Flink应用场景:社交应用中同步用户信息到ES
背景
目前公司社交应用“暖聊”中的首页推荐等用户匹配功能,都是基于 es 算法实现,那么就需要将用户数据实时同步到 es。项目中操作 es 的方式是基于 jpa 框架直连操作 es,当用户信息变更时,通过 jpa 的 save 方法实时同步用户数据到 es。这样做的后果就是,es 更新频繁,在用户活跃高峰期,es 服务器 IO、CPU 都面临巨大的压力,甚至会直接影响线上功能的正常使用,同步 es 的方式调整优化迫在眉睫。
现状
当前项目 es 集群配置:2核4G 2节点,线上日活 4w+,es 服务器 CPU 使用率在用户活跃时段基本处于 90% 以上。当公司通过投放或者各种营销方式成功引流时,线上将会迎来流量小高峰,es 服务器 CPU 使用率甚至可能达到 100%,导致项目中任何 es 请求都处于超时状态,服务出现短时间内不可用。
优化方案
优化方案必须满足两个条件
- 短时间内解决线上 es 服务不可用问题
- 彻底优化 es 同步方式,从根本上解放 es 服务器压力
基于此,我们做了两步优化,服务器升配和引入 Flink + Kafka + es 流式处理
-
提升硬件配置
为了及时改变线上服务不可用的现状,我们做了es 服务器配置的升级,从 2核4G 2节点 提升到 8核16G 3节点,从硬件层面提升 es 服务的并发处理能力。做完硬件层面的提升后,线上反馈很明显,基于当前应用的增长量,可以保证在短时间内不再有因 es 导致的服务不可用风险。
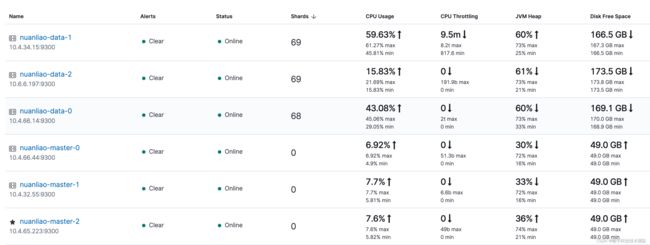
升配后的 es 集群表现:
-
基于 Kafka -> Flink -> es ,实现用户数据实时同步 es
- 为什么选择 Kafka -> Flink -> es 的流式处理
要想彻底解决 es 服务器压力问题,必须替换项目中基于 jpa 直连操作 es 的方式。新的替代方式需要至少满足下 2 个条件:
- 容错性:如果处理过程出现故障,要能够自行恢复,并且从它离开的位置再次开始处理;
- 高性能:延时应尽可能的小,吞吐量应尽可能的大(批量操作 es 可以有效提升 es 性能);
Flink 的 checkpoint 能很好的结合 Kafka 偏移量,保证程序的容错恢复以及程序启动时状态恢复。
在阿里,Flink集群能达到每秒处理17亿数据量,一天可处理上万亿条数据。并且 Flink 集成 es 提供批量处理的方式,可以大大减少访问 es 的次数。
使用 Flink sink 同步 es 还有个优点,可以很好的支持增量更新。只需要将涉及到的属性字段放入一个 map 中,在同步 es 时只会更新我们指定的字段,无需担心会将其他字段覆盖为空。
- 优化过程
第一步:统一项目中更新用户信息入口,通过 Kafka 消息将业务与 es 操作解耦。
第二步:接入 Flink 流处理框架。它可以在内存中对数据进行分布式计算,然后通过 sink 将数据输出到外部系统es。
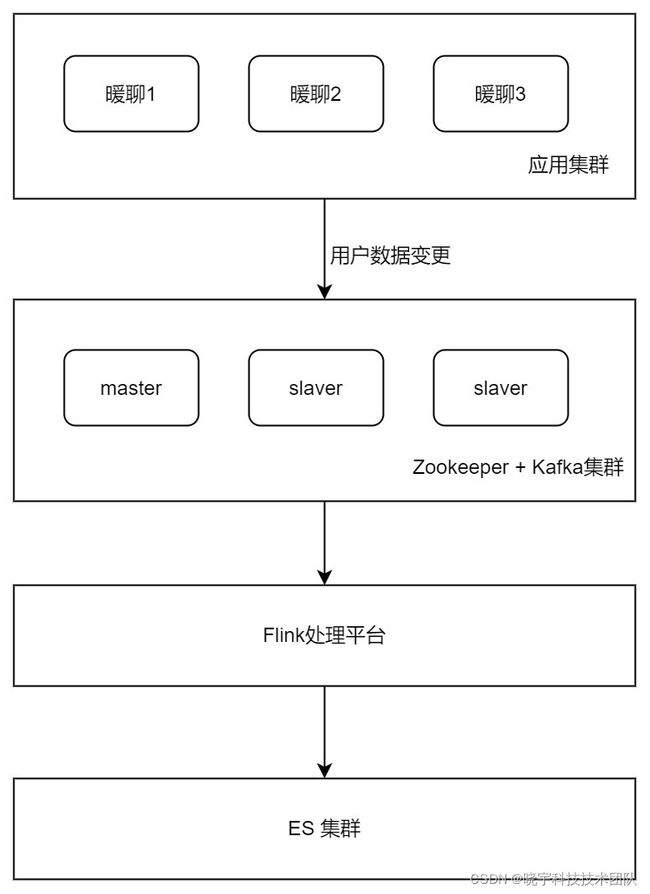
Flink 集成 Kafka、es(版本 Flink: 1.14 Kafka: 2.0 es: 7.12)
pom 文件
org.apache.flink
flink-core
1.14.0
org.apache.flink
flink-clients_2.11
1.14.0
org.apache.flink
flink-java
1.14.0
org.apache.flink
flink-streaming-java_2.11
1.14.0
org.apache.flink
flink-connector-kafka_2.11
1.14.0
org.apache.flink
flink-connector-elasticsearch7_2.11
1.14.0
com.alibaba
fastjson
1.2.71
org.projectlombok
lombok
1.18.8
Flink 主流程,从 Kafka 读取目标数据,在经过处理后写入 es
// 获取所有参数
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
// 准备好环境
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
// 从kafka读取数据
DataStreamSource data = KafkaConfigUtil.buildSource(env);
// 从配置文件中读取 es 的地址
List esAddresses = ESSinkUtil.getEsAddresses(parameterTool.get(PropertiesConstants.ELASTICSEARCH_HOSTS));
// 从配置文件中读取 bulk flush size,代表一次批处理的数量
int bulkSize = parameterTool.getInt(PropertiesConstants.ELASTICSEARCH_BULK_FLUSH_MAX_ACTIONS, 40);
// 从配置文件中读取并行 sink 数
int sinkParallelism = parameterTool.getInt(PropertiesConstants.STREAM_SINK_PARALLELISM, 5);
ESSinkUtil.addSink(esAddresses, bulkSize, sinkParallelism, data,
(MetricEvent event, RuntimeContext runtimeContext, RequestIndexer requestIndexer) -> {
logger.info("======================== model {}", JSON.toJSONString(event));
if (null != event) {
ModelHandler handler = HandlerFactory.getHandler(event.getHandlerType(), event.getIndex());
EsTypeEnum type = EsTypeEnum.findByCode(event.getEsType());
if (null == handler || null == type) {
logger.error("没有对应处理器或者没指定操作类型");
return;
}
try {
switch (type) {
case ADD:
requestIndexer.add(Requests.indexRequest(event.getIndex()).id(event.getIndexId())
.source(handler.doHandle(event.getFields())));
break;
case UPDATE:
requestIndexer.add(new UpdateRequest(event.getIndex(), event.getIndexId()).
doc(handler.doHandle(event.getFields())));
break;
case DELETE:
requestIndexer.add(Requests.deleteRequest(event.getIndex()).id(event.getIndexId()));
break;
default:
logger.error("暂不支持的操作类型");
}
} catch (ElasticsearchGenerationException e) {
logger.error("数据同步到 es 异常 ", e);
}
}
},
parameterTool);
env.execute("flink sync es"); 构建 Kafka DataStreamSource,从 Kafka 消息中解析出目标数据
public static DataStreamSource buildSource(StreamExecutionEnvironment env){
ParameterTool parameter = (ParameterTool) env.getConfig().getGlobalJobParameters();
ParameterTool parameterTool = (ParameterTool) env.getConfig().getGlobalJobParameters();
KafkaSource source = KafkaSource.builder()
// kafka 集群地址
.setBootstrapServers(parameterTool.getRequired(PropertiesConstants.KAFKA_BROKERS))
// kafka topic
.setTopics(parameter.getRequired(PropertiesConstants.METRICS_TOPIC))
// kafka group id
.setGroupId(parameterTool.getRequired(PropertiesConstants.KAFKA_GROUP_ID))
.setStartingOffsets(OffsetsInitializer.latest())
// 反序列化目标对象
.setValueOnlyDeserializer(new MetricSchema())
.build();
return env.fromSource(source, WatermarkStrategy.noWatermarks(), SOURCE_NAME); Kafka 消息体数据结构
public class MetricEvent {
/** 索引名(必填) */
private String index;
/** 索引 id(必填) */
private String indexId;
/** 处理器类型 HandlerTypeEnum(定制化处理方式) */
private String handlerType;
/** 处理类型 EsTypeEnum (必填,增/删/改) */
private String esType;
/** timestamp 消息发送时间戳 (非必填) */
private Long timestamp;
/** 具体内容 (必填) */
private Map fields;
} es 配置需要特别注意,批量提交可以极大的减少 es 请求次数。但是又必须考虑到,如果在用户活跃低峰期,Kafka 消息数达不到批量提交上限,这将导致用户数据无法及时同步 es。
Flink ElasticsearchSink 提供两种批量提交方式,按数据量和按两次提交最大间隔时间。
public static void addSink(ParameterTool parameterTool, SingleOutputStreamOperator data, ElasticsearchSinkFunction func) throws MalformedURLException {
// 从配置文件中读取 es 的地址
List esAddresses = getEsAddresses(parameterTool);
// 从配置文件中读取 bulk flush size,代表一次批处理的数量
int bulkSize = parameterTool.getInt(PropertiesConstants.ELASTICSEARCH_BULK_FLUSH_MAX_ACTIONS, DEFAULT_ELASTICSEARCH_BULK_SIZE);
// 从配置文件中读取 bulk flush interval,代表批处理最大间隔时间
int bulkInterval = parameterTool.getInt(PropertiesConstants.ELASTICSEARCH_BULK_FLUSH_MAX_INTERVAL, DEFAULT_ELASTICSEARCH_BULK_INTERVAL);
// 从配置文件中读取并行 sink 数
int sinkParallelism = parameterTool.getInt(PropertiesConstants.ELASTICSEARCH_STREAM_SINK_PARALLELISM, DEFAULT_ELASTICSEARCH_SINK_PARALLELISM);
ElasticsearchSink.Builder esSinkBuilder = new ElasticsearchSink.Builder<>(esAddresses, func);
esSinkBuilder.setBulkFlushMaxActions(bulkSize);
esSinkBuilder.setBulkFlushInterval(bulkInterval);
esSinkBuilder.setFailureHandler(new RetryRequestFailureHandler());
data.addSink(esSinkBuilder.build()).setParallelism(sinkParallelism);
} 配置优化建议
Kafka 分区数会决定 Flink 的并行度,最好 Kafka 的分区数和 Flink 的并行度一致,Flink 的并行度最好和 es 的分片数相等,这样能并行写入。
性能提升
Flink 平台上线后,es 服务始终平稳,CPU 使用率未再出现因系统流量突增而飙升的情况。
后续优化方向
目前项目会在用户信息变更时主动发送 Kafka 消息,这本身就是对业务代码的入侵。基于 Flink CDC 实现用户数据同步 es,将可以达到业务与同步 es 完全解耦的目的。 感兴趣的同学可以自行了解下 Flink CDC 是什么。后续项目优化完成后,我们再来分享如何基于 Flink CDC 实现用户数据同步 es。