移动端自动化任务-AutoJs Pro v9使用教程(一)
官网 - Auto.js Pro
Github代码示例
教程与博客 (autojs.org)
开源版文档
Pro 版 API 旧文档
Pro 版 v9新文档
2023-2-13 更新:因 Autojs Pro 可能用于某些违法违规活动, AutoJs Pro 的核心功能:自动化操作、消息通知、截图等已被开发者移除,大家可以选用免费版或者其他方案了,此教程。。。如果对你们还有用的话就先留着吧
历史版本及ocr插件下载: 链接
一、前言
本教程是本人学习 Auto.js Pro V9 的记录,算是个入门教程,通过本文可帮你快速了解 autojs 的大体用法和开发步骤。官方文档也有中文的,想了解更多 autojs 的用法和实战案例的话还是推荐去阅读官方文档和博客,链接我放在了最上方❤。由于 pro 版本对微信、支付宝等软件做了限制,无法通过控件定位,如有相关需求的用户请用免费版或者 AutoX
Auto.js是一个支持无障碍服务的Android平台上的JavaScript IDE,其发展目标是JsBox和Workflow。
与运行在PC端的:Appium、Airtest等框架相比,Auto.js 可以直接运行在移动端,它通过编写 JavaScript 脚本,结合系统的「 无障碍服务 」可对 App 进行自动化操作。
这里放一下官方的功能介绍:
- 由无障碍服务实现的简单易用的自动操作函数
- 悬浮窗录制和运行
- 更专业&强大的选择器API,提供对屏幕上的控件的寻找、遍历、获取信息、操作等。类似于Google的UI测试框架UiAutomator,您也可以把他当做移动版UI测试框架使用
- 采用JavaScript为脚本语言,并支持代码补全、变量重命名、代码格式化、查找替换等功能,可以作为一个JavaScript IDE使用
- 支持使用e4x编写界面,并可以将JavaScript打包为apk文件,您可以用它来开发小工具应用
- 支持使用Root权限以提供更强大的屏幕点击、滑动、录制功能和运行shell命令。录制录制可产生js文件或二进制文件,录制动作的回放比较流畅
- 提供截取屏幕、保存截图、图片找色、找图等函数
- 可作为Tasker插件使用,结合Tasker可胜任日常工作流
- 带有界面分析工具,类似Android Studio的LayoutInspector,可以分析界面层次和范围、获取界面上的控件信息
本软件与按键精灵等软件不同,主要区别是:
- Auto.js主要以自动化、工作流为目标,更多地是方便日常生活工作,例如启动游戏时自动屏蔽通知、一键与特定联系人微信视频(知乎上出现过该问题,老人难以进行复杂的操作和子女进行微信视频)等
- Auto.js兼容性更好。以坐标为基础的按键精灵、脚本精灵很容易出现分辨率问题,而以控件为基础的Auto.js则没有这个问题
- Auto.js执行大部分任务不需要root权限。只有需要精确坐标点击、滑动的相关函数才需要root权限
- Auto.js可以提供界面编写等功能,不仅仅是作为一个脚本软件而存在
二、安装测试
1. 安装auto.js APP
从官网首页下载 auto.js 安装到真机或模拟器(推荐网易 MuMu 或雷电模拟器)中。
安装完后打开,需要注册账号并登录,为了使用更多强大的功能和长期稳定的版本支持,我开通了 Pro 版本(¥45),所以该教程是基于 Pro 版本进行介绍的
Auto.js 开源版本已不再维护(原因参见Auto.js Pro FAQ),后续将只维护Auto.js Pro专业版,更多信息查看Auto.js Pro文档和Auto.js Pro特性。
2. 安装VSCode 插件
在VS Code中菜单"查看"->“扩展”->输入"Auto.js"或"hyb1996"搜索,即可看到"Auto.js-Pro-Ext"插件,点击安装即可。
注意有Pro,另一个Auto.js-VSCode-Extension是给免费版本用的。
3. 创建项目
在Vscode中 按 Ctrl+Shift+P 或点击"查看"->"命令面板"可调出命令面板,输入 Auto.js 可以看到列出的命令,我当前的 autojs 版本是 v9.2,就选择新建 V9 API 项目。
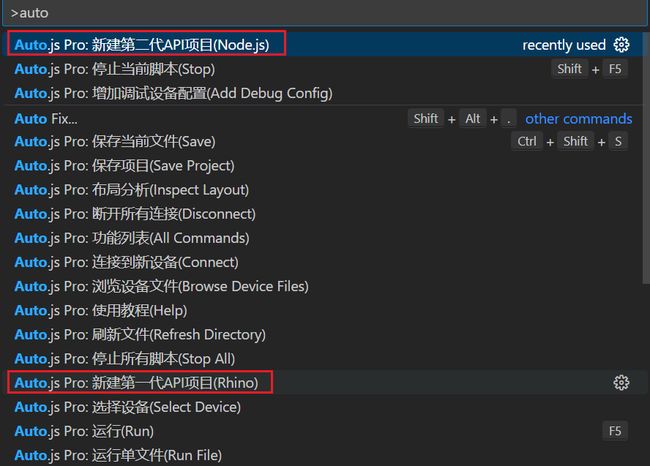
4. 连接测试
连接说明
运行 auto.js 有服务端模式和客户端模式之分
- 服务器模式:用电脑连接手机,手机作为主控制端,模拟器中不推荐该模式。
- 客户端模式:用手机连接电脑,主要用于手机端控制电脑端模拟器
这两种工作模式用哪种都一样,都是在 PC 端写代码运行到移动端上。
连接方式也有两种:远程连接和 usb 直连
-
远程连接:手机端能通过 ip 地址直接访问到电脑端,一般是同在一个局域网内。用笔记本电脑或者手机开热点也行。
-
usb 直连:如果以上都无法做到,或者 autojs 在模拟器中的IP地址连不上,你还可以通过 USB 线连接手机,参考使用USB连接手机(adb)
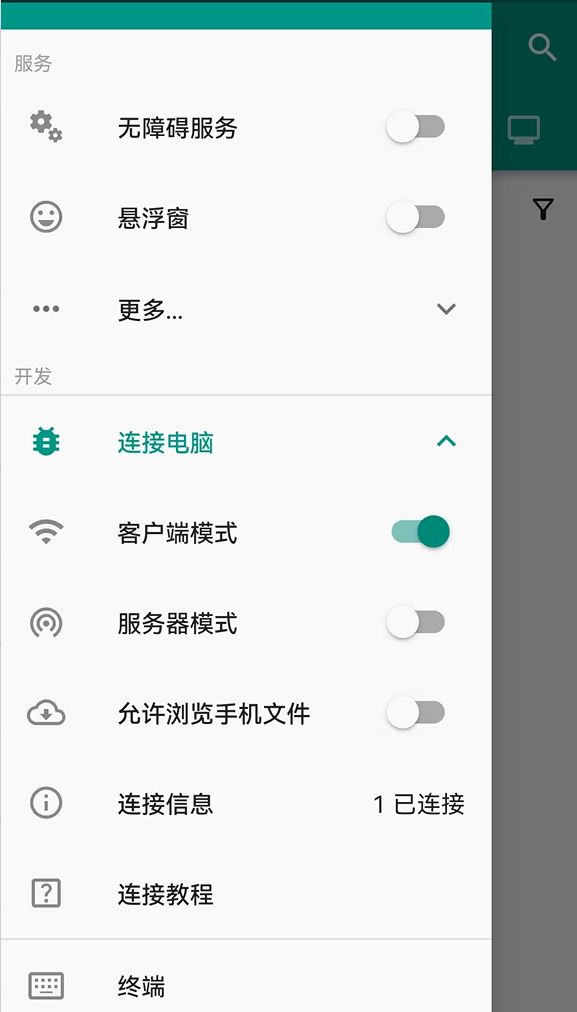
使用WiFi连接手机
这里我只演示真机(非模拟器)的客户端模式(因为此方式最简单),其他方式请移步教程:Auto.js Pro使用VSCode调试教程
将手机连接到电脑启用的Wifi或者同一局域网中,查看电脑的IP地址(ipconfig、ifconfig)。
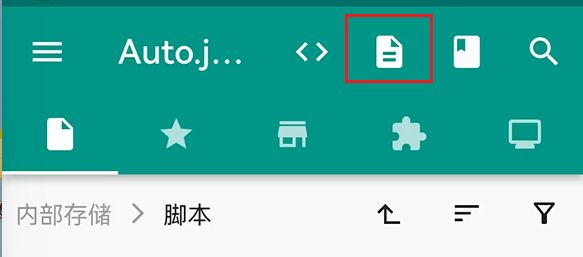
在手机端打开 Auto.js ,在开发这一栏将客户端模式打开 “客户端模式”,输入电脑的 IP 地址,连接成功后如下图:
vscode 中右下角显示设备已连接
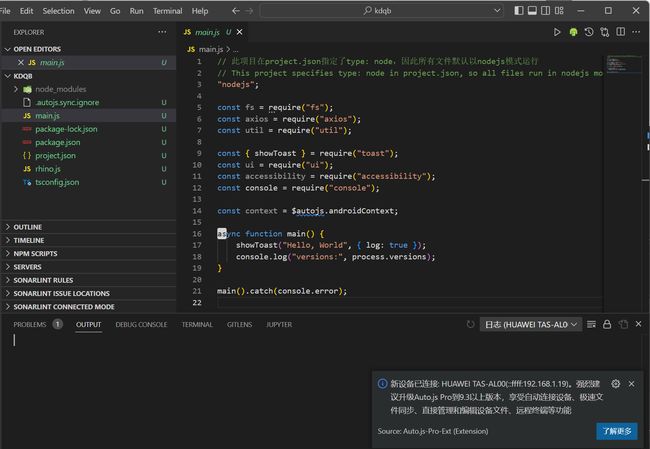
如果连接没有成功,请尝试暂时关闭Windows防火墙后重试。
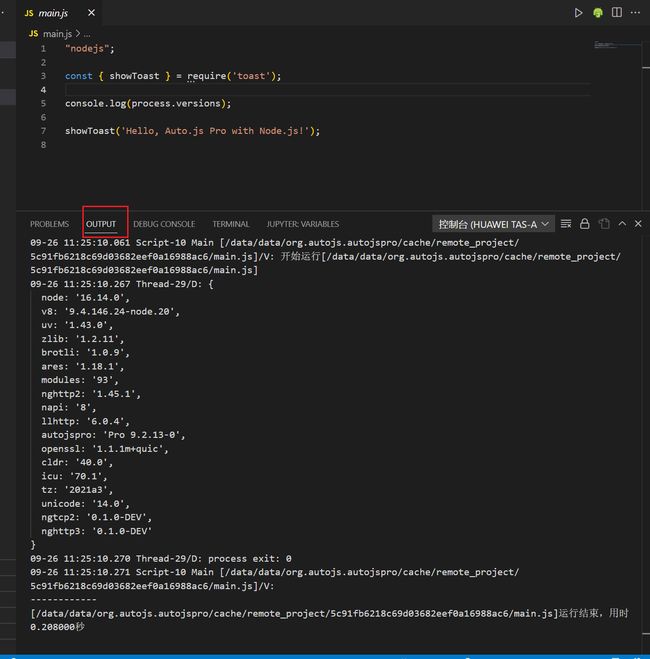
我们以上图中的 4 行代码做测试,效果就是 vscode 中打印 process.versions 的信息,并且在手机屏幕上显示 Hello, Auto.js Pro with Node.js! 这一行字。
点击右上角的绿色图标或者Ctrl+Shift+P调出 autojs 功能菜单,选择运行(Run),快捷键是 F5。如果有多个设备连接到此 PC 上,默认会应用到所有已连接的设备上,你也可以选择在指定设备运行脚本(RUn On Device),如下图所示:
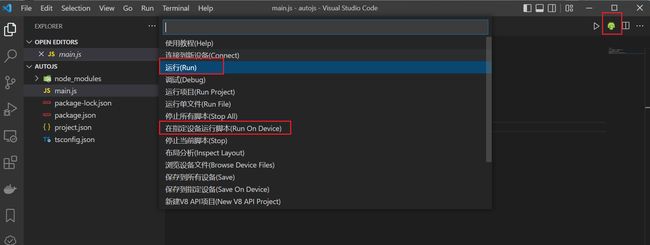
点击运行后
在 vscode 的 OUTPUT 栏可以看输出到 console 的输出信息:
在手机端可看到显示的文字

也可在手机端查看 console 输出:
三、开发指南
1. 版本选择
如果你要操作的软件是微信、支付宝、淘宝等可能涉及黑产的软件,用免费版或者其他同类型的软件,Pro 版对这些软件做了限制,我也是开通了 pro 版之后才发现的,有点后悔(ps:我只是想做个微信小游戏的辅助工具)
如果免费版可以满足需求的话,就用免费版。Pro 版作为长期支持版本,后续集成的功能会越来越多,比如现在就集成了 OCR 模块,但功能再多用不上也摆设。
如果你已经开通了 Pro版本,就可享用更方便的 node.js 模块、Es6 语法和庞大的npm生态(接近200万个npm包),在创建项目的时候需要选择创建 v9 API 项目。(其实 autojs 为了兼容,只要在
v9版本对应的新文档是: https://pro.autojs.org/docs/v9/zh/
关于V9版本的路线规划,请参考https://github.com/hyb1996/Auto.js/issues/526 。
如果你是 Pro 版本,并不依赖node模块、Es6 语法和 npm 扩展包,那就在创建项目的时候选择创建 v8 API 项目,对应的是旧文档:https://pro.autojs.org/docs/#/zh-cn/
新的 API 文档当前还在完善中,还有就是网上教程大多数是 v9 版本之前的,遇到问题更容易找到解决方案,对于新手我建议从 v8 版本入门,熟练后再看 v9。
2. 熟悉API文档
当前文档还处于不断完善中,v9新版的文档是基于代码自动生成的,个人感觉阅读体验不如旧版。
相同的模块的用法和方法名存在很大差异,如果想切换项目的 JavaScript 引擎,请注意兼容性,比如 threads 线程模型用法就不一样。
3. 开启必要权限
-
必须开启无障碍服务,不同厂家的手机开启步骤可能不一样,请按照指引操作;每次启动 autojs 都要检查一遍。
-
前台服务用于提升服务的存活率,防止服务被回收掉;
-
悬浮窗功能
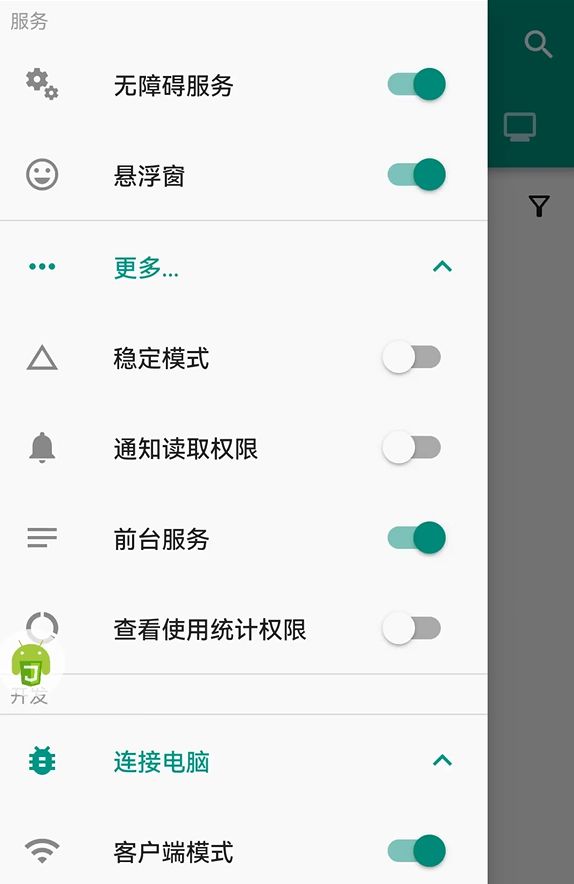

悬浮窗会悬浮在任意界面之上,提供一些快捷功能操作,具体包含:
- 文件项目列表:会展示示例代码及自己编写的脚本、文件夹,可以快速完成脚本编辑、运行、定时任务、打包等操作
- 脚本录制:录制脚本,仅适用于 Root 后的设备,由于它基于坐标点,适配性不强,所以很少使用
- 元素控件定位:针对当前界面进行布局控件分析、布局层次分析
- 关闭正在执行的脚本:一键停止所有正在执行的脚本任务
- 更多设置:可以快速进入到无障碍服务页面、查看当前应用包名及 Activity 名称等
4. 选择定位方式
使用 autojs 主要是帮我们完成"自动操作"任务,大致分为基于控件和基于坐标的操作。
(1) 基于坐标
单纯的按照你要点击或滑动的目标位置在屏幕的坐标位置操作,例如click(100, 200), press(100, 200, 500)等。优点就是定位目标元素简单,适合写游戏辅助工具,但因为不同型号手机的屏幕分辨率可能相同也可能不同,这种方式写的脚本通用性较差,横屏竖屏一切换根本用不了,比如平板用户。
这部分相关的模块有:accessibility、media_projection、color、image
为了快速知道我们目标点的(x,y)坐标位置,在真机上可以打开开发者模式(如何打开开发者模式请自行百度),在开发人员选项中打开指针位置,然后就能看到在屏幕上点击、滑动的坐标位置和持续时间了,如下图:
在模拟器中也有类似的查看坐标功能,这里不做赘述。
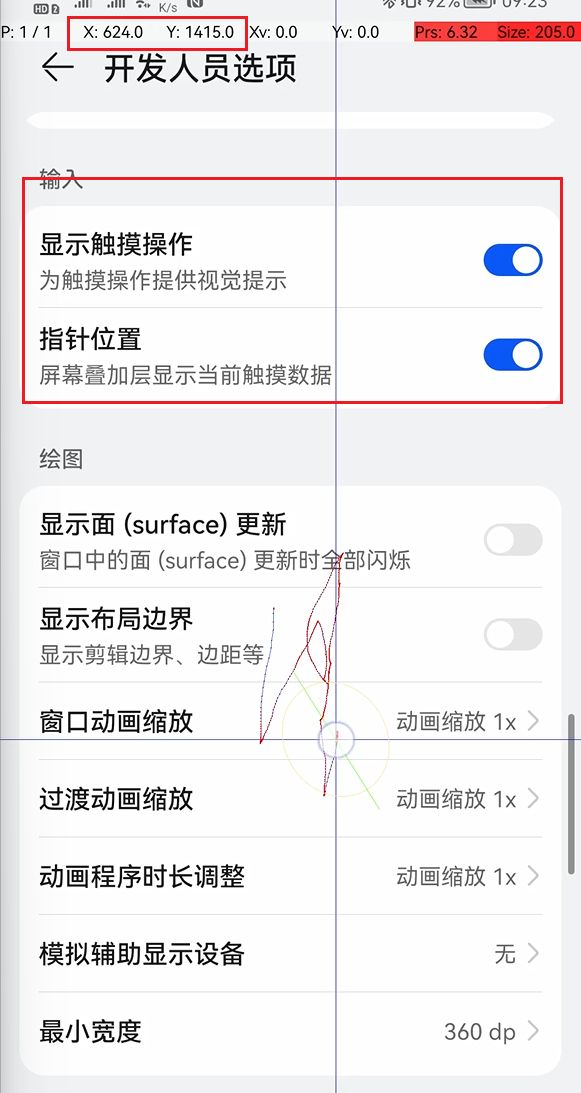
为了增强脚本的通用性,基于坐标的定位方式一般会配合以图找图、OCR 识别等技术,但是效率会低一点。
(2) 基于控件
一般的应用软件的界面是基于控件排版布局的,每个按钮、文本框、输入框都有相应的层级关系,类似于 HTML 布局。基于控件的操作对不同机型有很好的兼容性,不用担心分辨率不同的问题,但不适合大多数游戏应用中。
开启 autojs 的悬浮窗后,打开目标应用(比如通讯录),点击 autojs 悬浮窗的蓝色按钮(元素控件定位),如果能看到页面包含许多小方格,就说明是能用控件定位的;如果只有一个大的方格,中心区域没有任何可点击查看的控件,就不能用控件定位了,只能老老实实用做坐标定位了。
(也可以试试 AutoX )
这部分相关的模块有:accessibility 的 select() 方法、ui_object、ui_selector
四、常用模块
挑几个写脚本常用的模块介绍下功能
1. app 应用控制
app模块提供一系列函数,用于启动应用、与其他应用交互。
-
getInstalledPackages(options[, options]):获取安装的应用列表, 返回包含PackageInfo对象组成的列表,示例:'nodejs'; const app = require('app'); const context = $autojs.androidContext; // 输出所有已安装的应用信息 function outputInstalledApp() { const packages = app.getInstalledPackages({ get: ['meta_data'] }); packages.forEach((packageInfo) => { name = packageInfo.applicationInfo.loadLabel(context.getPackageManager());// 应用名 packageName = packageInfo.packageName; //获取应用包名,可用于卸载和启动应用 version = packageInfo.versionName; //获取应用版本名 versionCode = packageInfo.versionCode; //获取应用版本号 console.log(`${name}---${packageName}---${version}---${versionCode}`); }); } -
getPackageName(targetAppName): 获取应用名称对应的已安装的应用的包名。如果该找不到该应用,返回null;如果该名称对应多个应用,则只返回其中某一个的包名。'nodejs'; const app = require('app'); console.log(app.getPackageName('微信')); // com.tencent.mm -
launch(packageName): 通过包名启动,例如:if (app.launch('com.tencent.mm')) { // 启动微信 console.log('启动成功'); } -
launchApp(targetAppName):通过应用名称启动,即图标下显示的名称,例如:if (app.launchApp('微信')) { console.log('启动成功'); }
2. clip_manager 剪切板
剪贴板模块,用于获取、设置剪贴板内容。在Android 10以上,由于系统限制,在后台无法访问、监听剪贴板。
-
clipboardManager:剪贴板管理器。用于获取、设置、监听剪贴板内容。'nodejs'; const { clipboardManager, getClip, setClip } = require('clip_manager'); let taskId; // 事件监听 clipboardManager.on('clip_changed', () => { let content = getClip(); // 获取剪切板内容 console.log('检测到剪切板内容变动:' + content); setClip('hello world ' + content); // 设置剪切板内容 $autojs.cancelKeepRunning(taskId); // 终止执行 }); taskId = $autojs.keepRunning(); // 保持引擎运行,阻止Node.js事件循环退出
3. device 系统相关
device模块提供了与设备有关的信息与操作,例如获取设备宽高,内存使用率,设备ID,调整设备亮度、音量等。
此模块的部分函数,需要"修改系统设置"的权限。如果没有该权限,会抛出异常。
-
androidId: 一串64位的编码(十六进制字符串),是随机生成的设备的第一个引导。 -
imei或serial:设备的唯一标识符。从Android 10开始,应用不再有权限获取IMEI。 -
displayMetrics:获取屏幕宽、高、像素密度等参数,例如:'nodejs'; const { device } = require('device'); console.log(device.displayMetrics); // 返回一个对象 { widthPixels: 1080, heightPixels: 2340, density: 3, scaledDensity: 3, densityDpi: 480, xdpi: 391.885009765625, ydpi: 391.0260009765625 } -
vibrate(millis): 让设备震动一段时间。这个功能在写脚本时我觉得还是挺有用的,脚本放在一边跑着,出了异常或者需要手动解决的问题时,可以发起震动提醒,就是有点耗电。
const { device } = require('device'); device.vibrate(1000) // 震动一秒 -
sdkName、sdkVersionCode: 获取安卓版本名称和 SDK 版本号。const { OS } = require('device'); console.log(OS.sdkName); // e.g. 10 console.log(OS.sdkVersionCode); // e.g. 29 -
requiresAndroidVersion(version, message): 要求最低在给定的Android版本中运行。如果当前系统版本小于给定版本,则抛出异常,异常信息为给定的message字段。"nodejs"; const { OS } = require('device'); OS.requiresAndroidVersion(OS.ANDROID_N, '不满足安卓最低版本要求'); // 最低要求 Android7.0 -
其他:电量、供电方式、音量控制、亮度、品牌、CPU架构、内存占用、mac 地址等
4. accessibility 无障碍服务
基于坐标和基于控件都用得到的一个模块,包括模拟点击、滑动、按键输入、事件监听等功能。
但无法实现多点触摸和动态改变手势,要实现类似双指缩放操作需要 root 权限,详见 root_automator 模块文档。
-
click(x, y)\longClick(x, y): 点击 \ 长按屏幕上指定位置,注意返回的是Promise。 -
press(x, y, duration): 长按 (x, y) 位置持续 duration 毫秒。 -
clickText(text[, index]): 点击屏幕中的第几个文本,从0开始。审查到控件且该控件的 text 属性有值才能用。 -
swipe(x1, y1, x2, y2, duration): 从(x1,y1)滑动到(x2,y2),持续 duration 毫秒。 -
performGesture(points, duration[, delay]): 模拟手势。依次滑动多个点的折线路径,可通过大量点来模拟曲线。performGestures()同时模拟多个滑动动作执行,但好像并没什么用,在图片上双指缩放都实现不了。 -
inputText(text, index=0):向第 index 个输入框中输入文本 text。 -
back()、home()、toggleRecents()、lockScreen():返回键、 home 键、后台任务、锁屏键。 -
select([query]): UI 控件选择器,可选参数属性查询条件。这个用法需要看完 ui_object、ui_selector 这俩模块才能明白。 -
accessibility:无障碍服务实例,常量。包含以下重要属性、方法。enabled:无障碍服务是否启用root(): 获取当前活跃窗口的根节点。若无障碍服务未启动,则会等待服务启动;若无法获取到根节点,则返回null的Promise。rootOrNull: 直接获取当前活跃窗口的根节点。若无障碍服务未启动,或无法获取到根节点,则返回null
综合示例:
"nodejs";
const { accessibility, click, back, home, press, performGesture, toggleRecents } = require('accessibility');
const { showToast } = require('toast');
let enable = false;
async function openService() {
if (accessibility.enabled) {
enable = true;
return;
}
let sure = await dialogs.showConfirmDialog('提示', {
content: '开启Auto.js 无障碍服务权限?',
positive: '开启',
negative: '下次一定',
type: 'overlay'
});
if (sure) {
await accessibility.enableService();
}
enable = sure;
}
async function main() {
await openService();
if (!enable) {
showToast('无权限');
return;
}
console.log('点击:', await click(964, 113));
console.log('长按 5 s:', await press(100, 320, 5000));
// 划一个正方形;
let ret = await performGesture(
[
{ x: 200, y: 200 },
{ x: 500, y: 200 },
{ x: 500, y: 500 },
{ x: 200, y: 500 },
{ x: 200, y: 200 }
],
4000
);
console.log('不同方向滑动:', ret);
// console.log('按下 home 键:', home());
// console.log('按下返回键:', back());
console.log('显示后台程序:', toggleRecents());
}
main();
5. shell 执行命令
-
isRootAvailable():检查设备是否已Root。需要注意的是,设备已Root不代表本应用已获得Root权限。"nodejs"; const { isRootAvailable } = require("shell"); async function main() { const rootAvailable = await isRootAvailable(); console.log(`rootAvailable: ${rootAvailable}`); } main(); -
其他内置了一些使用 adb 点击、滑动等操作,我觉得移动端的脚本开发中没啥需要执行 shell 命令的吧,如果有,那也得要 root 权限。
6. color 颜色
color模块包含了表示颜色的 Color 类,颜色的用途主要体现在后面的多点找色上。
颜色常用十六进制值或 RGB 值来表示,如蓝色可表示为 #0000FF 或(0, 0, 255),分别表示 R、G、B 的通道值,范围都是0-255。
Autojs里前面还用一个A(Alpha 通道) 即 :0xAARRGGBB,一般也用不到 Alpah 通道。
-
Clolor类常用方法fromRGB(r, g, b): 从RGB颜色通道构造一个不透明颜色(alpha通道为255)。fromGray(gray): 根据灰度值构造颜色,alpha通道为255,R、G、B通道均为gray的值。parse(color):解析十六进制字符串构造一个颜色。若解析失败,则返回null。equals(obj):两个颜色是否完全相等,一般使用中不会比较颜色是否严格相同,而是比较是否相似。isSimilarTo(other[, options]): 比较当前颜色是否与另一个颜色相似。可通过 options 参数这设置允许的比较误差,默认为16。
示例:
"nodejs"; const { Color } = require('color'); const red = Color.fromRGB(255, 0, 0); console.log(red.toString()); // Color(0x00ff0000) const red2 = Color.parse('#ff0000'); console.log(red2.toString()); // Color(0xffff0000) const gray = Color.fromGray(100); console.log(gray.toString()); // Color(0xff646464) const gray2 = Color.fromGray(120); console.log(gray2); // Color(0xff787878) // 比较 console.log('是否相等:', red === red2, red.equals(red2)); // false true console.log('是否相似:', gray.isSimilarTo(gray2, { threshold: 21 })); // true,120-100 < 21 -
HSLColor、HSVColor是另外两种表示颜色的类,但 autojs 的支持不够,如有需要还是建议用更强大的 opencv 模块。
7. media_projection 截图
此模块用于请求截图权限,获取截图和监听截图事件。
-
requestScreenCapture(options):请求截图权限,并返回ScreenCapturer对象的Promise,如果用户拒绝则抛出异常。第一次使用该函数会弹出截图权限请求,建议选择“总是允许”。(某些系统没有总是允许选项)
该函数在截图脚本中只需执行一次,而无需每次调用
captureScreen()都调用一次;options参数不用传, 用默认就好。 -
ScreenCapturer实例方法、属性awaitForImageAvailable():等待有截图可用。仅在刚申请到截图权限,未有任何截图可用时,会等待有第一张截图到来。在第一张截图到来的任何时刻调用,会立即返回。nextImage():等待截图并返回,截图结果是个接下来要讲的Image对象
示例:
"nodejs";
const { requestScreenCapture } = require("media_projection");
async function main() {
const capturer = await requestScreenCapture();
const img = await capturer.nextImage();
console.log(img);
// 停止截图
capturer.stop();
}
main();
8. image 图片查找
image 模块主要提供图片读写、灰度化、剪切、缩放、模板匹配等图像处理函数。
(1) 创建 Image
创建 Image 实例除了上面提到的截图,还有以下两种加载方法:
readImage(file): 读取指定路径的文件,异步返回Image对象。若文件不存在或无法解析,则抛出异常。loadImage(url): 加载指定 url 地址的图片(加载网络图片)。
(2) 保存
将 Image 对象写入到本地文件:
-
writeImage(img, file[, quality]): 将图片异步写入到指定的路径,注意带上格式后缀。图片质量,范围0-100。默认值为100。如果文件不存在会被创建;文件存在会被覆盖。
"nodejs"; const { loadImage, writeImage } = require("image"); async function main() { const img = await loadImage('https://game.gtimg.cn/images/lol/v3/logo-public.png'); await writeImage(img, '/sdcard/Download/logo.png'); // 将图片保存到 Download 目录下 } main();
(3) 图像变换
Image 的变换操作实际是操作图像矩阵(多维数组),RGB 三通道即三维数组,ARGB就是四位数组,还有图像降噪用到的高斯模糊、腐蚀、膨胀等操作,都是 opencv 里常用。
通过 Image 类的构造方法,可以看出 autojs v9 的图像操作底层就是通过 opencv 实现的。但 Image 类只封装了我们写脚本常用的几个方法,如果我们要用一些高级 API,就得去 @autojs/opencv 模块去找了,这部分 API 太多,都是直接从 opencv 库映射过来的,所以这部分的文档直接找 opencv 的教程和文档就好。
-
height、width:属性,获取图像的高度、宽度。 -
pixel(x, y):获取图像在位置(x, y)处的颜色,返回一个 Color 对象。在不同屏幕上审查同一点的颜色会有细微差别,所以在比较颜色时,在允许的误差范围内,比较颜色是否相近即可 -
clip(rect):用给定的区域剪切图像,异步返回剪切后的图像,可以理解为抠图。rect参数指定剪切区域(长方形区域),Rect类型 ,构造参数为
(x: number, y: number, width: number, height: number) -
resize(width, height[, interpolation]): 缩放图像大小为(width,height) ,interpolation 指定插值算法,默认为cv.INTER_LINEAR线性插值。 -
scale(fx, fy[, interpolation]): 与 resize 功能一样,只不过参数为原图宽、高的缩放倍数 -
grayscale(): 转为灰度图,常用于降噪处理。此时,Alpah 通道值默认为255,其他三通道值是相同的, 由原图的RGB值按照一定算法计算得出,如:0xff009688 转为 0xff686868
示例:
"nodejs";
const cv = require("@autojs/opencv");
const { delay: sleep } = require('lang');
const { requestScreenCapture } = require('media_projection');
const { writeImage } = require('image');
async function main() {
const capturer = await requestScreenCapture();
await sleep(500);
const img = await capturer.nextImage();
console.log('宽、高:', img.width, img.height);
console.log('位置(100, 100) 颜色信息:', img.pixel(100, 100));
// 裁剪,从左上角(0, 500) 开始截取宽高各为 1000 像素的图片
const rect = new cv.Rect(0, 500, 1000, 1000);
const imgClip = await img.clip(rect);
// 将高度拉长一倍
const imgClipResize = await imgClip.resize(1000, 2000);
const imgClipScale = await imgClip.scale(0.5);
// 转为灰度图
const gray = await img.grayscale();
console.log('灰度图位置(100, 100) 颜色信息:', gray.pixel(100, 100));
// 保存到本地查看
await writeImage(img, '/sdcard/Download/1.png');
await writeImage(imgClip, '/sdcard/Download/2.png');
await writeImage(imgClipResize, '/sdcard/Download/3.png');
await writeImage(imgClipScale, '/sdcard/Download/4.png');
await writeImage(gray, '/sdcard/Download/5.png');
// 停止截图
capturer.stop();
}
main();
(4)全图找色、区域找色
findColor(img, color[, options]): 在图片中寻找颜色color。找到时返回找到的点Point,找不到时返回null。为提高效率、提高容错,option 选项可设置region查找的区域范围和threshold颜色误差,范围为0 ~ 255(越小越相似,0为颜色相等,255为任何颜色都能匹配)。v9 版本中无法指定误差判定算法,可以看一下 v8 版本中的用法。
用这个方法在图片中找寻一个像素点,要求该点的颜色特征必须突出,有多个目标点满足需求时必须指定 region 选项,该方法只能确定首次出现的位置。
示例:
"nodejs";
const { findColor } = require('image');
const { Color } = require('color');
const { delay: sleep } = require('lang');
const cv = require('@autojs/opencv');
const { requestScreenCapture } = require('media_projection');
async function main() {
const capturer = await requestScreenCapture();
await sleep(500);
const img = await capturer.nextImage();
// 全图找色
// const point = await findColor(img, targetColor);
// 区域找色 Rect((x, y, width, height)
const point = await findColor(img, Color.parse('#ffff3725'), {
region: new cv.Rect(0, 0, 1000, 1000),
threshold: 10
});
if (point) {
console.log('找到第一个位置:', point.x, point.y);
} else {
console.log('未找到');
}
// 停止截图
capturer.stop();
}
main();
(5)多点找色
-
findMultiColors(img, colors[, options]): 多点找色。即找到目标色的位置后,在该点偏移一定距离的另一点颜色也满足要求才算找到。- 在图片img中找到颜色firstColor的位置(x0, y0)
- 对于数组colors的每个元素[x, y, color],检查图片img在位置(x + x0, y + y0)上的像素是否是颜色color,是的话返回(x0, y0),否则继续寻找 firstColor 的位置,重新执行第1步
- 整张图片都找不到时返回
null
colors参数为其他参考点的信息,其坐标为第一个点的相对偏移位置
这部分看 v8 版的文档很容易理解,v9暂时没有。
示例:
"nodejs";
const { findMultiColors } = require('image');
const { Color } = require('color');
const { delay: sleep } = require('lang');
const cv = require('@autojs/opencv');
const { requestScreenCapture } = require('media_projection');
async function main() {
const capturer = await requestScreenCapture();
await sleep(500);
const img = await capturer.nextImage();
const point = await findMultiColors(
img,
{
firstColor: Color.parse('#ff3725'),
offsetColors: [
{ color: Color.parse('#f8cad9'), offsetX: -26, offsetY: 44 }, // (x-26, y+44)
{ color: Color.parse('#288deb'), offsetX: -10, offsetY: 0 } // (x-10, y)
]
},
{
region: new cv.Rect(0, 0, 500, 1200), // 限定查找范围,(9.2版本有bug,如果检测全图请设置区域为 0, 0, width-1, height -1)
threshold: 10
}
);
if (point) {
console.log('找到第一个位置:', point.x, point.y);
} else {
console.log('未找到');
}
// 停止截图
capturer.stop();
}
main();
同区域找色,最好还是限定一下 region 查找范围,否则在计算偏移点位置的时候容易超出图片边界,导致程序报错
(6) 找子图
找出一个:
-
findImage(img, template[, options]):找图。在大图片 img 中查找小图片 template 第一次出现的位置,找到时返回子图左上角的位置坐标(Point2),找不到时返回 null。option 选项可设置region查找的区域范围和threshold颜色误差。找到子图的左上角位置后还要再加上自身宽高一半来确定其中心点的位置。
-
findImageInRegion(img, template, x, y[, width, height, threshold]):功能与上个方法一致,只是优化了参数排列。
示例:
"nodejs";
const { readImage, findImage, findImageInRegion } = require('image');
const { Color } = require('color');
const { delay: sleep } = require('lang');
const cv = require('@autojs/opencv');
const { requestScreenCapture } = require('media_projection');
async function main() {
const capturer = await requestScreenCapture();
await sleep(500);
const img = await capturer.nextImage();
const template = await readImage('/sdcard/Download/task.png');
const point = await findImage(img, template, {
threshold: 0.7, // 相似度
region: new cv.Rect(0, 0, img.width / 2, img.height / 2), // 查找范围在图片左上角1/4区域内
level: 2 // 这个参数一般不用设,除非你知道该参数的意义
});
// 等价于
// const point = await findImageInRegion(img, template, 0, 0, img.width, img.height, 0.85);
if (point) {
console.log('子图中心点坐标:x,y=', point.x + template.width / 2, point.y + template.height / 2);
} else {
console.log('未找到');
}
// 停止截图
capturer.stop();
// 回收图片
template.recycle();
}
main();
找出多个:
matchTemplate(src, template, options):在大图中搜索小图所有出现的位置,并返回搜索结果Match[],找不到返回空数组。options找图选项:threshold:图片相似度。取值范围为0~1的浮点数。默认值为0.9。region:找图区域,同findImage。max:找图结果最大数量,默认为5level:默认即可,除非你知道具体影响。
示例:
const capturer = await requestScreenCapture();
const img = await capturer.nextImage();
const template = await readImage('/sdcard/Download/pic.png');
const results = await matchTemplate(img, template, {
threshold: 0.75, // 这些参数按照实际情况调整
max: 3,
level: 1
});
results.forEach((item) => {
console.log('位置 x:', item.point.x, 'y:', item.point.y, '相似度:', item.similarity);
});
9. ui_object 控件对象
本模块目前就包含两个类:UiObject 和 Rect
(1)UiObject 类
首先认识下 UI 控件对象,就是在 autojs 的悬浮窗打开控件审查功能后看到的各种方框,获取到控件对象后就能获取控件的信息,模拟用户操作控件。
稍后在 ui_selector 中会介绍如何获取控件对象以及如何使用,这里我们先看下都有哪些属性和方法。
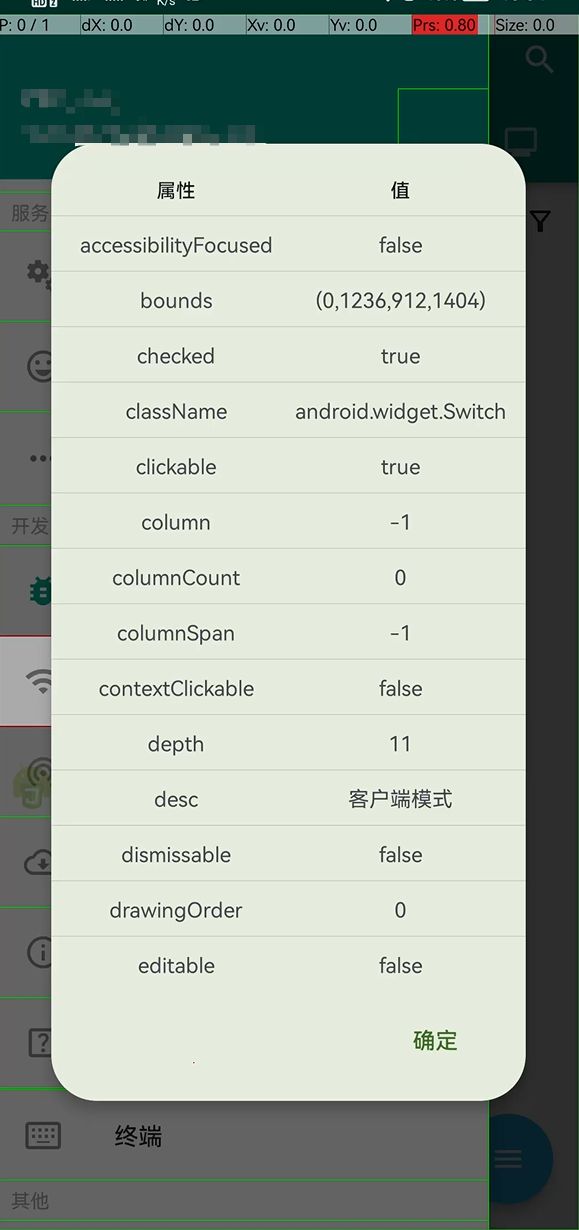
属性
在审查控件中列出的所有 UiObject对象属性都可获取到 :
常用的属性有:
boundsInScreen: 控件在屏幕中的边框位置,返回ui_object.Rect对象。desc、text:控件的文本内容,可用于定位控件id、fullId:id、控件的完整id。用于定位控件,这个 id 值不是唯一的,同一页面可能存在多个 id 相同的控件。className:控件的类名,用于定位控件depth:获取控件相对于页面根结点 root 的深度。用于定位控件indexInParent:获取控件在父控件中的索引。从0开始。children:子控件的列表,返回UiObject数组。可以用于遍历一个控件的子控件,获取到父组件 parent 的所有子组件 children 就相当于获得了所有兄弟组件。root:获取控件所在布局的根布局控件。parent:获取控件的父控件。最外层控件的父控件为 null。drawingOrder:控件在父控件中的绘制顺序。通常可用于区分同一个层次的控件。用于定位控件
方法
包含了用户对控件的所有操作,包括:点击、长按、选定、复制、剪切文、,输入文字,上、下、左、右翻页(可能不起作用),方法都比较简单,请对照文档自行尝试。
click():点击该控件。如果该函数返回false,可用boundsInScreen获取到坐标后用accessibility.click来点击。。longClick():长按该控件。setText(text):输入文本。将输入框内的文字替换为 text,不是追加refresh():刷新控件。当状态发生改变后,不刷新就获取不到最新的属性值。tree():返回该节点及其所有子孙结点的列表
(2) Rect 类
矩形类,表示一个矩形范围。一般不用手动创建,用在 UiObject.boundsInScreen 属性和 ocr.OCRResult 识别结果中。
top、left、bottom、right: 矩形左上角、右下角的坐标。centerX、centerY:矩形中心点的 x、y 坐标,比较常用。width、height: 矩形宽、高。
10. ui_selector 控件选择
上面我们初步认识了 UI 控件的各种属性以及操作,接下来再学习如何在代码中获取到它们。
主要包含两部分内容:查找条件、选择器
选择器配合查找条件可层层筛选出目标控件,复杂的界面可能需要多次筛选才能得到目标控件,如何确定选择条件往往需要大量的实践,还要考虑软件更新后条件是否依然有效。
相比基于坐标的定位方式,基于控件的执行效率会更高,代码兼容性更强,不容易出错;但相对的筛选条件的确定就不如找图、找色简单了。
(1) 查找条件
查找条件大体分三种:简单的属性查,更灵活的控件过滤器和控件提供器。
-
属性查询:即上面
UiObject的各种属性值与预期的值是否满足:!=、< 、<=、=、>、>=、正则表达式。被用于UiSelector.where方法属性值也就 3 种类型:字符串、数字和布尔值。
属性查询基本能满足大多数需求,单个属性查询用一个对象表示:
// 查询 desc 属性值为’无障碍服务‘ 的控件 const query = { desc: '无障碍服务' }如果单个属性无法定位目标控件,可以联合多个属性查询:
// 查询 depth 属性大于10 且 className为android.widget.Switch,且 desc 属性值满足以下正则表达式 const query = { depth: { '>=': 10, '<=': 15 }, className: 'android.widget.Switch', desc: '/.*模式$/' } -
控件过滤器:
(obj: UiObject) => boolean,即一个方法,入参为UiObject对象,方法内部判断该组件是否满足要求,返回true或false。适合复杂点的查询,比如:判断控件
boundsInScreen在屏幕中的大概位置、父子节点关系、多个属性是否同时满足条件等。属性查询在内部也会转为一个条件过滤器,相当于简化了控件过滤器的使用。
-
控件提供器:
() => UiObject[] | Promise也是一个方法,返回UiObject[]类型的数组。限定查询范围在该方法返回的数组中。被用于
uiSelector.from方法,但我觉得没啥用
(2) UiSelector 选择器类
截止我测试使用,这部分 API 应该还在完善中,没找到如何设置搜索算法。。。
创建一个选择器有两种方法:直接 new UiSelector() 或者 accessibility.select(query), 详见下面示例。
-
where(filter):设置查询条件,参数为属性查询或者控件过滤器。对一个 UiSelector 对象多次调用该方法,且传入不同的条件,会使查询条件进行叠加,即所有条件都满足时才会返回结果。 -
from(target: UiSelector | UiObject | UiObject[] | UiObjectProvider): 设置选择控件的来源(查找范围) -
atLeast(min)、atMost(max):设置最少、最多返回的控件数量。 -
maxRetries(max):设置查询重试次数。暂没搞清楚有没有用 -
timeout(timeout):设置查询超时时间,单位毫秒。在设置了atLeast后才生效。以上几个方法都返回this,可链式调用
-
first()、last()、takeAt(i)、all():获取第一个、最后一个、第 i 个、全部符合条件的控件。这 4 个都是异步方法,有结果返回UiObject对象或UiObject列表,无结果返回undefined。有时在 Autojs 里用控件审查无法定位到某一控件,不妨试试打印出
all()所有控件信息,从输出日志里搜搜有没有目标关键字✌。
示例:
我们以 Autojs 的左侧菜单页面为例,实现功能:
- 搜索客户端模式和服务器模式两个开关控件
- 找到这两个开关后判断是否都已打开,若处于关闭状态则模拟点击打开。
通过审查控件发现,关键字都在控件的 desc 属性上。
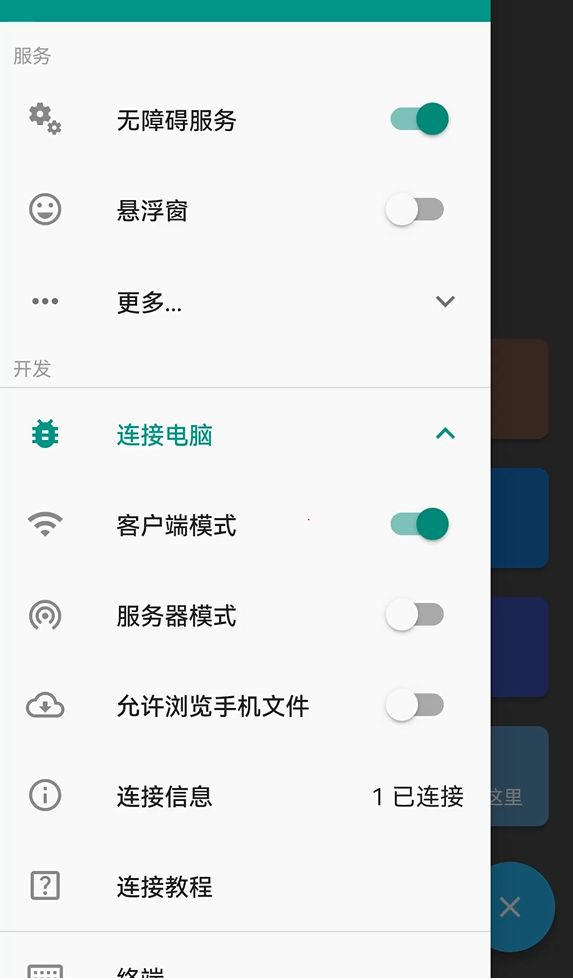
(以下代码仅供演示学习,不考虑是否合理)
'nodejs';
const { showConfirmDialog } = require('dialogs');
const { showToast } = require('toast');
const { delay: sleep } = require('lang');
const { accessibility, select } = require('accessibility');
const { UiSelector } = require('ui_selector');
let enable = false;
async function openService() {
if (accessibility.enabled) {
enable = true;
return;
}
let sure = await showConfirmDialog('提示', {
content: '开启Auto.js 无障碍服务权限?',
positive: '开启',
negative: '下次一定',
type: 'overlay'
});
if (sure) {
await accessibility.enableService();
}
enable = sure;
}
/**
* 打开客户端模式
*/
async function openClientMode(switchButton, serverIP) {
if (!switchButton.checked) {
await switchButton.click();
// 查找 ip 输入框
let selector = new UiSelector()
.where({
className: 'android.widget.EditText'
})
.atLeast(1)
.timeout(2000);
const inputBox = await selector.first();
// 模拟输入服务端 IP 地址
inputBox && inputBox.setText(serverIP);
await clickConfirmButton();
await sleep(500);
switchButton.refresh();
}
console.log('打开客户端模式:', switchButton.checked);
}
/**
* 打开服务端模式
*/
async function openServerMode(switchButton) {
if (!switchButton.checked) {
await switchButton.click();
await clickConfirmButton();
await sleep(500);
// 刷新控件
switchButton.refresh();
}
console.log('打开服务端模式:', switchButton.checked);
}
/**
* 点击确定
*/
async function clickConfirmButton() {
// 也可通过 select 方法创建
const selector = await select({
className: 'android.widget.Button',
desc: '确定'
})
.atLeast(1)
.timeout(2000);
const confirmButton = await selector.first();
confirmButton && confirmButton.click();
}
async function main() {
await openService();
if (!enable) {
showToast('无权限');
return;
}
const myPCAddress = '192.168.1.11';
// 这里只是演示查询条件用法,实际可以优化
const query = {
className: 'android.widget.Switch',
depth: {
'>=': 10,
'<': 14
},
desc: /.*模式$/
};
const expectCount = 2;
// 刚创建的 UiSelector 必须设置查询条件或者控件过滤器
// 要获取全部组件,可传个空对象 {}
let selector = new UiSelector().where(query).atMost(expectCount);
const results = await selector.all();
if (results.length !== expectCount) {
console.error('查询条件有误');
return;
}
await openClientMode(results[0], myPCAddress);
await openServerMode(results[1]);
}
main();
11. ocr 文字识别
v9 版中集成了 ocr 功能,实际测试效果也还不错,就是文档还不全,参数作用看不太懂。
基础用法
-
createOCR([options): 创建 ocr 实例,参数解释未知。ocr 实例的方法:
-
detect(image):检测 image 对象中的所有文字,返回OCRResult类型数组,未识别到文字返回空数组。OCRResult的方法和属性bounds:文字的坐标,ui_object.Rect类型confidence:置信度text: 文字内容click():模拟点击文字,坐标由 bounds 属性决定
-
-
release():释放资源。
使用建议:
detect()方法的参数 imgage 传整个屏幕的截图即可,如果是经过image.clip()截取的部分图片,则识别结果中的bounds属性是截取后小图片中的位置,可能需要转换才能得到文字在原图中的位置。
示例:
'nodejs';
const cv = require('@autojs/opencv');
const { delay: sleep } = require('lang');
const { requestScreenCapture } = require('media_projection');
const ui_object = require('ui_object');
const { createOCR } = require('ocr');
async function main() {
const capturer = await requestScreenCapture();
const ocr = await createOCR();
await sleep(500);
const img = await capturer.nextImage();
// 演示缩小检测区域,从左上角(20, 160)截取部分图片进行ocr识别(建议直接检测全图)
const offsetX = 20;
const offsetY = 160;
const temp = await img.clip(new cv.Rect(offsetX, offsetY, img.width - offsetX, 600)); // 注意不要超出范围
const result = await ocr.detect(temp);
// 过滤掉置信度 < 0.6 的,按文字出现的位置从左到右排序
result
.filter((item) => item.confidence > 0.6)
.sort((a, b) => a.bounds.left <= b.bounds.left)
.forEach((item) => {
console.log('【文字】', item.text, '【置信度】', item.confidence, '【位置】', item.bounds);
if (item.text.trim() === '邮件') {
// 点击该文字前将其调整到大图的位置
const { top, left, bottom, right } = item.bounds;
item.bounds = new ui_object.Rect(left + offsetX, top + offsetY, right + offsetX, bottom + offsetY);
item
.click() // 点击文字在原图中的位置
.then((ret) => console.log('点击结果:', ret))
.catch((e) => console.log(e));
// 等价于:
// const { click } = require('accessibility');
// click(item.bounds.centerX + offsetX, item.bounds.centerY + offsetY).then((e) => console.log('点击结果:', e));
}
});
ocr.release();
// 停止截图
capturer.stop();
}
main();
OCR & 图像预处理
有时文字的周围有许多图案,会影响识别准确度,我们可以先对图像进行简单的处理,降低干扰。
下图是某游戏中的一部分截图,不同的 OCR 识别模型识别出的文字和准确度是有差别的,优秀的ocr模型抗干扰能力强一些,但也不能保证完全不会出错。要想降低出错的概率,图像预处理是不可或缺的,目标就是将文字与背景相分离,去除噪点,尽量降低文字周围的干扰。

图1
观察上图文字与背景,文字颜彩与白色接近,而背景有绿、橙、红三种颜色,且文字下边两条斜边与文字颜色相近,我用二值化函数 cv::threshold() 尝试了各种参数都没能将其消除,中间又加了灰度处理才得到预期的效果。
虽然这个例子比较简单,涉及的图像处理也不多,但想要将原始图片处理成理想状态,需要要先学习的部分理论知识,外加不断调参。
'nodejs';
const { writeImage, readImage, Image } = require('image');
const { createOCR } = require('ocr');
const cv = require('@autojs/opencv');
async function main() {
let img = await readImage('./game.png');
// 灰度处理
img = await img.grayscale();
// 二值化,类型 THRESH_BINARY_INV
const mat = await img.mat.thresholdAsync(230, 255, cv.THRESH_BINARY_INV);
await writeImage(img, '/sdcard/Download/game-gray.jpg');
img = new Image(mat);
await writeImage(img, '/sdcard/Download/game-thresh.jpg');
const ocr = await createOCR();
console.log(await ocr.detect(img));
}
main();
二值化函数及参数说明参考:threshold函数的使用
经过处理后文字与背景就完全分开了,再进行 ocr 识别就不会出错了。(还识别错误就换个ocr模型吧)

图2

图3
其他模块
- globals:控制程序执行和退出、提供Java交互的API、获取
androidContext等,上面示例中也用到过, - engines:获取当前运行环境信息;运行、控制其他脚本、互相通信
- floating_window:编写悬浮窗样式,后期为自己的脚本设计一个悬浮窗,方便使用
- lang:lang提供语言相关的API ,值得一看,或许用的上
- notification:触发、监听通知栏
- settings:控制一些内部设置,比如稳定模式、前台服务等。
- Context | Android Developers (google.cn)
- 应用快捷方式概览 | Android 开发者 | Android Developers
- AutoX