GPU-CUDA编程学习(四)-共享内存
Shared memory
共享内存在芯片上可用,因此它比全局内存快得多。共享内存延迟大约比未调用的全局内存延迟低100倍。来自同一块的所有线程都可以访问共享内存。这在许多需要与其他线程共享结果的应用程序中非常有用。但是,如果没有同步,也会产生混乱或错误的结果。如果一个线程在其他线程写入数据之前从内存中读取数据,那么可能会导致错误的结果。因此,应该适当地控制或管理内存访问。这是由剩余的**syncthreads()**指令完成的,该指令确保在程序继续执行之前,对内存的所有写操作都已完成。这也叫做阻塞。阻塞的意思是所有线程都将到达这一行并等待其他线程完成。在所有线程都达到这个阻塞之后,它们可以进一步移动。为了演示共享内存和线程同步的使用,本文给出了一个移动平均的示例。其核函数如下:
#include 移动平均操作只是找到一个数组中直到当前元素的所有元素的平均值。许多线程的计算都需要相同的数组数据。这是使用共享内存的理想情况,它将比全局内存提供更快的数据。这将减少每个线程的全局内存访问次数,从而减少程序的延迟。共享内存的位置是用__shared__指令定义的。在本例中,定义了十个浮点数元素的共享内存。通常,共享内存的大小应该等于每个块的线程数。在这里,我们处理的是数组长度10,因此我们获得了这个大小的共享内存。下一步是将数据从全局内存复制到这个共享内存。所有线程都将按其线程ID索引的元素复制到共享数组中。现在,这是一个共享内存的写操作,在下一行中,我们将从这个共享数组中读取。因此,在继续之前,我们应该确保所有共享内存写操作都已完成。因此,让我们引入**__synchronizethreads()**阻塞。
接下来,for循环使用共享内存中的值计算到当前元素的所有元素的平均值,并将结果存储在由当前线程ID索引的全局内存中。现在,我们将尝试为这段代码编写如下的main函数:
int main(int argc, char **argv)
{
float h_a[10];
float *d_a;
//Initialize host Array
for (int i = 0; i < 10; i++)
{
h_a[i] = i;
}
// allocate global memory on the device
cudaMalloc((void **)&d_a, sizeof(float) * 10);
// copy data from host memory to device memory
cudaMemcpy((void *)d_a, (void *)h_a, sizeof(float) * 10, cudaMemcpyHostToDevice);
gpu_shared_memory << <1, 10 >> >(d_a);
// copy the modified array back to the host
cudaMemcpy((void *)h_a, (void *)d_a, sizeof(float) * 10, cudaMemcpyDeviceToHost);
printf("Use of Shared Memory on GPU: \n");
for (int i = 0; i < 10; i++)
{
printf("The running average after %d element is %f \n", i, h_a[i]);
}
return 0;
}
在主函数中,为主机数组和设备数组分配内存后,主机阵列被从0到9的值填充。它被复制到设备内存中,在那里计算移动平均并存储结果。来自设备内存的结果被复制回主机内存,然后打印在控制台上。控制台输出如下: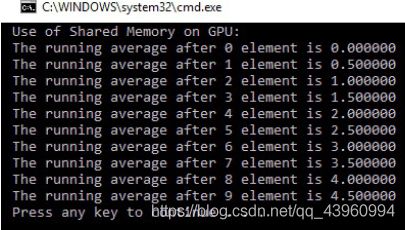
本节演示了当多个线程使用来自相同内存位置的数据时共享内存的使用。接下来演示原子操作的使用,它们在读修改写操作中非常重要。
Atomic operations
考虑这样一种情况:大量线程试图修改一小部分内存。这是一种经常发生的现象。当我们尝试执行一个读-修改-写操作时,它会产生更多的问题。该操作的示例是d_out[i] ++,其中从内存中读取第一个d_out[i],然后递增,然后写回内存。但是,当多个线程在同一内存位置上执行此操作时,可能会给出错误的输出。假设一个内存位置的初始值为6,并且线程p和q试图增加这个内存位置,那么最终的答案应该是8。但是在执行时,p线程和q线程可能同时读取这个值,然后两个线程都将得到值6。它们将其增量为7,并且都将这个7存储在内存中。所以不是8,我们最终的答案是7,这是错的。
以ATM取现金为例,就可以理解这有多危险。假设你的账户上有5000英镑。你有同一账户的两张提款卡。你和你的朋友同时去两台不同的自动取款机取4000英镑。两人同时刷卡;因此,当自动取款机检查余额时,两者都会显示余额为5000英镑。
当你们两个都取4000英镑时,两台机器都会查看初始余额,即5000英镑。取钱的金额少于余额,因此两台机器都能取4000英镑。即使你的余额是5000英镑,你得到了8000英镑,这很危险。为了演示这一现象,我们举了一个大线程试图访问小数组的例子。本例的核函数如下:
include <stdio.h>
#define NUM_THREADS 10000
#define SIZE 10
#define BLOCK_WIDTH 100
__global__ void gpu_increment_without_atomic(int *d_a)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// Each thread increment elements which wraps at SIZE
tid = tid % SIZE;
d_a[tid] += 1;
}
内核函数只是递增d_a[tid] +=1行的内存位置。问题是这个内存位置增加了多少次。线程总数为10,000个,数组的大小仅为10。我们通过在线程ID和数组大小之间进行模操作来为数组建立索引。因此,1000个线程将在同一位置增加。理想情况下,数组中的每个位置都应该增加1000次。但正如我们将在输出中看到的,情况并非如此。在看到输出之前,我们先试着写main函数:
int main(int argc, char **argv)
{
printf("%d total threads in %d blocks writing into %d array elements\n",
NUM_THREADS, NUM_THREADS / BLOCK_WIDTH, SIZE);
// declare and allocate host memory
int h_a[SIZE];
const int ARRAY_BYTES = SIZE * sizeof(int);
// declare and allocate GPU memory
int * d_a;
cudaMalloc((void **)&d_a, ARRAY_BYTES);
// Initialize GPU memory with zero value.
cudaMemset((void *)d_a, 0, ARRAY_BYTES);
gpu_increment_without_atomic << <NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH >> >(d_a);
// copy back the array of sums from GPU and print
cudaMemcpy(h_a, d_a, ARRAY_BYTES, cudaMemcpyDeviceToHost);
printf("Number of times a particular Array index has been incremented without atomic add is: \n");
for (int i = 0; i < SIZE; i++)
{
printf("index: %d --> %d times\n ", i, h_a[i]);
}
cudaFree(d_a);
return 0;
}
在主函数中,设备数组被声明并初始化为零。这里,一个特殊的cudaMemSet函数用于初始化设备上的内存。它作为参数传递给内核,内核会增加这10个内存位置。在这里,总共有10,000个线程被启动为1,000个块,每个块有100个线程。内核执行后存储在设备上的答案被复制回主机,每个内存位置的值显示在控制台上。输出如下: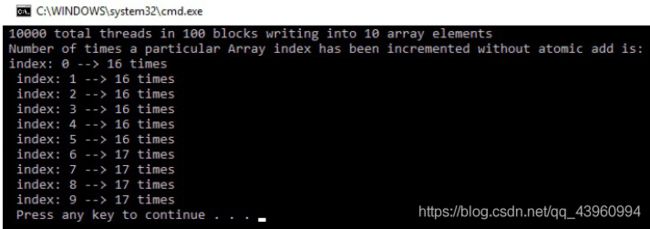
如前所述,理想情况下,每个内存位置应该增加1,000次,但是大多数内存位置的值为16和17。这是因为许多线程同时读取相同的位置,因此增加相同的值并将其存储在内存中。由于线程执行的时间超出了程序员的控制,因此并发内存访问的次数是不知道的。如果您第二次运行您的程序,那么您的输出是否与第一次相同?您的输出可能如下所示: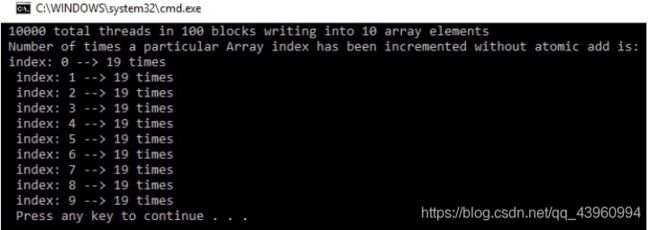
正如你可能已经猜到的,每次运行程序时,内存位置可能有不同的值。这是因为设备上的所有线程都是随机执行的。
为了解决这个问题,CUDA提供了一个名为atomicAdd 操作的API。它是一个阻塞操作,这意味着当多个线程试图访问相同的内存位置时,一次只能有一个线程访问该内存位置。其他线程必须等待这个线程完成并在内存中写入它的答案。使用atomicAdd操作的内核函数如下所示:
#include 核函数与我们之前看到的非常相似。使用atomicAdd函数,而不是使用**+=**操作符递增内存位置。它有两个参数。第一个是我们想要增加的内存位置,第二个是这个位置必须增加的值。在这段代码中,1000个线程将再次尝试访问相同的位置;因此,当一个线程使用这个位置时,其他999个线程必须等待。这将增加执行时间方面的成本。使用原子操作的增量的主要功能如下所示:
int main(int argc, char **argv)
{
printf("%d total threads in %d blocks writing into %d array elements\n",NUM_THREADS, NUM_THREADS / // declare and allocate host memory
int h_a[SIZE];
const int ARRAY_BYTES = SIZE * sizeof(int);
// declare and allocate GPU memory
int * d_a;
cudaMalloc((void **)&d_a, ARRAY_BYTES);
// Initialize GPU memory withzero value
cudaMemset((void *)d_a, 0, ARRAY_BYTES);
gpu_increment_atomic << <NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH >> >(d_a);
// copy back the array from GPU and print
cudaMemcpy(h_a, d_a, ARRAY_BYTES, cudaMemcpyDeviceToHost);
printf("Number of times a particular Array index has been incremented is: \n");
for (int i = 0; i < SIZE; i++)
{
printf("index: %d --> %d times\n ", i, h_a[i]);
}
cudaFree(d_a);
return 0;
}
在main函数中,包含10个元素的数组被初始化为零值并传递给内核。但是现在,内核将执行原子添加操作。所以,这个程序的输出应该是准确的。数组中的每个元素应该增加1000次。下面是输出:

如果您使用原子操作来度量程序的执行时间,它所花费的时间可能比使用全局内存的简单程序所花费的时间更长。这是因为许多线程在原子操作中等待内存访问。使用共享内存可以帮助加速操作。另外,如果相同数量的线程访问更多的内存位置,那么原子操作将导致更少的时间开销,因为等待内存访问的线程更少。
这里举一个图像操作中常用的统计直方图的例子:
我们将从CPU上计算直方图开始,以便您可以了解如何计算直方图。假设数据中有1,000个元素,每个元素的值在0到15之间。我们要计算这个分布的直方图。在CPU上进行计算的示例代码如下:
int h_a[1000] = Random values between 0 and 15
int histogram[16];
for (int i = 0; i<16; i++)
{
histogram[i] = 0;
} for (
i=0; i
<
1000; i++)
{
histogram[h_a[i]] +=1;
}
我们有1,000个数据元素,它们存储在h_a中。h_a数组包含0到15之间的值;它有16个不同的值。
现在,我们将为GPU开发相同的代码。我们将尝试使用三种不同的方法来开发此代码。前两种方法的内核代码如下:
#include 第一个函数是直方图计算中最简单的核函数。每个线程操作一个数据元素。使用线程ID作为输入数组的索引来获取数据元素的值。这个值用作d_b输出数组的索引,该数组递增。d_b数组应该包含输入数据中0到15之间每个值的频率。但是如果你回想上边讲的内容,这可能不会给你一个正确的答案,因为许多线程试图同时修改相同的内存位置。在本例中,1,000个线程试图同时修改16个内存位置。对于这种场景,我们需要使用原子添加操作。第二个设备函数是使用原子添加操作开发的。这个内核函数将给您正确的答案,但它将花费更多的时间来完成,因为原子操作是一个阻塞操作。当一个线程正在使用一个特定的内存位置时,所有其他线程都必须等待。因此,第二个内核函数将增加开销时间,这使得它甚至比CPU版本更慢。为了完成代码,我们试着为它编写如下的主函数:
int main()
{
int h_a[SIZE];
for (int i = 0; i < SIZE; i++) {
h_a[i] = i % NUM_BIN;
}
int h_b[NUM_BIN];
for (int i = 0; i < NUM_BIN; i++) {
h_b[i] = 0;
}
int * d_a;
int * d_b;
// allocate GPU memory
cudaMalloc((void **)&d_a, SIZE * sizeof(int));
cudaMalloc((void **)&d_b, NUM_BIN * sizeof(int));
// transfer the arrays to the GPU
cudaMemcpy(d_a, h_a, SIZE * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, NUM_BIN * sizeof(int), cudaMemcpyHostToDevice);
// launch the kernel
//histogram_without_atomic << <((SIZE+NUM_BIN-1) / NUM_BIN), NUM_BIN >> >(d_b, d_a);
histogram_atomic << <((SIZE+NUM_BIN-1) / NUM_BIN), NUM_BIN >> >(d_b, d_a);
// copy back the sum from GPU
cudaMemcpy(h_b, d_b, NUM_BIN * sizeof(int), cudaMemcpyDeviceToHost);
printf("Histogram using 16 bin without shared Memory is: \n");
for (int i = 0; i < NUM_BIN; i++) {
printf("bin %d: count %d\n", i, h_b[i]);
}
// free GPU memory allocation
cudaFree(d_a);
cudaFree(d_b);
return 0;
}
// declare GPU memory pointers
输出如下:
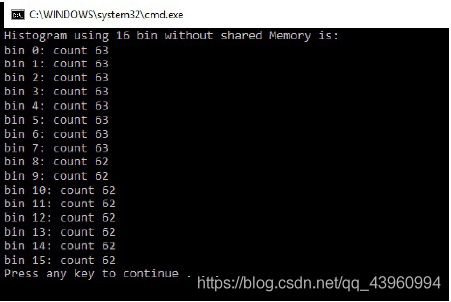
当我们尝试使用原子操作度量这段代码的性能并将其与CPU性能进行比较时,它比大型数组的CPU性能要慢。这就引出了一个问题:我们使用CUDA来进行直方图计算,有可能使计算速度更快吗?
这个问题的答案是:是的。如果我们使用共享内存来计算给定块的直方图,然后将这个块直方图添加到全局内存的总体直方图中,那么它可以加快操作速度。这是可能的,因为加法是一个累积操作。使用共享内存的内核代码:
#include 在本例中,只有256个线程尝试访问共享内存中的256个内存元素,而不是前面代码中的1,000个元素。这将有助于减少原子操作的时间开销。最后一行中的最后一个原子添加操作将把一个块的直方图添加到总体直方图值中。
因为加法是一个累积操作,所以我们不必担心每个块的执行顺序。
如果你测量之前的程序的性能,它将击败没有共享内存的GPU版本和大数组的CPU实现。你可以通过比较GPU计算的直方图和CPU计算的结果来检查GPU计算的直方图是否正确。