C++之继承
目录
继承的概念及定义
继承的概念
继承定义
定义格式
继承方式
继承基类成员访问方式的变化
基类和派生类对象赋值转换(切片/切割)
继承中的作用域
派生类的默认成员函数
构造函数和析构函数
拷贝构造函数和赋值重载
继承和友元
继承与静态成员
菱形继承及菱形虚拟继承
菱形继承
继承和组合
继承的概念及定义
继承的概念
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,继承是类设计层次的复用。
这就比如我们设计一个学生管理系统,学校中有老师,学生,工作人员等,我们要记录他们的信息比如学生有电话,姓名,地址,学号等这些信息。
class Student
{
string _name;
string _tel;
string _add;
int _stuNo;
}比如教师有电话,姓名,地址,工号这些信息。
class Teacher
{
string _name;
string _tel;
string _add;
int _workNo;
}这样设计后我们会发现会有很多的重复信息,那么我们可以把重复的信息提取出来,重新建立一个Person类。
class Person
{
string _name;
string _tel;
string _add;
}那么我们的学生类和教师类就可以复用Person类
class Student
{
Person p;
int _stuNo;
}
class Teacher
{
Person p;
int _workNo;
}这里的_stuNo和_workNo则是学生类和教师类自己独有的变量。
下面是完整版的继承方式:
#include
using namespace std;
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
protected:
string _name = "Tom"; // 姓名
int _age = 22; // 年龄
};
//这里的Student类和Teacher类继承了Person类,那么Student就享有了Person中的成员
//Person类叫为基类或父类
//Student类和Teacher类为派生类或子类
class Student : public Person
{
protected:
int _stuNo; // 学号
};
class Teacher :public Person
{
protected:
int _workNo;//工号
};
int main()
{
Student s;
Teacher t;
s.Print();
t.Print();
return 0;
} 
在继承后父类Person的成员(成员函数与成员变量)都会变成子类的一部分,这里就体现出Student和Teacher复用了Person类,我们可以通过调试的监视窗口看到继承关系和调用父类成员。
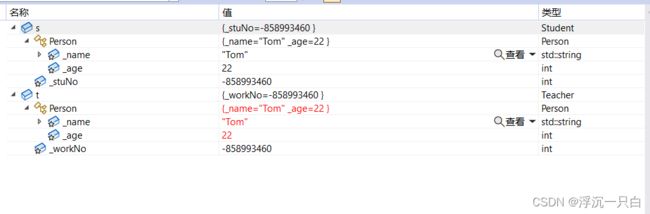
继承定义
定义格式
这里的Person为基类/父类,Student和Teacher为派生类/子类,public则为继承方式。

继承方式

上图为继承关系和访问限定符
继承基类成员访问方式的变化
在继承当中,基类成员的访问方式有三种,权限设定大小为:public>protected>private
| 类成员/继承方式 | public继承 | protected继承 | private继承 |
|---|---|---|---|
| 基类的public成员 | 派生类的public成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的protected成员 | 派生类的protecte成员 | 派生类的protected成员 | 派生类的private成员 |
| 基类的private成员 | 在派生类不可见 | 在派生类不可见 | 在派生类不可见 |
通过此表格我们可以知道基类给派生类的访问方式为,min(访问方式,继承方式),派生类的访问方式会变为基类的访问方式和继承方式取权限最小的那个。
代码辅助理解为:
#include
using namespace std;
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
protected:
string _name = "Tom"; // 姓名
private:
int _age = 22; // 年龄
};
class Student : public Person
{
void fun()
{
Print();
_name = "王五";
_age = 20;
}
protected:
int _stuNo; // 学号
};
int main()
{
Student s;
return 0;
} 我们将Person类中的_age设置为私有成员,再通过继承Person的Student来修改_age的值,因为继承方式为public,所以基类的私有成员是不可以被访问的,所以我们修改私有成员会报错。
![]()
C++的继承方式有三种,实际上最常使用的为public和继承方式,而基类的访问限定符设置最多的为public和protected。
总结
- 基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
- 如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
- class的默认继承方式为public,而struct的默认继承方式为public
- 实际应用多为public继承
基类和派生类对象赋值转换(切片/切割)
我们先定义基类和派生类
class Person
{
public:
string name;
string add;
int age;
};
class Student :public Person
{
private:
string No;
};
int main()
{
Person p;
Student s;
p = s;//子类对象赋值给父类对象
return 0;
}有以上可知我们可以把派生类的对象赋值给基类,派生类赋值给基类的过程我们称其为切片或切割,但注意的是基类对象不能赋值给派生类对象。
我们还可以赋值给基类的指针、基类的引用。
Person *pr = &s;pr只指向父类这一部分的成员
Person& prf = s;prf时父类部分的别名
继承中的作用域
在继承体系中基类和派生类都有独立的作用域,子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义,但我们可以在子类中通过父类::父类成员显示访问。如果是成员函数的隐藏,只要函数名相同就会隐藏。我们需要注意的是在继承体系中最好不要定义同名成员。
我们来看一下代码辅助分析:
class Person
{
protected:
string name = "张三";
int num = 250;
};
class Student :public Person
{
public:
void Print()
{
cout << "姓名:" << name << endl;
cout << "身份ID:" <我们来运行后会发现什么呢?

我们可以看到父类和子类的成员名字相同,那么我们在打印成员num时则都会显示子类里成员变量的值,因为在子类作用域中所以会首先访问自类成员,就如同我们定义了零时变量和全局变量,当他们同名时,我们会首先访问局部变量,所以当子类和父类成员同名时,子类成员会隐藏父类成员,也叫重定义。
那么我们如果想要打印父类的成员num应该怎么办呢?那么我们应该指定类域:
cout << "身份ID:" <
我们可以看到这样就可以打印父类里的同名成员。
我们来看这一段代码:
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
void fun(int i)
{
cout << "func(int i)->" << i << endl;
}
};
int main()
{
B b;
b.fun(10);
b.A::fun();
return 0;
}
我们可以看到A和B的成员函数名字是一样的,这里同样构成了上述的隐藏,要想访问父类的成员函数需要指定类域。
这里如果设置选择题b.fun(10),b.fun()时,我们大多数人都会认为构成了函数重载,但是我们要知道构成重载需要同一作用域,所以这里的fun()构成了隐藏。
派生类的默认成员函数
派生类的默认成员函数有6个,有负责初始化和清理的构造函数和析构函数,负责拷贝复制的拷贝构造函数和赋值重载,还有负责取地址重载的普通对象取地址和const对象取地址,但最后两个我们很少自己实现。
构造函数和析构函数
首先我们来看构造函数和析构函数如何实现:
我们都知道构造一个类后,没有写构造函数和析构函数,编译器会自动生成一个默认成员函数,那当我们创建子类时会是怎样的情形?
class Person
{
public:
Person(const char* name = "peter")
: _name(name)
{
cout << "Person()" << endl;
}
~Person()
{
cout << "~Person()" << endl;
}
protected:
string _name; // 姓名
};
class Student : public Person
{
public:
protected:
int _num; //学号
string str;
};
int main()
{
Student s;
return 0;
}![]()
我们会发现我们的子类中并没有写构造函数和析构函数时,对于父类继承下来的部分,我们的子类会调用父类的默认构造函数和析构函数,正如上述代码所示,而对于自己的内置类型和自定义类型来说,则像普通类一样内置类型不处理,自定义类型调用默认构造函数。
当父类没有默认构造函数,自类有资源需要释放,子类有浅拷贝问题,我们就需要自己实现构造函数和析构函数了,那么如果要我们自己实现该如何实现呢?
当我们构造时,父类调用对应的构造函数,自己的成员则按照自己需求处理。
Student(const char* name="王五",int num=100)
:Person(name)
,_num(num)
{
cout << "Student()" << endl;
}
我们可以看到先调用了父类的构造函数,在调用了子类自身的构造函数。
对于析构函数如果我们自己实现时:
~Student()
{
~Person;
}这样的写法是错误的,因为编译器对析构函数名会做特殊处理,所有类名会被统一成一样的,所以会报错。
我们正确写法应该是指定类域,Person::~Person(),从而释放子类的资源。
![]()
我们发现这里调用了两次析构函数,为什么呢?因为子类的析构函数会在执行之后调用父类的析构函数。这里如同栈的原理,先构造的后释放,所以构造时会先调用父类的构造函数,再构造子类,所以析构时会先析构子类,再析构父类,这样才能符合规则,所以我们不需要显式调用父类的析构函数,编译器会去自动调用。
拷贝构造函数和赋值重载
那么拷贝构造和赋值重载是怎样的呢?
与构造与析构相同,我们在调用拷贝构造和重载时,对于继承父类部分我们会调用父类的拷贝构造和赋值重载,而对于内置类型和自定义类型来说则与普通类一样,拷贝构造会调用浅拷贝,而自定义类类型会调用自身的拷贝。
int main()
{
Student s1;
Student s2(s1);
return 0;
}
如果子类存在浅拷贝问题,就需要自己实现拷贝构造和赋值解决浅拷贝,那么我们又该如何实现拷贝构造和赋值呢?
Student(const Student& s)
:Person(s)
,_num(s._num)
{}我们这里实现的是子类的拷贝构造函数,我们自身的内置类型直接传值拷贝即可,而对于父类的部分我们需要运用到切片,将子类的 父类部分直接切片至新的子类的父类部分。
Student& operator=(const Student& s)
{
if (this != &s)
{
Person::operator=(s);//我们需要指定为父类作用域
_num = s._num;
}
return *this;
}我们这里实现的是子类的赋值重载,与拷贝构造原理相同,我们可以直接将内置类型赋值过去,对于子类的父类部分,则调用父类的赋值重载运用切片将其赋值给新的子类的父类部分。
我们这里需要特别注意的是由于operator=是在子类的作用域中,而我们希望调用的是父类的operator=,所以这里我们需要特别指定为父类的作用域。
继承和友元
class Person
{
public:
friend void Display(const Person& p, const Student& s);
protected:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _num; // 学号
};
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;
cout << s._num << endl;
}
void main()
{
Person p;
Student s;
Display(p, s);
}这里的Print()函数是父类的友元函数,但是友元是不能够继承的,也说明父类的友元无法访问子类的私有和保护成员。
继承与静态成员
我们在父类定义了stactic静态成员,那么在整个继承体系只有这一个成员。无论派生出多少子类最终只有这一个static成员实例。
我们可以通过代码来统计static成员的变化情况:
class Person
{
public:
Person() { ++_count; }
protected:
string _name; // 姓名
public:
static int _count; // 统计人的个数。
};
int Person::_count = 0;
class Student : public Person
{
protected:
int _num; // 学号
};
class Graduate : public Student
{
protected:
string _course; // 科目
};
int main()
{
Student s1;
Student s2;
Graduate s3;
cout << " 人数 :" << Person::_count << endl;
Student::_count = 0;
cout << " 人数 :" << Person::_count << endl;
return 0;
}
我们可以从代码看出static成员在整个继承体系只有一个这样的成员。
菱形继承及菱形虚拟继承
菱形继承
谈到菱形继承,首先我们要先知道什么是单继承和多继承:
单继承:一个子类只有一个直接父类父类时称这个继承关系为单继承。

多继承:一个子类有两个或两个以上直接父类时称这个继承关系称为多继承。

那么菱形继承则为:(一种多继承的特殊表达)

通过图片的分析,我们可以看出菱形继承拥有的问题:Assitant会有两个Person类的数据,这样会导致数据的冗余性和二义性。
class Person
{
public:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _num; //学号
};
class Teacher : public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _Course; // 课程
};
void Test()
{
// 这样会出现二义性无法明确知道访问的是哪一个
Assistant a;
a._name = "peter";
a.Student::_name = "Tom";
a.Teacher::_name = "Jack";
}如上代码为一个菱形继承,当我们使用子类Assistant来访问Person类的成员,这样会导致编译器不知道访问Student类和Teacher类哪个Person类中的成员。
![]()
但是我们可以通过指定访问谁的父类来解决二义性:
a.Student::_name = "Tom";
a.Teacher::_name = "Jack";

但这样只是解决了二义性,为了解决冗余性,则出现了菱形虚拟继承:
class Person
{
public:
string _name; // 姓名
};
class Student : virtual public Person
{
protected:
int _num; //学号
};
class Teacher : virtual public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _Course; // 课程
};
int main()
{
Assistant a;
a.Student::_name = "Tom";
a.Teacher::_name = "Jack";
a._name = "peter";
return 0;
}
在这里虚拟机称virtual很好的解决了冗余性和二义性,我们可以从监视窗口看出三个类的name都是一样的,但这其实是编译器优化以后的结果。那么我们想要更好的了解菱形虚拟继承,我们可以从内存监视窗口来观察,所以我们代码如下:
class A
{
public:
int _a;
};
class B : public A
{
public:
int _b;
};
class C : public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
int main()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
}

当我们建立一个D类的菱形继承时,我们可以看出红色框为B类的b和a值的地址,处于紧邻的位置,同理橘色框的C类也如此。那么我们来看看菱形虚拟继承是怎么样的呢?
int main()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
d._a = 0;
return 0;
}
当我们调试时会发现:
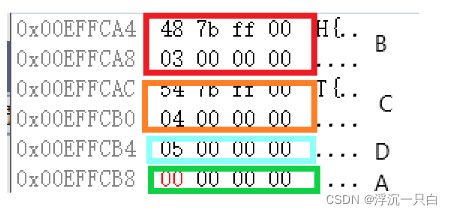
B类的a值并未像菱形继承一样放于属于B类的位置,我们通过后续的调试会发现B,C,D类的a值都会处于这个共同位置,说明我们修改的a是只有一份的,而且我们通过仔细观察B类众多了48 7b ff 00这个内容,C类多了54 7b ff 00的内容,我们来打开内存监视来观察一下。

我么们可以看到内存的下一个位置是14,而内存以16进制存储,所以十进制下是20,那么我们来看一下下一个是怎样的。

我们可以看到代表C类的下一内存位置是0c,十进制下是12。
实际上这两个数据代表着B类和C类到a值的位置的内存大小,叫做偏移量。那么为什么要在这里存储偏移量呢?这里我们要提到切片,B b = d;切片是将d对象中的父类B的部分赋值给b,B类的部分有_a成员,那么怎么找到这个B类的_a成员呢?此时就需要用偏移量去找。只有虚基类B和C需要用偏移量去找_a,其他都是正常去找。
int main()
{
D d;
B b = d;
b._a = 1;
b._b = 2;
return 0;
}当我们通过观察汇编可以发现:

我们可以发现虚基类B访问_a成员需要三行,我们可以发现它去寻找_a是需要通过偏移量的,而直接访问自身的成员_b是不需要的。
我们可以看出设置了虚拟继承后可以解决菱形继承的问题,虚基类的对象、指针、引用可以通过偏移量去访问父类的成员。但需要注意的是一般情况下不建议设计出菱形继承,我们还是要避免这样的情况。
继承和组合
class A
{
public:
void func(){}
protected:
int _a;
};
//B继承了A,可以复用A
class B : public A
{
protected:
int _b;
};
//C组合A,可以复用A
class C
{
private:
int _c;
A _a;
};
A和B的关系是继承关系,B作为子类继承了父类A,而A和C的关系是组合,C调用了A。这里的public继承实际上是一种is_a关系,继承了基类以后成为了一个基类的对象,而组合则是has_a的关系,是C类中有了A类。这里的B类继承了A类,可以说这是一种白箱复用,因为A类对于B类是一种透明状态的,B类可以去访问A类的公有与私有成员,那么它们的关联度会很高,(A的改变会牵连B,A的封装对B是不起作用的),而C组合了A,这种的复用情况,可以说是一种黑箱复用,A对C的影响不大,C只可以访问A的公有成员,A和C的关联度低。
所以我们可以知道的是B和A强关联关系,而C和A低关联关系。
软件设计类之间关系或者模块间强调:
通过上述的讲解,我们可以知道的的是不同的复用手法会导致的关系是不同的,我们学过软件工程可以知道工程的设计要求是,高内聚(类里面的成员之间关联度很高),低耦合(类和类之间关联度很低),在开发工程时,多人协作完成多个模块时,那么每个人之间的模块就应该关联度低一些,对于自己的模块则应该关联度好一些,否则就会互相影响。
我们要注意的是,我们要去清楚类与类之间时is_a还是has_a关系,然后再去决定使用继承还是组合。