操作系统调度
只要有两个或者多个进程处于就绪状态就有可能出现竞争CPU的状况。如果只有一个CPU可用,那么就必须选择下一个要运行的进程。在操作系统中完成选择的工作称之为调度程序,该程序使用的算法成为调度算法。
进程行为
几乎所有的进程都是I/O请求和计算(磁盘和网络)交替突发的。
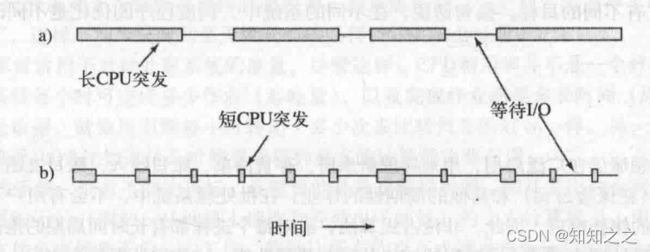
上图a-》计算密集型进程。
上图b-》I/O密集型进程。
何时调度
- 创建一个新进程之后,要决定是运行父进程还是子进程。
- 在一个进程退出时必须要做出调度决策。
- 当一个进程阻塞在I/O和信号量上或者由于其他原因阻塞时,必须选择另一个进程运行。
- 在一个I/O中断发生时,必须做出调度决策。
调度算法
调度算法分类
在不同的操作系统中,调度程序的优化是不同的。可划分为三种环境:
- 批处理。
- 交互式。
- 实时。
调度算法的目标

所有系统
相似的进程应该得到相似的服务,换言之就是给每个进程公平的CPU时间片段。
保证规定的策略能够强制执行。
保持系统的所有部分尽可能忙碌。
系统工作状态三个指标:
吞吐量:系统每小时完成的作业数
周转时间:从一个批处理作业提交时间开始直到该作业完成时刻为止的统计平均时间。该数据度量了用户要得到输出所需的平均等待时间,规则就是:小就是好的。
CPU利用率:CPU利用率尽可能的高
批处理系统
- 先来先服务
使用此算法,将按照请求顺序为进程分配 CPU。最基本的,会有一个就绪进程的等待队列。当第一个任务从外部进入系统时,将会立即启动并允许运行任意长的时间。它不会因为运行时间太长而中断。当其他作业进入时,它们排到就绪队列尾部。当正在运行的进程阻塞,处于等待队列的第一个进程就开始运行。当一个阻塞的进程重新处于就绪态时,它会像一个新到达的任务,会排在队列的末尾,即排在所有进程最后。
- 最短作业优先
当输入队列中有若干个同等重要的作业被启动时,调度程序应使用最短作业优先算法。
4个作业A、B、C、D运行时间分别是8、4、4、4。

若按上图中顺序运行,则 A、B、C、D周转时间为8、12、16、20,平均周转时间为14分钟。
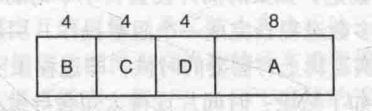
按最短作业优先算法, 则 A、B、C、D周转时间为4、8、12、20,平均周转时间为11分钟。
假设有 4 个作业的情况,其运行时间分别为 a、b、c、d。第一个作业在时间 a 结束,第二个在时间 a + b 结束,以此类推。平均周转时间为 (4a + 3b + 2c + d) / 4 。显然 a 对平均值的影响最大,所以 a 应该是最短优先作业,其次是 b,然后是 c ,最后是 d 它就只能影响自己的周转时间了。
- 最短剩余时间优先
使用这个算法,调度程序总是选择剩余运行时间最短的那个进程运行。当一个新作业到达时,其整个时间同当前进程的剩余时间做比较。如果新的进程比当前运行进程需要更少的时间,当前进程就被挂起,而运行新的进程。这种方式能够使短期作业获得良好的服务。
交互式系统
- 轮转调度
每个进程都会被分配一个时间片段,在这个时间片内允许进程运行。如果时间片结束时进程还在运行的话,则剥夺CPU并将其分配给另一个进程。如果进程在时间片结束前阻塞或结束,则 CPU 立即进行切换。轮询算法比较容易实现。调度程序所做的就是维护一个可运行进程的列表,就像下图中的 a,当一个进程用完时间片后就被移到队列的末尾,就像下图的 b。
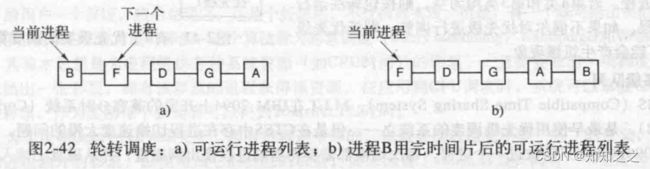
如果时间片段设置的太短会导致过多的进程切换,降低CPU效率;如果设置太长又有可能引起对短的交互请求响应时间变成,将时间设置为20-50ms通常是比较合理折中。
- 优先级调度
事实情况是不是所有的进程都是优先级相等的。优先级调度的基本思想很明确,每个进程都被赋予一个优先级,优先级高的进程优先运行。
但是也不意味着高优先级的进程能够永远一直运行下去,调度程序会在每个时钟中断期间降低当前运行进程的优先级。如果此操作导致其优先级降低到下一个最高进程的优先级以下,则会发生进程切换。或者,可以为每个进程分配允许运行的最大时间间隔。当时间间隔用完后,下一个高优先级的进程会得到运行的机会。
- 多级调度
为CPU密集型进程设置较长的时间片段比频繁地分给它们很短的时间片段更高效(减少进程切换次数)。长时间片段的进程又会影响到响应时间,其解决方法是设立优先级类。属于最高优先级的进程运行一个时间片段,属于次高优先级的进程运行两个时间片段,以此类推。当一个进程用完时间片段之后被移到下一类。
- 最短进程优先
对于批处理系统而言,由于最短作业优先常常伴随着最短响应时间,所以如果能够把它用于交互进程,那将是非常好的。在某种程度上,的确可以做到这一点。交互进程通常遵循下列模式:等待命令、执行命令、等待命令、执行命令,如此不断反复。如果我们将每一条命令的执行看作是一个独立的“作业”,则我们可以通过首先运行最短的作业来使响应时间最短。这里惟一的问题是如何从当前可运行进程中找出最短的那一个进程。
一种办法是根据进程过去的行为进行推测,并执行估计运行时间最短的那一个。假设某个终端上每条命令的估计运行时间为T0。现在假设测量到其下一次运行时间为T1。可以用这两个值的加权和来改进估计时间,即aT0 + (1-a)T1。通过选择a的值,可以决定是尽快忘掉老的运行时间,还是在一段长时间内始终记住它们。当a = 1/2时,可以得到如下序列:
T0,T0/2 + T1/2,T0/4 + T1/4 + T2/2, T0/8 + T1/8 + T2/4 + T3/2(CPU执行时间估计值)
可以看到,在三轮过后,T0在新的估计值中所占的比重下降到1/8。
有时把这种通过当前测量值和先前估计值进行加权平均而得到下一个估计值的技术称作老化(aging)。它适用于许多预测值必须基于先前值的情况。老化算法在a = 1/2时特别容易实现,只需将新值加到当前估计值上,然后除以2(即右移一位)。
- 保证调度
向用户作出明确的性能保证,然后去实现它。一种很实际并很容易实现的保证是:若用户工作时有n个用户登录,则用户将获得CPU处理能力的1/n。类似地,在一个有n个进程运行的单用户系统中,若所有的进程都等价,则每个进程将获得1/n的CPU时间。看上去足够公平了。
为了实现所做的保证,系统必须跟踪各个进程自创建以来已使用了多少CPU时间。然后它计算各个进程应获得的CPU时间,即自创建以来的时间除以n。由于各个进程实际获得的CPU时间是已知的,所以很容易计算出真正获得的CPU时间和应获得的CPU时间之比。比率为0.5说明一个进程只获得了应得时间的一半,而比率为2.0则说明它获得了应得时间的2倍。于是该算法随后转向比率最低的进程,直到该进程的比率超过它的最接近竞争者为止。
- 彩票调度
向进程提供各种系统资源(如CPU时间)的彩票。一旦需要做出一项调度决策时,就随机抽出一张彩票,拥有该彩票的进程获得该资源。例如在应用到CPU调度时,系统可以掌握每秒钟50次的一种彩票,作为奖励每个获奖者可以得到20ms的CPU时间。
- 公平分享调度
如果用户 1 启动了 9 个进程,而用户 2 启动了一个进程,使用轮转或相同优先级调度算法,那么用户 1 将得到 90 % 的 CPU 时间,而用户 2 将之得到 10 % 的 CPU 时间。
为了阻止这种情况的出现,一些系统在调度前会把进程的拥有者考虑在内。在这种模型下,每个用户都会分配一些CPU 时间,而调度程序会选择进程并强制执行。因此如果两个用户每个都会有 50% 的 CPU 时间片保证,那么无论一个用户有多少个进程,都将获得相同的 CPU 份额。
实时系统
实时系统是一种必须提供时序可预测性的系统,应用范围广和特性不同于一般计算机,因此调度算法也别出一格。前面的算法只要考虑的是平均响应时间和系统吞吐率的问题,而实时系统则必须考虑每个具体的任务响应时间必须符合要求,即每个任务必须要在什么时间之前完成,而无需考虑如何降低整个系统响应时间或吞吐率。
- 最早截止时间优先EDF(Earliest Deadline First)
根据任务的开始截止时间来确定任务的优先级。截止时间越早,其优先级越高。(开始截至时间为t:在t时刻之前该任务必须开始执行)
- 系统保持一个实时任务就绪队列
- 队列按各任务截止时间的早晚排序
- 调度程序总是选择就绪队列中的第一个任务,分配处理机使之投入运行。
EDF在抢占式和非抢占式的区别就是,抢占式就是,当新任务A来到的时候,如果A的截止时间比正在执行的任务B的截止时间提前,那么就中断B,抢夺处理机控制权,转而运行A。
-
最低松弛度优先LLF(Least Laxity First)
根据任务紧急(或松弛)的程度,来确定任务的优先级。任务的紧急程度越高(松弛度值越小),优先级就越高。
松弛度= 截止完成时间 – 还需执行时间 - 当前时间
可理解为当前时刻到开始截止时刻间的差距,随着时间的推进,这个差值逐渐变小,任务越来越紧迫。
线程调度
当若干进程都有多个线程时,就存在两个层次的并行:进程和线程。在这样的系统中调度处理有着本质的区别,这取决于支持的是用户级线程还是内核级线程。
用户级线程调度
由于内核不知道线程的存在,所以内核还是选取一个进程A,给予A时间片段,A进程中的线程调度取决于A进程的线程调度程序,如果A进程中的线程用完了进程的时间片段,内核就会切换到另一个进程运行。
内核级线程调度
内核选择一个特定的线程运行, 不用考虑该线程属于哪一个进程,赋予被选择的线程一个时间片段,如果超过了该时间片段就会强制挂起该线程。