2022谷粒商城SpringCloud项目环境搭建+项目流程(基础篇)
谷粒商城项目
前言:在真正开始敲代码实现项目功能之前,关于此项目的介绍和环境搭建读者阅读本篇就可以了(笔者自己还记录了一下项目中遇到的小bug以及知识点)。后面的功能实现从简考虑没有附上具体的代码(篇幅会过长,且意义不大),而只是记录了每一步具体的功能实现流程,完成实现代码可以通过下方的gitee仓库地址获取。下面就让我们开始学习这一个分布式微服务项目吧!
项目的gitee码云地址:https://gitee.com/Toprogrammer/gulimall。
笔者在这里强烈建议同学把它拉取到自己电脑上,因为大部分功能实现难点我都会直接在代码中写上注释,搭配本文使用效果更好哦!
分布式基础概念
微服务
微服务是一种架构风格,就像是把一个单独的应用程序开发成一组小型服务,每个小服务运行在自己的进程中,也就是可独立部署和升级。并且使用轻量级机制通信,通常是 HTTP API 这些服务围绕业务能力来构建,并通过完全自动化部署机制来独立部署,这些服务可以使用不同的编程语言书写,以及使用不同的数据存储技术,并保持最低限度的集中式管理。
简而言之,微服务这种架构风格的意思就是拒绝大型单体应用,基于业务边界进行服务微化拆分,每个服务独立部署运行。即把一个大型的业务拆分成一个个小业务。
集群&分布式&节点
集群是个物理状态,分布式是个工作方式。
只要是一堆机器,就可以叫做集群,他们是不是一起协作干活,这谁也不知道。
《分布式系统原理与范型》定义:
分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统 (distributed system) ,分布式系统是建立于网络之上的软件系统。
分布式是指根据不同的业务分布在不同的地方。 而业务就可能是一个集群
集群指的是将几台服务器集中在一起,实现同一业务。
例如:京东是一个分布式系统,众多业务运行在不同的机器上,所有业务构成一个大型的业务集群,每一个小的业务,比如用户系统,访问压力大的时候一台服务器是不够的,我们就应该将用户系统部署到多个服务器,此时这个用户系统就是一个集群。由此得知每一个业务系统都可以做集群化处理。
分布式中的每一个节点,都可以做集群,而集群并不一定就是分布式的。(只有当集群中的业务或者任务比较复杂或者说多样化,以至于可以继续分解,此时这个业务就可以做成分布式的)
节点: 集群中的一个服务器
远程调用
在分布式系统中,各个服务可能处于不同主机,但是各个服务之间不可避免的需要互相调用,这种调用我们称之为远程调用
SpringCloud中使用HTTP+JSON的方式来完成远程调用

负载均衡
分布式系统中,A 服务需要调用B服务,B服务在多台机器中都存在, A调用B服务的任意一个服务器均可完成功能
为了使每一个服务器都不要太或者太闲,我们可以负载均衡调用每一个服务器,以此提升网站的健壮性
常见的负载均衡算法:
轮询: 为第一个请求选择健康池中的每一个后端服务器,然后按顺序往后依次选择,直到最后一个,然后循环
最小连接: 优先选择链接数最少,也就是压力最小的后端服务器,在会话较长的情况下可以考虑采取这种方式

服务注册/发现&注册中心
A服务调用B服务,A服务不知道B服务当前在哪几台服务器上有,哪些正常的,哪些服务已经下线,解决这个问题可以引入注册中心
如果某些服务下线,我们其他人(还有服务)可以实时的感知到其他服务的状态(是否下线),从而避免调用不可用的服务。
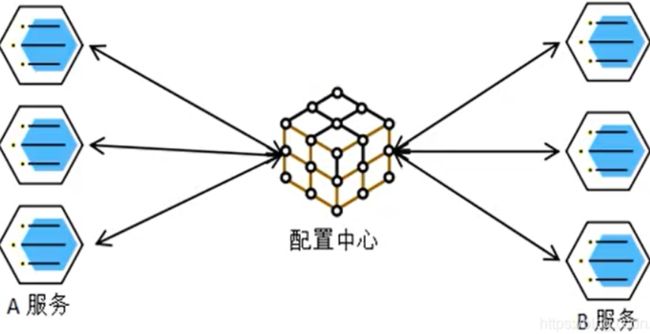
配置中心
每一个服务最终都有大量配置,并且每个服务都可能部署在多个服务器上,我们经常需要变更配置,为了更加方便的管理服务的配置信息,我们可以让每个服务在配置中心获取自己的配置信息。
配置中心就是用来集中管理微服务的配置信息的。
服务熔断&服务降级
在微服务架构中,微服务之间通过网络来进行通信,存在相互依赖,当其中一个服务不可用时,有可能会造成雪崩效应,要防止这种情况,必须要有容错机制来保护服务。
比如一个rpc情景:订单服务 --> 商品服务 --> 库存服务
库存服务出现故障导致响应慢,导致商品服务需要等待,可能等到10s后库存服务才能响应。库存服务的不可用导致商品服务阻塞,商品服务等的期间,订单服务也处于阻塞。一个服务不可用导致整个服务链都阻塞。如果是高并发,第一个请求调用后阻塞10s得不到结果,第二个请求直接阻塞10s。更多的请求进来导致请求积压,全部阻塞,最终服务器的资源耗尽,导致雪崩。
常见容错机制有以下两种:
-
服务熔断:
设置服务的超时,当被调用的服务经常失败到达某个阈值,我们可以开启断路保护机制,后来的请求不再去调用这个服务,本地直接返回默认的数据 -
服务降级:
在运维期间,当系统处于高峰期,系统资源紧张,我们可以让非核心业务降级运行。降级:某些服务不处理,或者简单处理【抛异常,返回NULL,调用 Mock数据,调用 FallBack 处理逻辑】
API 网关
在微服务架构中,API Gateway 作为整体架构的重要组件,抽象服务中需要的公共功能,同时它提供了客户端负载均衡,服务自动熔断,灰度发布,统一认证,限流监控,日志统计等丰富功能,帮助我们解决很多API管理的难题。
网关就相当于一个安检系统,可以对经过的请求进行一些处理。

环境搭建
项目是由人人开源项目直接生成的,可以节省我们大部分的前期开发工作。
我们在使用人人开源项目根据我们设计的数据库表逆向生成实体类,Controller,Service,dao,mapper等等代码时发现每个服务都会引入一些相同的依赖,那么我们就可以创建一个Common模块用来保存这些公共部分,这个公共部分包括相同的依赖,相同的工具类,相同的实体类等等。
bug1:
在虚拟机上运行mysql服务之后,主机无法连接虚拟机上的mysql服务。此时可以通过命令systemctl status firewalld查看防火墙是否关闭,如果没有关闭就使用stop命令进行关闭。但是这一步如果涉及到了docker那么我们需要重启docker服务来重新生成链(原因:docker服务启动时定义的自定义链DOCKER,当 centos7 firewall 被清掉时,firewall的底层是使用iptables进行数据过滤,建立在iptables之上,这可能会与 Docker 产生冲突。当 firewalld 启动或者重启的时候,将会从 iptables 中移除 DOCKER 的规则,从而影响了 Docker 的正常工作。)
bug2:
在连接数据库时,出现last packet sent successfully to the server was 0 milliseconds ago. The driver has not received错误。使用命令行与数据库工具都可以连接上,但是程序无法连接。排查出来是SSL安全验证的问题。在url后加上useSSL=fasle取消验证即可。
bug3:
Caused by: java.lang.ClassNotFoundException: org.springframework.boot.context.properties.ConfigurationPropertiesBean
出现这个异常时,可能就是spring相关组件的依赖发生冲突,更换一下依赖。
bug4:
当我们编译项目时,如果项目编译错误,且出现这样的错误Failed to execute goal on project …: Could not resolve dependencies for project …。如果项目是多个moudule的,那么我们在编译子项目时,一定要先把父项目先install一下。
知识点1:

在我们配置mybatis的属性的时候如果需要扫描所有class路径就需要在classpath后加上*。
classpath 和 classpath 区别:*
classpath:只会到你的class路径中查找找文件;
classpath:不仅包含class路径,还包括我们引入的依赖中的jar文件中(class路径)进行查找
classpath的使用:当项目中有多个classpath路径,并同时加载多个classpath路径下(此种情况多数不会遇到)的文件,就发挥了作用,如果不加,则表示仅仅加载第一个classpath路径。
知识点2:
因为单个项目中有很多复用的类和方法,鉴于封装的思想,我们可以将其复用的方法进行封装,而公共类我们可以新建module来进行保存,然后只需要导入这个新moudle的依赖即可,这样我们可以省去很多冗余代码。
总结springboot整合mybatis过程:
第一步需要导入springboot整合mybatis的依赖(mybatis-plus-boot-starter),然后需要导入mybatis的依赖(mysql-connector-java),这时我们就可以使用mybatis来操作数据库了。
第二步需要配置mybatis的配置信息,因为这里是使用springboot整合mybatis,所以我们需要在src/main/resources中添加配置文件(application.properties和application.yml二选一,两者只是数据格式不同)。然后在里面配置springboot整合mybatis的信息,如数据源信息:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
#MySQL配置
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.10.10:3306/gulimall_pms?useUnicode=true&characterEncoding=UTF- 8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
然后还需要配置上mybatis的配置信息如sql映射文件的位置
mybatis-plus:
mapper-locations: classpath:/mapper/**/*.xml
global-config:
db-config:
id-type: auto
logic-delete-value: 1
logic-not-delete-value: 0
通过mybatis-plus这个属性我们可以配置很多mybatis的相关属性。
第三步就是我们书写我们操作数据库的各种类了(controller->service->dao->mapper.xml),这里没有main函数,因为我们使用的是springboot,有主启动类,所以我们可以直接开启主启动类(需要加上注解@MapperScan然后配置上我们mapper类所在的位置)。这样springboot和mybatis的整合就完成了。总结下来就是三步,引入依赖,修改配置,编写代码。
SpringCloudAlibaba:
SpringCloudAlibaba是对SpringCloud中组件的拓展,使用其需要先整合Springboot和SpringCloud,这里一定要注意它们的版本号,因为springboot 和 springCloud 版本有约束,不按照它的约束会有冲突。
- boot使用的是数字作为版本。官网强烈建议升级到2.0以上
- cloud使用的是字母作为版本,伦敦地铁站站名
cloud版本决定了boot版本

查看版本对应关系:https://start.spring.io/actuator/info
Nacos:注册中心和配置中心
使用nacos注册中心的步骤
第一步是下载并启动nacos,启动之后我们可以访问本机的8848端口来访问nacos的网页来进行管理服务了。
第二步需要导入依赖,修改pom文件。这里我们使用了dependencyManagement来进行依赖版本控制,只需要引入SpringCloudAlibaba的版本即可直接控制其组件的版本
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-alibaba-dependenciesartifactId>
<version>2.1.2.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
然后就可以直接引入nacos的依赖而不用注明其版本了。
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId>
dependency>
第三步是向配置文件(application.properties/yml)中配置nacos注册中心的配置信息
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring.application.name=当前模块名字
最后一步只需要给主启动类标上注解@EnableDiscoveryClient即可,然后我们就可以在nacos的页面上查到我们注册的服务了。
使用nacos配置中心的步骤
第一步先导入nacos-config的依赖(因为之前我们已经下载好nacos的客户端了不需要再次下载),修改pom文件。这里一样使用了dependencyManagement来进行依赖版本控制,所以只需要引入SpringCloudAlibaba的版本即可直接控制其组件的版本
然后就可以直接引入nacos的依赖而不用注明其版本了。
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId>
dependency>
这里我在配置时有一个小bug,我的SpringCloud的版本用的是Greenwich:SR3,对应的SpringBoot版本号为2.1.X这里我使用的是2.1.8,对应SpringCloudAlibaba的版本号为2.1.2.RELEASE,用其声明nacos注册中心依赖时无异常,但是声明config依赖时就会出现和SpringBoot依赖冲突问题,但是我的版本都是根据github上的spring官网进行配置的,找半天也不知道哪个依赖引错了,迫于无奈只能去mvnrepository找nacos-config的依赖一个个试了,只有2.1.1.RELEASE可以。
第二步需要在/src/main/resources/bootstrap.properties这个配置文件中配置nacos-config元数据。这个文件是springboot里规定的,其优先级比application.properties高。
spring.application.name=gulimall-coupon//要配置的服务的服务名
spring.cloud.nacos.config.server-addr=127.0.0.1:8848//配置中心的地址
第三步我们就可以在nacos中添加我们服务对应的的配置文件了。在配置管理中的配置列表点击+号即可创建对应配置文件,注意这个配置文件格式为服务名.格式名。这个配置文件名字会在我们启动这个服务之后在日志中打印出来。配置文件名格式和文件类型一定要对!
![]()
最后一步在我们需要动态获取配置中心中配置文件的地方如controller上加上@RefreshScope注解,意思为动态获取配置信息。
配置中心相关概念及其操作
一下属性都是配置在bootstrap.properties属性文件中的。
命名空间: 用作配置隔离。(一般一个微服务对应一个命名空间),微服务可以通过不同的命名空间区分配置信息,将相当于将配置信息分类存放了。
默认的命名空间是public,所以默认情况下新增的配置都在public命名空间下。
比如开发、测试、开发可以用不同的命名空间分割。properties文件在每个空间都有一份。也可以为每个微服务配置一个命名空间,这样可以将微服务的配置信息互相隔离,使微服务只加载自己命名空间下的配置文件。
命名空间的信息可以在bootstrap.properties里进行配置,具体内容如下:
#首先选择要进行读取的配置文件所在的命名空间,然后属性值为命名空间的ID
spring.cloud.nacos.config.namespace=b176a68a-6800-4648-833b-be10be8bab00
配置分组: 默认所有的配置集都属于DEFAULT_GROUP。配置分组也可以理解为另一种配置隔离,这个隔离比命名空间的隔离范围更广。比如多个微服务同属一个组下,那么就可以将这个多个微服务的配置文件放在一个组中。比如双十一的配置信息组和618的配置信息组。
#值直接写组名即可
spring.cloud.nacos.config.group=DEFAULT_GROUP
此外,命名空间和配置分组之间并无交叉,也就是说不同命名空间下的配置文件可以同属一个组,不同组中的配置文件可以同属一个命名空间。
项目中对这两者的结合使用:每个微服务创建自己的命名空间,然后使用配置分组区分环境(dev,test)。
配置集ID: 类似于配置文件名,即Data ID
配置集: 一组相关或不相关配置文件的集合。
在项目中,极有可能出现一个配置文件过大,即其中配置信息量过多,导致不好管理,这时我们可以将其中的配置信息进行分类存储在不同的配置文件中(使用nacos管理这些配置文件,微服务的任何配置信息,任何配置文件都可以放在配置中心中),但是springboot默认只会读取application.properties/yml这一个配置文件的信息,如果我们想一次加载所有需要加载的配置文件,就需要知道如何加载配置集了。步骤如下:
只需要在bootstrap.properties文件中用数组spring.cloud.nacos.config.extension-configs[下标]写明每个配置集即可
#配置文件名
spring.cloud.nacos.config.extension-configs[0].data-id=datasource.yml
#配置文件组
spring.cloud.nacos.config.extension-configs[0].group=dev
#是否动态刷新
spring.cloud.nacos.config.extension-configs[0].refresh=true
spring.cloud.nacos.config.extension-configs[1].data-id=mybatis.yml
spring.cloud.nacos.config.extension-configs[1].group=dev
spring.cloud.nacos.config.extension-configs[1].refresh=true
如果不加extension-configs[0]这一属性则默认操作的配置文件是application.properties/yml这一配置文件。
那么得到了配置文件之后应如何取出里面的配置属性值呢?
@value,@ConfigurationProperties,springboot中任何从配置文件中获取值的方法都一样可以在这里使用。获取的配置信息优先是配置中心里的,如果配置中心没有才会获取本地application.properties/yml配置文件中的配置信息。
OpenFeign:远程调用
feign是一个声明式的HTTP客户端,他的目的就是让远程调用更加简单。给远程服务发的是HTTP请求。openfeign是feign的开源实现。
例如如果会员服务想要远程调用优惠券服务,只需要给会员服务里引入openfeign依赖,他就有了远程调用其他服务的能力。
使用feign的步骤
第一步在pom文件中加入feign的依赖,因为在这个pom文件中配置过springcloud的组件版本控制了
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-dependenciesartifactId>
<version>${spring-cloud.version}version>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
所以我们可以直接引入openfeign的依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
第二步就是编写(远程调用)接口,需要给这个接口加上@FeignClient注解表示这个接口需要开启远程调用并且给其默认属性value附上值,这个值就是要调用远程服务的服务名。然后就需要在这个接口中定义处理远程调用的服务请求的方法。
@FeignClient("gulimall-coupon")//远程调用的服务名
public interface CouponFeignService {
@RequestMapping("/coupon/coupon/member/list")//远程调用服务的方法名
public R membercoupons();
}
第三步就是开启远程调用服务功能:在主启动类上加上@EnableFeignClients注解,然后需要给这个注解的basePackages属性附上要扫描包含远程调用接口的包,这个属性表明openfeign将去哪个包下扫描带有@FeignClient注解的接口。
@EnableFeignClients(basePackages = "com.xjx.gulimall.member.feign")
最后一步就是使用远程调用功能了。我们只需要在需要调用远程服务的地方使用其方法对应的feign接口(先获取这个接口的bean实例)来调用这个方法即可。
@Autowired
private CouponFeignService couponFeignService;
couponFeignService.membercoupons();
gateway:网关
网关主要是用来对客户端发送的请求进行前期处理的,比如给网关配置了nacos之后,它就可以从注册中心实时地感知各个服务的状态,从而对请求进行相关处理。请求路径由客户端直接到服务提供者改为请求先通过网关,然后网关路由到服务提供者。
网关还可以对请求进行拦截,请求在发送时也要加上询问权限,然后网关就可以看当前发送请求的用户有没有权限访问这个请求的地址。
网关是请求流量的入口,常用功能包括路由转发,权限校验,限流控制等。springcloud gateway取代了zuul网关。
三大核心概念:
Route路由: 用户发送一个请求给网关,网关将请求路由到指定的服务。路由有id,目的地uri,断言的集合,请求匹配了断言就能到达指定位置。
Predicate断言: 就是java里的断言函数,匹配请求里的任何信息,包括请求头等,根据请求头来判定路由哪个服务。
Filter过滤器: 过滤器请求和响应都可以被修改。
客户端发请求给服务端。中间有网关。先交给映射器,如果能处理就交给handler处理,然后交给一系列filer,然后给指定的服务,再返回回来给客户端。

gateway的使用步骤:
第一步先引入nacos的依赖,因为我们需要通过gateway来处理请求,那么它就需要感知其他服务。所以我们要引入nacos的依赖。然后在主启动类上标注上@EnableDiscoveryClient注解,接着在application.properties文件中配置上nacos注册中心的地址以及当前服务的名字。
spring.application.name=gulimall-coupon//要配置的服务的服务名
spring.cloud.nacos.config.server-addr=127.0.0.1:8848//配置中心的地址
我们还可以把gateway的配置信息也放到nacos的配置中心中,所以还需要创建一个bootstrap.properties配置文件来存放nacos配置中心的配置信息。还可以在其中按需进行其他配置如命名空间等。
spring.application.name=gulimall-coupon//要配置的服务的服务名
spring.cloud.nacos.config.server-addr=127.0.0.1:8848//配置中心的地址
第二步我们就可以使用gateway的功能了,比如路由功能。我们可以在application.yml文件中书写路由断言规则
spring:
cloud:
gateway:
routes:
- id: test_route
uri: https://www.baidu.com
predicates:
- Query=url,baidu
- id: qq_route
uri: https://www.qq.com
predicates:
- Query=url,qq
#这个断言的意思就是判断url中是否含有baidu或者qq
renren-fast-vue前端页面的登录
第一步: 填充表数据,然后需要实现从表中取出我们填充的数据的功能,取出的数据要按照等级分别存放,就是一个简单的crud。
第二步: 后台取数据功能实现之后,就需要准备前端页面了,使用renren-fast-vue项目快速创建我们的前端页面,然后编写前端请求后端功能的url。但这里renren-fast-vue中的配置文件已经设置过默认访问url了,我们在验证我们请求后端功能的url时会发现这个设置的默认url,然后去前端项目中查找这个路径是配置在什么地方了,把它改为我们要请求的主机地址即可。但是这里我们不能每次请求不同服务都修改一次url,所以这里我们设置默认请求为网关(88端口)。
第三步: 我们在设置过之后重新访问前端页面会发现验证码消失了,因为验证码是后端项目renren-fast发送给前端项目的,但是我们改了前端项目默认地址,所以验证码由网关发起了,我们需要修改这个请求重新由renren-fast发起。所以我们现在就需要把renren-fast这个项目注册进nacos中。这里因为renren-fast用的boot版本过高,引入nacos依赖会导致依赖冲突,且renren-fast中引入依赖过多不好排查,建议直接copy完成的pom文件。
第四步: 需要修改由网关发起的请求地址,我们通过过滤器让网关把验证码请求转给fast进行处理,这里还需要进行路径重写因为renren
-fast这个项目中设置了项目名也就是说这个项目下的请求都需要这个项目名前缀。
第五步: 我们在设置好路径后,验证码虽然出来了,但是我们登录不进去,因为当前请求会发生跨域。我们需要在服务器进行配置允许请求跨域。只需要给网关配置允许跨域即可,因为我们所有的请求都是交由网关进行处理的。(使用配置类配置跨域,相当于注册进了一个bean用于请求跨域的)
- 跨域: 指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器对js施加的安全限制。(ajax可以)
- 同源策略: 是指
协议,域名,端囗都要相同,其中有一个不同都会产生跨域;
跨域流程:
这个跨域请求的实现是通过预检请求实现的,先发送一个OPSTIONS探路,收到响应允许跨域后再发送真实请求
跨域请求流程: 非简单请求(PUT、DELETE)等,需要先发送预检请求
-----1、预检请求、OPTIONS ------>
<----2、服务器响应允许跨域 ------
浏览器 | | 服务器
-----3、正式发送真实请求 -------->
<----4、响应数据 --------------
商品服务的三级分类功能实现
三级分类的查询:
为了实现商品三级分类的展示,我们就需要把查到的商品服务按照等级进行分类。这里是给商品添加父子字段(子字段是虚构字段)来实现分类的。这里我们需要改一下前端路由规则,因为它默认都是向renren-fast的8080端口发送请求,而我们是分布式系统,一个服务一个端口号,所以为了避免后面频繁的改请求规则,这里我们把renren-fast也注册到nacos中,然后使用网关统一管理请求。
记录一下关于java8中stream流的用法:
首先要获取流数据,即对应集合调用stream方法。然后使用filter过滤器方法对流中数据进行我们想要的过滤,过滤代码的结果是布尔类型,这里过滤方法会对流中的每一个数据都进行过滤,只有返回值为true的元素才会被收集进新的流中。然后如果我们想要对数据进行操作的话需要使用map方法,filter方法只会对数据进行过滤,不能对其进一步加工,而map方法可以,它相当于把原来的元素映射成了一个新的元素。然后我们就可以进行收集了,使用collect方法(参数是一个集合)。因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。如果我们还需要对流中数据进行排序那么需要在调用collect方法直接调用sorted方法并传入排序规则(也是一个函数式接口),因为collect之后就是一个集合了,而不是流了,所以我们要想排序就要在其之前调用sorted方法。
三级分类的删除:
我们使用了element-ui的tree来实现三级分类,所以以后操作的也是tree里面的属性,有两个属性很重要:
node与data:
node代表当前结点(是否展开等信息,element-ui自带属性),
data是结点数据,是自己的数据。
data从哪里来:前面ajax发送请求,拿到data,赋值给menus属性,而menus属性绑定到标签的data属性。而node是ui的默认规则
只有子节点才有删除选项。且我们的删除并不是物理删除数据库中的数据,而是逻辑删除,只是改变数据的一个字段,使其的状态改为删除状态。
三级分类新增
在每一个一二级节点后增加一个append按钮,因为我们设计的是三级分类,所以三级菜单是不允许append的。然后我们点击append,弹出对话框,输入分类名称。然后点击确定,新建方法addCategory发送post请求到后端; 因为要把数据添加到数据库,所以在前端数据中按照数据库的格式声明一个category,这个category会动态获取对话框中的数据,点击确定时发送post请求同步数据库数据。
三级分类修改
在每一个产品后都加上一个edit按钮,绑定一个edit函数,然后使用elementui创建一个对话框,在对话框里需要回显我们选定产品的数据(动态更新),我们可以在点击按钮时就把数据动态绑定进来(首先就是主键字段,这个一定要绑定,因为需要确定数据),为了防止多人同时操作,对话框中所有数据都应该从数据库中读取出来。然后声明vue实例的一个数据变量来接收它的初值,并保存它的修改值然后传递给后台进行修改。修改过后,还要重置回显信息。
拖拽修改功能
这一步比较麻烦,因为我们拖动节点时要考虑到每个节点的深度和其它节点的顺序问题。
首先我们在设置节点可拖拽时还要判断当前节点是否可以移动到被拖拽节点,这里需要使用一个函数进行判断,因为拖拽后必须保持树型的三层结构。然后我们需要收集拖拽节点后影响到的其他节点,这里通过一个v-on绑定拖拽结束事件触发收集函数,还需要一个数组用来保存需要修改的节点。为了避免每次拖动菜单都需要发送请求,我们设置一个批量修改的选项,一次性将所有需要修改的节点都发送到后台进行更新。
批量删除功能
增加一个批量删除按钮,获取所有选中的节点,然后遍历这些节点,取出它们的id主键值和name值,把值放入一个数组中。然后会触发一个对话框进行提示是否进行删除(所有敏感操作比如删除都需要进行二次确定),只有二次确定为true才会发送ajax请求给后台进行数据库的逻辑删除(这里也不是直接删除数据库中的数据,所有删除操作使用的都是逻辑删除)。
商品服务的品牌管理
页面创建及优化
我们可以直接使用renren-generate直接生成我们product表对应的前端内容然后导入到前端工程下即可。但是我们生成的这个页面初始并没有新增和删除的权限,只需要到isAuth这个方法下让其返回true即可,然后把页面适当优化。
快速显示开关
我们可以在列表中添加自定义列,中间加标签。可以通过然后可以在template的 Scoped slot 属性中设置scope就可以获取到 row, column, $index 和 store(table 内部的状态管理)的数据。然后我们就可以在template标签中设置我们想要的样式了,这里我们设置样式为switch,我们根据数据库的值设置对应的true/fasle多为1/0。然后绑定change事件这样每次点击开关都会修改数据库中的这个商品的显示状态。因为swich的开关值默认是true/false,但我们可以设置为其他值( :active-value=“1”/:inactive-value="0"这两个字是从elementui官网得到的)。
文件上传功能
和传统的单体应用不同,这里我们选择将数据上传到分布式文件服务器上。因为我们项目采用的就是分布式系统,所以服务和数据存储不会在一台服务器之上。
但由于学习阶段,配置一台专门的服务器用来存储数据不太现实,所以这里我们选择将图片放置到阿里云上,使用对象存储OSS。
上传策略: 服务端签名后直传

使用这种方式即免除了通过应用服务器进行传输数据的不便,且能保证我们数据存储服务器的安全。
上传有两种方式:
第一种时我们可以手动导入依赖包,然后手写一个传输数据的方法来进行数据的传输。
第二种就是我们使用springcloudalibaba的oss服务。这样我们就可以直接调其写好的方法直接传送一个文件流即可。但是我们这里使用的上传策略是服务端签名后直传,所以我们还需要写一个请求policy的方法让我们的应用服务器(third-party)返回一个签名。我们一样把third-party服务器所有的请求都交给网关来处理(所有请求都交给网管处理),所以就需要去网关服务器的配置文件中再配置third-party中的请求路由规则。
之后我们就需要编写前端上传数据的请求了。我们只需要使用renrenfastvue提供的上传组件即可,把上传地址改为我们阿里云的bucket即可然后在上传页面引入这个组件。但是我们默认的oss是不允许跨域的,手动设置一下所有请求都允许跨域即可。然后我们在组件里面配置好要上传的数据库地址,再把获取policy方法(这个方法执行在上传之前)中的请求地址配置成我们本地服务器的请求地址即可。这样我们在前端页面上上传文件之后会先去本地服务器(third-party)中获取policy签名,然后由前端页面直接访问阿里云进行数据传输了。
这里注意一点:我们已经在前段项目设置过了请求路径默认都是http://localhost:88/api,所以我们用vue调用的所有请求地址前缀都是这个开头的,默认都是访问网关的,api只是为了更好的区分请求。
数据校验
数据校验分为前端校验和后端校验。前端校验主要是用来给用户看的,规范一下用户填写的表单数据。后端校验是为了防止有一些请求越过前端校验直接请求服务器而导致修改数据库的数据格式不正确。
前端校验就是先获取表单项数据,然后将数据与预先设定好的数据格式进行对比,如果不符合则会实时显示错误信息引导用户进行修改。
后端数据校验我们只需要导入一个数据校验的依赖(spring-boot-starter-validation)即可。然后我们就可以以注解的方式给实体类的字段添加数据校验(还可以给注解的属性赋值,以我们想要的格式对数据进行校验),然后在需要校验的方法上添加@Valid注解这个注解放在需要进行数据校验的实体类的形参前面,并返回提示信息。给校验的bean(是一个字段)后紧跟着一个BindingResult,就可以获取到校验的结果,然后我们就可以自定义校验结果了。
统一异常处理
但以上那种获取校验结果并且自定义处理只是对那一个方法来说的这种是针对于该请求设置了一个内容校验,如果针对于每个请求都单独进行配置,显然不合适,但实际上我们可以统一对校验结果进行处理。这种方式就是定义一个异常处理类来处理所有异常,因为数据校验结果如果出错也是一种异常。然后可以给这个异常处理类上加上SpringMvc所提供的@ControllerAdvice注解,通过“basePackages”能够说明处理哪些路径下的异常。但对于一些错误状态码是我们随意定义的,然而正规开发过程中,错误状态码有着严格的定义规则,所以在项目中我们可以定义一个枚举类来定义错误状态码。
分组校验功能
首先新建valid包,里面新建两个空接口AddGroup,UpdateGroup用来分组,这两个接口就相当于是两个标识。第一步给校验注解标注上groups(属性),指定什么分组时才需要进行校验。但我一旦使用了分组校验,那么在这种情况下,没有指定分组的字段的校验注解,默认是不起作用的,想要起作用就必须要加groups指定这个字段是哪一个分组下的。第二步在对应的业务方法上使用@Validated注解指定是哪一个分组下的数据校验。
自定义校验
自定义校验有三步:
第一步是编写一个自定义的校验注解,它有三个必须的属性。
第二步是编写一个自定义的校验器。
第三步是把自定义的注解和自定义的校验器进行关联。具体做法是在我们自定义的注解上的@Constraint注解配置它的validatedBy属性值为自定义的校验器的class类。
商品服务的属性分组
分类分组及其属性说明
商品分类分为三级,每一级都是对上一级分类的进一步划分,三级分类就差不多是一类具体商品的抽象。
属性分组是对属性的集合,也是三级分类组织起来的,一些商品共有的属性我们可以把它们填充到一个属性分组里面。
属性也是以三级分类组织起来的,属性分为规格参数和商品属性,每个分类下的商品共享规格参数和商品属性,只是有些商品可能不会用到这个分类下全部的属性。属性名是确定的,但是值是根据商品来决定的。
前端代码并不用自己写,我们在使用逆向工程时,已经根据数据库中表的字段生成了前端页面,所以我们只需要复制逆向生成的前端代码到前端项目中即可。属性分组就是对商品的一些具有相似性质的属性抽出来分到一个分组下,便于管理。
属性表中有一个分类字段,表示其在哪个分类下。属性分组下也有一个分类字段,表示其在哪一个分类下。属性和属性分组是靠一个关联关系表关联在一起的。
属性表只是存储具体属性的描述信息,而商品具体的属性值是放在ppav商品属性表中的(通过指定商品id和属性id来指定属性值)。spuid就是具体的商品id。
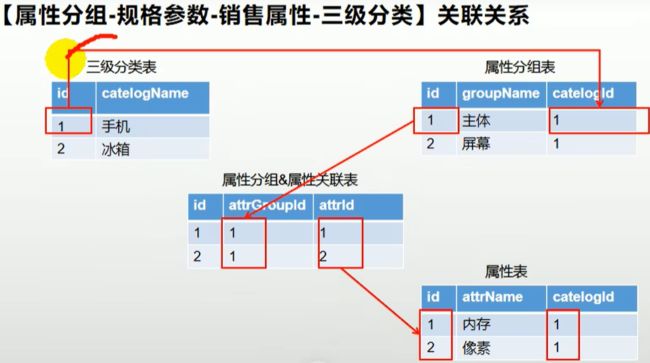
商品属性是存在ssav表中的。

举个栗子:
比如手机就是一个商品分类,然后其有一个属性分组名为基本信息,基本信息比如就有机身颜色,机身长度,重量等。
前端组件抽取
我们在属性分组页面的很多地方都需要用到前面三级分类,所以这里我们把三级分类抽取为一个组件,让需要使用三级分类的地方直接引用这个三级分类组件就可以了。我们可以创建在modeules下新建一个common文件夹,用以存放所有公共组件。这里把三级菜单抽取为categroy.vue,它就相当于是一个三级菜单组件。然后我们就可以在需要的vue页面直接导入这个组件,然后直接使用组件名字作为标签来使用这个组件。
父子组件传递数据
但我们使用引入的组件有一个问题,那就是我们引入组件的这个vue页面无法感知引入组件中是否发生某个事件。这里就需要使用this. e m i t 这个方法向父组件(引入组件的那个 v u e 页面)发送事件。我们只需要在子组件需要发送事件给父组件的地方绑定一个事件,然后在这个事件中调用 t h i s . emit这个方法向父组件(引入组件的那个vue页面)发送事件。我们只需要在子组件需要发送事件给父组件的地方绑定一个事件,然后在这个事件中调用this. emit这个方法向父组件(引入组件的那个vue页面)发送事件。我们只需要在子组件需要发送事件给父组件的地方绑定一个事件,然后在这个事件中调用this.emit方法即可,它的第一个参数就是要在父组件中触发的事件名,父组件在给绑定的这个事件名定义一个触发函数即可。
获取分类属性分组
然后我们就可以书写后端处理请求的代码了,因为前端会发送一个分类id,我们需要查出这个分类id的所有属性信息。我们可以直接调用生成好的一系列工具类来完成这个功能,只需要判断一下分类id为不为0的情况以及是否需要进行检索功能(这里是or模糊检索)。最后修改一下前端代码中getDataList()中的请求路径中新增catId。
属性分组新增功能
新增时我们需要把父id改换成选择框,通过选择框来添加菜单数据,且如果当前菜单为第三级菜单则不显示下一级菜单界面,但这里我们要提交的只是最后一级的菜单,这样才能进行添加操作。但这又是一个问题,因为这里只取得了最后一级菜单,那么在进行修改操作时,回显数据就只会回显最后一级菜单,而不会回显整个菜单链,所以我们还需要通过这个最后一级的菜单id来获取其父菜单,以达到修改时显示整个菜单路径。
关联分类与品牌
商品分类与商品品牌是多对多的关系,所以我们应该创建一个额外的表保存这种关联关系。
增加关联关系主要就是通过传过来的id查找具体的值比如名字然后把数据存入关联关系表中。但这里我们还要注意同步数据信息,比如
对品牌(分类)名字进行修改时,品牌分类关系表之中的名字也要进行修改。也就是说关联关系表中所有和分类与品牌有关的字段(除了主键id)在其他功能下进行更新时,关联关系表中的数据都要进行同步更新。
商品服务的规格参数
规格参数的新增
我们在增加商品的属性(规格参数)时,会给这个属性绑定其分组信息,但是我们新增之后,属性和分组关联关系表中并没有关联数据,所以我们需要修改新增方法,获取属性id和分组id,然后在关联关系表中新增它们的关联数据。
这里我们知道VO(value object现在也可以叫view object)的用法,前端传回来的数据有可能与我们的数据库表中数据不一样,且我们也许还需要对前端传送回来的数据进行处理才会向service中传,并且service传送回来的数据我们也需要处理才能向前端页面进行传送,这时就需要VO了。而且我们可以使用BeanUtils工具类把vo中数据拷贝到真正到实体类中,而Vo中其他数据根据需要进行操作。
VO现在更多叫view object(视图对象),其主要作用就是接受页面传递来的数据,封装成我们需要的对象。然后将业务处理完成的对象,封装成页面要用的对象。
规格参数的查询
我们查询规格参数时与查找商品属性分组一样,都需要判断是否有商品id和查询条件,所以这俩功能是类似的。但是这里我们查询的规格参数信息与我们之前定义的实体类的字段是有出入的,可能需要用到关联表数据,但是在数据库中进行多表联查是非常消耗性能的,所以我们在这里创建新的实体类来保存多余出来的查询数据(尽管是冗余数据)。然后我们可以把原本查出的数据使用BeanUtils工具类的copy方法把数据复制到我们新的实体类中(只要它们的属性名相同即可)
规格参数的修改
我们还是用到之前创建的实体类,然后先利用查询回显数据,之后对数据进行修改就可以了。注意如果修改的是一个空值是失败的,所以我们要进行判断,如果一个值之前没有值,那么我们进行修改时对这个属性其实是新增操作。
商品服务的销售属性
这里跟规格参数功能基本差不多,只是获取的属性值不同,规格参数是基本属性,而这里是销售属性。数据库中有一个字段是用来判断到底是规格参数还是销售属性的(0/1),而为了代码的拓展性和可维护性,我们可以抽象出来一个枚举类,以后只要需要使用0/1判断是什么属性的地方都可以使用这个枚举类。而这两个属性之间会有不同的数据库字段,在操作关于这些字段的地方,我们都需要判断一下是什么属性。
商品服务的属性与属性分组的关联
我们单击属性分组的关联时会弹出一个对话框,里面会显示当前所点击的属性分组所关联的所有属性,这里我们需要从数据库中取出数据。注意一点:这里我们是使用的自定义的VO接收的前台返回来的数据(json形式),所以需要在形参前面加上@RequestBody注解。本节的其他操作也需要这样处理。
注意一个属性只能与一个分组相关联,那么我们在新增关联关系时,查出的属性就需要排除其他分组已经关联的属性和当前分组已经关联的属性。且当前分组只能关联自己所属分类里面的所有属性。
商品服务的新增商品
调试会员等级相关接口
这个接口已经自动生成了,我们只需要开启会员服务即可。首先把gulimall-member添加到服务注册中心,然后启动gulimall-member服务,然后在网关的yml文件中配置会员服务的网关路由。
获取分类关联的品牌
我们在新增商品时需要设定商品所属的品牌,那么点击商品的分类时就要获取与该分类关联的所有品牌。这里向后台发送的是get请求,那么需要@RequestParam注解获取请求信息时可以设置它的required属性为true,意思是只有携带这个注解指定value值的请求数据才会处理这个请求否则不进行处理。
这里我们总结出了Controller层的任务:
- Controller: 处理请求,接受和校验数据
- Service接受controller传来的数据,进行业务处理
- Controller接受Service处理完的数据,封装成页面指定的vo。
获取分类下所有分组以及属性
新增商品的第二步是添加它的规格参数,第一步中我们添加了这个商品的所属分类,这一步中就需要用到这个商品分类去找这个分类下的所有属性分组及其下面的所有基本属性。前端需要返回的数据直接就包括属性分组信息和其下的所有属性,所以我们这里需要自定义一个VO用来返回数据。
这里写代码时发现了我们因为使用了Mybatis所以很多增删改查的方法都不需要我们写,而是直接调用即可,但是如果我们有自定义需求怎么办,Mybatis给我们提供了Wrapper类,也就是说Mybatis给我们创建好的增删改查方法如果不够用,我们可以把我们的需求写入Wrapper对象中然后传给Mybatis给我们创建好的方法中,这样就可以实现我们自定义的需求了。
新增商品
在前端点击保存商品信息后,后台要把前端传过来的商品信息插入数据库中,因为传过来的数据量很大,甚至涉及多个服务多个数据库。所以我们还是要先创建一个VO来接收前端传过来的数据,然后开始存数据。注意这里Service层中的方法要加@Transactional因为这个方法中要调用很多service实现类的方法,所以一定要添加事务。基本的添加都很简单,就是需要知道具体表结构与其对应的实体类。这里重点记录一下远程调用的过程:
首先把coupon优惠券服务加入Naco注册中心中,确保我们的商品服务可以通过网关找到优惠券服务并且把请求转发过去。这里我们在创建模块的时候已经配置了feign,所以不需要再导入Feign的依赖了,然后在我们商品服务的主启动类上加上@EnableFeignClients(basePackages =XXX)注解以开启feign的远程调用功能并且说明feign的远程调用接口都在哪个包下。
然后我们先去coupon服务下编写我们处理商品服务所放松请求的处理方法。
编写好之后回到我们的商品服务模块中,然后编写我们商品服务的远程调用接口。接口上要表明@FeignClient(“gulimall-coupon”)注解以及它调用的服务名,然后声明远程调用服务的方法。我们只需要定义方法即可,注意这里方法签名以及返回值需要与coupon优惠券服务中真正处理请求的方法签名以及返回值相同(其实形参可以不同,因为数据是通过json的形式传递获取的,只要接收json数据的实体类中的属性名和json数据中的属性名相等就可以取得数据)。然后标上请求映射注解如post请求就用@PostMapping("/coupon/spubounds/save")路径就是coupon服务下真正处理请求的路径。这里我们在调用完远程服务之后需要接收一下返回值,判断一下处理是否成功了。
商品服务的商品管理
这个比较简单,只是对我们刚才增加的商品的一个CRUD,大部分操作我们都可以直接复用Mybatis给我们写好的。我们需要修改的只是查的功能。把前端需要的查找条件以及分页参数传到后台,然后后台根据这些条件来查找数据。
仓库服务的库存查询
这里也是一个简单的查操作,把前端需要的查找条件以及分页参数传到后台,然后后台根据这些条件来查找数据。
仓库服务的采购需求查询
这里也是一个简单的查操作,把前端需要的查找条件以及分页参数传到后台,然后后台根据这些条件来查找数据。
这里记录一点:就是包装类Wrapper的and和or操作如果and操作需要一个括号把后面的操作包括起来的话还是需要用到Lamda表达式的,不然and和or连在一起,那么无论and是什么加上or之后如果or是对的那么整个都是对的。
仓库服务的合并采购
这里我们先理一下采购逻辑:新建采购需求后还要可以提供合并采购单,比如一个仓库的东西可以合并到一起,让采购人员一趟采购完。
具体流程看下图:

我们需要先创建采购需求,然后将这些采购需求合并到一张采购单中。我们可以手动创建采购单,也可以选择在合并采购需求时让系统为我们创建一张新的采购单。这里采购单有很多种状态,所以我们可以在common模块中为仓库服务的采购单创建一个枚举类保存这些状态。然后合并采购需求,具体就是把我们刚刚得到的要合并的采购单(无论是前端指明的还是后端新创建的),我们只需要对每一个采购需求指明它们的采购单id以及修改它们的状态即可完成合并采购的要求。最后记得更新一下采购单的更新时间。
仓库服务的领取采购单
这个请求是员工服务中发过来的,我们还没写员工服务所以用postman模拟一下。发送请求中携带着需要领取的采购单id。首先我们确认一下要领取的采购单状态是新建或者已分配这两种。如果是就改变它们的状态为已领取。然后改变采购单中采购需求的状态为正在采购。
仓库服务的完成采购
这里会有前台的员工服务放松完成采购请求,参数包括采购单id和采购项id,状态及其如果发生异常的异常原因。
首先我们改变采购需求的状态,因为下面要进行判断:只有全部采购需求的状态都为成功,采购单状态才能设为成功(利用了一个标志位)。采购需求如果采购无异常那么就修改其状态为完成并且把对应库存加上,有异常就只修改一下状态以及标志位设为false。然后修改采购单状态。
商品服务的SPU规格参数的查询与修改
查询就是很简单的查询,使用Mybatis自带的就可以,只需要传入一个带着spu_id的Wrapper就可以了。
关于修改:因为修改的时候,商品属性可能有新增有修改有删除。 所以就先把spuId对应的所有属性都删了,再新增。原有的属性会回显出来,所以如果我们没有修改一些数据,那么原有的数据会重新插入到表当中。
感谢耐心看到这里的同学,觉得文章对您有帮助的希望同学们不要吝啬您手中的赞,动动您智慧的小手,您的认可就是我创作的动力!
之后还会勤更自己的学习笔记,感兴趣的朋友点点关注哦。