存、SSD和HDD等。worker也负责响应client的请求,将数据写入到缓存中的block中,当缓存被写满时,worker还会根据预设的策略进行数据块替换。
client
client,即客户端,是与Alluxio进行交互的入口。client与master通信以获取元数据,对worker发起请求以进行数据的读写。Alluxio提供了基于HDFS、S3等等的API以进行数据读写,也支持通过多种语言的API访问。需要注意的是,通过client无法直接访问底层存储,即使不开启缓存,访问请求和返回数据也会经过Alluxio进行转发。
1.2 Alluxio服务组成
从实际使用的角度出发,可将Alluxio的节点角色抽象为三种服务:Caching、Catalog和Transformation。
Caching
Caching即缓存服务,就是worker所负责的功能,包括了数据的读写、请求响应、缓存替换等功能,这部分主要体现在worker中,也是Alluxio的核心功能。为保持最高的缓存性能,Caching需要在集群中配置ramdisk内存文件系统,更为常见的做法是多层存储,将SSD、HDD等介质的存储资源均配置到Caching中。除此之外,可通过配置数据块生存时间、数据块副本来最大化缓存性能,Caching中也内置了一些优化策略,用来提高缓存数据的读取效率。
Catalog
从Alluxio 2.1开始,Alluxio引入了Catalog服务,Catalog负责管理结构化元数据以及Alluxio自身的元数据Cache,存储了数据库的表、数据格式、存储目录等信息,并支持读取Hive或Glue的元数据,这部分功能体现在master中。分布式查询引擎PrestoSQL和PrestoDB内置了支持Alluxio的连接器,通过Catalog服务,PrestoSQL和PrestoDB可直接访问缓存在Alluxio中的元数据,而不需要从HMS获取元数据,提高了查询的执行效率。Catalog服务的一些使用方法将在下文中详细展开介绍,包括数据文件格式转换、attach数据库、元数据同步等等。
Transformation
基于Catalog服务,Alluxio还有一个独立的服务Transformation。同样是从Alluxio 2.1开始,Alluxio引入了Transformation服务,主要功能是将csv、parquet、orc等格式的文件统一转换为parquet格式文件,同时将小文件进行合并,这部分功能主要体现在job_master和job_worker中。从Alluxio 2.3开始,Transformation的结果统一为parquet格式,Transformation的功能需要Catalog服务先attach一个Hive的数据库,随后通过命令行进行文件格式转换,Alluxio会通过job_master将任务分发到job_worker上进行执行,转换后的文件将写入到Caching中,但元数据不会写回Hive metastore。
1.3 Alluxio与其他大数据系统
Alluxio可作为Spark、Presto、Impala等系统的后端存储,也可作为HDFS、S3、COS等存储引擎的上层缓存,通过在配置文件中设置不同的访问方式,客户端可访问Alluxio中的数据或绕路访问底层存储的数据。Alluxio通过统一命名空间,可同时挂载不同存储引擎的底层存储,如通过mount命令可实现通过alluxio://path的地址来同时访问HDFS和S3上的存储,并把这些不同存储引擎上的数据缓存到Alluxio中,降低了运维管理成本。Alluxio也可作为Presto等查询引擎的存储后端,通过将查询热点缓存到内存/SSD中来提高查询效率。将查询频率较高的表从HDFS缓存到Alluxio中,并利用pin命令禁止将其替换出缓存,相比从HDFS获取数据,利用Alluxio可实现较为可观的查询效率提升。对于数据集规模较大的机器学习场景,也可将数据集缓存到Alluxio中,加速如Tensorflow、PyTorch等机器学习框架的训练速度。
2. Alluxio基本使用
2.1 Alluxio基本运维
Alluxio的编译&部署可见另一篇文档,此处不作赘述,仅简要介绍Alluxio的运维相关操作。
启动
如果部署账户能免密到所有部署节点,则可通过一台机器统一启动Alluxio集群:
- 进入$ALLUXIO_HOME/bin,执行./alluxio-start.sh all,随后脚本将自动kill已启动的Alluxio服务进程,并重新启动所有Alluxio服务进程,如果有节点上的服务启动失败,可在节点上单独重新启动。
如果没有配置或无法配置免密ssh,也可手动单独启动服务:
- 在master所在节点的$ALLUXIO_HOME/bin目录执行./alluxio-start.sh master,如果配置了高可用,可同时启动所有master,启动成功后会自动进行leader选举,通过alluxio fs masterInfo查看。master启动完成后执行./alluxio-start.sh job_master和./alluxio-start.sh proxy,启动作业master服务和代理服务。
- master启动并选举出leader master后,在所有worker节点执行./alluxio-start.sh worker Mount,启动worker服务,并挂载ramdisk到配置的目录中(如果已挂载则忽略)。启动成功后再执行./alluxio-start.sh job_worker和./alluxio-start.sh proxy,启动作业worker服务和代理。
Alluxio集群启动后可通过WebUI查看集群情况,有不同的页面用来查看存储空间、配置项、数据目录、worker节点情况等等。
停止
有免密ssh的可直接在任意节点执行./alluxio-stop.sh all,如果有报错停止失败的服务可直接到节点上kill掉。没有ssh免密的节点则需要手动停止所有Alluxio服务,执行./alluxio-stop.sh master/worker/job_master /job_worker/proxy,执行顺序可任意。
2.2 Alluxio常用操作
Alluxio的命令行操作与Hadoop命令类似,下表简要介绍了常用的一些Alluxio命令,完整的命令说明可见官方文档。
| 命令 | 功能 |
|---|---|
| alluxio getConf | 读取alluxio-site.properties查看当前的Alluxio配置(不一定是目前生效的配置,需要重启集群才能使修改后的配置生效) |
| alluxio fs masterInfo | 查看HA模式部署的当前Alluxio master |
| alluxio fs ls [-R] /path/to/data | (递归地)查看/path/to/data路径的文件 |
| alluxio fs chmod [-R] XXX /path | (递归地)将/path目录的权限设为XXX,chgrp和chown同理 |
| alluxio fs rm [-R] [–alluxioOnly] /path | (递归地)将Alluxio及UFS(或仅Alluxio)上/path的数据删除(正在使用中的数据立即不可用) |
| alluxio fs load /path | 将UFS上的/path目录加载到Alluxio缓存中 |
| alluxio fs free /path | 将Alluxio缓存上的/path目录释放(正在使用中的数据仍可用) |
| alluxio fs pin/unpin /path | 将Alluxio缓存上/path路径固定住/解除固定,用于禁止空间不足时的数据块换出 |
| alluxio fs location /path | 查看/path目录的数据位于哪些worker上 |
| alluxio fs mount /path UFS://u_path | 将UFS上的/u_path挂载到Alluxio的/path目录 |
| alluxio fs setTtl [–action delete] /path ttl_ms | 将/path路径的数据设为ttl_ms毫秒后失效,将其移出Alluxio |
| alluxio fs checkConsistency [-r] | 检查(并修复)Alluxio与UFS元数据的差异 |
| alluxio fs setfacl ‘u/g/o:name:rwx’ /path | 设置/path路径的UGO权限 |
| alluxio fs getfacl /path | 返回/path路径的UGO权限 |
下面基于上表的命令,针对几个Alluxio的特性功能和常见问题进行详细介绍。
文件格式转换(合并)
从Alluxio 2.1版本开始,Alluxio支持将ORC、Parquet以及CSV格式的文件转换为Parquet格式,同时将文件合并为至少100个、每个2GB的大小(默认)。通过以下步骤实现:
- 通过Catalog服务将底层数据库attach到Alluxio中,执行
alluxio table attachdb --ignore-sync-errors hive thrift://{hostname}:{hms_port} db_name
其中底层数据库支持Hive或Glue;
2. 执行alluxio命令
alluxio table transform db_name table_name
# 如果在attach之后数据产生变动,需要额外执行同步操作:
alluxio table sync db_name
转换的结果文件默认存储在ufs://namespace/catalog目录,因此没有根目录读写权限时会转换失败,可通过增加配置项来更改转换结果的位置目录:
alluxio.table.catalog.path=/path/to/catalog
元数据同步
当上层数据写入底层时,如果全部读写均走Alluxio,则不存在元数据问题;但如果仅通过Alluxio读或部分写入操作通过Alluxio完成,可能存在元数据不同步的问题,如下图所示:

此时读取非Alluxio更改的数据,将可能读取失败,同时Alluxio会报错:

针对此问题,Alluxio有手动同步元数据的命令(上表的最后一个),执行
alluxio fs checkConsistency -r /path
将修复Alluxio中/path目录与UFS的元数据异常,即进行同步。另外,在Alluxio 2.0.0以后的版本中,引入了元数据自动同步的功能(需UFS为HDFS,且版本>2.6.1)。Alluxio侧将主动监听HDFS的数据修改事件,并自动将其同步在Alluxio中,通过以下命令开启:
alluxio fs startSync /path
开启后Alluxio将自动监听/path目录的写入删除操作。而Alluxio官方表示,元数据同步效率较低,不推荐频繁同步,因此还有若干配置项用来提高自动同步的效率:
alluxio.master.activesync.interval
此配置项默认值为30,表示每30秒同步一次元数据,也可自行设定为其他值;
alluxio.master.activesync.maxactivity
如果目前对同步目录进行了较大的修改操作,为了不增加UFS的工作负载,Alluxio会在同步目录相对不那么忙碌的期间进行元数据同步。此配置项表示HDFS的修改事件数目的指数移动平均值最大达到多大时停止元数据同步。举例来说,如果在3个间隔内,每个间隔的HDFS事件数分别为100、10、1,则这期间的HDFS事件指数移动平均值为3,如果配置项的值小于3,则会停止元数据自动同步。在实际使用场景中,应预先考虑到可能的HDFS操作,并根据实际情况设定;
alluxio.master.activesync.maxage
为防止alluxio.master.activesync.maxactivity配置项导致很长时间内都没有元数据自动同步,可增加此配置项来进行限制。假如设定为5,那么在maxactivity配置项的基础上,当跳过了5个同步间隔时,强行进行元数据同步,防止Alluxio与UFS的元数据出现不一致。
元数据缓存
区别于上文中的UFS元数据,此处的元数据是指Alluxio中master所管理的所有元数据,不仅包括UFS元数据,还有Alluxio自身存储的ACL相关数据等等。这些数据默认存储在内存中,如果master因为某些原因宕机,元数据就会丢失,即使master恢复也可能出现元数据丢失导致的数据访问报错。针对此问题,Alluxio在2.0版本开始支持了将元数据存储在RocksDB的配置项:
alluxio.master.metastore=ROCKS #默认为HEAD,即存储在内存中
配置为ROCKS后,所有元数据将存储于RocksDB数据库中,重启master也不会丢失。由于Alluxio中数据的ACL继承于UFS,如果UFS不支持ACL配置则需要用户自己设置目录权限组,使得一旦元数据丢失则会产生很大的运维成本,此时将元数据配置为RocksDB存储就可应对这种情况。
Alluxio也支持内存和RocksDB两种存储方式之间的切换,比如Alluxio集群部署时没有配置RocksDB元数据存储,使用一段时间后想要切换为RocksDB时,则需要进行切换。Alluxio给出的步骤为:
1. 备份。执行以下命令:
alluxio fsadmin backup
2. 修改alluxio-site.properties配置文件:
alluxio.master.metastore=ROCKS
3. 关闭master,然后执行日志格式化:
./alluxio-stop.sh masters
alluxio formatMasters
4. 从备份启动master
./alluxio-start.sh -i /path/to/backup masters
其中备份存储路径/path/to/backup如下图所示,在执行备份命令时输出的Backup URI。通过上述命令启动后master将从之前备份的元数据继续恢复运行。

Alluxio对于RocksDB中的元数据也采用了分级缓存的策略,访问频率相对较高的元数据将存储在内存Cache中,其他冷数据将存储在RocksDB中。就inode元数据来说,每1千万个inode将占用约1GB的存储空间,为节约元数据对内存的空间占用,Alluxio引入了数个配置项来优化元数据的存储。
alluxio.master.metastore.dir
默认为$ALLUXIO_HOME/metastore,表示RocksDB数据的存储目录。
alluxio.master.metastore.inode.cache.max.size
默认10000000,表示内存Cache存储的最大inode数量,默认10000000即表示占用1GB空间。
alluxio.master.metastore.inode.cache.evict.batch.size
默认为1000,表示达到缓存替换阈值时,默认每次缓存替换内存Cache中的1000个inode。
alluxio.master.metastore.inode.cache.high.water.mark.ratio
默认0.85,表示内存Cache空间使用了85%时,达到缓存替换阈值,开始进行缓存替换。
alluxio.master.metastore.inode.cache.low.water.mark.ratio
默认为0.8,表示当缓存替换使得内存Cache空间占用比例小于80%时,停止缓存替换。
ACL相关设置
在S3场景下,UFS中的数据不像在HDFS中可以设置权限,而直接通过chmod/chown/chgrp将更改整个目录的权限,无法灵活设置各子目录的ACL,因此需要通过Alluxio来设置目录访问权限。Alluxio设置ACL的方式与linux系统中的setfacl命令类似,也是可单独为某个目录及子目录设置某用户/用户组的rwx权限,设置方法举例如下:
# 给/path/to/data路径(-R表示同时递归更改子目录及文件)增加hadoop用户组的所有rwx权限
alluxio fs setfacl [-R] -m 'group:hadoop:rwx' /path/to/data
# 给/path/to/data路径增加netease用户的所有rwx默认权限(仅增加默认权限,不改变现有ACL,新建的子目录及文件会继承默认权限)
alluxio fs setfacl -d -m 'user:netease:rwx' /path/to/data
# 给/path/to/data路径及其子目录递归增加hadoop用户组的r-x权限(仅对目录生效,对文件不生效)
alluxio fs setfacl -R -d -m 'group:hadoop:r-x' /path/to/data
查看某个目录的ACL可通过getfacl实现:
alluxio fs getfacl /path/to/data
返回类似下图

通过setfacl命令设置ACL需要遵循’user/group/other:name:rwx’的规则。需要注意的是,所有设置的访问权限均无法超过mask值的限制,如果某目录的mask值为r-x,那么即使设置了某用户的rwx权限,也只能获得r-x的权限。在实际线上环境的使用过程中,我们发现Alluxio社区版的两个问题(2.4.1-1版本):
1.设置了默认mask后,子目录无法正确继承mask值
经过多次测试均发现,对某个目录设置了默认mask为rwx后,新建的子目录的mask仍为r-x。分析Alluxio代码后发现是由于新建目录时,Alluxio会先获取父目录的默认mask,然后与父目录的group权限相与,得到的结果作为子目录的mask值。
2.通过setfacl -R -d -m设置目录权限时,如果目录中有文件,会设置失败
Alluxio虽然仿照linux系统的setfacl命令实现了Alluxio版本的setfacl命令,但对于存在文件的场景没有正确处理。在linux中,如果某目录存在文件,对整个目录通过递归方式设置默认权限不会报错(文件inode无法设置默认权限),而是自动跳过文件并设置其他子目录的权限。Alluxio中则会直接报类似下图的错误,然后不会设置其他子目录的权限,这样使得当目录已存在很多数据时,无法统一为其添加新的ACL设置,只能一个一个子目录去单独设置。
对于以上两个问题,笔者所在团队基于Alluxio 2.4.1-1增加了两个临时patch,用来1)使子目录能够正确继承默认mask;2)当目录中存在文件时,setfacl会自动跳过,而不是直接返回。
3. Alluxio性能调优配置
在Alluxio中,某些配置项仅使用默认值会对性能产生负面影响,而某些配置项如果根据使用场景进行配置,则会提高缓存性能。本节将从配置项出发,对可能影响Alluxio性能的配置项进行简介,并针对性地给出一些推荐值。
worker定位相关配置
1. alluxio.user.ufs.block.read.location.policy
默认值:alluxio.client.block.policy.LocalFirstPolicy
此配置项表示在读取数据时,优先去哪些worker进行扫描,由于alluxio读取未缓存数据时,根据不同的配置策略可能在读数据的时候也会进行写入,因此读取数据与写入数据的worker策略类似,可选项如下:
1. alluxio.client.block.policy.DeterministicHashPolicy
表示不同的访问请求采用相同的哈希函数确定worker序号,并通过alluxio.user.ufs.block.read.location.policy.deterministic.hash. shards参数来确定请求会被路由到多少个worker上;
2. alluxio.client.block.policy.LocalFirstPolicy
表示总是先选择本地worker进行读取;如果本地worker空间已满,则随机返回一个worker;
3. alluxio.client.block.policy.LocalFirstAvoidEvictionPolicy
与LocalFirstPolicy类似,优先返回本地worker;如果本地worker空间已满,则随机返回一个worker;如果没有满足条件的worker,则仍返回本地worker(将触发缓存替换)
4. alluxio.client.block.policy.MostAvailableFirstPolicy
总是返回可用空间最大的worker
5. alluxio.client.block.policy.RoundRobinPolicy
轮流返回每一个可用的worker
6. alluxio.client.block.policy.SpecificHostPolicy
通过hostname指定每次访问时的worker
此配置项也可以通过自行实现BlockLocationPolicy接口来实现自定义的worker选择策略。如果想要数据在各worker之间的分布相对均衡,可使用RoundRobinPolicy;如果要读写性能最佳,则应使用默认配置LocalFirstPolicy;如果是查询频率较高的场景,推荐使用DeterministicHashPolicy,并设置shards与数据副本数相同。
2. alluxio.user.block.write.location.policy.class
默认值:alluxio.client.block.policy.LocalFirstPolicy
在写入数据块时,决定选取哪个worker进行写入的配置,与alluxio.user.ufs.block.read.location.policy配置项相同,也可以自行实现BlockLocation-Policy接口来实现自定义的worker选择策略,此配置有4个可选项:
1. alluxio.client.block.policy.LocalFirstPolicy
表示总是先选择本地worker进行写入;如果本地worker空间已满,则随机返回一个worker;
2. alluxio.client.block.policy.MostAvailableFirstPolicy
总是返回可用空间最大的worker进行写入;
3. alluxio.client.block.policy.RoundRobinPolicy
轮流返回每一个可用的worker进行写入;
4. alluxio.client.block.policy.SpecificHostPolicy
通过hostname指定每次写入时的worker;
数据缓存相关配置
1. alluxio.worker.block.annotator.class
默认值:alluxio.worker.block.annotator.LRUAnnotator
此配置项表示,当某个缓存层(MEM/SSD/HDD)空间不足时,采用哪种缓存数据块替换策略,有两个可选项:
#以下选项适用于Alluxio 2.3.0及以上版本
1. alluxio.worker.block.annotator.LRUAnnotator
最近最少使用替换策略,将选取最近最少访问的数据块进行替换。
2. alluxio.worker.block.annotator.LRFUAnnotator
最近最不经常使用与LRU的混合策略,有两个配置项可对此进行相关参数调整:
a. alluxio.worker.block.annotator.lrfu.step.factor
LRFU的权重参数,取值[0, 1],靠近0时将接近LFU策略,靠近1时将接近LRU策略;
b. alluxio.worker.block.annotator.lrfu.attenuation.factor
衰减因子,取值[2, +∞),控制块替换的顺序;
2. alluxio.worker.tieredstore.reserver.interval.ms
默认值:1000
表示默认每1000毫秒检查一次缓存层空间是否足够,如果不足则需要进行缓存替换。
3. alluxio.worker.allocator.class
默认值:alluxio.worker.block.allocator.MaxFreeAllocator
用来确定新存储块写入时,往哪个缓存层的目录进行写入(针对相同层有多个存储目录),有3个可选项:
1. alluxio.worker.block.allocator.MaxFreeAllocator
返回具有最大可用空间比例的目录,而且总是返回最高存储层
2. alluxio.worker.block.allocator.GreedyAllocator
直接返回第一个符合写入数据块大小的目录
3. alluxio.worker.block.allocator.RoundRobinAllocator
先从最高层开始,最高层的每个目录轮流进行数据块的写入,如果空间不足,则顺延到下一缓存层
4. alluxio.user.file.readtype.default
默认值:CACHE
通过Alluxio读取数据时,如果此数据没有缓存在Alluxio中,Alluxio会根据配置来决定是否将其缓存进来,此配置项控制了通过Alluxio读取数据时,缓存的相关策略,共有3个可选项:
1. CACHE:在读取UFS上的数据时,不仅将其缓存,还要缓存在最高的缓存层中
2. CACHE_PROMOTE:读取UFS的数据时,行为与CACHE模式的相同;读取Alluxio上的数据时,也将其移动到最高缓存层;
3. NO_CACHE:读取UFS数据时,不将其缓存到Alluxio中,读取Alluxio已缓存的数据也不会移动其缓存层;
5. alluxio.user.file.writetype.default
默认值:ASYNC_THROUGH
通过Alluxio写入数据时,Alluxio会根据不同的配置来决定是否将其持久化到UFS中,抑或是否只写入Alluxio或UFS,有4个可选项:
1. ASYNC_THROUGH:先将数据写到Alluxio,再异步地将数据写到UFS持久化;
2. MUST_CACHE:数据块只写在Alluxio中,且会写在最高层,这种模式最快;
3. CACHE_THROUGH:数据块试图写到worker的最高层,并同步地写回UFS;
4. THROUGH:不缓存数据在Alluxio中,直接将其写到UFS;
数据规模相关配置
1. alluxio.user.file.passive.cache.enabled
默认值:true
表示是否将远程worker读取过来的数据块缓存到本地worker。
2. alluxio.user.file.replication.max
默认值:-1
数据块副本的数量上限,为-1时表示无上限,即所有worker都保留有任意数据块的副本。
3. alluxio.user.file.replication.min
默认值:0
数据块副本的数量下限,结合前一个配置表示默认情况下,每个worker都将缓存同一个数据块的数据,会造成数据冗余。
4. alluxio.user.file.replication.durable
默认值:1
当写入配置采用ASYNC_THROUGH时,此配置生效,表示向worker写入数据时的初始副本个数,写入模式为其他时,初始副本个数以alluxio.user.file.replication.min为准。
(注:数据副本也可通过命令行来设置,如执行alluxio fs setReplication --min 3 --max 5 -R /path,则将把/path目录设定为最少3个最多5个副本,用这种方式设定副本的数据将被pin在缓存中,不可换出)
5. alluxio.master.persistence.blacklist
默认值:空
设定为某目录后,此目录下的数据都不会缓存到Alluxio中。
6. alluxio.user.file.persist.on.rename
默认值:false
表示默认不将重命名的文件或目录持久化到UFS中。
7. alluxio.master.whitelist
默认值:/
表示默认将缓存根目录的所有数据到Alluxio中,也可以配置为单独的某个目录,此时只会缓存此目录的数据;
8. alluxio.master.startup.block.integrity.check.enabled
默认值:true
在Alluxio 1.7.1版本后开始支持,表示在启动master时,是否删除缓存中孤立失效的数据块。
其他性能相关配置
1. alluxio.worker.ufs.instream.cache.enabled
默认值:true
此配置表示默认将UFS文件的定位信息流缓存到Alluxio元数据缓存中,下次访问相同数据块时,可提高访问速度。
2. alluxio.worker.ufs.instream.cache.expiration.time
默认值:5min
结合前一个配置项,表示每个文件定位信息流的缓存有效期为默认5分钟。
3. alluxio.worker.ufs.instream.cache.max.size
默认值:5000
表示缓存定位信息流的最大个数默认为5000,与HDFS集群中的dfs.datanode.handler.count配置相对应。
4. alluxio.integration.master.resource.cpu
默认值:1
默认每个master进程将占用1个CPU的资源。
5. alluxio.integration.master.resource.mem
默认值:1
默认每个master进程将占用1GB的内存资源。
6. alluxio.integration.worker.resource.cpu
默认值:1
默认每个worker进程将占用1个CPU的资源。
7. alluxio.integration.worker.resource.mem
默认值:1
默认每个worker进程将占用1GB的内存资源。
8. alluxio.underfs.hdfs.remote
默认值:true
表示默认情况下,当dn与worker处于相同节点时,alluxio不通过HDFS的api获取本地数据块的距离信息,否则将通过getFileBlockLocations来获取数据块的位置,将产生额外数据访问开销。
集群稳定性相关配置
使用Alluxio内置Raft协议实现高可用部署
alluxio.master.hostname:配置高可用时,需将所有master的hostname加入到此配置项中。
alluxio.master.mount.table.root.ufs:UFS的访问URI。
alluxio.master.embedded.journal.addresses:参加leading master选举的所有master的hostname。
以上配置完成并启动master后,可通过alluxio fs masterInfo来查看目前的leading master,高可用模式下,master之间将自动同步元数据。
使用ZooKeeper实现高可用部署
alluxio.zookeeper.enabled:是否开启zk实现高可用
alluxio.zookeeper.address:要连接的zk集群地址
alluxio.master.journal.type:zk模式只能通过UFS来存放读写日志
alluxio.master.journal.folder:UFS中日志存储位置的URI
连接高可用模式的Alluxio集群时,需要将所有master的地址均写入到客户端的配置文件中。
worker可用性相关配置
1. alluxio.worker.block.heartbeat.interval
默认值:1s
表示worker每1秒发送心跳包给master。
2. alluxio.worker.block.heartbeat.timeout
默认值:1h
表示默认master在1小时没有收到worker的心跳后,将此worker放入failed worker中,需要注意的是,数据块读取失败的worker也会变为failed worker。
3. alluxio.underfs.allow.set.owner.failure
默认值:false
alluxio会试图将新写入数据的owner改为alluxio,默认情况下,如果获取不到owner权限,数据将无法写入,将此配置项改为true可解决此问题。
4. 总结
Alluxio作为一个开源分布式缓存系统,其性能对使用过程中的配置较为敏感。本文介绍了Alluxio的基础使用方法,并给出了一些有助于Alluxio性能调优的配置项及推荐值。在实际使用过程中发现了一些Alluxio的问题:Alluxio社区版的ACL设置命令有一定缺陷,不够灵活;Alluxio目录结构中的默认权限设置存在bug等等