Redis缓存服务器搭建与解析
Redis缓存服务器
什么是redis?
redis是一个开源,C语言编写的高级键值缓存和持久性存储的Nosql数据库产品,它可以作为数据库,也可以作为缓存作用的消息中间人
redis的特点:1.高速读写的能力,存储数据的类型丰富
2.能够支持持久化(把内存上的数据写到磁盘上实现持久存储)
3.支持多事务,消息队列、消息订阅的功能
4.支持高可用以及分布式分片集群
redis与memcache和tair的比较
memcache:高性能的读写能力,支持客户端式分布式集群,多线程读写性能高,但是数据单一,无持久化,节点故障容易出现问题,因为分布式需要客户端实现,所以跨机房数据同步困难,架构扩容难度高
tair:高性能读写,支持高可用和分布式分片集群,淘宝在使用,但是单机的情况,它的读写能力比memcache和redis都要慢
redis:高性能读写,多数据类型,数据持久化,高可用架构,可以自定义虚拟内存,支持分布式分片集群,单线程读写能力极高,但是多线程读写比mencache差
redis的常用环境架构
Redis+MySQL+MongoDB(如下图所示)
一、redis安装配置以及基础应用
下载安装redis安装
1.下载安装redis(官方已经编译了redis源码包生成Makefile文件了,所以这里直接安装就行了)
tar zxf redis-4.0.9.tar.gz
cd redis-4.0.9
make && make PREFIX=/usr/local/redis install
2.创建和配置配置文件(直接使用安装包里面的redis.conf模板)
mkdir -p /usr/local/redis/conf
cp redis.conf /usr/local/redis/conf/redis.conf
3.命令操作
命令存放在安装目录下:/usr/local/redis/bin
redis-benchmark:性能测试工具,可以在自己本地运行,看看自己本地性能如何(服务启动起来后执行)
redis-check-aof:修复有问题的AOF文件,持久化
redis-check-rdb:修复有问题的dump.rdb文件
redis-sentinel:Redis集群使用,哨兵
redis-server:Redis服务器启动命令
redis-cli:客户端,操作入口
启动服务(指定配置文件):redis-server /usr/local/redis/conf/redis.conf
连接redis:redis-cli -h 127.0.0.1 -p 6379 -a password
二、数据库的常用操作
set:存放数据
get:获取数据
keys:获取符合规则的键值列表
exists:命令可以判断键值是否存在
type:获取 key 对应的 value 值类型
rename:对已有 key 进行重命名(强制覆盖)
renamenx:命令的作用是对已有 key 进行重命名,并检测新名是否存在。
dbsize:命令的作用是查看当前数据库中 key 的数目
exists key:确认key是否存在
set key value:设置key和value
get key:获取key的value
del key:删除一个key
type key:返回值的类
keys pattern:返回满足给定pattern的所有key
random key:随机返回key空间的一个key
rename oldname newname:重命名
select index:选择第0~15中的库
move key dbindex:移动当前数据库中的key到dbindex数据库
redis数据库整库删除:
清除当前数据库数据:FLUSHDB
清空所有库的数据库:FLUSHALL
redis数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)
三、redis事务
事务时提供多个命令请求打包,然后依次一次性执行的机制,服务器不会中断事务去执行其他客户端命令
redis事务只保证讲命令序列中操作的结果提交到内存中,不一定永久保存,但传统关系型数据库事务完成,数据永久存储
事务的操作:
multi:事务开始
exec:提交事务
discard:结束事务
watch:执行乐观锁(悲观锁)从2.2版本
unwatch:取消乐观锁
事务的特性:1.入队错误,全体连坐(如果其中一个命令格式错误或者不存在将会终止整个事务)
2.执行错误,照常执行(就是事务队列中命令格式或本身没错,而是执行命令出现的错误,事务不会终止,会继续执行事务中的其他命令,并且已经执行的命令出现的错误不会影响其他命令)
3.由乐观锁失败的错误,事务提交时,将丢弃之前缓存的所有命令序列
四、redis数据持久化
redis的所有数据都是保存在内存中
半持久化模式:然后不定期的通过异步方式保存到磁盘上
全持久化模式:把每一次数据变化都写入到一个appendonlyfile(aof)里面
半持久化,RDB 持久化(原理是将 Reids 在内存中的数据库记录定时dump到磁盘上的RDB持久化):持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘
全持久化,AOF 持久化(原理是将 Reids 的操作日志以追加的方式写入文件):持久化以日志的形式记录服务器所处理的每一个写、删除操作
RDB和AOF的优缺点对比
RDB的优点:
1.整个 Redis 数据库将只包含一个文件
2.性能最大化
3.相比于 AOF 机制,如果数据集很大,RDB 的启动效率会更高
RDB的缺点:
1.数据有丢失的风险
2.故障风险大(由于 RDB 是通过 fork 子进程来协助完成数据持久化工作的,因此当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是 1 秒钟)
AOF的优点:
AOF 机制可以带来更高的数据安全性
1.Redis 中提供了 3 种同步策略:即每秒同步、每次修改同步和不同步
2.追加方式写入日志文件,写入过程出现宕机, redis-check-aof工具来解决数据一致性的问题
3.如果日志过大,Redis 可以自动启用 rewrite 机制
4.可以通过该文件完成数据的重建
AOF的缺点:
1.AOF机制 每次发生的数据变化都会被立即记录到磁盘中,这种方式在效率上是最低的
2.对于相同数量的数据集而言,AOF 文件通常要大于 RDB 文件
3.RDB 在恢复大数据集 时的速度比 AOF 的恢复速度要快
RDB持久化配置
在配置文件中配置
#时间的配置策略
save 900 1
save 300 10
save 60 10000
rdbcompression yes \\是否压缩
rdbchecksum yes \\导入时是否检查
stop-writes-on-bgsave-error yes \\如果持久化出错,主进程是否停止写入
#针对RDB方式的持久化,手动触发可以使用:
save \\会阻塞当前Redis服务器,直到持久化完成,线上应该禁止使用。
bgsave \\该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候AOF持久化配置
appendonly yes \\是否开启aof
appendfilename "appendonly.aof" \\文件的名称
appendfsync everysec \\模式选择
#它其实有三种模式:
#always:把每个写命令都立即同步到aof,很慢,但是很安全
#everysec:每秒同步一次,是折中方案
#no:redis不处理交给OS来处理,非常快,但是也最不安全
#AOF文件过大 通过移除 AOF 文件中的冗余命令来重写(rewrite)AOF 文件
#Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发五、redis备份恢复
数据的备份恢复:redis所有数据都是保存在内存中,redis数据备份可以定期的通过异步方式保存到磁盘上,该方式称为半持久化模式,如果每一次数据变化都写入aof文件里面,则称为全持久化模式
文件的备份恢复:持久化文件的保存和恢复,定期进行备份恢复操作,rsync
服务器的备份恢复:通过redis主从复制实现Redis备份与恢复
六、redis性能管理
查看redis内存使用情况:info memory
内存使用率
mem_fragmentation_ratio=used_memory_rss(内存碎片率)/used_memory(redis使用的内存值)
used_memory:由 Redis 分配器分配的内存总量,包含了redis进程内部的开销和数据占用的内存,以字节(byte)为单位
used_memory_human:以更直观的可读格式显示返回使用的内存量。
used_memory_rss:rss是Resident Set Size的缩写,表示该进程所占物理内存的大小,是操作系统分配给Redis实例的内存大小。
used_memory_rss_human:以更直观的可读格式显示该进程所占物理内存的大小。
used_memory_peak:redis的内存消耗峰值(以字节为单位)
used_memory_peak_human:以更直观的可读格式显示返回redis的内存消耗峰值
used_memory_peak_perc:使用内存达到峰值内存的百分比,即(used_memory/ used_memory_peak) *100%
used_memory_overhead:Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog。
used_memory_startup:Redis服务器启动时消耗的内存
used_memory_dataset:数据占用的内存大小,即used_memory-used_memory_overhead
used_memory_dataset_perc:数据占用的内存大小的百分比,100%*(used_memory_dataset/(used_memory-used_memory_startup))
total_system_memory:整个系统内存
total_system_memory_human:以更直观的可读格式显示整个系统内存
used_memory_lua:Lua脚本存储占用的内存
used_memory_lua_human:以更直观的可读格式显示Lua脚本存储占用的内存
maxmemory:Redis实例的最大内存配置
maxmemory_human:以更直观的可读格式显示Redis实例的最大内存配置
maxmemory_policy:当达到maxmemory时的淘汰策略
mem_fragmentation_ratio:内存的碎片率,used_memory_rss/used_memory --4.0版本之后可以使用memory purge手动回收内存
mem_allocator:内存分配器
active_defrag_running:表示没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理)
lazyfree_pending_objects: 表示redis执行lazy free操作,在等待被实际回收内容的键个数
内存碎片率应该大于1小于1.5
内存碎片率超过1.5:重启redis服务器可以让额外产生的内存碎片失效并重新作为新内存来使用,使操作系统恢复高效的内存管理
内存碎片率低于1:应该增加可用物理内存或减少redis内存占用
修改内存分配
redis支持 libc、jemalloc11、tcmalloc三种不同的内存分配器,每个分配器 在内存分配和碎片上都有不同的实现
内存使用率
如果redis 实例的内存使用率超过可 用最大内存,那么操作系统开始进行内存与swap空间交换
1、针对缓存数据大小选择(如果缓存数据小于4GB,就使用32位的redis 实例)
2、使用Hash数据结构
3、设置key的过期时间
内存回收策略:LRU淘汰算法-Redis 从整个数据集中挑选最近最少使用的key进行删除
其他淘汰的策略:
volatile-lru:使用 LRU 算法从已设置过期时间的数据集合中淘汰数据
volatile-ttl:从已设置过期时间的数据集合中挑选即将过期的数据淘汰
volatile-random:从已设置过期时间的数据集合中随机挑选数据淘汰
allkeys-lru:使用 LRU 算法从所有数据集合中淘汰数据
allkeys-random:从数据集合中任意选择数据淘汰;
no-enviction:禁止淘汰数据(默认)
七、redis安全管理
存在的安全隐患:1.redis默认是没有密码用户名
2.redis允许任意地址连接,即bind 0.0.0.0
3.默认6379端口 没有开启认证
禁止使用root启动redis:为redis服务创建单独用户和相应的目录
开启redis密码
1.修改配置文件配置requirepass参数
echo "qwertyuiopasdfghjklzxcvbnm" | sha256sum
2.使用密码登陆redis(登录时-a选项加密码),登陆到redis上使用auth 进行密码验证
config get requirepass:查询密码
config set requirepass 密码字符串:设置密码
限制redis文件目录访问权限
设置redis的主目录权限为700;如果redis配置文件独立于redis主目录,权限修改为600,对配置文件设置特殊权限 文件权限除了r、w、x外还有s、t、i、a权限
配置监听地址
修改配置文件设置监听地址:vim /usr/local/redis/conf/redis.conf
bind 127.0.0.1 192.168.0.101
修改默认端口6379
修改配置文件设置端口号:vim /usr/local/redis/conf/redis.conf
port 8888
设置防火墙限制相关客户端登陆
禁用或重命名危险命令
redis数据库整库删除:清除当前数据库数据:FLUSHDB和清空所有库的数据库:FLUSHALL
修改配置文件:vim /usr/local/redis/conf/redis.conf
rename-command FLUSHDB zhangsan
监控:redis-cli工具
查看基础信息:info
查看客户端连接:127.0.0.1:6379> CLIENT LIST
踢出客户端连接:127.0.0.1:6379> CLIENT KILL 127.0.0.1:6380
显示key数量、内存、客户端数量、QPS情况:redis-cli --stat
查看redis延迟:redis-cli --latency
监控当前redis接受的命令和数据内容:redis-cli monitor(这个命令会比较消耗资源,根据官网的测试,QPS会下降到原先的50%,需要谨慎使用)
使用bigkeys查找占用空间较大的key:redis-cli --bigkeys
八、redis主从复制
redis主从复制原理
1.从服务器向主服务器发送SYNC命令
2.主服务器收到SYNC命令后,执行BGSAVE命令,在后台生成RDB文件,使用缓冲区记录从现在开始执行的所有的写命令
3.当主服务器的BGSAVE命令执行完毕后,主服务器后将BGSAVE命令生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE命令时的数据库状态
4.主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态
主从复制配置(这里以多实例演示)
从服务器登录redis执行命令:127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
或者配置配置文件添加下面
slaveof
启动服务:redis-server --slaveof
当master服务器出现故障之后需要手动把slave服务器变为master
执行命令:127.0.0.1:6380> slaveof no one
补充:要实现自动,就需要redis哨兵
九、redis哨兵
redis实现了Sentinel哨兵机制作用
监控(Monitoring):Sentinel会不断地检查你的主服务器和从服务器是否运作正常;
提醒(Notification):当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知;
自动故障迁移(Automatic failover):当一个主服务器不能正常工作时,Sentinel 会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器
配置redis哨兵服务器(这里以多实例演示)
编辑配置文件:vim /etc/redis/sentinel.conf
sentinel monitor mymaster 127.0.0.1 6379 1 \\指示Sentinel去监视一个被命名为 mymaster 的master,可指定为任何名字(配置文件中可以只写这一条)MasterIP为127.0.0.1,端口号为 6379
#这个master判断为失效至少需要 1 个 Sentinel 同意 (只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行),注意,无论你设置多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移
sentinel down-after-milliseconds mymaster 30000 \\指定了 Sentinel 认为master已经断线所需的毫秒数
down-after-milliseconds \\指定了 Sentinel 认为master已经断线所需的毫秒数
sentinel parallel-syncs mymaster 1 \\指定了在执行故障转移时, 最多可以有多少个slave同时对新的master进行同步, 这个数字越小, 完成故障转移所需的时间就越长
parallel-syncs \\指定了在执行故障转移时, 最多可以有多少个slave同时对新的master进行同步, 这个数字越小,完成故障转移所需的时间就越长
sentinel failover-timeout mymaster 180000 \\指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟
failover-timeout \\指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟启动sentinel:redis-sentinel /etc/redis/sentinel.conf
登录:redis-cli -p 26379
查看状态:127.0.0.1:26379> info sentinel
十、redis集群
注意:在创建集群之前需要先取消主从复制
1.创建6个实例,创建6个配置文件(6379.conf、6380.conf、6381.conf、6382.conf、6383.conf、6384.conf)
修改配置文件加入
cluster-enabled yes \\开启集群把注释#去掉
cluster-config-file nodes-6379.conf \\集群的配置
cluster-node-timeout 15000 \\设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换
appendonly yes \\//aof日志开启 有需要就开启,它会每次写操作都记录一条日志参照6379的配置文件修改port端口号还有pidfile文件位置参数
2.启动六个实例服务
redis-server /usr/local/redis/conf/6379.conf
redis-server /usr/local/redis/conf/6380.conf
redis-server /usr/local/redis/conf/6381.conf
redis-server /usr/local/redis/conf/6382.conf
redis-server /usr/local/redis/conf/6383.conf
redis-server /usr/local/redis/conf/6384.conf
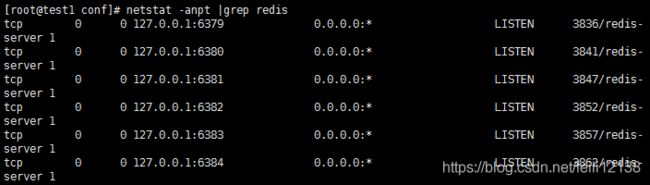
3.创建群集,redis提供了redis-trib.rb工具,在安装包里的src目录中,将该工具复制到/usr/local/bin/目录下就可以使用
cp redis-4.0.9/src/redis-trib.rb /usr/local/bin/
如果redis版本比较低,则需要安装ruby
yum -y install ruby ruby-devel rubygems rpm-build
安装redis集群接口:gem install redis
出现下图所示情况说明需要更高版本(在centos7.2中yum默认安装的ruby的版本是2.0.0,但此处需要更高版本)

yum -y install centos-release-scl-rh
会在/etc/yum.repos.d/目录下多出一个CentOS-SCLo-scl-rh.repo源
yum -y install rh-ruby23
scl enable rh-ruby23 bash(必须执行这一步)
查看安装版本:ruby -v
再次执行:gem install redis
创建群集:redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
--replicas 1:表示我们希望为集群中的每个主节点创建一个从节点
redis集群操作
登录集群:redis-cli -c -h 127.0.0.1 -p 6382 -a 123456
-c:使用集群方式登录
查看集群信息:127.0.0.1:6382> CLUSTER INFO
列出节点信息:127.0.0.1:6382> CLUSTER NODES
写入数据:127.0.0.1:6382> set key111 aaa
下图所示说明数据到了127.0.0.1:6381上

redis cluster集群是去中心化的,每个节点都是平等的,连接哪个节点都可以获取和设置数据,当然,平等指的是master节点,因为slave节点根本不提供服务,只是作为对应master节点的一个备份
cluster扩展(增加节点):
127.0.0.1:6382> CLUSTER MEET 127.0.0.1 6386
redis-cli -c -h 127.0.0.1 -p 6386 cluster replicate e51ab166bc0f33026887bcf8eba0dff3d5b0bf14
十一、php使用redis
安装php的redis扩展模块
1.下载安装phpredis-master
cd phpredis-master》phpize》./configure》make && make install
2.编辑php的配置文件添加模块:vim /usr/local/php/etc/php.ini
extension_dir = "/usr/local/php/lib/php/extensions/no-debug-zts-20090626"
extension=redis.so
3.进行php页面测试
connect('127.0.0.1',6379);
echo "连接redis成功";
echo "服务正在运行: " . $redis->ping();
?>十二、redis与mysql结合实现数据同步
mysql 同步到redis:解析mysql的binlog,然后做同步处理
redis读取速度快,也没有必要把所有的数据都放到redis里面,redis里面只放使用频繁,用户操作量较大的数据,或者用户近期使用的数据
解决方法:
1:读取数据的时候先从redis里面查,若没有,再去数据库查,同时写到redis里面,并且要设置失效时间
2:利用mysql的UDF,通过数据库的触发器调用UDF,来触发对redis的相应操作
3.通过mysql UDF,将mysql数据先放入Gearman中,然后通过php,将数据同步到redis
4.通过Open Replicator(Open Replicator是一个用Java编写的MySql binlog分析程序)首先连接到MySql,然后接收和分析binlog,根据binlog的分析结果进行缓存操作
5.通过CanalCanal解析binlog(主要是基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,核心基本就是模拟MySql中Slave节点请求)