大数据技术及应用—Hadoop 基础 笔记
Hadoop采用分布式存储和并行执行机制,为整个数据群带来了非常高的宽带,因此能大大提高效率。Hadoop事实上是用大量的廉价机器组成的集群去执行大规模运算,这包括大规模的计算和大规模的存储。
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力,几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务。是具有可靠性和扩展性的一个开源分布式计算的存储系统,它为用户提供了一个透明的生态系统,用户在不了解分布式底层细节的情况下,可开发分布式应用程序,充分利用集群的威力进行数据的高速运算和存储。
Hadoop是基于Java语言开发的,具有很好的跨平台特性。
Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed FileSystem)和MapReduce。HDFS(Hadoop分布式系统)可实现大数据的存储,MapReduce可实现大数据复杂度计算。
hadoop是能为大量数据进行分布式处理的软件框架。
Hadoop的特点:
高可靠性:主要体现在Hadoop能自动维护多个工作数据副本,并且在任务失败后能自动的重新部署计算任务,因为Hadoop采用的是分布式架构,因即使有一台服务器硬件坏掉,HDFS仍能正常运转,因为数据库还有另外的副本。
高效性:主要体现在Hadoop以并行的方式处理大规模数据,而且能够在节点之间,动态的移动数据,并保证各节点的动态平衡,从而加快了处理速度 。
成本低:主要体现在集群可以由廉价的服务器组成,由此这个集群可以方便地组成数以千计的节点,只要一般等级的服务器就可搭建出高性能、高容量的集群。
高可扩展性:主要体现在Hadoop采用分布式计算与存储,其高可扩展性主要体现在,可以通过添加节点或者集群、使得性能和容量得到提升。
支持多种编程语言:Hadoop支持多种编程语言。提供了Java以及C/C++等编程作业方式。
Hadoop组件由规下层的Hadoop核心构件以及上层的Hadoop生态系统共同集成,而上层的生态系统都是基于下层的存储和计算来完成的,如下图所示。

Hadoop的各类组件功能都不相同,它们之间相互提供了互补性的服务。从而形成了一个处理大数据的生态系统。根据Hadoop发行版本,目前Hadoop生态系统,大体可分为两类:Hadoop1.0生态系统和Hadoop2.0生态系统。
Hadoop1.0生态系统
Hadoop1.0生态系统主要是指Hadoop1.X及其以前的版本,并包含很多相关子系统的完整的大数据处理生态系统,如图所示。
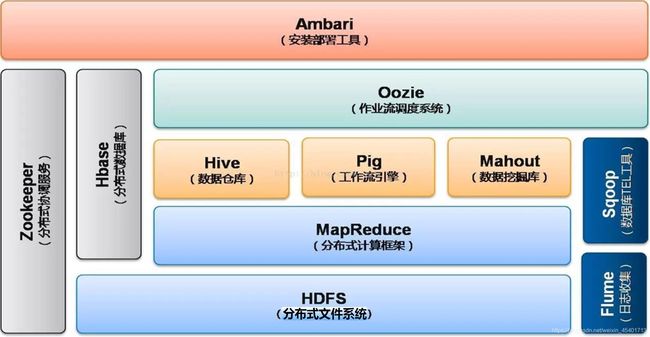
Hadoop2.0生态系统
Hadoop2.0生态系统主要是指Hadoop2.X及其以后的版本,并包含很多相关子系统的完整的大数据处理生态系统,如图所示。
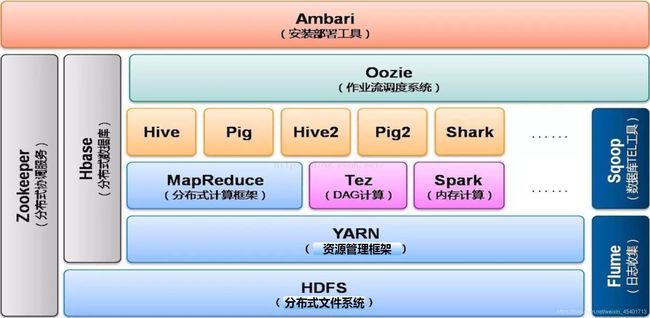
Hadoop2.0生态系统与Hadoop1.0生态系统相比,增加了多个组件,其中YARN、Spark大大提升了Hadoop较前版本的功能。
Hadoop1.0只支持单一的计算模型MapReduce,Hadoop2.0加入Yarn资源调度器,可以支持多种类型的计算模型,Yarn同时可以给不同的计算任务进行计算资源的分配。
Spark(基于内存的并行计算框架)
YARN(资源管理框架)
Tez(DAG计算框架)
Shark(数据分析处理)
Hadoop系统核架构是由HDFS、MapReduce和Spark核心组件组成,如下图所示。
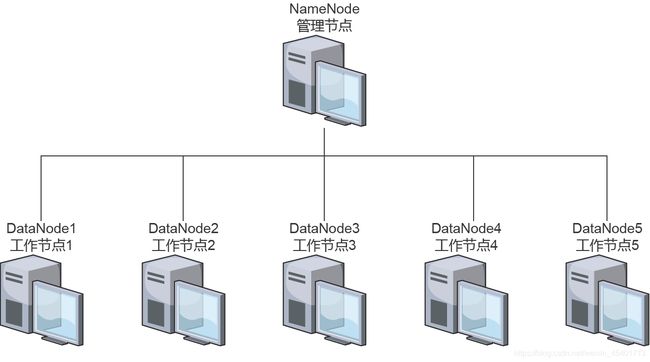
HDFS采用了主从架构,一个集群,有一个NameNode和多个DataNode,一台计算机
可以运行多个DateNode节点,但是在实际应用中,往往一台计算机只运行一个
DataNode,如下图所示。
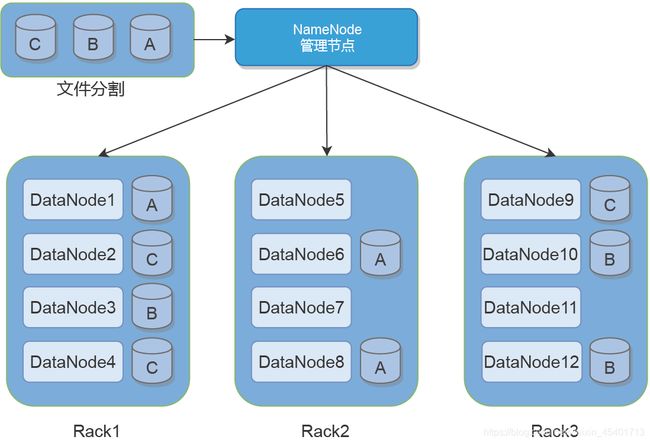
在HDFS中,一个文件通常被分割成若干个块(Block),存储在一组DataNode上,同时建立Block和DataNode之间的映射,如下图所示。
MapReduce是Google公司2004年提出的,能并发处理海量数据的并行编程模型,其特点是简单易学,是一个适用广泛,能够降低并行编程难度,让程序员从繁杂的,并行编程工作中解脱出来,轻松地编写简单高效的并行程序。
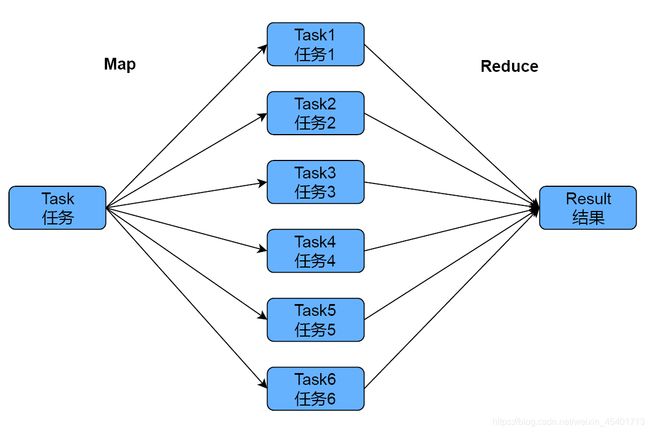
MapReduce将复杂且运行在大规模集群上的并行计算过程抽象到Map和Reduce两个函数。Map和Reduce处理数据的主要思想是将待处理数据分解成许多小的数据集,由每台服务器分别运行,所有小的数据集可以完全并行地进行计算,如下图所示。
Hadoop的job client提交作业和配置信息给ResourceManager,ResourceManager负责分发这些软件和配置信息给slave节点调度任务,并且监控这些slave节点的执行过程,将状态和诊断信息反馈给job client。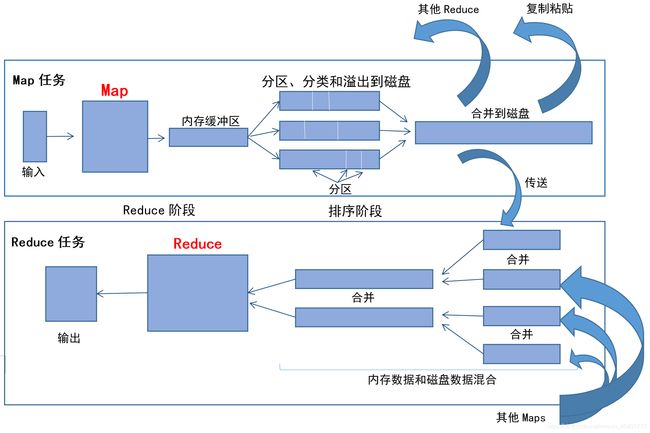
MapReducer 2.0是运行于资源管理框架YARN之上的计算框架。
MapReducer 2.0的运行时环境不再由JobTracker和TaskTracker等服务组成,而是变为通用资源管理系统YARN和作业控制进程ApplicationMaster,其中YARN负责资源管理的调度,ApplicationMaster负责作业的管理。
大数据使用的资源大多是一个共用集群资源,资源使用过程中就需要进行资源控制, YARN主要作用是强化控制和使用资源管理功能。YARN架构如图所示。
YARN主要作用是强化控制和使用资源管理功能。YARN架构如图所示。
MapReduce的计算框架,在数据运算时,Hadoop需要将中间产生运算结果存储在硬盘中,如下图所示。
***Spark***在借鉴 MapReduce优点的同时,很好地解决了MapReduce中的诸多性能缺陷。它是一个可应用于大规模数据处理的快速、通用引擎,如今是 Apache软件基金会下的顶级开源项目之一。基于DAG的任务调度执行机制,优于MapReduce的迭代执行机制。Spark正以其结构一体化、功能多元化的优势,逐渐成为当今大数据领域最热门的大数据计算平台。
Apache Spark由SparkCore、Spark SQL、Spark Streaming、GraphX、MLlib等模块组成,如图所示。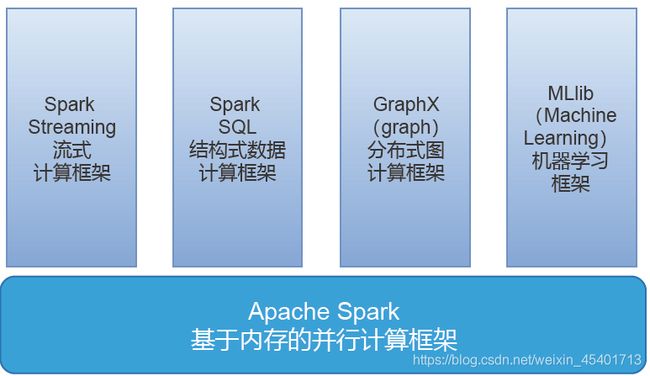
Spark是基于内存的计算框架,Spark在运算时,将中间产生运算结果暂存储在内存中,如图所示。