(史上最完整)k8s和kubesphere搭建图文教程
搭建前的准备
1.安装最小版的centos7.6系统
安装过程参考如下:Centos7超详细服务器上安装配置教程_我想学建模的博客-CSDN博客_服务器安装centos7安装教程
- (ps):在这里我们是在 Kubernetes1.17上安装 KubeSphere v3.0.0,如需详细知道版本兼容问题,参考kubesphere官网:在 Kubernetes 上最小化安装 KubeSphere
k8s的安装
一.前置步骤(3台机器同时执行以下代码)
#关闭防火墙: 或者阿里云开通安全组端口访问
systemctl stop firewalld
systemctl disable firewalld
#关闭 selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
#关闭 swap:
swapoff -a #临时
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久
#将桥接的 IPv4 流量传递到 iptables 的链:
# 修改 /etc/sysctl.conf
# 如果有配置,则修改
sed -i "s#^net.ipv4.ip_forward.*#net.ipv4.ip_forward=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-ip6tables.*#net.bridge.bridge-nf-call-ip6tables=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-iptables.*#net.bridge.bridge-nf-call-iptables=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.all.disable_ipv6.*#net.ipv6.conf.all.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.default.disable_ipv6.*#net.ipv6.conf.default.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.lo.disable_ipv6.*#net.ipv6.conf.lo.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.all.forwarding.*#net.ipv6.conf.all.forwarding=1#g" /etc/sysctl.conf
# 可能没有,追加
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-iptables = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.all.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.default.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.lo.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.all.forwarding = 1" >> /etc/sysctl.conf
# 执行命令以应用
sysctl -p二.安装docker(3台机器同时执行以下代码)
#1、安装docker
##1.1、卸载旧版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
##1.2、安装基础依赖
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
##1.3、配置docker yum源
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
##1.4、安装并启动 docker
yum install -y docker-ce-19.03.8 docker-ce-cli-19.03.8 containerd.io
systemctl enable docker
systemctl start docker
##1.5、配置docker加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://hub-mirror.c.163.com/"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker三.安装k8s环境
1.安装k8s、kubelet、kubeadm、kubectl(所有节点安装,3台机器同时执行以下代码)
# 配置K8S的yum源
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 卸载旧版本
yum remove -y kubelet kubeadm kubectl
# 安装kubelet、kubeadm、kubectl
yum install -y kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3
#开机启动和重启kubelet
systemctl enable kubelet && systemctl start kubelet
##注意,如果此时查看kubelet的状态,他会无限重启,等待接收集群命令,和初始化。这个是正常的。 2、master节点下载k8s的核心主件(所有节点安装,3台机器同时执行以下代码)
下载master节点需要的镜像【选做】
#1、(三台机器同时)创建一个.sh文件,同样是给每个机器都安装,vi一个image.sh,内容如下,
#!/bin/bash
images=(
kube-apiserver:v1.17.3
kube-proxy:v1.17.3
kube-controller-manager:v1.17.3
kube-scheduler:v1.17.3
coredns:1.6.5
etcd:3.4.3-0
pause:3.1
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
done
#2、开启执行权限:chmod 777 image.sh
#3、执行image.sh文件: ./image.sh3、初始化master节点
#1操作需要注意的地方
将apiserver-advertise-address=172.26.165.243这句后面的ip修改为自己的要成为master的节点的IP
将pod-network-cidr=192.168.0.0/16后面修改为calico.yaml中的value值.(查找calico中的value值:cat calico.yaml |grep 192)
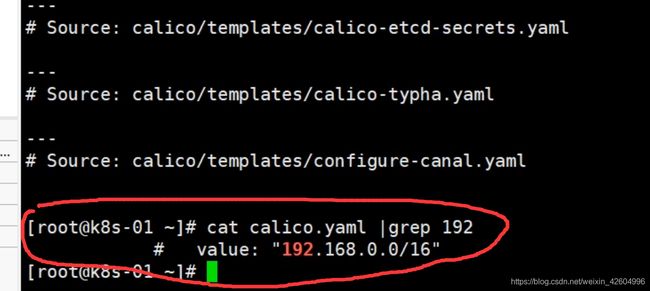
#2操作需要注意的地方
使用自己的令牌,令牌在#1操作完成后出现,最后一行

#1、初始化master节点(单节点操作,关闭xshell的输入到所有会话)
kubeadm init \
--apiserver-advertise-address=172.26.165.243 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.17.3 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16
#service网络和pod网络;docker service create
#docker container --> ip brigde
#Pod ---> ip 地址,整个集群 Pod 是可以互通。255*255
#service --->
#2、配置 kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#3、提前保存令牌
kubeadm join 172.26.165.243:6443 --token afb6st.b7jz45ze7zpg65ii \
--discovery-token-ca-cert-hash sha256:e5e5854508dafd04f0e9cf1f502b5165e25ff3017afd23cade0fe6acb5bc14ab
#4、部署网络插件
#上传网络插件,并部署
如果没有calico.yaml,下载并执行
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
如果已有calico.yaml直接执行
#kubectl apply -f calico.yaml
#网络好的时候,就没有下面的操作了
calico:
image: calico/cni:v3.14.0
image: calico/cni:v3.14.0
image: calico/pod2daemon-flexvol:v3.14.0
image: calico/node:v3.14.0
image: calico/kube-controllers:v3.14.0
#5、查看状态,等待就绪
watch kubectl get pod -n kube-system -o wide查看所有的pod是否就绪:

查看master节点是否就绪:
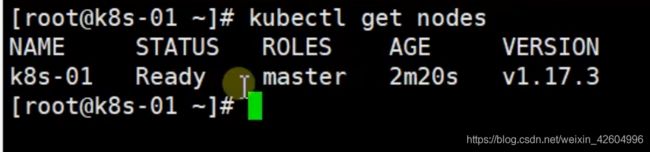
4、worker节点加入集群
#1、使用刚才master打印的令牌命令加入
kubeadm join 172.26.248.150:6443 --token ktnvuj.tgldo613ejg5a3x4 \
--discovery-token-ca-cert-hash sha256:f66c496cf7eb8aa06e1a7cdb9b6be5b013c613cdcf5d1bbd88a6ea19a2b454ec
#2、如果超过2小时忘记了令牌,可以这样做
kubeadm token create --print-join-command #打印新令牌
kubeadm token create --ttl 0 --print-join-command #创建个永不过期的令牌新加入node节点后查看所有pod是否就绪:
5、搭建NFS作为默认存储驱动(SC)
yum install -y nfs-utils
#执行命令 vi /etc/exports,创建 exports 文件,文件内容如下:
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
#/nfs/data 172.26.248.0/20(rw,no_root_squash)
#执行以下命令,启动 nfs 服务
# 创建共享目录
mkdir -p /nfs/data
systemctl enable rpcbind
systemctl enable nfs-server
systemctl start rpcbind
systemctl start nfs-server
exportfs -r
#检查配置是否生效
exportfs
# 输出结果如下所示
/nfs/data /nfs/data写一个 测试用pod
#测试Pod直接挂载NFS了
apiVersion: v1
kind: Pod
metadata:
name: vol-nfs
namespace: default
spec:
volumes:
- name: html
nfs:
path: /nfs/data #1000G
server: 自己的nfs服务器地址
containers:
- name: myapp
image: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html/其中只需要修改server,修改成自己的服务器地址。你把哪个服务器作为nfs服务器就写哪个地址。

这就是测试节点创建成功。然后我们获取这个pod的详细信息
![]()
然后测试能否在集群内访问节点。如下图所示就是访问成功了,虽然显示的时403只是因为我们没有设置页面。我在操作的过程当中,第一次curl失败了,后面在复查的过程中发现第一次没有配置dockers加速,并且我的centos7.6没有安装最小版有可能是这两个原因导致无法访问pod。
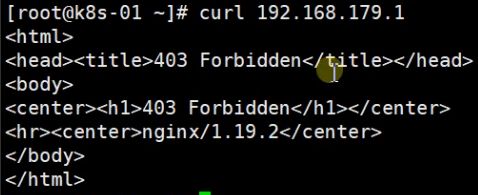
然后我们给他写一个页面 ,因为我们之前是将这个pod挂载到nfs/data/下面的所以我们进入这个文件夹,然后在其中创建index.html,然后在其中输入你想显示的东西。然后再次访问就能显示 你想要的输出的东西了。
![]()
![]()

然后将这个目录设置为共享目录
#3操作需要注意的地方
将其中IP地址改为你自己的nfs服务器地址。
#执行以下命令检查 nfs 服务器端是否有设置共享目录
# showmount -e $(nfs服务器的IP)
showmount -e 172.26.165.243
# 输出结果如下所示
Export list for 172.26.165.243
/nfs/data *
# 以下两条语句在非master节点上运行
#执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /root/nfsmount
mkdir /root/nfsmount
#高可用备份的方式
mount -t nfs 172.26.165.243:/nfs/data /root/nfsmount6、创建provisioner(NFS环境前面已经搭好)
在nfs服务器的root文件夹下创建 nfs.yaml
#4操作需要注意的地方
将其中IP地址改为你自己nfs服务器的地址,并且名字可以随便取但是要保证之后必须一致。
# 先创建授权
# vi nfs.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["services", "endpoints"]
verbs: ["get","create","list", "watch","update"]
- apiGroups: ["extensions"]
resources: ["podsecuritypolicies"]
resourceNames: ["nfs-provisioner"]
verbs: ["use"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner
namespace: default
roleRef:
kind: ClusterRole
name: nfs-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
#vi nfs-deployment.yaml;创建nfs-client的授权
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-client-provisioner
image: lizhenliang/nfs-client-provisioner
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME #供应者的名字
value: storage.pri/nfs #名字虽然可以随便起,以后引用要一致
- name: NFS_SERVER
value: 172.26.165.243
- name: NFS_PATH
value: /nfs/data
volumes:
- name: nfs-client-root
nfs:
server: 172.26.165.243
path: /nfs/data
##这个镜像中volume的mountPath默认为/persistentvolumes,不能修改,否则运行时会报错然后apply -f应用,等待provisioner创建成功。

7、创建存储类
在nfs服务器的根目录下创建sc.yaml。接下来kubectl apply-f sc.yaml即可。
#创建storageclass
# vi sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: storage-nfs
provisioner: storage.pri/nfs
reclaimPolicy: Delete8、安装metrics-server
有人要问,kubesphere里面有metrics-server为什么我们要自己安装,因为经过测试其自带的有问题安装不了所以我们提前安装。在nfs服务器的根目录下写mes.yaml,然后kubectl apply -f mes.yaml应用即可。
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:aggregated-metrics-reader
labels:
rbac.authorization.k8s.io/aggregate-to-view: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rules:
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.metrics.k8s.io
spec:
service:
name: metrics-server
namespace: kube-system
group: metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
labels:
k8s-app: metrics-server
spec:
selector:
matchLabels:
k8s-app: metrics-server
template:
metadata:
name: metrics-server
labels:
k8s-app: metrics-server
spec:
serviceAccountName: metrics-server
volumes:
# mount in tmp so we can safely use from-scratch images and/or read-only containers
- name: tmp-dir
emptyDir: {}
containers:
- name: metrics-server
image: mirrorgooglecontainers/metrics-server-amd64:v0.3.6
imagePullPolicy: IfNotPresent
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
ports:
- name: main-port
containerPort: 4443
protocol: TCP
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- name: tmp-dir
mountPath: /tmp
nodeSelector:
kubernetes.io/os: linux
kubernetes.io/arch: "amd64"
---
apiVersion: v1
kind: Service
metadata:
name: metrics-server
namespace: kube-system
labels:
kubernetes.io/name: "Metrics-server"
kubernetes.io/cluster-service: "true"
spec:
selector:
k8s-app: metrics-server
ports:
- port: 443
protocol: TCP
targetPort: main-port
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system应用成功之后,使用kubectl top nodes 可以监测各个node的cpu和内存的使用情况。

kubesphere安装
一、修改集群配置
在master节点,使用 wget命令下载kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.1.1/kubesphere-installer.yaml这个文件,若报错没有wget这个指令,在网上下载就好了。
接下来在master节点的根目录下创建c.yaml。
#5操作需要注意的地方
将ectd下的 endpointIps改为你的master节点的私有IP地址。
---
apiVersion: installer.kubesphere.io/v1alpha1
kind: ClusterConfiguration
metadata:
name: ks-installer
namespace: kubesphere-system
labels:
version: v3.0.0
spec:
persistence:
storageClass: "" # If there is not a default StorageClass in your cluster, you need to specify an existing StorageClass here.
authentication:
jwtSecret: "" # Keep the jwtSecret consistent with the host cluster. Retrive the jwtSecret by executing "kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret" on the host cluster.
etcd:
monitoring: true # Whether to enable etcd monitoring dashboard installation. You have to create a secret for etcd before you enable it.
endpointIps: 172.26.165.243 # etcd cluster EndpointIps, it can be a bunch of IPs here.
port: 2379 # etcd port
tlsEnable: true
common:
mysqlVolumeSize: 20Gi # MySQL PVC size.
minioVolumeSize: 20Gi # Minio PVC size.
etcdVolumeSize: 20Gi # etcd PVC size.
openldapVolumeSize: 2Gi # openldap PVC size.
redisVolumSize: 2Gi # Redis PVC size.
es: # Storage backend for logging, events and auditing.
# elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
# elasticsearchDataReplicas: 1 # total number of data nodes.
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes.
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes.
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks--log.
console:
enableMultiLogin: true # enable/disable multiple sing on, it allows an account can be used by different users at the same time.
port: 30880
alerting: # (CPU: 0.3 Core, Memory: 300 MiB) Whether to install KubeSphere alerting system. It enables Users to customize alerting policies to send messages to receivers in time with different time intervals and alerting levels to choose from.
enabled: true
auditing: # Whether to install KubeSphere audit log system. It provides a security-relevant chronological set of records,recording the sequence of activities happened in platform, initiated by different tenants.
enabled: true
devops: # (CPU: 0.47 Core, Memory: 8.6 G) Whether to install KubeSphere DevOps System. It provides out-of-box CI/CD system based on Jenkins, and automated workflow tools including Source-to-Image & Binary-to-Image.
enabled: true
jenkinsMemoryLim: 2Gi # Jenkins memory limit.
jenkinsMemoryReq: 1500Mi # Jenkins memory request.
jenkinsVolumeSize: 8Gi # Jenkins volume size.
jenkinsJavaOpts_Xms: 512m # The following three fields are JVM parameters.
jenkinsJavaOpts_Xmx: 512m
jenkinsJavaOpts_MaxRAM: 2g
events: # Whether to install KubeSphere events system. It provides a graphical web console for Kubernetes Events exporting, filtering and alerting in multi-tenant Kubernetes clusters.
enabled: true
ruler:
enabled: true
replicas: 2
logging: # (CPU: 57 m, Memory: 2.76 G) Whether to install KubeSphere logging system. Flexible logging functions are provided for log query, collection and management in a unified console. Additional log collectors can be added, such as Elasticsearch, Kafka and Fluentd.
enabled: true
logsidecarReplicas: 2
metrics_server: # (CPU: 56 m, Memory: 44.35 MiB) Whether to install metrics-server. IT enables HPA (Horizontal Pod Autoscaler).
enabled: false
monitoring:
# prometheusReplicas: 1 # Prometheus replicas are responsible for monitoring different segments of data source and provide high availability as well.
prometheusMemoryRequest: 400Mi # Prometheus request memory.
prometheusVolumeSize: 20Gi # Prometheus PVC size.
# alertmanagerReplicas: 1 # AlertManager Replicas.
multicluster:
clusterRole: none # host | member | none # You can install a solo cluster, or specify it as the role of host or member cluster.
networkpolicy: # Network policies allow network isolation within the same cluster, which means firewalls can be set up between certain instances (Pods).
# Make sure that the CNI network plugin used by the cluster supports NetworkPolicy. There are a number of CNI network plugins that support NetworkPolicy, including Calico, Cilium, Kube-router, Romana and Weave Net.
enabled: true
notification: # Email Notification support for the legacy alerting system, should be enabled/disabled together with the above alerting option.
enabled: true
openpitrix: # (2 Core, 3.6 G) Whether to install KubeSphere Application Store. It provides an application store for Helm-based applications, and offer application lifecycle management.
enabled: true
servicemesh: # (0.3 Core, 300 MiB) Whether to install KubeSphere Service Mesh (Istio-based). It provides fine-grained traffic management, observability and tracing, and offer visualization for traffic topology.
enabled: true 然后kubectl apply -f应用这两个文件即可。接下来我们就可以静静的等待kubesphere的安装了,可以通过
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f 进行检测。在安装的过程中不能出现failed。如果出现错误就修改刚才创建的c.yaml文件,再修改之后重新apply -f即可。
二、完成安装!
若出现以下界面说明已经安装成功,但是,一定要通过kubectl get pod -A 确保所有的pod都在Running状态。
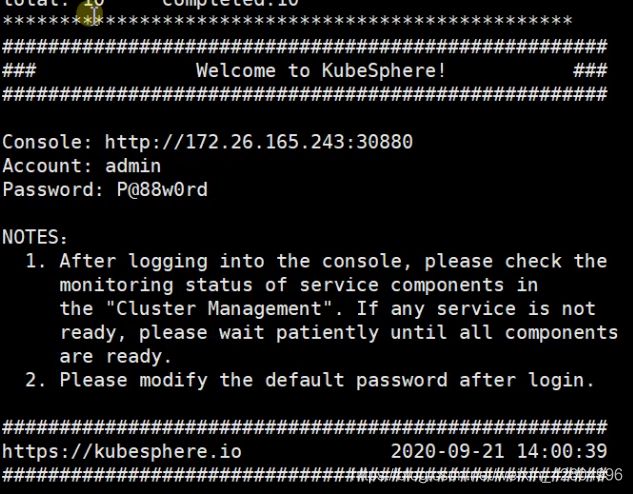
我在安装完成之后,始终有两个pod创建不成功,我在安装完成之后,始终有两个pod创建不成功,只需要master节点运行以下这段代码即可。
kubectl -n kubesphere-monitoring-system create secret generic kube-etcd-client-certs --from-file=etcd-client-ca.crt=/etc/kubernetes/pki/etcd/ca.crt --from-file=etcd-client.crt=/etc/kubernetes/pki/apiserver-etcd-client.crt --from-file=etcd-client.key=/etc/kubernetes/pki/apiserver-etcd-client.key若你的网络好运行完这段代码pod就会自动的创建好,但是如果修改之后还是一段时间创建不成功,只需要把这两个pod删除让他重新创建就好了。如下图所示。

至此整个环境的搭建就结束了!