想找工作,这一篇15w字数+的文章帮你解决
文章目录
- 前言
- 一 专业技能
-
- 1. 熟悉GoLang语言
-
- 1.1 Slice
- 1.2 Map
- 1.3 Channel
- 1.4 Goroutine
- 1.5 GMP调度
- 1.6 垃圾回收机制
- 1.7 其他知识点
- 2. 掌握Web框架Gin和微服务框架Micro
-
- 2.1 Gin框架
- 2.2 Micro框架
- 2.3 Viper
- 2.4 Swagger
- 2.5 Zap
- 2.6 JWT
- 3. 熟悉使用 MySQL 数据库
-
- 3.1 索引
- 3.2 事务
- 3.3 存储引擎
- 3.4 锁机制
- 3.5 其他面试题
- 4. 熟悉计算机网络
-
- 4.1 TCP/IP协议
- 4.2 HTTP/HTTPS协议
- 4.3 TCP三次握手/四次挥手
- 4.4 IP协议
- 4.5 其他面试题
- 5. 熟悉操作系统
-
- 5.1 进程、线程管理
- 5.2 内存管理
- 5.3 进程调度算法
- 5.4 磁盘调度算法
- 5.5 页面置换算法
- 5.6 网络系统
- 5.7 锁
- 5.8 其他面试题
- 6. 熟悉Redis的基本使用
-
- 6.1 基本数据结构
- 6.2 数据持久化
- 6.3 高可用
- 6.4 缓存
- 7.熟悉使用 Python 语言
-
- 7.1 Django框架
- 7.2 爬虫
- 7.3 数据分析
- 7.4 机器学习算法
- 7.5 Python语言
- 8. 了解前端技术
-
- 8.1 Html/Css
- 8.2 JavaScript
- 8.3 Vue框架
- 二 项目经历
-
- 1. 基于机器学习的冬奥会智能分析与预测系统
-
- 1.1 项目描述
- 1.2 工作内容
- 1.3 面试问题
- 2. 基于微服务的通用账户功能系统
-
- 2.1 项目描述
- 2.2 工作内容
- 2.3 面试问题
文章字数大约15.5万字,阅读大概需要8.6小时,建议收藏后慢慢阅读!!!
前言
本篇文章是博主自己找工作时收集总结的,涵盖了Go语言、MySQL数据库、计算机网络、操作系统、Redis、Python语言等多种面经,主要是根据博主自己的简历来制作的,编写不易,先赞后看。
话不多说,开搞!
一 专业技能
1. 熟悉GoLang语言
1.1 Slice
-
Slice底层实现原理
切片是基于数组实现的,它的底层是数组,它自己本身非常小,可以理解为对底层数组的抽象。因为基于数组实现,所以它的底层的内存是连续分配的,效率非常高,还可以通过索引获得数据,可以迭代以及垃圾回收优化。 切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内。切片本身是一 个只读对象,其工作机制类似数组指针的一种封装。
切片对象非常小,是因为它是只有 3 个字段的数据结构:
-
指向底层数组的指针
-
切片的长度
-
切片的容量
-
-
Slice扩容机制
在使用 append 向 slice 追加元素时,若 slice 空间不足则会发生扩容,扩容会重新分配一块更大的内存,将原 slice 拷贝到新 slice ,然后返回新 slice。扩容后再将数据追加进去。
扩容操作只对容量,扩容后的 slice 长度不变,容量变化规则如下:
- 若 slice 容量小于1024个元素,那么扩容的时候slice的cap就翻番,乘以2;一旦元素个数超过1024个元素,增长因子就变成1.25,即每次增加原来容量的四分之一。
- 若 slice 容量够用,则将新元素追加进去,slice.len++,返回原 slice
- 若 slice 容量不够用,将 slice 先扩容,扩容得到新 slice,将新元素追加进新 slice,slice.len++,返回新 slice。
-
Slice与数组区别
array是固定长度的数组,使用前必须确定数组长度,是值类型。
slice是一个引用类型,是一个动态的指向数组切片的指针。
slice是一个不定长的,总是指向底层的数组array的数据结构,可以动态扩容。创建方式不一样,Slice使用make创建或者根据数组创建。
作为函数参数时,数组传递的是数组的副本,而slice传递的是指针。
1.2 Map
-
Map底层实现原理
Golang 中 map 的底层实现是一个散列表,因此实现 map 的过程实际上就是实现散表的过程。在这个散列表中,主要出现的结构体有两个,一个叫 hmap(a header for a go map),一个叫 bmap(a bucket for a Go map,通常叫其 bucket)。
hmap 哈希表
hmap是Go map的底层实现,每个hmap内都含有多个bmap(buckets桶、oldbuckets旧桶、overflow溢出桶),既每个哈希表都由多个桶组成。-
buckets
buckets是一个指针,指向一个bmap数组,存储多个桶。 -
oldbuckets
oldbuckets是一个指针,指向一个bmap数组,存储多个旧桶,用于扩容。 -
overflow
overflow是一个指针,指向一个元素个数为2的数组,数组的类型是一个指针,指向一个slice,slice的元素是桶(bmap)的地址,这些桶都是溢出桶。为什么有两个?因为Go map在哈希冲突过多时,会发生扩容操作。[0]表示当前使用的溢出桶集合,[1]是在发生扩容时,保存了旧的溢出桶集合。overflow存在的意义在于防止溢出桶被gc。
bmap 哈希桶
bmap是一个隶属于hmap的结构体,一个桶(bmap)可以存储8个键值对。如果有第9个键值对被分配到该桶,那就需要再创建一个桶,通过overflow指针将两个桶连接起来。在hmap中,多个bmap桶通过overflow指针相连,组成一个链表。 -
-
Map进行有序的排序
map每次遍历,都会从一个随机值序号的桶,再从其中随机的cell开始遍历,并且扩容后,原来桶中的key会落到其他桶中,本身就会造成失序
如果想顺序遍历map,先把key放到切片排序,再按照key的顺序遍历map。
或者可以先把map中的key,通过sort包排序,再遍历map。
-
map 为什么是不安全的
Go map 默认是并发不安全的,同时对 map 进行并发读写的时,程序会 panic,原因如下:Go 官方经过长时间的讨论,认为 map 适配的场景应该是简单的(不需要从多个 gorountine 中进行安全访问的),而不是为了小部分情况(并发访问),导致大部分程序付出锁的代价,因此决定了不支持。
map 在扩缩容时,需要进行数据迁移,迁移的过程并没有采用锁机制防止并发操作,而是会对某个标识位标记为 1,表示此时正在迁移数据。如果有其他 goroutine 对 map 也进行写操作,当它检测到标识位为 1 时,将会直接 panic。
如果想实现map线程安全,有两种方式:
方式一:使用读写锁
map+sync.RWMutex方式二:使用golang提供的
sync.Map -
Map扩容策略
扩容时机:
向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容
扩容条件:
-
超过负载 map元素个数 > 6.5(负载因子) * 桶个数
-
溢出桶太多
当桶总数<2^15时,如果溢出桶总数>=桶总数,则认为溢出桶过多
当桶总数>215时,如果溢出桶总数>=215,则认为溢出桶过多
扩容机制:
-
双倍扩容:针对条件1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。
-
等量扩容:针对条件2,并不扩大容量,buckets数量维持不变,重新做一遍类似双倍扩容的搬迁动作,把松散的键值对重新排列一次,使得同一个 bucket 中的 key 排列地更紧密,节省空间,提高 bucket 利用率,进而保证更快的存取。
-
渐进式扩容:
插入修改删除key的时候,都会尝试进行搬迁桶的工作,每次都会检查oldbucket是否nil,如果不是nil则每次搬迁2个桶,蚂蚁搬家一样渐进式扩容
-
-
Map和Slice区别
- 数组:数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。声明方式:var a [3]int
- slice(切片):Slice(切片)代表变长的序列,序列中每个元素都有相同的类型,slice的语法和数组很像,只是没有固定长度而已。
- map:在Go语言中,一个map就是一个哈希表的引用,是一个无序的key/value对的集合
-
Map总结
- map是引用类型
- map遍历是无序的
- map是非线程安全的
- map的哈希冲突解决方式是链表法
- map的扩容不是一定会新增空间,也有可能是只是做了内存整理
- map的迁移是逐步进行的,在每次赋值时,会做至少一次迁移工作
- map中删除key,有可能导致出现很多空的kv,这会导致迁移操作,如果可以避免,尽量避免
1.3 Channel
-
介绍一下Channel(有缓冲和无缓冲)
Go 语言中,不要通过共享内存来通信,而要通过通信来实现内存共享。Go 的CSP(Communicating Sequential Process)并发模型,中文可以叫做通信顺序进程,是通过 goroutine 和 channel 来实现的。
所以 channel 收发遵循先进先出 FIFO,分为有缓存和无缓存,channel 中大致有 buffer(当缓冲区大小部位 0 时,是个 ring buffer)、sendx 和 recvx 收发的位置(ring buffer 记录实现)、sendq、recvq 当前 channel 因为缓冲区不足 而阻塞的队列、使用双向链表存储、还有一个 mutex 锁控制并发、其他原属等。
// 无缓冲的channel由于没有缓冲发送和接收需要同步 ch := make(chan int) //有缓冲channel不要求发送和接收操作同步 ch := make(chan int, 2)channel 无缓冲时,发送阻塞直到数据被接收,接收阻塞直到读到数据;channel有缓冲时,当缓冲满时发送阻塞,当缓冲空时接收阻塞。
-
Channel实现原理
channel 内部维护了两个 goroutine 队列,一个是待发送数据的 goroutine 队列,另一个是待读取数据的 goroutine 队列。
每当对 channel 的读写操作超过了可缓冲的 goroutine 数量,那么当前的 goroutine 就会被挂到对应的队列上,直到有其他 goroutine 执行了与之相反的读写操作,将它重新唤起。
-
Channel读写流程
向 channel 写数据:
若等待接收队列 recvq 不为空,则缓冲区中无数据或无缓冲区,将直接从 recvq 取出 G ,并把数据写入,最后把该 G 唤醒,结束发送过程。
若缓冲区中有空余位置,则将数据写入缓冲区,结束发送过程。
若缓冲区中没有空余位置,则将发送数据写入 G,将当前 G 加入 sendq ,进入睡眠,等待被读 goroutine 唤醒。
从 channel 读数据
若等待发送队列 sendq 不为空,且没有缓冲区,直接从 sendq 中取出 G ,把 G 中数据读出,最后把 G 唤醒,结束读取过程。
如果等待发送队列 sendq 不为空,说明缓冲区已满,从缓冲区中首部读出数据,把 G 中数据写入缓冲区尾部,把 G 唤醒,结束读取过程。
如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程。
将当前 goroutine 加入 recvq ,进入睡眠,等待被写 goroutine 唤醒。
关闭 channel
1.关闭 channel 时会将 recvq 中的 G 全部唤醒,本该写入 G 的数据位置为 nil。将 sendq 中的 G 全部唤醒,但是这些 G 会 panic。
panic 出现的场景还有:
- 关闭值为 nil 的 channel
- 关闭已经关闭的 channel
- 向已经关闭的 channel 中写数据
-
Channel为什么能做到线程安全
Channel 可以理解是一个先进先出的队列,通过管道进行通信,发送一个数据到Channel和从Channel接收一个数据都是原子性的。不要通过共享内存来通信,而是通过通信来共享内存,前者就是传统的加锁,后者就是Channel。设计Channel的主要目的就是在多任务间传递数据的,本身就是安全的。
-
Channel是同步进行还是异步的(Channel的三种状态)
Channel是异步进行的, channel存在3种状态:
- nil,未初始化的状态,只进行了声明,或者手动赋值为nil
- active,正常的channel,可读或者可写
- closed,已关闭,千万不要误认为关闭channel后,channel的值是nil
操作 一个零值nil通道 一个非零值但已关闭的通道 一个非零值且尚未关闭的通道 关闭 产生恐慌 产生恐慌 成功关闭 发送数据 永久阻塞 产生恐慌 阻塞或者成功发送 接收数据 永久阻塞 永不阻塞 阻塞或者成功接收 - 给一个 nil channel 发送数据,造成永远阻塞
- 从一个 nil channel 接收数据,造成永远阻塞
- 给一个已经关闭的 channel 发送数据,引起 panic
- 从一个已经关闭的 channel 接收数据,如果缓冲区中为空,则返回一个零值
- 无缓冲的 channel 是同步的,而有缓冲的 channel 是非同步的
- 关闭一个 nil channel 将会发生 panic

1.4 Goroutine
-
进程、线程和协程的区别
-
进程: 进程是具有一定独立功能的程序,进程是系统资源分配和调度的最小单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
-
线程: 线程是进程的一个实体,线程是内核态,而且是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
-
协程: 协程是一种用户态的轻量级线程,协程的调度完全是由用户来控制的。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
-
线程和协程的区别
- 线程切换需要陷入内核,然后进行上下文切换,而协程在用户态由协程调度器完成,不需要陷入内核,这样代价就小了。
- 协程的切换时间点是由调度器决定,而不是由系统内核决定的,尽管它们的切换点都是时间片超过一定阈值,或者是进入I/O或睡眠等状态时。
- 基于垃圾回收的考虑,Go实现了垃圾回收,但垃圾回收的必要条件是内存位于一致状态,因此就需要暂停所有的线程。如果交给系统去做,那么会暂停所有的线程使其一致。对于Go语言来说,调度器知道什么时候内存位于一致状态,所以也就没有必要暂停所有运行的线程。
-
-
介绍一下Goroutine
Goroutine 是一个与其他 goroutines 并行运行在同一地址空间的 Go 函数或方法。
goroutine的概念类似于线程,但 goroutine是由Go的运行时(runtime)调度和管理的。Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。它在语言层面已经内置了调度和上下文切换的机制。
goroutine是Go并发设计的核心,也叫协程,它比线程更加轻量,因此可以同时运行成千上万个并发任务。在Go语言中,每一个并发的执行单元叫作一个goroutine。我们只需要在调用的函数前面添加go关键字,就能使这个函数以协程的方式运行。
-
context包结构原理和用途
Context(上下文)是Golang应用开发常用的并发控制技术 ,它可以控制一组呈树状结构的goroutine,每个goroutine拥有相同的上下文。Context 是并发安全的,主要是用于控制多个协程之间的协作、取消操作。
Context 只定义了接口,凡是实现该接口的类都可称为是一种 context。
- 「Deadline」 方法:可以获取设置的截止时间,返回值 deadline 是截止时间,到了这个时间,Context 会自动发起取消请求,返回值 ok 表示是否设置了截止时间。
- 「Done」 方法:返回一个只读的 channel ,类型为 struct{}。如果这个 chan 可以读取,说明已经发出了取消信号,可以做清理操作,然后退出协程,释放资源。
- 「Err」 方法:返回Context 被取消的原因。
- 「Value」 方法:获取 Context 上绑定的值,是一个键值对,通过 key 来获取对应的值。
-
goroutine调度
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
-
- G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。
-
- P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。
-
- M(machine)是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
-
-
如何避免Goroutine泄露和泄露场景
gorouinte 里有关于 channel 的操作,如果没有正确处理 channel 的读取,会导致 channel 一直阻塞住, goroutine 不能正常结束
-
waitgroup 用法和原理
waitgroup 内部维护了一个计数器,当调用
wg.Add(1)方法时,就会增加对应的数量;当调用wg.Done()时,计数器就会减一。直到计数器的数量减到 0 时,就会调用
runtime_Semrelease 唤起之前因为wg.Wait()而阻塞住的 goroutine。使用方法:
- main 协程通过调用 wg.Add(delta int) 设置 worker 协程的个数,然后创建 worker 协程;
- worker 协程执行结束以后,都要调用 wg.Done();
- main 协程调用 wg.Wait() 且被 block,直到所有 worker 协程全部执行结束后返回。
实现原理:
-
WaitGroup 主要维护了 2 个计数器,一个是请求计数器 v,一个是等待计数器 w,二者组成一个 64bit 的值,请求计数器占高 32bit,等待计数器占低 32bit。
-
每次 Add 执行,请求计数器 v 加 1,Done 方法执行,请求计数器减 1,v为0 时通过信号量唤醒 Wait()。
1.5 GMP调度
-
GMP是什么
- G(Goroutine):即Go协程,每个go关键字都会创建一个协程。
- M(Machine):工作线程,在Go中称为Machine,数量对应真实的CPU数(真正干活的对象)。
- P(Processor):处理器(Go中定义的一个摡念,非CPU),包含运行Go代码的必要资源,用来调度 G 和 M 之间的关联关系,其数量可通过 GOMAXPROCS() 来设置,默认为核心数。
M必须拥有P才可以执行G中的代码,P含有一个包含多个G的队列,P可以调度G交由M执行。
优先从 P 的本地队列获取 goroutine 来执行;如果本地队列没有,从全局队列获取,如果全局队列也没有,会从其他的 P 上偷取 goroutine。
-
GMP goroutine调度策略
- 队列轮转:P 会周期性的将G调度到M中执行,执行一段时间后,保存上下文,将G放到队列尾部,然后从队列中再取出一个G进行调度。除此之外,P还会周期性的查看全局队列是否有G等待调度到M中执行。
- 系统调用:当G0即将进入系统调用时,M0将释放P,进而某个空闲的M1获取P,继续执行P队列中剩下的G。M1的来源有可能是M的缓存池,也可能是新建的。
- 当G0系统调用结束后,如果有空闲的P,则获取一个P,继续执行G0。如果没有,则将G0放入全局队列,等待被其他的P调度。然后M0将进入缓存池睡眠。
-
调度器的设计策略
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
- work stealing 机制
- 当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
- hand off 机制
- 当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行:GOMAXPROCS 设置 P 的数量,最多有 GOMAXPROCS 个线程分布在多个 CPU 上同时运行。GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
抢占:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
全局 G 队列:,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G。
- work stealing 机制
-
CSP 模型是“以通信的方式来共享内存”,不同于传统的多线程通过共享内存来通信。用于描述两个独立的并发实体通过共享的通讯 channel (管道)进行通信的并发模型。
-
两种抢占式调度
协作式的抢占式调度
在 1.14 版本之前,程序只能依靠 Goroutine 主动让出 CPU 资源才能触发调度,存在问题
-
某些 Goroutine 可以长时间占用线程,造成其它 Goroutine 的饥饿
-
垃圾回收需要暂停整个程序(Stop-the-world,STW),最长可能需要几分钟的时间,导致整个程序无法工作。
基于信号的抢占式调度
在任何情况下,Go 运行时并行执行(注意,不是并发)的 goroutines 数量是小于等于 P 的数量的。为了提高系统的性能,P 的数量肯定不是越小越好,所以官方默认值就是 CPU 的核心数,设置的过小的话,如果一个持有 P 的 M, 由于 P 当前执行的 G 调用了 syscall 而导致 M 被阻塞,那么此时关键点:GO 的调度器是迟钝的,它很可能什么都没做,直到 M 阻塞了相当长时间以后,才会发现有一个 P/M 被 syscall 阻塞了。然后,才会用空闲的 M 来强这个 P。通过 sysmon 监控实现的抢占式调度,最快在 20us,最慢在 10-20ms 才 会发现有一个 M 持有 P 并阻塞了。操作系统在 1ms 内可以完成很多次线程调度(一般情况 1ms 可以完成几十次线程调度),Go 发起 IO/syscall 的时候执行该 G 的 M 会阻塞然后被 OS 调度走,P 什么也不干,sysmon 最慢要 10-20ms才能发现这个阻塞,说不定那时候阻塞已经结束了,宝贵的 P 资源就这么被阻塞的 M 浪费。
-
-
GMP 调度过程中存在哪些阻塞
-
I/O,select
-
block on syscall
-
channel
-
等待锁
-
runtime.Gosched()
-
-
GMP 调度流程
-
每个 P 有个局部队列,局部队列保存待执行的 goroutine(流程 2),当 M 绑 定的 P 的的局部队列已经满了之后就会把 goroutine 放到全局队列(流程 2- 1)
-
每个 P 和一个 M 绑定,M 是真正的执行 P 中 goroutine 的实体(流程 3),M 从绑定的 P 中的局部队列获取 G 来执行
-
当 M 绑定的 P 的局部队列为空时,M 会从全局队列获取到本地队列来执行G(流程 3.1),当从全局队列中没有获取到可执行的 G 时候,M 会从其他 P 的局部队列中偷取 G 来执行(流程 3.2),这种从其他 P 偷的方式称为 work stealing
-
当 G 因系统调用(syscall)阻塞时会阻塞 M,此时 P 会和 M 解绑即 hand off,并寻找新的 idle 的 M,若没有 idle 的 M 就会新建一个 M(流程 5.1)。
-
当 G 因 channel 或者 network I/O 阻塞时,不会阻塞 M,M 会寻找其他 runnable 的 G;当阻塞的 G 恢复后会重新进入 runnable 进入 P 队列等待执 行(流程 5.3)
-
1.6 垃圾回收机制
-
GC 原理
垃圾回收就是对程序中不再使用的内存资源进行自动回收的操作。
三色标记法
- 初始状态下所有对象都是白色的。
- 从根节点开始遍历所有对象,把遍历到的对象变成灰色对象
- 遍历灰色对象,将灰色对象引用的对象也变成灰色对象,然后将遍历过的灰色对象变成黑色对象。
- 循环步骤3,直到灰色对象全部变黑色。
- 通过写屏障(write-barrier)检测对象有变化,重复以上操作
- 收集所有白色对象(垃圾)。
STW(Stop The World)
- 为了避免在 GC 的过程中,对象之间的引用关系发生新的变更,使得GC的结果发生错误(如GC过程中新增了一个引用,但是由于未扫描到该引用导致将被引用的对象清除了),停止所有正在运行的协程。
- STW对性能有一些影响,Golang目前已经可以做到1ms以下的STW。
-
GC 的触发条件
主动触发(手动触发),通过调用 runtime.GC 来触发GC,此调用阻塞式地等待当前GC运行完毕。
被动触发,分为两种方式:- 使用步调(Pacing)算法,其核心思想是控制内存增长的比例,每次内存分配时检查当前内存分配量是否已达到阈值(环境变量GOGC):默认100%,即当内存扩大一倍时启用GC。
- 使用系统监控,当超过两分钟没有产生任何GC时,强制触发 GC。
-
Golang为什么小对象多了会造成gc压力
通常小对象过多会导致GC三色法消耗过多的GPU。优化思路是,减少对象分配。
-
GC的屏障介绍
写屏障(Write Barrier)
- 为了避免GC的过程中新修改的引用关系到GC的结果发生错误,我们需要进行STW。但是STW会影响程序的性能,所以我们要通过写屏障技术尽可能地缩短STW的时间。
写屏障:并发gc会产生黑色节点引用白色节点情况,导致正常的指针变量错误的被清除;解决方法为写屏障;
主要包括强三色不变式和弱三色不变式;
强三色不变:黑色节点不能引用白色节点,如果引用白色节点需要将白色节点置灰(插入写屏障);
弱三色不变:黑节点可以引用白节点,但白节点有其他灰色节点或递归指向存在灰色节点,删除白色节点引用时,需要把白色节点置灰(删除写屏障);
栈上变量较小,且频繁开辟或删除,不开启写屏障;需要之后一次rescan;
stw时机:
插入写屏障:结束时需要STW来重新扫描栈,标记栈上引用的白色对象的存活;(1.5版本采用) 删除写屏障:回收精度低,GC开始时STW扫描堆栈来记录初始快照,这个过程会保护开始时刻的所有存活对象;混合写屏障:1.8版本加入
原因是stw需要耗时;加入混合写屏障,解决这个问题;
流程:
1.开始标记时候,栈上可达节点均置黑,之后不进行rescan,不用stw;
2.gc时产生的在栈上创建的对象,均置黑;
3.堆空间删除的对象置灰;
4.堆空间插入的对象置灰;
特点
-
混合写屏障继承了插入写屏障的优点,起始无需 STW 打快照,直接并发扫描垃圾即可;
-
混合写屏障继承了删除写屏障的优点,赋值器是黑色赋值器,GC 期间,任何在栈上创建的新对象,均为黑色。扫描过一次就不需要扫描了,这样就消除了插入写屏障时期最后 STW 的重新扫描栈;
-
混合写屏障扫描精度继承了删除写屏障,比插入写屏障更低,随着带来的是 GC 过程全程无 STW;
-
混合写屏障扫描栈虽然没有 STW,但是扫描某一个具体的栈的时候,还是要停止这个 goroutine 赋值器的工作的哈(针对一个 goroutine 栈来说,是暂停扫的,要么全灰,要么全黑哈,原子状态切换)。
-
GC 的流程是什么
当前版本的 Go 以 STW 为界限,可以将 GC 划分为五个阶段:
阶段说明赋值器状态 GCMark 标记准备阶段,为并发标记做准备工作,启动写屏障 STWGCMark 扫描标记阶段,与赋值器并发执行,写屏障开启并发
GCMarkTermination 标记终止阶段,保证一个周期内标记任务完成,停止写屏障 STWGCoff 内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭并发
GCoff 内存归还阶段,将过多的内存归还给操作系统,写屏障关闭并发
-
GC 如何调优
优化内存的申请速度,尽可能少申请内存,复用已申请的内存。三个关键字:控制、减少、复用。
通过 go tool pprof 和 go tool trace 等工具
- 控制内存分配的速度,限制 goroutine 的数量,从而提高赋值器对 CPU 的利用率。
- 减少并复用内存,例如使用 sync.Pool 来复用需要频繁创建临时对象,例如提前分配足够的内存来降低多余的拷贝。
- 需要时,增大 GOGC 的值,降低 GC 的运行频率。
1.7 其他知识点
-
new和make的区别
- make 仅用来分配及初始化类型为 slice、map、chan 的数据。
- new 可分配任意类型的数据,根据传入的类型申请一块内存,返回指向这块内存的指针,即类型 *Type。
- make 返回引用,即 Type,new 分配的空间被清零, make 分配空间后,会进行初始。
-
go的内存分配是怎么样的
Go 的内存分配借鉴了 Google 的 TCMalloc 分配算法,其核心思想是内存池 + 多级对象管理。内存池主要是预先分配内存,减少向系统申请的频率;多级对象有:mheap、mspan、arenas、mcentral、mcache。它们以 mspan 作为基本分配单位。具体的分配逻辑如下:
- 当要分配大于 32K 的对象时,从 mheap 分配。
- 当要分配的对象小于等于 32K 大于 16B 时,从 P 上的 mcache 分配,如果 mcache 没有内存,则从 mcentral 获取,如果 mcentral 也没有,则向 mheap 申请,如果 mheap 也没有,则从操作系统申请内存。
- 当要分配的对象小于等于 16B 时,从 mcache 上的微型分配器上分配。
-
竞态、内存逃逸
竞态
资源竞争,就是在程序中,同一块内存同时被多个 goroutine 访问。我们使用 go build、go run、go test 命令时,添加 -race 标识可以检查代码中是否存在资源竞争。
解决这个问题,我们可以给资源进行加锁,让其在同一时刻只能被一个协程来操作。
- sync.Mutex
- sync.RWMutex
逃逸分析
「逃逸分析」就是程序运行时内存的分配位置(栈或堆),是由编译器来确定的。堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。
在 Go 里变量的内存分配方式则是由编译器来决定的。如果变量在作用域(比如函数范围)之外,还会被引用的话,那么称之为发生了逃逸行为,此时将会把对象放到堆上,即使声明为值类型;如果没有发生逃逸行为的话,则会被分配到栈上,即使 new 了一个对象。
逃逸场景:
- 指针逃逸
- 栈空间不足逃逸
- 动态类型逃逸
- 闭包引用对象逃逸
-
什么是 rune 类型
rune 类型,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型等价于 int32 类型。
-
go语言触发异常的场景有哪些
-
空指针解析
-
下标越界
-
除数为0
-
调用panic函数
-
-
go的接口
Go 语言提供了另外一种数据类型即接口,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口。
接口可以让我们将不同的类型绑定到一组公共的方法上,从而实现多态和灵活的设计。
Go 语言中的接口是隐式实现的,也就是说,如果一个类型实现了一个接口定义的所有方法,那么它就自动地实现了该接口。因此,我们可以通过将接口作为参数来实现对不同类型的调用,从而实现多态。
-
相比较于其他语言, Go 有什么优势或者特点
-
Go代码的设计是务实的。每个功能和语法决策都旨在让程序员的生活更轻松。
-
Golang 针对并发进行了优化,并且在规模上运行良好。
-
由于单一的标准代码格式,Golang 通常被认为比其他语言更具可读性。
-
自动垃圾收集明显比 Java 或 Python 更有效,因为它与程序同时执行。
-
-
defer、panic、recover 三者的用法
defer 函数调用的顺序是后进先出,当产生 panic 的时候,会先执行 panic 前面的 defer 函数后才真的抛出异常。一般的,recover 会在 defer 函数里执行并捕获异常,防止程序崩溃。
-
Go反射
介绍
Go语言提供了一种机制在运行时更新和检查变量的值、调用变量的方法和变量支持的内在操作,但是在编译时并不知道这些变量的具体类型,这种机制被称为反射。反射也可以让我们将类型本身作为第一类的值类型处理。
反射是指在程序运行期对程序本身进行访问和修改的能力,程序在编译时变量被转换为内存地址,变量名不会被编译器写入到可执行部分,在运行程序时程序无法获取自身的信息。
Go语言中的反射是由 reflect 包提供支持的,它定义了两个重要的类型 Type 和 Value 任意接口值在反射中都可以理解为由 reflect.Type 和 reflect.Value 两部分组成,并且 reflect 包提供了 reflect.TypeOf 和 reflect.ValueOf 两个函数来获取任意对象的 Value 和 Type。
反射三定律
- 反射第一定律:反射可以将interface类型变量转换成反射对象
- 反射第二定律:反射可以将反射对象还原成interface对象
- 反射第三定律:反射对象可修改,value值必须是可设置的
-
Go语言函数传参是值类型还是引用类型
- 在Go语言中只存在值传递,要么是值的副本,要么是指针的副本。无论是值类型的变量还是引用类型的变量亦或是指针类型的变量作为参数传递都会发生值拷贝,开辟新的内存空间。
- 另外值传递、引用传递和值类型、引用类型是两个不同的概念,不要混淆了。引用类型作为变量传递可以影响到函数外部是因为发生值拷贝后新旧变量指向了相同的内存地址。
-
Go语言中的内存对齐
CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如 32 位的 CPU ,字长为 4 字节,那么 CPU 访问内存的单位也是 4 字节。
CPU 始终以字长访问内存,如果不进行内存对齐,很可能增加 CPU 访问内存的次数,例如:
变量 a、b 各占据 3 字节的空间,内存对齐后,a、b 占据 4 字节空间,CPU 读取 b 变量的值只需要进行一次内存访问。如果不进行内存对齐,CPU 读取 b 变量的值需要进行 2 次内存访问。第一次访问得到 b 变量的第 1 个字节,第二次访问得到 b 变量的后两个字节。
内存对齐对实现变量的原子性操作也是有好处的,每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的,这个特性在并发场景下至关重要。
简言之:合理的内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性。
-
空 struct{} 的用途
因为空结构体不占据内存空间,因此被广泛作为各种场景下的占位符使用。
- 将 map 作为集合(Set)使用时,可以将值类型定义为空结构体,仅作为占位符使用即可。
- 不发送数据的信道(channel)
使用 channel 不需要发送任何的数据,只用来通知子协程(goroutine)执行任务,或只用来控制协程并发度。 - 结构体只包含方法,不包含任何的字段
-
值传递和地址传递(引用传递)
Go 语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。因为拷贝的内容有时候是非引用类型(int、string、struct 等这些),这样就在函数中就无法修改原内容数据;有的是引用类型(指针、map、slice、chan等 这些),这样就可以修改原内容数据。
Golang 的引用类型包括 slice、map 和 channel。它们有复杂的内部结构,除了申请内存外,还需要初始化相关属性。内置函数 new 计算类型大小,为其分配零值内存,返回指针。而 make 会被编译器翻译成具体的创建函数,由其分 配内存和初始化成员结构,返回对象而非指针。
-
原子操作
一个或者多个操作在 CPU 执行过程中不被中断的特性,称为原子性 (atomicity)。
这些操作对外表现成一个不可分割的整体,他们要么都执行,要么都不执行,外界不会看到他们只执行到一半的状态。而在现实世界中,CPU不可能不中断的执行一系列操作,但如果我们在执行多个操作时,能让他们的中间状态对外不可见,那我们就可以宣城他们拥有了“不可分割”的原子性。
在 Go 中,一条普通的赋值语句其实不是一个原子操作。列如,在 32 位机器上写 int64 类型的变量就会有中间状态,因为他会被拆成两次写操作(MOV)——写低 32 位和写高 32 位。
2. 掌握Web框架Gin和微服务框架Micro
2.1 Gin框架
-
什么是Gin框架
Gin是一个用Go语言编写的web框架,,优点是封装比较好,API友好,源码注释比较明确,具有快速灵活,容错方便等特点。它具有运行速度快,分组的路由器,良好的崩溃捕获和错误处理,非常好的支持中间件和 json。
-
Gin路由的实现
gin框架使用的是定制版本的httprouter,其路由的原理是大量使用公共前缀的树结构,它基本上是一个紧凑的Trie tree(或者只是Radix Tree)。具有公共前缀的节点也共享一个公共父节点。
gin框架使用的是定制版本的httprouter,其路由的原理是大量使用公共前缀的树结构,它基本上是一个紧凑的Trie tree(或者只是Radix Tree)。具有公共前缀的节点也共享一个公共父节点。
路由树是由一个个节点构成的,gin框架路由树的节点由
node结构体表示在gin的路由中,每一个
HTTP Method(GET、POST、PUT、DELETE…)都对应了一棵radix tree,我们注册路由的时候会调用addRoute`函数注册路由的逻辑主要有
addRoute函数和insertChild方法。 路由树构造的详细过程:
- 第一次注册路由,例如注册search
- 继续注册一条没有公共前缀的路由,例如blog
- 注册一条与先前注册的路由有公共前缀的路由,例如support
路由树构造的详细过程:
- 第一次注册路由,例如注册search
- 继续注册一条没有公共前缀的路由,例如blog
- 注册一条与先前注册的路由有公共前缀的路由,例如support
路由匹配是由节点的
getValue方法实现的。getValue根据给定的路径(键)返回nodeValue值,保存注册的处理函数和匹配到的路径参数数据。gin框架路由使用前缀树,路由注册的过程是构造前缀树的过程,路由匹配的过程就是查找前缀树的过程。
-
Gin的中间件
Gin框架允许开发者在处理请求的过程中,加入用户自己的钩子(Hook)函数。这个钩子函数就叫中间件,中间件适合处理一些公共的业务逻辑,比如登录认证、权限校验、数据分页、记录日志、耗时统计等。
gin框架涉及中间件相关有4个常用的方法,它们分别是
c.Next()、c.Abort()、c.Set()、c.Get()。gin框架的中间件函数和处理函数是以切片形式的调用链条存在的,我们可以顺序调用也可以借助
c.Next()方法实现嵌套调用。借助
c.Set()和c.Get()方法我们能够在不同的中间件函数中传递数据。gin默认中间件
gin.Default()默认使用了Logger和Recovery中间件,其中:Logger中间件将日志写入gin.DefaultWriter,即使配置了GIN_MODE=release。
Recovery中间件会recover任何panic。如果有panic的话,会写入500响应码。
如果不想使用上面两个默认的中间件,可以使用gin.New()新建一个没有任何默认中间件的路由。
2.2 Micro框架
-
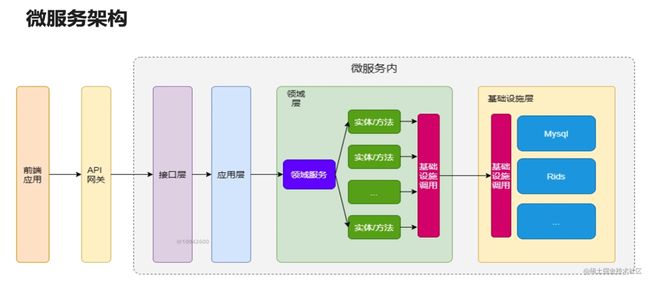
对微服务的了解
使用一套小服务来开发单个应用的方式,每个服务运行在独立的进程里,一般采用轻量级的通讯机制互联,并且它们可以通过自动化的方式部署
微服务特点
- 单一职责,此时项目专注于登录和注册
- 轻量级的通信,通信与平台和语言无关,http是轻量的
- 隔离性,数据隔离
- 有自己的数据
- 技术多样性
-
微服务架构的优势和缺点
优点
1、易于开发和维护
2、启动较快
3、局部修改容易部署
4、技术栈不受限
5、按需伸缩
缺点
1、运维要求较高
2、分布式的复杂性
3、接口调整成本高
4、重复劳动
-
RPC协议
- 远程过程调用(Remote Procedure Call,RPC)是一个计算机通信协议
- 该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程
- 如果涉及的软件采用面向对象编程,那么远程过程调用亦可称作远程调用或远程方法调用
RPC调用流程
微服务架构下数据交互一般是对内 RPC,对外 REST
将业务按功能模块拆分到各个微服务,具有提高项目协作效率、降低模块耦合度、提高系统可用性等优点,但是开发门槛比较高,比如 RPC 框架的使用、后期的服务监控等工作
一般情况下,我们会将功能代码在本地直接调用,微服务架构下,我们需要将这个函数作为单独的服务运行,客户端通过网络调用流行RPC框架:Dubbo、Motan、Thrift、gRPC
-
gRPC介绍
gRPC由google开发,是一款语言中立、平台中立、开源的远程过程调用系统
gRPC 是一个高性能、开源、通用的RPC框架,基于HTTP2协议标准设计开发,默认采用Protocol Buffers数据序列化协议,支持多种开发语言。gRPC提供了一种简单的方法来精确的定义服务,并且为客户端和服务端自动生成可靠的功能库。
在gRPC客户端可以直接调用不同服务器上的远程程序,使用起来就像调用本地程序一样,很容易去构建分布式应用和服务。和很多RPC系统一样,服务端负责实现定义好的接口并处理客户端的请求,客户端根据接口描述直接调用需要的服务。客户端和服务端可以分别使用gRPC支持的不同语言实现。
gRPC主要特性
- 强大的IDL
gRPC使用ProtoBuf来定义服务,ProtoBuf是由Google开发的一种数据序列化协议(类似于XML、JSON、hessian)。ProtoBuf能够将数据进行序列化,并广泛应用在数据存储、通信协议等方面。
- 多语言支持
gRPC支持多种语言,并能够基于语言自动生成客户端和服务端功能库。目前已提供了C版本grpc、Java版本grpc-java 和 Go版本grpc-go,其它语言的版本正在积极开发中,其中,grpc支持C、C++、Node.js、Python、Ruby、Objective-C、PHP和C#等语言,grpc-java已经支持Android开发。
- HTTP2
gRPC基于HTTP2标准设计,所以相对于其他RPC框架,gRPC带来了更多强大功能,如双向流、头部压缩、多复用请求等。这些功能给移动设备带来重大益处,如节省带宽、降低TCP链接次数、节省CPU使用和延长电池寿命等。同时,gRPC还能够提高了云端服务和Web应用的性能。gRPC既能够在客户端应用,也能够在服务器端应用,从而以透明的方式实现客户端和服务器端的通信和简化通信系统的构建。
-
Protobuf介绍
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化、或者说序列化。它很适合做数据存储或RPC数据交换格式。可以用于即时通讯、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式
protobuf的核心内容包括:
-
定义消息:消息的结构体,以message标识。
-
定义接口:接口路径和参数,以service标识。
通过protobuf提供的机制,服务端与服务端之间只需要关注接口方法名(service)和参数(message)即可通信,不需关注繁琐的链路协议和字段解析,极大降低服务端的设计开发成本。
-
-
Micro介绍和主要功能
go-micro简介
- Go Micro是一个插件化的基础框架,基于此可以构建微服务,Micro的设计哲学是可插拔的插件化架构
- 在架构之外,它默认实现了consul作为服务发现,通过http进行通信,通过protobuf和json进行编解码
- 是用来构建和管理分布式程序的系统
- Runtime (运行时) : 用来管理配置,认证,网络等
- Framework (程序开发框架) : 用来方便编写微服务
- Clients (多语言客户端) : 支持多语言访问服务端
go-micro的主要功能
-
服务发现:自动服务注册和名称解析。
-
负载均衡:基于服务发现构建的客户端负载均衡。
-
消息编码:基于内容类型的动态消息编码。
-
请求/响应:基于RPC的请求/响应,支持双向流。
-
Async Messaging:PubSub是异步通信和事件驱动架构的一流公民。
-
可插拔接口:Go Micro为每个分布式系统抽象使用Go接口,因此,这些接口是可插拔的,并允许Go Micro与运行时无关,可以插入任何基础技术
go-micro特性
- api: api 网关。使用服务发现具有动态请求路由的单个入口点. API 网关允许您在后端构建可扩展的微服务体系结构,并在前端合并公共 api. micro api 通过发现和可插拔处理程序提供强大的路由,为 http, grpc, Websocket, 发布事件等提供服务.
- broker: 允许异步消息的消息代理。微服务是事件驱动的体系结构,应该作为一等公民提供消息传递。通知其他服务的事件,而无需担心响应.
- network: 通过微网络服务构建多云网络。只需跨任何环境连接网络服务,创建单个平面网络即可全局路由. Micro 的网络根据每个数据中心中的本地注册表动态构建路由,确保根据本地设置路由查询.
- new: 服务模板生成器。创建新的服务模板以快速入门. Micro 提供用于编写微服务的预定义模板。始终以相同的方式启动,构建相同的服务以提高工作效率.
- proxy: 建立在 Go Micro 上的透明服务代理。将服务发现,负载平衡,容错,消息编码,中间件,监视等卸载到单个位置。独立运行它或与服务一起运行.
- registry: 注册表提供服务发现以查找其他服务,存储功能丰富的元数据和终结点信息。它是一个服务资源管理器,允许您在运行时集中和动态地存储此信息.
- store: 有状态是任何系统的必然需求。我们提供密钥值存储,提供简单的状态存储,可在服务之间共享或长期卸载 m 以保持微服务无状态和水平可扩展.
- web: Web 仪表板允许您浏览服务,描述其终结点,请求和响应格式,甚至直接查询它们。仪表板还包括内置 CLI 的体验,适用于希望动态进入终端的开发人员.
-
Micro通信流程
Server监听客户端的调用,和Brocker推送过来的信息进行处理。并且Server端需要向Register注册自己的存在或消亡,这样Client才能知道自己的状态
Register服务的注册的发现,Client端从Register中得到Server的信息,然后每次调用都根据算法选择一个的Server进行通信,当然通信是要经过编码/解码,选择传输协议等一系列过程的
如果有需要通知所有的Server端可以使用Brocker进行信息的推送,Brocker 信息队列进行信息的接收和发布 -
consul
Consul是用于实现分布式系统的服务发现与配置,Consul是分布式的、高可用的、可横向扩展的。
注册中心Consul关键功能
服务发现:客户端可以注册服务,程序可以轻松找到它们所依赖的服务
运行状况检查:Consul客户端可以提供任意数量的运行状况检查
KV 存储:应用程序可以将Consul的层级键/值存储用于任何目的,包括动态配置,功能标记,协调,领导者选举等
安全服务通信:Consul 可以为服务生成和分发TLS证书,建立相互的TLS连接
多数据中心:Consul 支持多个数据中心
注册中心Consul两个重要协议-
Gossip Protocol (八卦协议)
-
Raft Protocol ( 选举协议)
-
-
Jaeger
什么是链路追踪:
分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等
链路追踪主要功能:-
故障快速定位:可以通过调用链结合业务日志快速定位错误信息
-
链路性能可视化:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来
-
链路分析:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景
jaeger链路追踪作用
- 它是用来监视和诊断基于微服务的分布式系统
- 用于服务依赖性分析,辅助性能优化
Jaeger组成
Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
Agent - 它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。
Data Store - 后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、elastic search。
Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。
分布式追踪系统发展很快,种类繁多,但核心步骤一般有三个:代码埋点,数据存储、查询展示
-
-
Prometheus
promethues介绍
- 是一套开源的监控&报警&时间序列数据库的组合
- 基本原理是通过HTTP协议周期性抓取被监控组件的状态
- 适合Docker、 Kubernetes环境的监控系统
promethues工作流程
-
Prometheus server定期从配置好的jobs/exporters/Pushgateway中拉数据
-
Prometheus server记录数据并且根据报警规则推送alert数据
-
Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
-
在图形界面中,可视化采集数据
promethues重要组件
-
Prometheus Server:用于收集和存储时间序列数据。
-
Client Library:客户端库成相应的metrics并暴露给Prometheus server
-
Push Gateway:主要用于短期的jobs
-
Exporters: 用于暴露已有的第三方服务的metrics给Prometheus
-
Alertmanager: 从Prometheus server端接收到alerts后,会进行
grafana看板
- 拥有 丰富dashboard和图表编辑的指标分析平台
- 拥有自己的权限管理和用户管理系统
- Grafana 更适合用于数据可视化展示
-
熔断降级、限流、负载均衡
-
熔断降级
服务熔断也称服务隔离或过载保护。在微服务应用中,服务存在一定的依赖关系,形成一定的依赖链,如果某个目标服务调用慢或者有大量超时,造成服务不可用,间接导致其他的依赖服务不可用,最严重的可能会阻塞整条依赖链,最终导致业务系统崩溃(又称雪崩效应)。此时,对该服务的调用执行熔断,对于后续请求,不再继续调用该目标服务,而是直接返回,从而可以快速释放资源。等到目标服务情况好转后,则可恢复其调用。
关闭 (Closed):在这种状态下,我们需要一个计数器来记录调用失败的次数和总的请求次数,如果在某个时间窗口内,失败的失败率达到预设的阈值,则切换到断开状态,此时开启一个超时时间,当到达该时间则切换到半关闭状态,该超时时间是给了系统一次机会来修正导致调用失败的错误,以回到正常的工作状态。在关闭状态下,调用错误是基于时间的,在特定的时间间隔内会重置,这能够防止偶然错误导致熔断器进去断开状态
打开 (Open):在该状态下,发起请求时会立即返回错误,一般会启动一个超时计时器,当计时器超时后,状态切换到半打开状态,也可以设置一个定时器,定期的探测服务是否恢复
半打开 (Half-Open):在该状态下,允许应用程序一定数量的请求发往被调用服务,如果这些调用正常,那么可以认为被调用服务已经恢复正常,此时熔断器切换到关闭状态,同时需要重置计数。如果这部分仍有调用失败的情况,则认为被调用方仍然没有恢复,熔断器会切换到关闭状态,然后重置计数器,半打开状态能够有效防止正在恢复中的服务被突然大量请求再次打垮。
常见的有三种熔断降级策略
- 错误比例:在所设定的时间窗口内,调用的访问错误比例大于所设置的阈值,则对接下来访问的请求进行自动熔断。
- 错误计数:在所设定的时间窗口内,调用的访问错误次数大于所设置的阈值,则对接下来访问的请求进行自动熔断。
- 慢调用比例:在所设定的时间窗口内,慢调用的比例大于所设置的阈值,则对接下来访问的请求进行自动熔断。
服务降级
当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度。
关于降级,这里有两种场景:
- 当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
- 当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
-
限流
在微服务架构下,若大量请求超过微服务的处理能力时,可能会将服务打跨,甚至产生雪崩效应、影响系统的整体稳定性。比如说你的用户服务处理能力是1w/s,现在因为异常流量或其他原因,有10w的并发请求访问你的服务,那你的服务肯定扛不住啊。这种情况下,我们可以在流量超出承受阈值时,直接进行”限流”、拒绝部分请求,从而保证系统的整体稳定性。
限流算法
固定时间窗口
基于固定时间窗口的限流算法是非常简单的。首先需要选定一个时间起点,之后每次接口请求到来都累加计数器,如果在当前时间窗口内,根据限流规则(比如每秒钟最大允许 100 次接口请求),累加访问次数超过限流值,则限流熔断拒绝接口请求。当进入下一个时间窗口之后,计数器清零重新计数。
滑动时间窗口算法
滑动时间窗口算法是对固定时间窗口算法的一种改进,流量经过滑动时间窗口算法整形之后,可以保证任意时间窗口内,都不会超过最大允许的限流值,从流量曲线上来看会更加平滑,可以部分解决上面提到的临界突发流量问题。对比固定时间窗口限流算法,滑动时间窗口限流算法的时间窗口是持续滑动的,并且除了需要一个计数器来记录时间窗口内接口请求次数之外,还需要记录在时间窗口内每个接口请求到达的时间点,对内存的占用会比较多。
漏桶和令牌桶算法
漏桶算法(Leaky Bucket):主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。
请求先进入到漏桶里,漏桶以一定的速度出水,当水请求过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
令牌桶算法(Token Bucket):是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
大小固定的令牌桶可自行以恒定的速率源源不断地产生令牌。如果令牌不被消耗,或者被消耗的速度小于产生的速度,令牌就会不断地增多,直到把桶填满。后面再产生的令牌就会从桶中溢出。最后桶中可以保存的最大令牌数永远不会超过桶的大小。
漏桶和令牌桶算法的区别
令牌桶算法,主要放在服务端,用来保护服务端(自己),主要用来对调用者频率进行限流,为的是不让自己被压垮。所以如果自己本身有处理能力的时候,如果流量突发(实际消费能力强于配置的流量限制=桶大小),那么实际处理速率可以超过配置的限制(桶大小)。
而漏桶算法,主要放在调用方,这是用来保护他人,也就是保护他所调用的系统。主要场景是,当调用的第三方系统本身没有保护机制,或者有流量限制的时候,我们的调用速度不能超过他的限制,由于我们不能更改第三方系统,所以只有在主调方控制。这个时候,即使流量突发,也必须舍弃。因为消费能力是第三方决定的。自适应限流
一般的限流常常需要指定一个固定值(qps)作为限流开关的阈值,这个值一是靠经验判断,二是靠通过大量的测试数据得出。但这个阈值,在流量激增、系统自动伸缩或者某某commit了一段有毒代码后就有可能变得不那么合适了。并且一般业务方也不太能够正确评估自己的容量,去设置一个合适的限流阈值。那么我们就可以考虑用自适应限流来解决这个问题。
对于自适应限流来说, 一般都是结合系统的 Load、CPU 使用率以及应用的入口 QPS、平均响应时间和并发量等几个维度的监控指标,通过自适应的流控策略, 让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定。
分布式限流
上面使用的限流算法,都是基本单节点限流的。但线上业务出于各种原因考虑,多是分布式系统,单节点的限流仅能保护自身节点,但无法保护应用依赖的各种服务,并且在进行节点扩容、缩容时也无法准确控制整个服务的请求限制。比如说我希望某个接口的QPS的1000次/秒,服务部署在5台机器上,虽然我们可以通过配置每台节点200次/秒来限流。但如果节点收缩或者扩容,那么久不能满足需求了。而且不同服务的物理配置不一定相同,可能有些节点处理得比较快,那么配置均值来限流,就不是一个好方法了。
常见的分布式限流策略
网关层限流:将限流规则应用在所有流量的入口处,比如nigix+lua
中间件限流:将限流信息存储在分布式环境中某个中间件里(比如Redis缓存),每个组件都可以从这里获取到当前时刻的流量统计,从而决定是拒绝服务还是放行流量。 -
负载均衡
Load balancing,即负载均衡,是一种计算机技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。
负载均衡(Load Balance),意思是将负载(工作任务,访问请求)进行平衡、分摊到多个操作单元(服务器,组件)上进行执行。是解决高性能,单点故障(高可用),扩展性(水平伸缩)的终极解决方案。
负载均衡算法
1、轮询法
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
2、随机法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
3、源地址哈希法
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
4、加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
5、加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
6、最小连接数法
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前。
积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
-
2.3 Viper
-
什么是Viper
Viper是适用于Go应用程序的完整配置解决方案。它被设计用于在应用程序中工作,并且可以处理所有类型的配置需求和格式。
特性:
- 设置默认值
- 从
JSON、TOML、YAML、HCL、envfile和Java properties格式的配置文件读取配置信息 - 实时监控和重新读取配置文件(可选)
- 从环境变量中读取
- 从远程配置系统(etcd或Consul)读取并监控配置变化
- 从命令行参数读取配置
- 从buffer读取配置
- 显式配置值
-
Viper支持什么功能
Viper能够为你执行下列操作:
- 查找、加载和反序列化
JSON、TOML、YAML、HCL、INI、envfile和Java properties格式的配置文件。 - 提供一种机制为你的不同配置选项设置默认值。
- 提供一种机制来通过命令行参数覆盖指定选项的值。
- 提供别名系统,以便在不破坏现有代码的情况下轻松重命名参数。
- 当用户提供了与默认值相同的命令行或配置文件时,可以很容易地分辨出它们之间的区别。
- 建立默认值
- 读取配置文件
- 写入配置文件
- 监控并重新读取配置文件
- 从io.Reader读取配置
- 覆盖设置
- 注册和使用别名
- 使用环境变量
- 使用Flags
- 远程Key/Value存储支持
- 监控etcd中的更改-未加密
- 查找、加载和反序列化
2.4 Swagger
-
什么是Swagger
Swagger本质上是一种用于描述使用JSON表示的RESTful API的接口描述语言。Swagger与一组开源软件工具一起使用,以设计、构建、记录和使用RESTful Web服务。Swagger包括自动文档,代码生成和测试用例生成。
想要使用
gin-swagger为你的代码自动生成接口文档,一般需要下面三个步骤:- 按照swagger要求给接口代码添加声明式注释,具体参照声明式注释格式
- 使用swag工具扫描代码自动生成API接口文档数据
- 使用gin-swagger渲染在线接口文档页面
-
Swagger的优势
在前后端分离的项目开发过程中,如果后端同学能够提供一份清晰明了的接口文档,那么就能极大地提高大家的沟通效率和开发效率。可是编写接口文档历来都是令人头痛的,而且后续接口文档的维护也十分耗费精力。
最好是有一种方案能够既满足我们输出文档的需要又能随代码的变更自动更新,而Swagger正是那种能帮我们解决接口文档问题的工具。
2.5 Zap
-
什么是Zap
Zap是在 Go 中实现超快、结构化、分级的日志记录。
Zap日志能够提供下面这些功能:
-
1、能够将事件记录到文件中,也可以在应用控制台输出
-
2、日志切割-可以根据文件大小,时间或间隔来切割日志文件
-
3、支持不同的日志级别。例如 INFO、DEBUG、ERROR等
-
4、能够打印基本信息,如调用文件/函数名和行号,日志时间等。
zap的基本配置
Zap提供了两种类型的日志记录器—Sugared Logger 和 Logger 。在性能很好但不是很关键的上下文中,使用 SugaredLogger 。它比其他结构化日志记录包快4-10倍,并且支持结构化和printf风格的日志记录。
在每一微秒和每一次内存分配都很重要的上下文中,使用 Logger 。它甚至比 SugaredLogger 更快,内存分配次数也更少,但它只支持强类型的结构化日志记录。
这个日志程序中唯一缺少的就是日志切割归档功能。添加日志切割归档功能,我们将使用第三方库Lumberjack来实现。
-
2.6 JWT
-
什么是JWT
JWT 英文名是 Json Web Token ,是一种用于通信双方之间传递安全信息的简洁的、URL安全的表述性声明规范,经常用在跨域身份验证。
JWT 以 JSON 对象的形式安全传递信息。因为存在数字签名,因此所传递的信息是安全的。
一个JWT Token就像这样:
eyJhbGci0iJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoyODAx0DcyNzQ40DMyMzU4NSwiZ
XhwIjoxNTk0NTQwMjkxLCJpc3MiOiJibHV1YmVsbCJ9.1k_ZrAtYGCeZhK3iupHxP1kgjBJzQTVTtX0iZYFx9wU -
JWT的实现
JWT由.分割的三部分组成,这三部分依次是:
- 头部(Header)
作用:记录令牌类型、签名算法等 例如:{“alg":“HS256”,“type”,"JWT} - 负载(Payload)
作用:携带一些用户信息 例如{“userId”:“1”,“username”:“mayikt”} - 签名(Signature)
作用:防止Token被篡改、确保安全性 例如 计算出来的签名,一个字符串
头部和负载以json形式存在,这就是JWT中的JSON,三部分的内容都分别单独经过了Base64编码,以.拼接成一个JWT Token。
- 头部(Header)
-
JWT的优势
JWT就是一种基于Token的轻量级认证模式,服务端认证通过后,会生成一个JSON对象,经过签名后得到一个Token(令牌)再发回给用户,用户后续请求只需要带上这个Token,服务端解密之后就能获取该用户的相关信息了。
JWT拥有基于Token的会话管理方式所拥有的一切优势,不依赖Cookie,使得其可以防止CSRF攻击,也能在禁用Cookie的浏览器环境中正常运行。
而JWT的最大优势是服务端不再需要存储Session,使得服务端认证鉴权业务可以方便扩展,避免存储Session所需要引入的Redis等组件,降低了系统架构复杂度。但这也是JWT最大的劣势,由于有效期存储在Token中,JWT Token-旦签发,就会在有效期内-直可用,无法在服务端废止,当用户进行登出操作,只能依赖客户端删除掉本地存储的JWT Token,如果需要禁用用户,单纯使用JWT就无法做到了。
3. 熟悉使用 MySQL 数据库
3.1 索引
-
为什么使用索引
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 帮助服务器避免排序和临时表
- 将随机IO变为顺序IO。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-
索引的分类
- 普通索引:仅加速查询
- 唯一索引:加速查询 + 列值唯一(可以有null)
- 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
- 组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
- 全文索引:对文本的内容进行分词,进行搜索
- 索引合并:使用多个单列索引组合搜索
- 覆盖索引:select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖
- 聚簇索引:表数据是和主键一起存储的,主键索引的叶结点存储行数据(包含了主键值),二级索引的叶结点存储行的主键值。使用的是B+树作为索引的存储结构,非叶子节点都是索引关键字,但非叶子节点中的关键字中不存储对应记录的具体内容或内容地址。叶子节点上的数据是主键与具体记录(数据内容)
-
什么时候需要/不需要创建索引
索引最大的好处是提高查询速度,但是索引也是有缺点的,比如:
- 需要占用物理空间,数量越大,占用空间越大;
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增大;
- 会降低表的增删改的效率,每次增删改索引,B+ 树为了维护索引有序性,需要进行动态维护。
所以,索引不是万能钥匙,它也是根据场景来使用的。
什么时候适用索引?
- 字段有唯一性限制的,比如商品编码;
- 经常用于
WHERE查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。 - 经常用于
GROUP BY和ORDER BY的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
什么时候不需要创建索引?
WHERE条件,GROUP BY,ORDER BY里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女,如果数据库表中,男女的记录分布均匀,那么无论搜索哪个值都可能得到一半的数据。在这些情况下,还不如不要索引,因为 MySQL 还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么需要频繁的重建索引,这个过程是会影响数据库性能的。
-
优化索引的方法
-
前缀索引优化;
前缀索引顾名思义就是使用某个字段中字符串的前几个字符建立索引。
使用前缀索引是为了减小索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
-
覆盖索引优化;
覆盖索引是指 SQL 中 query 的所有字段,在索引 B+Tree 的叶子节点上都能找得到的那些索引,从二级索引中查询得到记录,而不需要通过聚簇索引查询获得,可以避免回表的操作。
使用覆盖索引的好处就是,不需要查询出包含整行记录的所有信息,也就减少了大量的 I/O 操作。
-
主键索引最好是自增的;
如果我们使用自增主键,那么每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,就会自动开辟一个新页面。因为每次插入一条新记录,都是追加操作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
主键字段的长度不要太大,因为主键字段长度越小,意味着二级索引的叶子节点越小(二级索引的叶子节点存放的数据是主键值),这样二级索引占用的空间也就越小。
-
防止索引失效;
用上了索引并不意味着查询的时候会使用到索引,所以我们心里要清楚有哪些情况会导致索引失效,从而避免写出索引失效的查询语句,否则这样的查询效率是很低的。
发生索引失效的情况:
- 当我们使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; - 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
- 当我们使用左或者左右模糊匹配的时候,也就是
-
-
索引使用的注意事项
MySQL 索引通常是被用于提高 WHERE 条件的数据行匹配时的搜索速度,在索引的使用过程中,存在一些使用细节和注意事项。
函数,运算,否定操作符,连接条件,多个单列索引,最左前缀原则,范围查询,不会包含有NULL值的列,like 语句不要在列上使用函数和进行运算
- 1)不要在列上使用函数,这将导致索引失效而进行全表扫描。
- 2)尽量避免使用 != 或 not in或 等否定操作符
- 3)多个单列索引并不是最佳选择
- 4)复合索引的最左前缀原则
- 5)覆盖索引的好处
- 6)范围查询对多列查询的影响
- 7)索引不会包含有NULL值的列
- 8)隐式转换的影响
- 9)like 语句的索引失效问题
-
索引为什么使用B+树作为索引
主要原因:B+树只要遍历叶子节点就可以实现整棵树的遍历,而且在数据库中基于范围的查询是非常频繁的,而B树只能中序遍历所有节点,效率太低。
B+tree的磁盘读写代价更低,B+tree的查询效率更加稳定 数据库索引采用B+树而不是B树的主要原因:B+树只要遍历叶子节点就可以实现整棵树的遍历,而且在数据库中基于范围的查询是非常频繁的,而B树只能中序遍历所有节点,效率太低。
B+树的特点
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
-
索引失效有哪些
- 当我们使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; - 当我们在查询条件中对索引列使用函数,就会导致索引失效。
- 当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
- MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
- 当我们使用左或者左右模糊匹配的时候,也就是
-
MyISAM和InnoDB实现B树索引方式的区别是什么
-
MyISAM,B+Tree叶节点的data域存放的是数据记录的地址,在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的key存在,则取出其data域的值,然后以data域的值为地址读取相应的数据记录,这被称为“非聚簇索引”
-
InnoDB,其数据文件本身就是索引文件,相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的节点data域保存了完整的数据记录,这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,这被称为“聚簇索引”或者聚集索引,而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。
在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。因此,在设计表的时候,不建议使用过长的字段为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1pQCH7oH-1678081583393)(https://cdn.xiaolincoding.com/gh/xiaolincoder/mysql/%E7%B4%A2%E5%BC%95/%E7%B4%A2%E5%BC%95%E6%80%BB%E7%BB%93.drawio.png)]
-
3.2 事务
-
事务的四大特性
- 原子性:事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性:执行事务前后,数据库从一个一致性状态转换到另一个一致性状态。
- 隔离性:并发访问数据库时,一个用户的事物不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性:一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库 发生故障也不应该对其有任何影响。
-
事务的脏读、不可重复读、幻读问题
脏读:如果一个事务「读到」了另一个「未提交事务修改过的数据」,就意味着发生了「脏读」现象。
幻读:在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了「幻读」现象。
丢弃修改:两个写事务T1 T2同时对A=0进行递增操作,结果T2覆盖T1,导致最终结果是1 而不是2,事务被覆盖
不可重复读:在一个事务内多次读取同一个数据,如果出现前后两次读到的数据不一样的情况,就意味着发生了「不可重复读」现象。
-
事务的隔离级别有哪些
- READ_UNCOMMITTED(未提交读): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读;
- READ_COMMITTED(提交读): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生;
- REPEATABLE_READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生;
- SERIALIZABLE(串行化): 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
隔离级别 脏读 不可重复读 幻影读 READ-UNCOMMITTED 未提交读 √ √ √ READ-COMMITTED 提交读 × √ √ REPEATABLE-READ 重复读 × × √ SERIALIZABLE 可串行化读 × × × MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)
这里需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在 REPEATABLE-READ(可重读)事务隔离级别 下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以 说InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) 已经可以完全保证事务的隔离性要 求,即达到了 SQL标准的SERIALIZABLE(可串行化)隔离级别。
-
Read View的作用
Read View 有四个重要的字段:
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
-
MySQL可重复读级别完全解决幻读了吗
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select … for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同:
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
这两个隔离级别实现是通过「事务的 Read View 里的字段」和「记录中的两个隐藏列」的比对,来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
两个发生幻读场景的例子。
第一个例子:对于快照读, MVCC 并不能完全避免幻读现象。因为当事务 A 更新了一条事务 B 插入的记录,那么事务 A 前后两次查询的记录条目就不一样了,所以就发生幻读。
第二个例子:对于当前读,如果事务开启后,并没有执行当前读,而是先快照读,然后这期间如果其他事务插入了一条记录,那么事务后续使用当前读进行查询的时候,就会发现两次查询的记录条目就不一样了,所以就发生幻读。
所以,MySQL 可重复读隔离级别并没有彻底解决幻读,只是很大程度上避免了幻读现象的发生。
-
MySQL中为什么要有事务回滚机制
在 MySQL 中,恢复机制是通过回滚日志(undo log)实现的,所有事务进行的修改都会先记录到这个回滚日志,然后在对数据库中的对应行进行写入。 当事务已经被提交后,就无法再次回滚了。
回滚日志作用: 1)能够在发生错误或者用户执行 ROLLBACK 时提供回滚相关的信息 2) 在整个系统发生崩溃、数据库进程直接被杀死后,当用户再次启动数据库进程时,还能够立刻通过查询回滚日志将之前未完成的事务进行回滚,这也就需要回滚日志必须先于数据持久化到磁盘上,是我们需要先写日志后写数据库的主要原因。
3.3 存储引擎
-
InnoDB介绍
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。
InnoDB主要特性有:
-
InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。
InnoDB锁定在行级并且也在SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合。
-
InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的。
-
InnoDB存储引擎完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上。
-
InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键。
-
InnoDB被用在众多需要高性能的大型数据库站点上。InnoDB不创建目录,使用InnoDB时,MySQL将在MySQL数据目录下创建一个名为ibdata1的10MB大小的自动扩展数据文件,以及两个名为 ib_logfile0 和 ib_logfile1 的5MB大小的日志文件。
-
-
MyISAM介绍
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。
MyISAM主要特性有:
- 大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持。
- 当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成。
- 每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16。
- 最大的键长度是1000字节,这也可以通过编译来改变,对于键长度超过250字节的情况,一个超过1024字节的键将被用上。
- BLOB和TEXT列可以被索引。
- NULL被允许在索引的列中,这个值占每个键的0~1个字节。
- 所有数字键值以高字节优先被存储以允许一个更高的索引压缩。
- 每个MyISAM类型的表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新,同时AUTO_INCREMENT列将被刷新。所以说,MyISAM类型表的AUTO_INCREMENT列更新比InnoDB类型的AUTO_INCREMENT更快。
- 可以把数据文件和索引文件放在不同目录。
- 每个字符列可以有不同的字符集。
- 有VARCHAR的表可以固定或动态记录长度。
- VARCHAR和CHAR列可以多达64KB。
-
MEMORY介绍
MEMORY存储引擎将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。
MEMORY主要特性有:
- MEMORY表的每个表可以有多达32个索引,每个索引16列,以及500字节的最大键长度。
- MEMORY存储引擎执行HASH和BTREE缩影。
- 可以在一个MEMORY表中有非唯一键值。
- MEMORY表使用一个固定的记录长度格式。
- MEMORY不支持BLOB或TEXT列。
- MEMORY支持AUTO_INCREMENT列和对可包含NULL值的列的索引。
- MEMORY表在所由客户端之间共享(就像其他任何非TEMPORARY表)。
- MEMORY表内存被存储在内存中,内存是MEMORY表和服务器在查询处理时的空闲中,创建的内部表共享。
- 当不再需要MEMORY表的内容时,要释放被MEMORY表使用的内存,应该执行DELETE FROM或TRUNCATE TABLE,或者删除整个表(使用DROP TABLE)。
-
Archive介绍
archive储存引擎的应用场景就是它的名字的缩影,主要用于归档。archive储存引擎仅支持select和insert,最出众的是插入快,查询快,占用空间小。
文件系统存储特性
- 以zlib对表数据进行压缩,磁盘I/O更少(几Tinnodb表在archive中只需要几百兆)
- 数据存储在.ARZ为后缀的文件中
- .frm文件
功能特点
- 只支持insert、replace和select
- 支持行级锁和专用的缓存区,可实现高并发
- 只允许在自增ID列上加索引
- 支持分区,不支持事务处理
-
数据库引擎InnoDB与MyISAM的区别
InnoDB
- 是 MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。
- 实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ 间隙锁(Next-Key Locking)防止幻影读。
- 主索引是聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,因此对查询性能有很大的提升。
- 内部做了很多优化,包括从磁盘读取数据时采用的可预测性读、能够加快读操作并且自动创建的自适应哈希索引、能够加速插入操作的插入缓冲区等。
- 支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
MyISAM
- 设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用它。
- 提供了大量的特性,包括压缩表、空间数据索引等。
- 不支持事务。
- 不支持行级锁,只能对整张表加锁,读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但在表有读取操作的同时,也可以往表中插入新的记录,这被称为并发插入(CONCURRENT INSERT)。
总结
- 事务: InnoDB 是事务型的,可以使用
Commit和Rollback语句。 - 并发: MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
- 外键: InnoDB 支持外键。
- 备份: InnoDB 支持在线热备份。
- 崩溃恢复: MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
- 其它特性: MyISAM 支持压缩表和空间数据索引。
适用场景: MyISAM适合: 插入不频繁,查询非常频繁,如果执行大量的SELECT,MyISAM是更好的选择, 没有事务。 InnoDB适合: 可靠性要求比较高,或者要求事务; 表更新和查询都相当的频繁, 大量的INSERT或UPDATE
3.4 锁机制
-
MySQL有哪些锁(全局锁/表级锁/行级锁)
全局锁
MyISAM 只支持表锁,InnoDB 支持表锁和行锁,默认为行锁。
表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量最低。
- 表锁:表级别的锁
- 元数据锁:MDL 全称为 metadata lock,即元数据锁,一般也可称为字典锁。MDL 的主要作用是为了管理数据库对象的并发访问和确保元数据一致性。
- 意向锁:意向锁是放置在资源层次结构的一个级别上的锁,以保护较低级别资源上的共享锁或排它锁。
- AUTO-INC锁:AUTO-INC 锁是特殊的表锁机制,锁不是再一个事务提交后才释放,而是再执行完插入语句后就会立即释放。
行级锁:开销大,加锁慢,会出现死锁。锁粒度小,发生锁冲突的概率小,并发度最高。
- Record lock:单个行记录上的锁;
- Gap lock:间隙锁,锁定一个范围,不包括记录本身;
- Next-key lock:record+gap 锁定一个范围,包含记录本身。
- 插入意向锁:插入意向锁名字虽然有意向锁,但是它并不是意向锁,它是一种特殊的间隙锁,属于行级别锁。
-
MySQL是怎么加锁的
MySQL 行级锁的加锁规则。
唯一索引等值查询:
- 当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会退化成「记录锁」。
- 当查询的记录是「不存在」的,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的 next-key lock 会退化成「间隙锁」。
非唯一索引等值查询:
- 当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。
- 当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
非唯一索引和主键索引的范围查询的加锁规则不同之处在于:
- 唯一索引在满足一些条件的时候,索引的 next-key lock 退化为间隙锁或者记录锁。
- 非唯一索引范围查询,索引的 next-key lock 不会退化为间隙锁和记录锁。
-
MySQL记录锁+间隙锁解决幻读问题
在 MySQL 的可重复读隔离级别下,针对当前读的语句会对索引加记录锁+间隙锁,这样可以避免其他事务执行增、删、改时导致幻读的问题。
有一点要注意的是,在执行 update、delete、select … for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
-
死锁的四个必要条件
-
互斥条件:一个资源每次只能被一个进程使用;
-
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
-
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺;
-
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系;
-
-
如何解决MySQL死锁问题
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
常见的解决死锁的方法
- 如果不同程序并发存取多个表,尽量约定 以相同的顺序访问表,可以大大降低死锁机会;
- 在同一个事务中,尽可能做到 一次锁定所需要的所有资源,减少死锁产生概率;
- 对于非常容易产生死锁的业务部分,可以尝试使用 升级锁定颗粒度,通过 表级锁 定来减少死锁产生的概率。
-
数据库悲观锁和乐观锁的原理和应用场景
悲观锁,先获取锁,再进行业务操作,一般就是利用类似 SELECT … FOR UPDATE 这样的语句,对数据加锁,避免其他事务意外修改数据。 当数据库执行SELECT … FOR UPDATE时会获取被select中的数据行的行锁,select for update获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用。
乐观锁,先进行业务操作,只在最后实际更新数据时进行检查数据是否被更新过。Java 并发包中的 AtomicFieldUpdater 类似,也是利用 CAS 机制,并不会对数据加锁,而是通过对比数据的时间戳或者版本号,来实现乐观锁需要的版本判断。
3.5 其他面试题
-
MySQL的内部构造一般可以分为哪两个部分
可以分为服务层和存储引擎层两部分,其中:
服务层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的存储引擎是InnoDB,它从MySQL 5.5.5版本开始成为了默认的存储引擎。
-
undo log、redo log、binlog有什么用
redo log是InnoDB引擎特有的,只记录该引擎中表的修改记录。binlog是MySQL的Server层实现的,会记录所有引擎对数据库的修改。
redo log是物理日志,记录的是在具体某个数据页上做了什么修改;binlog是逻辑日志,记录的是这个语句的原始逻辑。
redo log是循环写的,空间固定会用完;binlog是可以追加写入的,binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
补充
1、redolog记录修改内容(哪一页发生了什么变化),写于事务开始前,用于数据未落磁盘,但数据库挂了后的数据恢复
2、binlog记录修改SQL,写于事务提交时,可用于读写分离
3、undolog记录修改前记录,用于回滚和多版本并发控制 -
什么是Buffer pool
Innodb 存储引擎设计了一个缓冲池(*Buffer Pool*),来提高数据库的读写性能。
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
缓存什么
InnoDB 会把存储的数据划分为若干个「页」,以页作为磁盘和内存交互的基本单位,一个页的默认大小为 16KB。因此,Buffer Pool 同样需要按「页」来划分。
在 MySQL 启动的时候,InnoDB 会为 Buffer Pool 申请一片连续的内存空间,然后按照默认的
16KB的大小划分出一个个的页, Buffer Pool 中的页就叫做缓存页。此时这些缓存页都是空闲的,之后随着程序的运行,才会有磁盘上的页被缓存到 Buffer Pool 中。Innodb 通过三种链表来管理缓页:
- Free List (空闲页链表),管理空闲页;
- Flush List (脏页链表),管理脏页;
- LRU List,管理脏页+干净页,将最近且经常查询的数据缓存在其中,而不常查询的数据就淘汰出去。;
InnoDB 对 LRU 做了一些优化,我们熟悉的 LRU 算法通常是将最近查询的数据放到 LRU 链表的头部,而 InnoDB 做 2 点优化:
- 将 LRU 链表 分为young 和 old 两个区域,加入缓冲池的页,优先插入 old 区域;页被访问时,才进入 young 区域,目的是为了解决预读失效的问题。
- 当**「页被访问」且「 old 区域停留时间超过
innodb_old_blocks_time阈值(默认为1秒)」**时,才会将页插入到 young 区域,否则还是插入到 old 区域,目的是为了解决批量数据访问,大量热数据淘汰的问题。
可以通过调整
innodb_old_blocks_pct参数,设置 young 区域和 old 区域比例。 -
DROP、DELETE 与 TRUNCATE 的区别
三种都可以表示删除,其中的细微区别之处如下:
DROP DELETE TRUNCATE SQL 语句类型 DDL DML DDL 回滚 不可回滚 可回滚 不可回滚 删除内容 从数据库中 删除表,所有的数据行,索引和权限也会被删除 表结构还在,删除表的 全部或者一部分数据行 表结构还在,删除表中的 所有数据 删除速度 删除速度最快 删除速度慢,需要逐行删除 删除速度快 因此,在不再需要一张表的时候,采用 DROP;在想删除部分数据行时候,用 DELETE;在保留表而删除所有数据的时候用 TRUNCATE。
-
SQL语法中内连接、自连接、外连接(左、右、全)、交叉连接的区别分别是什么
-
内连接:只有两个元素表相匹配的才能在结果集中显示。
-
外连接:
-
左外连接: 左边为驱动表,驱动表的数据全部显示,匹配表的不匹配的不会显示。
-
右外连接:右边为驱动表,驱动表的数据全部显示,匹配表的不匹配的不会显示。
-
全外连接:连接的表中不匹配的数据全部会显示出来。
- 交叉连接: 笛卡尔效应,显示的结果是链接表数的乘积。
-
-
MySQL中CHAR和VARCHAR的区别有哪些
- char的长度是不可变的,用空格填充到指定长度大小,而varchar的长度是可变的。
- char的存取数度还是要比varchar要快得多
- char的存储方式是:对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节。varchar的存储方式是:对每个英文字符占用2个字节,汉字也占用2个字节
-
数据库中的主键、超键、候选键、外键是什么
- 超键:在关系中能唯一标识元组的属性集称为关系模式的超键
- 候选键:不含有多余属性的超键称为候选键。也就是在候选键中,若再删除属性,就不是键了!
- 主键:用户选作元组标识的一个候选键程序主键
- 外键:如果关系模式R中属性K是其它模式的主键,那么k在模式R中称为外键。
主键为候选键的子集,候选键为超键的子集,而外键的确定是相对于主键的。
-
MySQL优化
- 为搜索字段创建索引
- 避免使用 Select *,列出需要查询的字段
- 垂直分割分表
- 选择正确的存储引擎
-
SQL语句执行流程
Server层按顺序执行sql的步骤为:
- 客户端请求->
- 连接器(验证用户身份,给予权限) ->
- 查询缓存(存在缓存则直接返回,不存在则执行后续操作)->
- 分析器(对SQL进行词法分析和语法分析操作) ->
- 优化器(主要对执行的sql优化选择最优的执行方案方法) ->
- 执行器(执行时会先看用户是否有执行权限,有才去使用这个引擎提供的接口)->
- 去引擎层获取数据返回(如果开启查询缓存则会缓存查询结果)
简单概括:
- 连接器:管理连接、权限验证;
- 查询缓存:命中缓存则直接返回结果;
- 分析器:对SQL进行词法分析、语法分析;(判断查询的SQL字段是否存在也是在这步)
- 优化器:执行计划生成、选择索引;
- 执行器:操作引擎、返回结果;
- 存储引擎:存储数据、提供读写接口。
-
数据库三范式是什么
- 第一范式:强调的是列的原子性,即数据库表的每一列都是不可分割的原子数据项;
- 第二范式:要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性;
- 第三范式:任何非主属性不依赖于其它非主属性。
-
对MVCC的了解
数据库并发场景:
- 读-读:不存在任何问题,也不需要并发控制;
- 读-写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读;
- 写-写:有线程安全问题,可能会存在更新丢失问题。
多版本并发控制(MVCC)是一种用来解决读-写冲突的无锁并发控制,也就是为事务分配单向增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照。
MVCC 可以为数据库解决以下问题:
- 在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能;
- 同时还可以解决脏读,幻读,不可重复读等事务隔离问题,但不能解决更新丢失问题。
-
主从复制中涉及到哪三个线程?
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
- binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
- I/O 线程 :负责从主服务器上读取二进制日志,并写入从服务器的重放日志(Relay log)中。
- SQL 线程 :负责读取重放日志并重放其中的 SQL 语句。
-
数据库如何保证持久性
主要是利用Innodb的redo log。重写日志, 正如之前说的,MySQL是先把磁盘上的数据加载到内存中,在内存中对数据进行修改,再写回到磁盘上。如果此时突然宕机,内存中的数据就会丢失。 怎么解决这个问题? 简单啊,事务提交前直接把数据写入磁盘就行啊。 这么做有什么问题?
- 只修改一个页面里的一个字节,就要将整个页面刷入磁盘,太浪费资源了。毕竟一个页面16kb大小,你只改其中一点点东西,就要将16kb的内容刷入磁盘,听着也不合理。
- 毕竟一个事务里的SQL可能牵涉到多个数据页的修改,而这些数据页可能不是相邻的,也就是属于随机IO。显然操作随机IO,速度会比较慢。
于是,决定采用redo log解决上面的问题。当做数据修改的时候,不仅在内存中操作,还会在redo log中记录这次操作。当事务提交的时候,会将redo log日志进行刷盘(redo log一部分在内存中,一部分在磁盘上)。当数据库宕机重启的时候,会将redo log中的内容恢复到数据库中,再根据undo log和binlog内容决定回滚数据还是提交数据。
采用redo log的好处?
其实好处就是将redo log进行刷盘比对数据页刷盘效率高,具体表现如下:
- redo log体积小,毕竟只记录了哪一页修改了啥,因此体积小,刷盘快。
- redo log是一直往末尾进行追加,属于顺序IO。效率显然比随机IO来的快。
-
数据库如何保证原子性
主要是利用 Innodb 的undo log。 undo log名为回滚日志,是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的 SQL语句,他需要记录你要回滚的相应日志信息。 例如
- 当你delete一条数据的时候,就需要记录这条数据的信息,回滚的时候,insert这条旧数据
- 当你update一条数据的时候,就需要记录之前的旧值,回滚的时候,根据旧值执行update操作
- 当年insert一条数据的时候,就需要这条记录的主键,回滚的时候,根据主键执行delete操作
undo log记录了这些回滚需要的信息,当事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
-
数据库如何保证一致性
- 从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性。也就是说ACID四大特性之中,C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是手段,是为了保证一致性,数据库提供的手段。数据库必须要实现AID三大特性,才有可能实现一致性。例如,原子性无法保证,显然一致性也无法保证。
- 从应用层面,通过代码判断数据库数据是否有效,然后决定回滚还是提交数据!
-
数据库高并发的解决方案
- 在web服务框架中加入缓存。在服务器与数据库层之间加入缓存层,将高频访问的数据存入缓存中,减少数据库的读取负担。
- 增加数据库索引,进而提高查询速度。(不过索引太多会导致速度变慢,并且数据库的写入会导致索引的更新,也会导致速度变慢)
- 主从读写分离,让主服务器负责写,从服务器负责读。
- 将数据库进行拆分,使得数据库的表尽可能小,提高查询的速度。
- 使用分布式架构,分散计算压力。
-
数据库结构优化的手段
- 范式优化: 比如消除冗余(节省空间。。)
- 反范式优化:比如适当加冗余等(减少join)
- 限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。
- 读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
- 拆分表:分区将数据在物理上分隔开,不同分区的数据可以制定保存在处于不同磁盘上的数据文件里。这样,当对这个表进行查询时,只需要在表分区中进行扫描,而不必进行全表扫描,明显缩短了查询时间,另外处于不同磁盘的分区也将对这个表的数据传输分散在不同的磁盘I/O,一个精心设置的分区可以将数据传输对磁盘I/O竞争均匀地分散开。对数据量大的时时表可采取此方法。可按月自动建表分区。
-
关系型和非关系型数据库的区别
非关系型数据库也叫NOSQL,采用键值对的形式进行存储。
它的读写性能很高,易于扩展,可分为内存性数据库以及文档型数据库,比如 Redis,Mongodb,HBase等等。
合使用非关系型数据库的场景:
- 日志系统、地理位置存储、数据量巨大、高可用
- 关系型数据库的优点
- 容易理解。因为它采用了关系模型来组织数据。
- 可以保持数据的一致性。
- 数据更新的开销比较小。
- 支持复杂查询(带where子句的查询)
- 非关系型数据库的优点
- 不需要经过SQL层的解析,读写效率高。
- 基于键值对,数据的扩展性很好。
- 可以支持多种类型数据的存储,如图片,文档等等
-
数据库为什么要进行分库和分表
分库与分表的目的在于,减小数据库的单库单表负担,提高查询性能,缩短查询时间。
通过分表,可以减少数据库的单表负担,将压力分散到不同的表上,同时因为不同的表上的数据量少了,起到提高查询性能,缩短查询时间的作用,此外,可以很大的缓解表锁的问题。 分表策略可以归纳为垂直拆分和水平拆分: 水平分表:取模分表就属于随机分表,而时间维度分表则属于连续分表。 如何设计好垂直拆分,我的建议:将不常用的字段单独拆分到另外一张扩展表. 将大文本的字段单独拆分到另外一张扩展表, 将不经常修改的字段放在同一张表中,将经常改变的字段放在另一张表中。 对于海量用户场景,可以考虑取模分表,数据相对比较均匀,不容易出现热点和并发访问的瓶颈。
库内分表,仅仅是解决了单表数据过大的问题,但并没有把单表的数据分散到不同的物理机上,因此并不能减轻 MySQL 服务器的压力,仍然存在同一个物理机上的资源竞争和瓶颈,包括 CPU、内存、磁盘 IO、网络带宽等。
分库与分表带来的分布式困境与应对之策 数据迁移与扩容问题----一般做法是通过程序先读出数据,然后按照指定的分表策略再将数据写入到各个分表中。 分页与排序问题----需要在不同的分表中将数据进行排序并返回,并将不同分表返回的结果集进行汇总和再次排序,最后再返回给用户。
4. 熟悉计算机网络
4.1 TCP/IP协议
-
TCP/IP网络模型有哪几层,分别有什么作用
应用层
最上层的,也是我们能直接接触到的就是应用层(Application Layer),我们电脑或手机使用的应用软件都是在应用层实现。
所以,应用层只需要专注于为用户提供应用功能,比如 HTTP、FTP、Telnet、DNS、SMTP等。
应用层是不用去关心数据是如何传输的,而且应用层是工作在操作系统中的用户态,传输层及以下则工作在内核态。
传输层
应用层的数据包会传给传输层,传输层(Transport Layer)是为应用层提供网络支持的。
在传输层会有两个传输协议,分别是 TCP 和 UDP。
TCP 的全称叫传输控制协议(Transmission Control Protocol),大部分应用使用的正是 TCP 传输层协议,比如 HTTP 应用层协议。TCP 相比 UDP 多了很多特性,比如流量控制、超时重传、拥塞控制等,这些都是为了保证数据包能可靠地传输给对方。
UDP 相对来说就很简单,简单到只负责发送数据包,不保证数据包是否能抵达对方,但它实时性相对更好,传输效率也高。当然,UDP 也可以实现可靠传输,把 TCP 的特性在应用层上实现就可以,不过要实现一个商用的可靠 UDP 传输协议,也不是一件简单的事情。
应用需要传输的数据可能会非常大,如果直接传输就不好控制,因此当传输层的数据包大小超过 MSS(TCP 最大报文段长度) ,就要将数据包分块,这样即使中途有一个分块丢失或损坏了,只需要重新发送这一个分块,而不用重新发送整个数据包。在 TCP 协议中,我们把每个分块称为一个 TCP 段(TCP Segment)。
网络层
我们不希望传输层协议处理太多的事情,只需要服务好应用即可,让其作为应用间数据传输的媒介,帮助实现应用到应用的通信,而实际的传输功能就交给下一层,也就是网络层(Internet Layer)。
网络层最常使用的是 IP 协议(Internet Protocol),IP 协议会将传输层的报文作为数据部分,再加上 IP 包头组装成 IP 报文,如果 IP 报文大小超过 MTU(以太网中一般为 1500 字节)就会再次进行分片,得到一个即将发送到网络的 IP 报文。
IP 协议的寻址作用是告诉我们去往下一个目的地该朝哪个方向走,路由则是根据「下一个目的地」选择路径。寻址更像在导航,路由更像在操作方向盘。
网络接口层
生成了 IP 头部之后,接下来要交给网络接口层(Link Layer)在 IP 头部的前面加上 MAC 头部,并封装成数据帧(Data frame)发送到网络上。
以太网在判断网络包目的地时和 IP 的方式不同,因此必须采用相匹配的方式才能在以太网中将包发往目的地,而 MAC 头部就是干这个用的,所以,在以太网进行通讯要用到 MAC 地址。
MAC 头部是以太网使用的头部,它包含了接收方和发送方的 MAC 地址等信息,我们可以通过 ARP 协议获取对方的 MAC 地址。
所以说,网络接口层主要为网络层提供「链路级别」传输的服务,负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标识网络上的设备。
-
输入网址到网页显示,期间发生了什么
- 根据域名,进行DNS域名解析;
- 拿到解析的IP地址,建立TCP连接;
- 向IP地址,发送HTTP请求;
- 服务器处理请求;
- 返回响应结果;
- 关闭TCP连接;
- 浏览器解析HTML;
- 浏览器布局渲染;
背后有哪些技术
1、查浏览器缓存,看看有没有已经缓存好的,如果没有
2 、检查本机host文件,
3、调用API,Linux下Socket函数 gethostbyname
4、向DNS服务器发送DNS请求,查询本地DNS服务器,这其中用的是UDP的协议
5、如果在一个子网内采用ARP地址解析协议进行ARP查询如果不在一个子网那就需要对默认网关进行DNS查询,如果还找不到会一直向上找根DNS服务器,直到最终拿到IP地址(全球400多个根DNS服务器,由13个不同的组织管理)
6、这个时候我们就有了服务器的IP地址 以及默认的端口号了,http默认是80 https是 443 端口号,会,首先尝试http然后调用Socket建立TCP连接,
7、经过三次握手成功建立连接后,开始传送数据,如果正是http协议的话,就返回就完事了,
8、如果不是http协议,服务器会返回一个5开头的的重定向消息,告诉我们用的是https,那就是说IP没变,但是端口号从80变成443了,好了,再四次挥手,完事,
9、再来一遍,这次除了上述的端口号从80变成443之外,还会采用SSL的加密技术来保证传输数据的安全性,保证数据传输过程中不被修改或者替换之类的,
10、这次依然是三次握手,沟通好双方使用的认证算法,加密和检验算法,在此过程中也会检验对方的CA安全证书。
11、确认无误后,开始通信,然后服务器就会返回你所要访问的网址的一些数据,在此过程中会将界面进行渲染,牵涉到ajax技术之类的,直到最后我们看到色彩斑斓的网页
4.2 HTTP/HTTPS协议
-
什么是HTTP协议
HTTP 是超文本传输协议,也就是HyperText Transfer Protocol。
HTTP 的名字「超文本协议传输」,它可以拆成三个部分:
- 超文本
- 传输
- 协议
-
GET和POST
GET 用于获取资源,而 POST 用于传输实体主体。
-
get是获取数据,post是修改数据
-
get把请求的数据放在url上, 以?分割URL和传输数据,参数之间以&相连,所以get不太安全。而post把数据放在HTTP的包体内(request body 相对安全)
-
get提交的数据最大是2k( 限制实际上取决于浏览器), post理论上没有限制。
-
GET产生一个TCP数据包,浏览器会把http header和data一并发送出去,服务器响应200(返回数据); POST产生两个TCP数据包,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
-
GET请求会被浏览器主动缓存,而POST不会,除非手动设置。
-
本质区别:GET是幂等的,而POST不是幂等的
这里的幂等性:幂等性是指一次和多次请求某一个资源应该具有同样的副作用。简单来说意味着对同一URL的多个请求应该返回同样的结果。
正因为它们有这样的区别,所以不应该且不能用get请求做数据的增删改这些有副作用的操作。因为get请求是幂等的,在网络不好的隧道中会尝试重试。如果用get请求增数据,会有重复操作的风险,而这种重复操作可能会导致副作用(浏览器和操作系统并不知道你会用get请求去做增操作)。
-
-
HTTP缓存技术
对于一些具有重复性的 HTTP 请求,比如每次请求得到的数据都一样的,我们可以把这对「请求-响应」的数据都缓存在本地,那么下次就直接读取本地的数据,不必在通过网络获取服务器的响应了,这样的话 HTTP/1.1 的性能肯定肉眼可见的提升。
所以,避免发送 HTTP 请求的方法就是通过缓存技术,HTTP 缓存有两种实现方式,分别是强制缓存和协商缓存。
强制缓存
强缓存指的是只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边。
强缓存是利用下面这两个 HTTP 响应头部(Response Header)字段实现的,它们都用来表示资源在客户端缓存的有效期:
Cache-Control, 是一个相对时间;Expires,是一个绝对时间;
如果 HTTP 响应头部同时有 Cache-Control 和 Expires 字段的话,Cache-Control 的优先级高于 Expires 。
Cache-control 选项更多一些,设置更加精细,所以建议使用 Cache-Control 来实现强缓存。具体的实现流程如下:
- 当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 Cache-Control,Cache-Control 中设置了过期时间大小;
- 浏览器再次请求访问服务器中的该资源时,会先通过请求资源的时间与 Cache-Control 中设置的过期时间大小,来计算出该资源是否过期,如果没有,则使用该缓存,否则重新请求服务器;
- 服务器再次收到请求后,会再次更新 Response 头部的 Cache-Control。
协商缓存
协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。
协商缓存可以基于两种头部来实现。
第一种:请求头部中的
If-Modified-Since字段与响应头部中的Last-Modified字段实现,这两个字段的意思是:- 响应头部中的
Last-Modified:标示这个响应资源的最后修改时间; - 请求头部中的
If-Modified-Since:当资源过期了,发现响应头中具有 Last-Modified 声明,则再次发起请求的时候带上 Last-Modified 的时间,服务器收到请求后发现有 If-Modified-Since 则与被请求资源的最后修改时间进行对比(Last-Modified),如果最后修改时间较新(大),说明资源又被改过,则返回最新资源,HTTP 200 OK;如果最后修改时间较旧(小),说明资源无新修改,响应 HTTP 304 走缓存。
第二种:请求头部中的
If-None-Match字段与响应头部中的ETag字段,这两个字段的意思是:- 响应头部中
Etag:唯一标识响应资源; - 请求头部中的
If-None-Match:当资源过期时,浏览器发现响应头里有 Etag,则再次向服务器发起请求时,会将请求头 If-None-Match 值设置为 Etag 的值。服务器收到请求后进行比对,如果资源没有变化返回 304,如果资源变化了返回 200。
第一种实现方式是基于时间实现的,第二种实现方式是基于一个唯一标识实现的,相对来说后者可以更加准确地判断文件内容是否被修改,避免由于时间篡改导致的不可靠问题。
当使用 ETag 字段实现的协商缓存的过程:
-
当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 ETag 唯一标识,这个唯一标识的值是根据当前请求的资源生成的;
-
当浏览器再次请求访问服务器中的该资源时,首先会先检查强制缓存是否过期:
- 如果没有过期,则直接使用本地缓存;
- 如果缓存过期了,会在 Request 头部加上 If-None-Match 字段,该字段的值就是 ETag 唯一标识;
-
服务器再次收到请求后,
会根据请求中的 If-None-Match 值与当前请求的资源生成的唯一标识进行比较:
- 如果值相等,则返回 304 Not Modified,不会返回资源;
- 如果不相等,则返回 200 状态码和返回资源,并在 Response 头部加上新的 ETag 唯一标识;
-
如果浏览器收到 304 的请求响应状态码,则会从本地缓存中加载资源,否则更新资源。
-
HTTP 如何实现长连接?在什么时候会超时?
通过在头部(请求和响应头)设置 Connection: keep-alive,HTTP1.0协议支持,但是默认关闭,从HTTP1.1协议以后,连接默认都是长连接
1、HTTP 一般会有 httpd 守护进程,里面可以设置 keep-alive timeout,当 tcp 链接闲置超过这个时间就会关闭,也可以在 HTTP 的 header 里面设置超时时间
2、TCP 的 keep-alive 包含三个参数,支持在系统内核的 net.ipv4 里面设置:当 TCP 链接之后,闲置了 tcp_keepalive_time,则会发生侦测包,如果没有收到对方的 ACK,那么会每隔 tcp_keepalive_intvl 再发一次,直到发送了 tcp_keepalive_probes,就会丢弃该链接。
(1)tcp_keepalive_intvl = 15
(2)tcp_keepalive_probes = 5
(3)tcp_keepalive_time = 1800实际上 HTTP 没有长短链接,只有 TCP 有,TCP 长连接可以复用一个 TCP 链接来发起多次 HTTP 请求,这样可以减少资源消耗,比如一次请求 HTML,可能需要请求后续的 JS/CSS/图片等
-
HTTP 1.0/1.1/2.0/3.0的介绍、优点和缺点
HTTP/1.0
1996年5月,HTTP/1.0 版本发布,为了提高系统的效率,HTTP/1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
HTTP/1.0中浏览器与服务器只保持短暂的连接,连接无法复用。也就是说每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
我们知道TCP连接的建立需要三次握手,是很耗费时间的一个过程。所以,HTTP/1.0版本的性能比较差。
HTTP/1.1
HTTP 最突出的优点是「简单、灵活和易于扩展、应用广泛和跨平台」。
HTTP 协议里有优缺点一体的双刃剑,分别是「无状态、明文传输」,同时还有一大缺点「不安全」。
为了解决HTTP/1.0存在的缺陷,HTTP/1.1于1999年诞生。相比较于HTTP/1.0来说,最主要的改进就是引入了持久连接。所谓的持久连接即TCP连接默认不关闭,可以被多个请求复用。
客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。或者客户端在最后一个请求时,主动告诉服务端要关闭连接。
HTTP/1.1版还引入了管道机制(pipelining),即在同一个TCP连接里面,客户端可以同时发送多个请求。这样就进一步改进了HTTP协议的效率。
有了持久连接和管道,大大的提升了HTTP的效率。但是服务端还是顺序执行的,效率还有提升的空间。
HTTP/2
HTTP/2 是 HTTP 协议自 1999 年 HTTP 1.1 发布后的首个更新,主要基于 SPDY 协议。
HTTP/2 为了解决HTTP/1.1中仍然存在的效率问题,HTTP/2 采用了多路复用。即在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应。能这样做有一个前提,就是HTTP/2进行了二进制分帧,即 HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码。
而这个负责拆分、组装请求和二进制帧的一层就叫做二进制分帧层。
除此之外,还有一些其他的优化,比如做Header压缩、服务端推送等。
Header压缩就是压缩老板和员工之间的对话。
服务端推送就是员工事先把一些老板可能询问的事情提现发送到老板的手机(缓存)上。这样老板想要知道的时候就可以直接读取短信(缓存)了。
HTTP/2 相比 HTTP/1.1 性能上的改进:
- 头部压缩
- 二进制格式
- 并发传输
- 服务器主动推送资源
HTTP/2 有什么缺陷?
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在“队头阻塞”的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
HTTP3.0
HTTP/2 虽然具有多个流并发传输的能力,但是传输层是 TCP 协议,于是存在以下缺陷:
- 队头阻塞,HTTP/2 多个请求跑在一个 TCP 连接中,如果序列号较低的 TCP 段在网络传输中丢失了,即使序列号较高的 TCP 段已经被接收了,应用层也无法从内核中读取到这部分数据,从 HTTP 视角看,就是多个请求被阻塞了;
- TCP 和 TLS 握手时延,TCP 三次握手和 TLS 四次握手,共有 3-RTT 的时延;
- 连接迁移需要重新连接,移动设备从 4G 网络环境切换到 WiFi 时,由于 TCP 是基于四元组来确认一条 TCP 连接的,那么网络环境变化后,就会导致 IP 地址或端口变化,于是 TCP 只能断开连接,然后再重新建立连接,切换网络环境的成本高;
HTTP/3 就将传输层从 TCP 替换成了 UDP,并在 UDP 协议上开发了 QUIC 协议,来保证数据的可靠传输。
QUIC 协议的特点:
- 无队头阻塞,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,也不会有底层协议限制,某个流发生丢包了,只会影响该流,其他流不受影响;
- 建立连接速度快,因为 QUIC 内部包含 TLS 1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与 TLS 密钥协商,甚至在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
- 连接迁移,QUIC 协议没有用四元组的方式来“绑定”连接,而是通过「连接 ID 」来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本;
另外 HTTP/3 的 QPACK 通过两个特殊的单向流来同步双方的动态表,解决了 HTTP/2 的 HPACK 队头阻塞问题。
-
HTTPS的介绍
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
-
HTTPS是如何保证数据传输的安全,整体的流程是什么?(SSL是怎么工作保证安全的)
(1)客户端向服务器端发起SSL连接请求;
(2) 服务器把公钥发送给客户端,并且服务器端保存着唯一的私钥
(3)客户端用公钥对双方通信的对称秘钥进行加密,并发送给服务器端
(4)服务器利用自己唯一的私钥对客户端发来的对称秘钥进行解密,
(5)进行数据传输,服务器和客户端双方用公有的相同的对称秘钥对数据进行加密解密,可以保证在数据收发过程中的安全,即是第三方获得数据包,也无法对其进行加密,解密和篡改。
因为数字签名、摘要是证书防伪非常关键的武器。 “摘要”就是对传输的内容,通过hash算法计算出一段固定长度的串。通过发送方的私钥对这段摘要进行加密,加密后得到的结果就是“数字签名”
SSL/TLS协议的基本思路是采用公钥加密法,也就是说,客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
补充:SSL/TLS的四次握手,目前网上的主流答案都在重复阮一峰老师的博客,属于TLS 1.0版本的答案,使用RSA密钥交换算法。但是现在TLS 1.2已经成为主流,使用ECDHE算法,如果面试可以说出这个版本的答案,应该会更好。
-
什么是SSL/TLS
SSL代表安全套接字层。它是一种用于加密和验证应用程序(如浏览器)和Web服务器之间发送的数据的协议。 身份验证 , 加密Https的加密机制是一种共享密钥加密和公开密钥加密并用的混合加密机制。
SSL/TLS协议作用:认证用户和服务,加密数据,维护数据的完整性的应用层协议加密和解密需要两个不同的密钥,故被称为非对称加密;加密和解密都使用同一个密钥的
对称加密:优点在于加密、解密效率通常比较高 ,HTTPS 是基于非对称加密的, 公钥是公开的。
-
TLS 握手过程
TLS 协议是如何解决 HTTP 的风险的呢?
- 信息加密: HTTP 交互信息是被加密的,第三方就无法被窃取;
- 校验机制:校验信息传输过程中是否有被第三方篡改过,如果被篡改过,则会有警告提示;
- 身份证书:证明淘宝是真的淘宝网;
TLS 的握手过程,其中每一个「框」都是一个记录(record),记录是 TLS 收发数据的基本单位,类似于 TCP 里的 segment。多个记录可以组合成一个 TCP 包发送,所以通常经过「四个消息」就可以完成 TLS 握手,也就是需要 2个 RTT 的时延,然后就可以在安全的通信环境里发送 HTTP 报文,实现 HTTPS 协议。
HTTPS 是应用层协议,需要先完成 TCP 连接建立,然后走 TLS 握手过程后,才能建立通信安全的连接。
-
HTTPS RSA握手过程
HTTPS 采用混合的加密机制,使用非对称密钥加密用于传输对称密钥来保证传输过程的安全性,之后使用对称密钥加密进行通信来保证通信过程的效率。
确保传输安全过程(其实就是rsa原理):
- Client给出协议版本号、一个客户端生成的随机数(Client random),以及客户端支持的加密方法。
- Server确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数(Server random)。
- Client确认数字证书有效,然后生成呀一个新的随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给Server。
- Server使用自己的私钥,获取Client发来的随机数(Premaster secret)。
- Client和Server根据约定的加密方法,使用前面的三个随机数,生成”对话密钥”(session key),用来加密接下来的整个对话过程。
使用 RSA 密钥协商算法的最大问题是不支持前向保密。因为客户端传递随机数(用于生成对称加密密钥的条件之一)给服务端时使用的是公钥加密的,服务端收到后,会用私钥解密得到随机数。所以一旦服务端的私钥泄漏了,过去被第三方截获的所有 TLS 通讯密文都会被破解。
为了解决这个问题,后面就出现了 ECDHE 密钥协商算法。
-
HTTPS ECDHE握手过程
ECDHE 算法是在 DHE 算法的基础上利用了 ECC 椭圆曲线特性,可以用更少的计算量计算出公钥,以及最终的会话密钥。
TLS 第一次握手
客户端首先会发一个「Client Hello」消息,消息里面有客户端使用的 TLS 版本号、支持的密码套件列表,以及生成的随机数(*Client Random*)。
TLS 第二次握手
服务端收到客户端的「打招呼」,同样也要回礼,会返回「Server Hello」消息,消息面有服务器确认的 TLS 版本号,也给出了一个随机数(*Server Random*),然后从客户端的密码套件列表选择了一个合适的密码套件。
接着,服务端为了证明自己的身份,发送「Certificate」消息,会把证书也发给客户端。
这一步就和 RSA 握手过程有很大的区别了,因为服务端选择了 ECDHE 密钥协商算法,所以会在发送完证书后,发送「Server Key Exchange」消息。
这个过程服务器做了三件事:
- 选择了名为 x25519 的椭圆曲线,选好了椭圆曲线相当于椭圆曲线基点 G 也定好了,这些都会公开给客户端;
- 生成随机数作为服务端椭圆曲线的私钥,保留到本地;
- 根据基点 G 和私钥计算出服务端的椭圆曲线公钥,这个会公开给客户端。
为了保证这个椭圆曲线的公钥不被第三方篡改,服务端会用 RSA 签名算法给服务端的椭圆曲线公钥做个签名。
随后,就是「Server Hello Done」消息,服务端跟客户端表明:“这些就是我提供的信息,打招呼完毕”。
至此,TLS 两次握手就已经完成了,目前客户端和服务端通过明文共享了这几个信息:Client Random、Server Random 、使用的椭圆曲线、椭圆曲线基点 G、服务端椭圆曲线的公钥,这几个信息很重要,是后续生成会话密钥的材料。
TLS 第三次握手
客户端收到了服务端的证书后,自然要校验证书是否合法,如果证书合法,那么服务端到身份就是没问题的。校验证书的过程会走证书链逐级验证,确认证书的真实性,再用证书的公钥验证签名,这样就能确认服务端的身份了,确认无误后,就可以继续往下走。
客户端会生成一个随机数作为客户端椭圆曲线的私钥,然后再根据服务端前面给的信息,生成客户端的椭圆曲线公钥,然后用「Client Key Exchange」消息发给服务端。
算好会话密钥后,客户端会发一个「Change Cipher Spec」消息,告诉服务端后续改用对称算法加密通信。
接着,客户端会发「Encrypted Handshake Message」消息,把之前发送的数据做一个摘要,再用对称密钥加密一下,让服务端做个验证,验证下本次生成的对称密钥是否可以正常使用。
TLS 第四次握手
最后,服务端也会有一个同样的操作,发「Change Cipher Spec」和「Encrypted Handshake Message」消息,如果双方都验证加密和解密没问题,那么握手正式完成。于是,就可以正常收发加密的 HTTP 请求和响应了。
-
RSA 和 ECDHE 握手过程的区别
- RSA 密钥协商算法「不支持」前向保密,ECDHE 密钥协商算法「支持」前向保密;
- 使用了 RSA 密钥协商算法,TLS 完成四次握手后,才能进行应用数据传输,而对于 ECDHE 算法,客户端可以不用等服务端的最后一次 TLS 握手,就可以提前发出加密的 HTTP 数据,节省了一个消息的往返时间(这个是 RFC 文档规定的,具体原因文档没有说明,所以这点我也不太明白);
- 使用 ECDHE, 在 TLS 第 2 次握手中,会出现服务器端发出的「Server Key Exchange」消息,而 RSA 握手过程没有该消息;
-
FIN_WAIT_2,CLOSE_WAIT状态和TIME_WAIT状态
- FIN_WAIT_2:
- 半关闭状态。
- 发送断开请求一方还有接收数据能力,但已经没有发送数据能力。
- CLOSE_WAIT状态:
- 被动关闭连接一方接收到FIN包会立即回应ACK包表示已接收到断开请求。
- 被动关闭连接一方如果还有剩余数据要发送就会进入CLOSE_WAIT状态。
- TIME_WAIT状态:
- 又叫2MSL等待状态。
- 如果客户端直接进入CLOSED状态,如果服务端没有接收到最后一次ACK包会在超时之后重新再发FIN包,此时因为客户端已经CLOSED,所以服务端就不会收到ACK而是收到RST。所以TIME_WAIT状态目的是防止最后一次握手数据没有到达对方而触发重传FIN准备的。
- 在2MSL时间内,同一个socket不能再被使用,否则有可能会和旧连接数据混淆(如果新连接和旧连接的socket相同的话)。
- FIN_WAIT_2:
-
对称密钥加密和非对称密钥加密
对称秘钥加密
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
- 优点:运算速度快
- 缺点:无法安全地将密钥传输给通信方
非对称秘钥加密
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
- 优点:可以更安全地将公开密钥传输给通信发送方;
- 缺点:运算速度慢。
-
HTTPS如何优化
对于硬件优化的方向,因为 HTTPS 是属于计算密集型,应该选择计算力更强的 CPU,而且最好选择支持 AES-NI 特性的 CPU,这个特性可以在硬件级别优化 AES 对称加密算法,加快应用数据的加解密。
对于软件优化的方向,如果可以,把软件升级成较新的版本,比如将 Linux 内核 2.X 升级成 4.X,将 openssl 1.0.1 升级到 1.1.1,因为新版本的软件不仅会提供新的特性,而且还会修复老版本的问题。
对于协议优化的方向:
- 密钥交换算法应该选择 ECDHE 算法,而不用 RSA 算法,因为 ECDHE 算法具备前向安全性,而且客户端可以在第三次握手之后,就发送加密应用数据,节省了 1 RTT。
- 将 TLS1.2 升级 TLS1.3,因为 TLS1.3 的握手过程只需要 1 RTT,而且安全性更强。
对于证书优化的方向:
- 服务器应该选用 ECDSA 证书,而非 RSA 证书,因为在相同安全级别下,ECC 的密钥长度比 RSA 短很多,这样可以提高证书传输的效率;
- 服务器应该开启 OCSP Stapling 功能,由服务器预先获得 OCSP 的响应,并把响应结果缓存起来,这样 TLS 握手的时候就不用再访问 CA 服务器,减少了网络通信的开销,提高了证书验证的效率;
对于重连 HTTPS 时,我们可以使用一些技术让客户端和服务端使用上一次 HTTPS 连接使用的会话密钥,直接恢复会话,而不用再重新走完整的 TLS 握手过程。
常见的会话重用技术有 Session ID 和 Session Ticket,用了会话重用技术,当再次重连 HTTPS 时,只需要 1 RTT 就可以恢复会话。对于 TLS1.3 使用 Pre-shared Key 会话重用技术,只需要 0 RTT 就可以恢复会话。
这些会话重用技术虽然好用,但是存在一定的安全风险,它们不仅不具备前向安全,而且有重放攻击的风险,所以应当对会话密钥设定一个合理的过期时间。
-
WebSocket协议
websocket是一种浏览器与服务器进行全双工通信的网络技术,属于 应用层协议。它 基于TCP传输协议,并 复用HTTP 的握手通道,用来弥补HTTP协议在持久通信能力上的不足。
- ws 默认端口:80
- wss 默认端口:443
- Websocket 通过HTTP协议握手。
websocket的特点有哪些?
- 节省资源开销,HTTP请求每次都要携带完整的头部,此项开销显著减少了;
- 更强的实时性,由于协议是全双工通信,所以服务器可以主动给客户端推送数据,相对于HTTP请求需要等待客户端发起请求服务端才能响应,延迟明显更少;
- 保持连接状态,能够记录用户状态,通信时可以省略部分状态信息,不像HTTP每次都需要携带用户认证信息;
- 更好的二进制支持,Websocket定义了二进制帧,相对HTTP,可以更轻松地处理二进制内容。
-
HTTP如何实现长连接
HTTP长连接
- 浏览器向服务器进行一次HTTP会话访问后,并不会直接关闭这个连接,而是会默认保持一段时间,那么下一次浏览器继续访问的时候就会再次利用到这个连接。
- 在
HTTP/1.1版本中,默认的连接都是长连接,我们可以通过Connection: keep-alive字段进行指定。
TCP保活机制
-
为什么要有保活机制?
- 第一点自然是我们这篇文章的主题,通过保活机制,我们可以保证通讯双方的连接不被释放掉
- 第二点就是在另一些情况下,如果客户端或者服务器发生了错误或者宕机,那么就可以依靠这种保活机制探测出网络通信出现了问题,进而可以释放掉这种错误连接。
-
保活机制
首先保活机制的工作原理就是,通过在服务器端设置一个保活定时器,当定时器开始工作后就定时的向网络通信的另一端发出保活探测的TCP报文,如果接收到了ACK报文,那么就证明对方存活,可以继续保有连接;否则就证明网络存在故障。
上面只是在原理层面简单的介绍,根据文献[1],我们可以了解到详细的内容:
- 如果一个给定的连接在两个小时之内没有任何动作,则服务器就向客户发送一个探查报文段。客户主机必须处于以下 4个状态之一。
- 状态1:客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常工作的。服务器在两小时以后将保活定时器复位。如果在两个小时定时器到时间之前有应用程序的通信量通过此连接,则定时器在交换数据后的未来2小时再复位。
- 状态2:客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务器将不能够收到对探查的响应,并在75秒后超时。服务器总共发送10个这样的探查,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
- 状态3:客户主机崩溃并已经重新启动。这时服务器将收到一个对其保活探查的响应,但是这个响应是一个复位,使得服务器终止这个连接。
- 状态4:客户主机正常运行,但是从服务器不可达。这与状态2相同,因为TCP不能够区分状态4与状态2之间的区别,它所能发现的就是没有收到探查的响应。
-
HTTP和HTTPS的区别
Http协议运行在TCP之上,明文传输,客户端与服务器端都无法验证对方的身份;Https是身披SSL(Secure Socket Layer)外壳的Http,运行于SSL上,SSL运行于TCP之上,是添加了加密和认证机制的HTTP。二者之间存在如下不同:
1、端口不同:Http与Https使用不同的连接方式,用的端口也不一样,前者是80,后者是443;
2、资源消耗:和HTTP通信相比,Https通信会由于加减密处理消耗更多的CPU和内存资源;
3、开销:Https通信需要证书,而证书一般需要向认证机构购买;
4、安全性:HTTP 的连接很简单,是无状态的;HTTPS 协议是由 TLS+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全
Https的加密机制是一种共享密钥加密和公开密钥加密并用的混合加密机制。websocket应用场景有哪些?
- 即时通信、直播、游戏、在线协同工具(腾讯文档等)、实时数据拉取和推送地图
-
HTTP请求方法有多少
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
序 号 方法 描述 1 GET 请求指定的页面信息,并返回实体主体。 2 HEAD 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 3 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 4 PUT 从客户端向服务器传送的数据取代指定的文档的内容。 5 DELETE 请求服务器删除指定的页面。 6 CONNECT HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 7 OPTIONS 允许客户端查看服务器的性能。 8 TRACE 回显服务器收到的请求,主要用于测试或诊断。 9 PATCH 是对 PUT 方法的补充,用来对已知资源进行局部更新 。
4.3 TCP三次握手/四次挥手
-
TCP三次握手和四次挥手的过程
三次握手过程
- 初始状态:客户端处于
closed(关闭)状态,服务器处于listen(监听)状态。 - 第一次握手:客户端发送请求报文将
SYN = 1同步序列号和初始化序列号seq = x发送给服务端,发送完之后客户端处于SYN_Send状态。(验证了客户端的发送能力和服务端的接收能力) - 第二次握手:服务端受到
SYN请求报文之后,如果同意连接,会以自己的同步序列号SYN(服务端) = 1、初始化序列号seq = y和确认序列号(期望下次收到的数据包)ack = x+ 1以及确认号ACK = 1报文作为应答,服务器为SYN_Receive状态。(问题来了,两次握手之后,站在客户端角度上思考:我发送和接收都ok,服务端的发送和接收也都ok。但是站在服务端的角度思考:哎呀,我服务端接收ok,但是我不清楚我的发送ok不ok呀,而且我还不知道你接受能力如何呢?所以老哥,你需要给我三次握手来传个话告诉我一声。你要是不告诉我,万一我认为你跑了,然后我可能出于安全性的考虑继续给你发一次,看看你回不回我。) - 第三次握手: 客户端接收到服务端的
SYN + ACK之后,知道可以下次可以发送了下一序列的数据包了,然后发送同步序列号ack = y + 1和数据包的序列号seq = x + 1以及确认号ACK = 1确认包作为应答,客户端转为established状态。(分别站在双方的角度上思考,各自ok)
为什么需要三次握手,两次不行吗
弄清这个问题,我们需要先弄明白三次握手的目的是什么,能不能只用两次握手来达到同样的目的。
- 第一次握手:客户端发送网络包,服务端收到了。 这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。
- 第二次握手:服务端发包,客户端收到了。 这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。不过此时服务器并不能确认客户端的接收能力是否正常。
- 第三次握手:客户端发包,服务端收到了。 这样服务端就能得出结论:客户端的接收、发送能力正常,服务器自己的发送、接收能力也正常。
三个方面分析三次握手的原因:
- 三次握手才可以阻止重复历史连接的初始化(主要原因)
- 三次握手才可以同步双方的初始序列号
- 三次握手才可以避免资源浪费
TCP 建立连接时,通过三次握手能防止历史连接的建立,能减少双方不必要的资源开销,能帮助双方同步初始化序列号。序列号能够保证数据包不重复、不丢弃和按序传输。
不使用「两次握手」和「四次握手」的原因:
- 「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
- 「四次握手」:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
四次挥手过程
- 初始化状态:客户端和服务端都在连接状态,接下来开始进行四次分手断开连接操作。
- 第一次分手:第一次分手无论是客户端还是服务端都可以发起,因为 TCP 是全双工的。
假如客户端发送的数据已经发送完毕,发送FIN = 1 告诉服务端,客户端所有数据已经全发完了,服务端你可以关闭接收了,但是如果你们服务端有数据要发给客户端,客户端照样可以接收的。此时客户端处于FIN = 1等待服务端确认释放连接状态。
- 第二次分手:服务端接收到客户端的释放请求连接之后,知道客户端没有数据要发给自己了,然后服务端发送ACK = 1告诉客户端收到你发给我的信息,此时服务端处于 CLOSE_WAIT 等待关闭状态。(服务端先回应给客户端一声,我知道了,但服务端的发送数据能力即将等待关闭,于是接下来第三次就来了。)
- 第三次分手:此时服务端向客户端把所有的数据发送完了,然后发送一个FIN = 1,用于告诉客户端,服务端的所有数据发送完毕,客户端你也可以关闭接收数据连接了。此时服务端状态处于LAST_ACK状态,来等待确认客户端是否收到了自己的请求。(服务端等客户端回复是否收到呢,不收到的话,服务端不知道客户端是不是挂掉了还是咋回事呢,所以服务端不敢关闭自己的接收能力,于是第四次就来了。)
- 第四次分手:此时如果客户端收到了服务端发送完的信息之后,就发送ACK = 1,告诉服务端,客户端已经收到了你的信息。有一个 2 MSL 的延迟等待。
为什么需要挥手四次
因为当服务端收到客户端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当服务端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉客户端,“你发的FIN报文收到了”。只有等到我服务端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四次挥手。
- 初始状态:客户端处于
-
TCP协议介绍
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。
特点
- TCP是面向连接的。
- 每一条TCP连接只能有两个端点,每一条TCP连接只能是点对点的(一对一);
- TCP提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达;
- TCP提供全双工通信。TCP允许通信双方的应用进程在任何时候都能发送数据。TCP连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据;
- 面向字节流。TCP中的“流”(stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序交下来的数据仅仅看成是一连串的无结构的字节流。
-
TCP三次握手、四次挥手丢失,会发生什么
三次握手丢失
第一次握手丢失了,会发生什么?
如果客户端迟迟收不到服务端的 SYN-ACK 报文(第二次握手),就会触发「超时重传」机制,重传 SYN 报文,而且重传的 SYN 报文的序列号都是一样的。每次超时的时间是上一次的 2 倍。
第二次握手丢失了,会发生什么?
因为第二次握手报文里是包含对客户端的第一次握手的 ACK 确认报文,所以,如果客户端迟迟没有收到第二次握手,那么客户端就觉得可能自己的 SYN 报文(第一次握手)丢失了,于是客户端就会触发超时重传机制,重传 SYN 报文。
然后,因为第二次握手中包含服务端的 SYN 报文,所以当客户端收到后,需要给服务端发送 ACK 确认报文(第三次握手),服务端才会认为该 SYN 报文被客户端收到了。
那么,如果第二次握手丢失了,服务端就收不到第三次握手,于是服务端这边会触发超时重传机制,重传 SYN-ACK 报文。
因此,当第二次握手丢失了,客户端和服务端都会重传
第三次握手丢失了,会发生什么?
客户端收到服务端的 SYN-ACK 报文后,就会给服务端回一个 ACK 报文,也就是第三次握手,此时客户端状态进入到
ESTABLISH状态。因为这个第三次握手的 ACK 是对第二次握手的 SYN 的确认报文,所以当第三次握手丢失了,如果服务端那一方迟迟收不到这个确认报文,就会触发超时重传机制,重传 SYN-ACK 报文,直到收到第三次握手,或者达到最大重传次数。
注意,ACK 报文是不会有重传的,当 ACK 丢失了,就由对方重传对应的报文。
挥手四次丢失
第一次挥手丢失了,会发生什么?
如果第一次挥手丢失了,那么客户端迟迟收不到被动方的 ACK 的话,也就会触发超时重传机制,重传 FIN 报文,重发次数由
tcp_orphan_retries参数控制。当客户端重传 FIN 报文的次数超过
tcp_orphan_retries后,就不再发送 FIN 报文,则会在等待一段时间(时间为上一次超时时间的 2 倍),如果还是没能收到第二次挥手,那么直接进入到close状态。第二次挥手丢失了,会发生什么?
当服务端收到客户端的第一次挥手后,就会先回一个 ACK 确认报文,此时服务端的连接进入到
CLOSE_WAIT状态。在前面我们也提了,ACK 报文是不会重传的,所以如果服务端的第二次挥手丢失了,客户端就会触发超时重传机制,重传 FIN 报文,直到收到服务端的第二次挥手,或者达到最大的重传次数。
第三次挥手丢失了,会发生什么?
当服务端(被动关闭方)收到客户端(主动关闭方)的 FIN 报文后,内核会自动回复 ACK,同时连接处于
CLOSE_WAIT状态,顾名思义,它表示等待应用进程调用 close 函数关闭连接。此时,内核是没有权利替代进程关闭连接,必须由进程主动调用 close 函数来触发服务端发送 FIN 报文。
服务端处于 CLOSE_WAIT 状态时,调用了 close 函数,内核就会发出 FIN 报文,同时连接进入 LAST_ACK 状态,等待客户端返回 ACK 来确认连接关闭。
如果迟迟收不到这个 ACK,服务端就会重发 FIN 报文,重发次数仍然由
tcp_orphan_retries 参数控制,这与客户端重发 FIN 报文的重传次数控制方式是一样的。第四次挥手丢失了,会发生什么?
当客户端收到服务端的第三次挥手的 FIN 报文后,就会回 ACK 报文,也就是第四次挥手,此时客户端连接进入
TIME_WAIT状态。在 Linux 系统,TIME_WAIT 状态会持续 2MSL 后才会进入关闭状态。
然后,服务端(被动关闭方)没有收到 ACK 报文前,还是处于 LAST_ACK 状态。
如果第四次挥手的 ACK 报文没有到达服务端,服务端就会重发 FIN 报文,重发次数仍然由前面介绍过的
tcp_orphan_retries参数控制。 -
2MSL等待状态
2MSL等待状态
TIME_WAIT状态也成为2MSL等待状态。每个具体TCP实现必须选择一个报文段最大生存时间MSL(Maximum Segment Lifetime),它是任何报文段被丢弃前在网络内的最长时间。这个时间是有限的,因为TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生存时间的TTL字段。
对一个具体实现所给定的MSL值,处理的原则是:当TCP执行一个主动关闭,并发回最后一个ACK,该连接必须在TIME_WAIT状态停留的时间为2倍的MSL。这样可让TCP再次发送最后的ACK以防这个ACK丢失(另一端超时并重发最后的FIN)。
这种2MSL等待的另一个结果是这个TCP连接在2MSL等待期间,定义这个连接的插口(客户的IP地址和端口号,服务器的IP地址和端口号)不能被使用。这个连接只能在2MSL结束后才能再被使用。
为什么TIME_WAIT状态需要经过2MSL才能返回到CLOSE状态
理论上,四个报文都发送完毕,就可以直接进入CLOSE状态了,但是可能网络是不可靠的,有可能最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
客户端给服务端发送的ACK = 1丢失,服务端等待 1MSL没收到,然后重新发送消息需要1MSL。如果再次接收到服务端的消息,则重启2MSL计时器,发送确认请求。客户端只需等待2MSL,如果没有再次收到服务端的消息,就说明服务端已经接收到自己确认消息;此时双方都关闭的连接,TCP 四次分手完毕
-
TIME_WAIT介绍
MSL是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为 TCP 报文基于是 IP 协议的,而 IP 头中有一个TTL字段,是 IP 数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。MSL 与 TTL 的区别: MSL 的单位是时间,而 TTL 是经过路由跳数。所以 MSL 应该要大于等于 TTL 消耗为 0 的时间,以确保报文已被自然消亡。
TTL 的值一般是 64,Linux 将 MSL 设置为 30 秒,意味着 Linux 认为数据报文经过 64 个路由器的时间不会超过 30 秒,如果超过了,就认为报文已经消失在网络中了。
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是: 网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。
为什么需要 TIME_WAIT 状态?
主动发起关闭连接的一方,才会有
TIME-WAIT状态。需要 TIME-WAIT 状态,主要是两个原因:
- 防止历史连接中的数据,被后面相同四元组的连接错误的接收;
- 保证「被动关闭连接」的一方,能被正确的关闭;
-
TIME_WAIT 过多有什么危害?
过多的 TIME-WAIT 状态主要的危害有两种:
- 第一是占用系统资源,比如文件描述符、内存资源、CPU 资源、线程资源等;
- 第二是占用端口资源,端口资源也是有限的,一般可以开启的端口为
32768~61000,也可以通过net.ipv4.ip_local_port_range参数指定范围。
-
如何优化 TIME_WAIT?
这里给出优化 TIME-WAIT 的几个方式,都是有利有弊:
- 打开 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_timestamps 选项;
- net.ipv4.tcp_max_tw_buckets
- 程序中使用 SO_LINGER ,应用强制使用 RST 关闭。
-
什么是半连接队列
服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。
当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
这里在补充一点关于SYN-ACK 重传次数的问题: 服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传。如果重传次数超过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。 注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s,2s,4s,8s…
-
常见TCP的连接状态有哪些
- CLOSED:初始状态。
- LISTEN:服务器处于监听状态。
- SYN_SEND:客户端socket执行CONNECT连接,发送SYN包,进入此状态。
- SYN_RECV:服务端收到SYN包并发送服务端SYN包,进入此状态。
- ESTABLISH:表示连接建立。客户端发送了最后一个ACK包后进入此状态,服务端接收到ACK包后进入此状态。
- FIN_WAIT_1:终止连接的一方(通常是客户机)发送了FIN报文后进入。等待对方FIN。
- CLOSE_WAIT:(假设服务器)接收到客户机FIN包之后等待关闭的阶段。在接收到对方的FIN包之后,自然是需要立即回复ACK包的,表示已经知道断开请求。但是本方是否立即断开连接(发送FIN包)取决是否还有数据需要发送给客户端,若有,则在发送FIN包之前均为此状态。
- FIN_WAIT_2:此时是半连接状态,即有一方要求关闭连接,等待另一方关闭。客户端接收到服务器的ACK包,但并没有立即接收到服务端的FIN包,进入FIN_WAIT_2状态。
- LAST_ACK:服务端发动最后的FIN包,等待最后的客户端ACK响应,进入此状态。
- TIME_WAIT:客户端收到服务端的FIN包,并立即发出ACK包做最后的确认,在此之后的2MSL时间称为TIME_WAIT状态。
-
TCP头部中有哪些信息
- 序号(32bit):传输方向上字节流的字节编号。初始时序号会被设置一个随机的初始值(ISN),之后每次发送数据时,序号值 = ISN + 数据在整个字节流中的偏移。假设A -> B且ISN = 1024,第一段数据512字节已经到B,则第二段数据发送时序号为1024 + 512。用于解决网络包乱序问题。
- 确认号(32bit):接收方对发送方TCP报文段的响应,其值是收到的序号值 + 1。
- 首部长(4bit):标识首部有多少个4字节 * 首部长,最大为15,即60字节。
- 标志位(6bit):
- URG:标志紧急指针是否有效。
- ACK:标志确认号是否有效(确认报文段)。用于解决丢包问题。
- PSH:提示接收端立即从缓冲读走数据。
- RST:表示要求对方重新建立连接(复位报文段)。
- SYN:表示请求建立一个连接(连接报文段)。
- FIN:表示关闭连接(断开报文段)。
- 窗口(16bit):接收窗口。用于告知对方(发送方)本方的缓冲还能接收多少字节数据。用于解决流控。
- 校验和(16bit):接收端用CRC检验整个报文段有无损坏。
-
RTO,RTT和超时重传分别是什么
- 超时重传:发送端发送报文后若长时间未收到确认的报文则需要重发该报文。可能有以下几种情况:
- 发送的数据没能到达接收端,所以对方没有响应。
- 接收端接收到数据,但是ACK报文在返回过程中丢失。
- 接收端拒绝或丢弃数据。
- RTO:从上一次发送数据,因为长期没有收到ACK响应,到下一次重发之间的时间。就是重传间隔。
- 通常每次重传RTO是前一次重传间隔的两倍,计量单位通常是RTT。例:1RTT,2RTT,4RTT,8RTT…
- 重传次数到达上限之后停止重传。
- RTT:数据从发送到接收到对方响应之间的时间间隔,即数据报在网络中一个往返用时。大小不稳定。
- 超时重传:发送端发送报文后若长时间未收到确认的报文则需要重发该报文。可能有以下几种情况:
-
TCP重传
TCP 实现可靠传输的方式之一,是通过序列号与确认应答。
在 TCP 中,当发送端的数据到达接收主机时,接收端主机会返回一个确认应答消息,表示已收到消息。
常见的重传机制:
- 超时重传
- 快速重传
- SACK
- D-SACK
超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的
ACK确认应答报文,就会重发该数据,也就是我们常说的超时重传。TCP 会在以下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
RTT指的是数据发送时刻到接收到确认的时刻的差值,也就是包的往返时间。超时重传时间是以
RTO(Retransmission Timeout 超时重传时间)表示。- 当超时时间 RTO 较大时,重发就慢,丢了老半天才重发,没有效率,性能差;
- 当超时时间 RTO 较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
根据上述的两种情况,我们可以得知,超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。
快速重传
TCP 还有另外一种快速重传(Fast Retransmit)机制,它不以时间为驱动,而是以数据驱动重传。
快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是重传的时候,是重传一个,还是重传所有的问题。
SACK 方法
还有一种实现重传机制的方式叫:
SACK( Selective Acknowledgment), 选择性确认。这种方式需要在 TCP 头部「选项」字段里加一个
SACK的东西,它可以将已收到的数据的信息发送给「发送方」,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。Duplicate SACK
Duplicate SACK 又称
D-SACK,其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。D-SACK有这么几个好处:- 可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
- 可以知道是不是「发送方」的数据包被网络延迟了;
- 可以知道网络中是不是把「发送方」的数据包给复制了;
在 Linux 下可以通过
net.ipv4.tcp_dsack参数开启/关闭这个功能(Linux 2.4 后默认打开)。 -
TCP滑动窗口
TCP 利用滑动窗口实现流量控制的机制。滑动窗口(Sliding window)是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包,谁也发不了数据,就有了滑动窗口机制来解决此问题。
TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报,但有两种情况除外,一种情况是可以发送紧急数据,例如,允许用户终止在远端机上的运行进程。另一种情况是发送方可以发送一个 1 字节的数据报来通知接收方重新声明它希望接收的下一字节及发送方的滑动窗口大小。
-
TCP流量控制
TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
- 目的是接收方通过TCP头窗口字段告知发送方本方可接收的最大数据量,用以解决发送速率过快导致接收方不能接收的问题。所以流量控制是点对点控制。
- TCP是双工协议,双方可以同时通信,所以发送方接收方各自维护一个发送窗和接收窗。
- 发送窗:用来限制发送方可以发送的数据大小,其中发送窗口的大小由接收端返回的TCP报文段中窗口字段来控制,接收方通过此字段告知发送方自己的缓冲(受系统、硬件等限制)大小。
- 接收窗:用来标记可以接收的数据大小。
- TCP是流数据,发送出去的数据流可以被分为以下四部分:已发送且被确认部分 | 已发送未被确认部分 | 未发送但可发送部分 | 不可发送部分,其中发送窗 = 已发送未确认部分 + 未发但可发送部分。接收到的数据流可分为:已接收 | 未接收但准备接收 | 未接收不准备接收。接收窗 = 未接收但准备接收部分。
- 发送窗内数据只有当接收到接收端某段发送数据的ACK响应时才移动发送窗,左边缘紧贴刚被确认的数据。接收窗也只有接收到数据且最左侧连续时才移动接收窗口。
-
TCP拥塞控制
拥塞控制目的是防止数据过多注入到网络中导致网络资源(路由器、交换机等)过载。因为拥塞控制涉及网络链路全局,所以属于全局控制。控制拥塞使用拥塞窗口。
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。
慢热启动算法 – Slow Start
所谓慢启动,也就是TCP连接刚建立,一点一点地提速,试探一下网络的承受能力,以免直接扰乱了网络通道的秩序。
慢启动算法:
- 连接建好的开始先初始化拥塞窗口cwnd大小为1,表明可以传一个MSS大小的数据。
- 每当收到一个ACK,cwnd大小加一,呈线性上升。
- 每当过了一个往返延迟时间RTT(Round-Trip Time),cwnd大小直接翻倍,乘以2,呈指数让升。
- 还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”
拥塞避免算法 – Congestion Avoidance
如同前边说的,当拥塞窗口大小cwnd大于等于慢启动阈值ssthresh后,就进入拥塞避免算法。算法如下:
- 收到一个ACK,则cwnd = cwnd + 1 / cwnd
- 每当过了一个往返延迟时间RTT,cwnd大小加一。
过了慢启动阈值后,拥塞避免算法可以避免窗口增长过快导致窗口拥塞,而是缓慢的增加调整到网络的最佳值。
拥塞发生状态时的算法
一般来说,TCP拥塞控制默认认为网络丢包是由于网络拥塞导致的,所以一般的TCP拥塞控制算法以丢包为网络进入拥塞状态的信号。对于丢包有两种判定方式,一种是超时重传RTO[Retransmission Timeout]超时,另一个是收到三个重复确认ACK。
超时重传是TCP协议保证数据可靠性的一个重要机制,其原理是在发送一个数据以后就开启一个计时器,在一定时间内如果没有得到发送数据报的ACK报文,那么就重新发送数据,直到发送成功为止。
但是如果发送端接收到3个以上的重复ACK,TCP就意识到数据发生丢失,需要重传。这个机制不需要等到重传定时器超时,所以叫 做快速重传,而快速重传后没有使用慢启动算法,而是拥塞避免算法,所以这又叫做快速恢复算法。
超时重传RTO[Retransmission Timeout]超时,TCP会重传数据包。TCP认为这种情况比较糟糕,反应也比较强烈:
- 由于发生丢包,将慢启动阈值ssthresh设置为当前cwnd的一半,即ssthresh = cwnd / 2.
- cwnd重置为1
- 进入慢启动过程
最为早期的TCP Tahoe算法就只使用上述处理办法,但是由于一丢包就一切重来,导致cwnd又重置为1,十分不利于网络数据的稳定传递。
所以,TCP Reno算法进行了优化。当收到三个重复确认ACK时,TCP开启快速重传Fast Retransmit算法,而不用等到RTO超时再进行重传:
- cwnd大小缩小为当前的一半
- ssthresh设置为缩小后的cwnd大小
- 然后进入快速恢复算法Fast Recovery。
快速恢复算法 – Fast Recovery
TCP Tahoe是早期的算法,所以没有快速恢复算法,而Reno算法有。在进入快速恢复之前,cwnd和ssthresh已经被更改为原有cwnd的一半。快速恢复算法的逻辑如下:
- cwnd = cwnd + 3 MSS,加3 MSS的原因是因为收到3个重复的ACK。
- 重传DACKs指定的数据包。
- 如果再收到DACKs,那么cwnd大小增加一。
- 如果收到新的ACK,表明重传的包成功了,那么退出快速恢复算法。将cwnd设置为ssthresh,然后进入拥塞避免算法。
-
流量控制和拥塞控制的区别
- 流量控制属于通信双方协商;拥塞控制涉及通信链路全局。
- 流量控制需要通信双方各维护一个发送窗、一个接收窗,对任意一方,接收窗大小由自身决定,发送窗大小由接收方响应的TCP报文段中窗口值确定;拥塞控制的拥塞窗口大小变化由试探性发送一定数据量数据探查网络状况后而自适应调整。
- 实际最终发送窗口 = min{流控发送窗口,拥塞窗口}。
-
TCP 协议如何保证可靠传输
- 确认和重传:接收方收到报文就会确认,发送方发送一段时间后没有收到确认就会重传。
- 数据校验:TCP报文头有校验和,用于校验报文是否损坏。
- 对失序数据包重排序:既然 TCP 报文段作为 IP 数据报来传输,而 IP 数据报的到达可能会失序,因此 TCP 报文段的到达也可能会失序。TCP 将对失序数据进行重新排序,才交给应用层;
- 流量控制:当接收方来不及处理发送方的数据,能通过滑动窗口,提示发送方降低发送的速率,防止包丢失。
- 拥塞控制:当网络拥塞时,通过拥塞窗口,减少数据的发送,防止包丢失。
- **丢弃重复数据:**对于重复数据,能够丢弃重复数据;
- **应答机制:**当 TCP 收到发自 TCP 连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒;
-
如何优化TCP
从三个角度来阐述提升 TCP 的策略,分别是:
- TCP 三次握手的性能提升;
- TCP 四次挥手的性能提升;
- TCP 数据传输的性能提升;
TCP 三次握手的性能提升
客户端的优化
当客户端发起 SYN 包时,可以通过
tcp_syn_retries控制其重传的次数。服务端的优化
当服务端 SYN 半连接队列溢出后,会导致后续连接被丢弃,可以通过
netstat -s观察半连接队列溢出的情况,如果 SYN 半连接队列溢出情况比较严重,可以通过tcp_max_syn_backlog、somaxconn、backlog参数来调整 SYN 半连接队列的大小。服务端回复 SYN+ACK 的重传次数由
tcp_synack_retries参数控制。如果遭受 SYN 攻击,应把tcp_syncookies参数设置为 1,表示仅在 SYN 队列满后开启 syncookie 功能,可以保证正常的连接成功建立。服务端收到客户端返回的 ACK,会把连接移入 accpet 队列,等待进行调用 accpet() 函数取出连接。
可以通过
ss -lnt查看服务端进程的 accept 队列长度,如果 accept 队列溢出,系统默认丢弃 ACK,如果可以把tcp_abort_on_overflow设置为 1 ,表示用 RST 通知客户端连接建立失败。如果 accpet 队列溢出严重,可以通过 listen 函数的
backlog参数和somaxconn系统参数提高队列大小,accept 队列长度取决于 min(backlog, somaxconn)。绕过三次握手
TCP Fast Open 功能可以绕过三次握手,使得 HTTP 请求减少了 1 个 RTT 的时间,Linux 下可以通过
tcp_fastopen开启该功能,同时必须保证服务端和客户端同时支持。TCP 四次挥手的性能提升
客户端和服务端双方都可以主动断开连接,通常先关闭连接的一方称为主动方,后关闭连接的一方称为被动方。
针对 TCP 四次挥手的优化,我们需要根据主动方和被动方四次挥手状态变化来调整系统 TCP 内核参数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vIOGjqUw-1678081583394)(https://cdn.xiaolincoding.com/gh/xiaolincoder/ImageHost/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/TCP-%E5%8F%82%E6%95%B0/39.jpg)]
主动方的优化
主动发起 FIN 报文断开连接的一方,如果迟迟没收到对方的 ACK 回复,则会重传 FIN 报文,重传的次数由
tcp_orphan_retries参数决定。当主动方收到 ACK 报文后,连接就进入 FIN_WAIT2 状态,根据关闭的方式不同,优化的方式也不同:
- 如果这是 close 函数关闭的连接,那么它就是孤儿连接。如果
tcp_fin_timeout秒内没有收到对方的 FIN 报文,连接就直接关闭。同时,为了应对孤儿连接占用太多的资源,tcp_max_orphans定义了最大孤儿连接的数量,超过时连接就会直接释放。 - 反之是 shutdown 函数关闭的连接,则不受此参数限制;
当主动方接收到 FIN 报文,并返回 ACK 后,主动方的连接进入 TIME_WAIT 状态。这一状态会持续 1 分钟,为了防止 TIME_WAIT 状态占用太多的资源,
tcp_max_tw_buckets定义了最大数量,超过时连接也会直接释放。当 TIME_WAIT 状态过多时,还可以通过设置
tcp_tw_reuse和tcp_timestamps为 1 ,将 TIME_WAIT 状态的端口复用于作为客户端的新连接,注意该参数只适用于客户端。被动方的优化
被动关闭的连接方应对非常简单,它在回复 ACK 后就进入了 CLOSE_WAIT 状态,等待进程调用 close 函数关闭连接。因此,出现大量 CLOSE_WAIT 状态的连接时,应当从应用程序中找问题。
当被动方发送 FIN 报文后,连接就进入 LAST_ACK 状态,在未等到 ACK 时,会在
tcp_orphan_retries参数的控制下重发 FIN 报文。TCP 数据传输的性能提升
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yvueg1Zy-1678081583395)(https://cdn.xiaolincoding.com/gh/xiaolincoder/ImageHost/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/TCP-%E5%8F%82%E6%95%B0/49.jpg)]
TCP 可靠性是通过 ACK 确认报文实现的,又依赖滑动窗口提升了发送速度也兼顾了接收方的处理能力。
可是,默认的滑动窗口最大值只有 64 KB,不满足当今的高速网络的要求,要想提升发送速度必须提升滑动窗口的上限,在 Linux 下是通过设置
tcp_window_scaling为 1 做到的,此时最大值可高达 1GB。滑动窗口定义了网络中飞行报文的最大字节数,当它超过带宽时延积时,网络过载,就会发生丢包。而当它小于带宽时延积时,就无法充分利用网络带宽。因此,滑动窗口的设置,必须参考带宽时延积。
内核缓冲区决定了滑动窗口的上限,缓冲区可分为:发送缓冲区 tcp_wmem 和接收缓冲区 tcp_rmem。
Linux 会对缓冲区动态调节,我们应该把缓冲区的上限设置为带宽时延积。发送缓冲区的调节功能是自动打开的,而接收缓冲区需要把 tcp_moderate_rcvbuf 设置为 1 来开启。其中,调节的依据是 TCP 内存范围 tcp_mem。
但需要注意的是,如果程序中的 socket 设置 SO_SNDBUF 和 SO_RCVBUF,则会关闭缓冲区的动态整功能,所以不建议在程序设置它俩,而是交给内核自动调整比较好。
-
UDP协议
提供无连接的,尽最大努力的数据传输服务(不保证数据传输的可靠性)。
特点
(1)UDP是无连接的传输层协议;
(2)UDP使用尽最大努力交付,不保证可靠交付;
(3)UDP是面向报文的,对应用层交下来的报文,不合并,不拆分,保留原报文的边界;
(4)UDP没有拥塞控制,因此即使网络出现拥塞也不会降低发送速率;
(5)UDP支持一对一 一对多 多对多的交互通信;
(6)UDP的首部开销小,只有8字节.
-
UDP 如何实现可靠传输
UDP不属于连接协议,具有资源消耗少,处理速度快的优点,所以通常音频,视频和普通数据在传送时,使用UDP较多,因为即使丢失少量的包,也不会对接受结果产生较大的影响。
传输层无法保证数据的可靠传输,只能通过应用层来实现了。实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
最简单的方式是在应用层模仿传输层TCP的可靠性传输。下面不考虑拥塞处理,可靠UDP的简单设计。
- 1、添加seq/ack机制,确保数据发送到对端
- 2、添加发送和接收缓冲区,主要是用户超时重传。
- 3、添加超时重传机制。
详细说明:送端发送数据时,生成一个随机seq=x,然后每一片按照数据大小分配seq。数据到达接收端后接收端放入缓存,并发送一个ack=x的包,表示对方已经收到了数据。发送端收到了ack包后,删除缓冲区对应的数据。时间到后,定时任务检查是否需要重传数据。
目前有如下开源程序利用udp实现了可靠的数据传输。分别为*RUDP、RTP、UDT*。
-
TCP和UDP的区别
(1)TCP是可靠传输,UDP是不可靠传输;
(2)TCP面向连接,UDP无连接;
(3)TCP传输数据有序,UDP不保证数据的有序性;
(4)TCP不保存数据边界,UDP保留数据边界;
(5)TCP传输速度相对UDP较慢;
(6)TCP有流量控制和拥塞控制,UDP没有;
(7)TCP是重量级协议,UDP是轻量级协议;
(8)TCP首部较长20字节,UDP首部较短8字节;
TCP应用场景:
效率要求相对低,但对准确性要求相对高的场景。因为传输中需要对数据确认、重发、排序等操作,相比之下效率没有UDP高。举几个例子:文件传输(准确高要求高、但是速度可以相对慢)、接受邮件、远程登录。
UDP应用场景:
效率要求相对高,对准确性要求相对低的场景。举几个例子:QQ聊天、在线视频、网络语音电话(即时通讯,速度要求高,但是出现偶尔断续不是太大问题,并且此处完全不可以使用重发机制)、广播通信(广播、多播)
基于TCP和UDP的常用协议
HTTP、HTTPS、FTP、TELNET、SMTP(简单邮件传输协议)协议基于可靠的TCP协议。DNS、DHCP、TFTP、SNMP(简单网络管理协议)、RIP基于不可靠的UDP协议
-
TCP黏包和拆包
TCP黏包
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
- 由TCP连接复用造成的粘包问题。
- 因为TCP默认会使用Nagle算法,此算法会导致粘包问题。
- 只有上一个分组得到确认,才会发送下一个分组;
- 收集多个小分组,在一个确认到来时一起发送。
- 数据包过大造成的粘包问题。
- 流量控制,拥塞控制也可能导致粘包。
- 接收方不及时接收缓冲区的包,造成多个包接收
解决:
- Nagle算法问题导致的,需要结合应用场景适当关闭该算法
- 尾部标记序列。通过特殊标识符表示数据包的边界,例如\n\r,\t,或者一些隐藏字符。
- 头部标记分步接收。在TCP报文的头部加上表示数据长度。
- 应用层发送数据时定长发送。
- 特殊字符控制;
-
URI和 URL之间的区别
URL,即统一资源定位符 (Uniform Resource Locator ),URL 其实就是我们平时上网时输入的网址,它标识一个互联网资源,并指定对其进行操作或获取该资源的方法。例如 https://leetcode-cn.com/problemset/all/ 这个 URL,标识一个特定资源并表示该资源的某种形式是可以通过 HTTP 协议从相应位置获得。
而 URI 则是统一资源标识符,URL 是 URI 的一个子集,两者都定义了资源是什么,而 URL 还定义了如何能访问到该资源。URI 是一种语义上的抽象概念,可以是绝对的,也可以是相对的,而URL则必须提供足够的信息来定位,是绝对的。简单地说,只要能唯一标识资源的就是 URI,在 URI 的基础上给出其资源的访问方式的就是 URL。
4.4 IP协议
-
IP协议的作用
网络层的主要作用是:实现主机与主机之间的通信,也叫点对点(end to end)通信。
IP协议的作用主要是在相互连接的网络之间传递IP数据包,主要功能有两方面,分别是寻址与路由和分段与重组,而在IP协议当中,最重要的就是TTL(IP允许通过的最大网段数量)字段(八位),规定该数据包能穿过几个路由之后才会被抛弃。
-
IPV4和IPV6
IPv4 的地址是 32 位的,大约可以提供 42 亿个地址,但是早在 2011 年 IPv4 地址就已经被分配完了。
IPv6 不仅仅只是可分配的地址变多了,它还有非常多的亮点。
- IPv6 可自动配置,即使没有 DHCP 服务器也可以实现自动分配IP地址,真是便捷到即插即用啊。
- IPv6 包头包首部长度采用固定的值
40字节,去掉了包头校验和,简化了首部结构,减轻了路由器负荷,大大提高了传输的性能。 - IPv6 有应对伪造 IP 地址的网络安全功能以及防止线路窃听的功能,大大提升了安全性。
IPv6 地址的结构
IPv6 类似 IPv4,也是通过 IP 地址的前几位标识 IP 地址的种类。
IPv6 的地址主要有以下类型地址:
- 单播地址,用于一对一的通信
- 组播地址,用于一对多的通信
- 任播地址,用于通信最近的节点,最近的节点是由路由协议决定
- 没有广播地址
IPv6 单播地址类型
对于一对一通信的 IPv6 地址,主要划分了三类单播地址,每类地址的有效范围都不同。
- 在同一链路单播通信,不经过路由器,可以使用链路本地单播地址,IPv4 没有此类型
- 在内网里单播通信,可以使用唯一本地地址,相当于 IPv4 的私有 IP
- 在互联网通信,可以使用全局单播地址,相当于 IPv4 的公有 IP
IPv6 相比 IPv4 的首部改进:
- 取消了首部校验和字段。 因为在数据链路层和传输层都会校验,因此 IPv6 直接取消了 IP 的校验。
- 取消了分片/重新组装相关字段。 分片与重组是耗时的过程,IPv6 不允许在中间路由器进行分片与重组,这种操作只能在源与目标主机,这将大大提高了路由器转发的速度。
- 取消选项字段。 选项字段不再是标准 IP 首部的一部分了,但它并没有消失,而是可能出现在 IPv6 首部中的「下一个首部」指出的位置上。删除该选项字段使的 IPv6 的首部成为固定长度的
40字节。
-
IPV4 地址不够如何解决
目前主要有以下两种方式:
1、其实我们平时上网,电脑的 IP 地址都是属于私有地址,我无法出网关,我们的数据都是通过网关来中转的,这个其实 NAT 协议,可以用来暂缓 IPV4 地址不够。
2、IPv6 :作为接替 IPv4 的下一代互联网协议,其可以实现 2 的 128 次方个地址,这个数量级,即使给地球上每一颗沙子都分配一个IP地址,该协议能从根本上解决 IPv4 地址不够用的问题。
-
IP地址和MAC地址有什么区别?各自的用处?
简单着说,IP 地址主要用来网络寻址用的,就是大致定位你在哪里,而 MAC 地址,则是身份的唯一象征,通过 MAC 来唯一确认这人是不是就是你,MAC 地址不具备寻址的功能。
-
网络层常见协议
议 名称 作用 IP 网际协议 IP协议不但定义了数据传输时的基本单元和格式,还定义了数据报的递交方法和路由选择 ICMP Internet控制报文协议 ICMP就是一个“错误侦测与回报机制”,其目的就是让我们能够检测网路的连线状况﹐也能确保连线的准确性,是ping和traceroute的工作协议 RIP 路由信息协议 使用“跳数”(即metric)来衡量到达目标地址的路由距离 IGMP Internet组管理协议 用于实现组播、广播等通信 -
什么是DNS和工作原理
DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。
通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。
工作原理
将主机域名转换为ip地址,属于应用层协议,使用UDP传输。
过程: 总结: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。 一、主机向本地域名服务器的查询一般都是采用递归查询。 二、本地域名服务器向根域名服务器的查询的迭代查询。
- 当用户输入域名时,浏览器先检查自己的缓存中是否包含这个域名映射的ip地址,有解析结束。 2)若没命中,则检查操作系统缓存(如Windows的hosts)中有没有解析过的结果,有解析结束。 3)若无命中,则请求本地域名服务器解析(LDNS)。 4)若LDNS没有命中就直接跳到根域名服务器请求解析。根域名服务器返回给LDNS一个 主域名服务器地址。 5)此时LDNS再发送请求给上一步返回的gTLD( 通用顶级域), 接受请求的gTLD查找并返回这个域名对应的Name Server的地址 6)Name Server根据映射关系表找到目标ip,返回给LDNS
- LDNS缓存这个域名和对应的ip, 把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
-
DNS负载均衡是什么策略
当一个网站有足够多的用户的时候,假如每次请求的资源都位于同一台机器上面,那么这台机器随时可能会崩掉。处理办法就是用DNS负载均衡技术,它的原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。例如可以根据每台机器的负载量,该机器离用户地理位置的距离等等。
-
数据链路层常见协议
议 名称 作用 ARP 地址解析协议 根据IP地址获取物理地址 RARP 反向地址转换协议 根据物理地址获取IP地址 PPP 点对点协议 主要是用来通过拨号或专线方式建立点对点连接发送数据,使其成为各种主机、网桥和路由器之间简单连接的一种共通的解决方案 -
ARP和RARP协议
RARP
概括: 反向地址转换协议,网络层协议,RARP与ARP工作方式相反。 RARP使只知道自己硬件地址的主机能够知道其IP地址。RARP发出要反向解释的物理地址并希望返回其IP地址,应答包括能够提供所需信息的RARP服务器发出的IP地址。
原理: (1)网络上的每台设备都会有一个独一无二的硬件地址,通常是由设备厂商分配的MAC地址。主机从网卡上读取MAC地址,然后在网络上发送一个RARP请求的广播数据包,请求RARP服务器回复该主机的IP地址。
(2)RARP服务器收到了RARP请求数据包,为其分配IP地址,并将RARP回应发送给主机。
(3)PC1收到RARP回应后,就使用得到的IP地址进行通讯。
ARP
网络层的 ARP 协议完成了 IP 地址与物理地址的映射。首先,每台主机都会在自己的 ARP 缓冲区中建立一个 ARP 列表,以表示 IP 地址和 MAC 地址的对应关系。当源主机需要将一个数据包要发送到目的主机时,会首先检查自己 ARP 列表中是否存在该 IP 地址对应的 MAC 地址:如果有,就直接将数据包发送到这个 MAC 地址;如果没有,就向本地网段发起一个 ARP 请求的广播包,查询此目的主机对应的 MAC 地址。
此 ARP 请求数据包里包括源主机的 IP 地址、硬件地址、以及目的主机的 IP 地址。网络中所有的主机收到这个 ARP 请求后,会检查数据包中的目的 IP 是否和自己的 IP 地址一致。如果不相同就忽略此数据包;如果相同,该主机首先将发送端的 MAC 地址和 IP 地址添加到自己的 ARP 列表中,如果 ARP 表中已经存在该 IP 的信息,则将其覆盖,然后给源主机发送一个 ARP 响应数据包,告诉对方自己是它需要查找的 MAC 地址;源主机收到这个 ARP 响应数据包后,将得到的目的主机的 IP 地址和 MAC 地址添加到自己的 ARP 列表中,并利用此信息开始数据的传输。如果源主机一直没有收到 ARP 响应数据包,表示 ARP 查询失败
-
DHCP/NAT协议
DHCP
DHCP 在生活中我们是很常见的了,我们的电脑通常都是通过 DHCP 动态获取 IP 地址,大大省去了配 IP 信息繁琐的过程。
DHCP 客户端进程监听的是 68 端口号,DHCP 服务端进程监听的是 67 端口号。
这 4 个步骤:
- 客户端首先发起 DHCP 发现报文(DHCP DISCOVER) 的 IP 数据报,由于客户端没有 IP 地址,也不知道 DHCP 服务器的地址,所以使用的是 UDP 广播通信,其使用的广播目的地址是 255.255.255.255(端口 67) 并且使用 0.0.0.0(端口 68) 作为源 IP 地址。DHCP 客户端将该 IP 数据报传递给链路层,链路层然后将帧广播到所有的网络中设备。
- DHCP 服务器收到 DHCP 发现报文时,用 DHCP 提供报文(DHCP OFFER) 向客户端做出响应。该报文仍然使用 IP 广播地址 255.255.255.255,该报文信息携带服务器提供可租约的 IP 地址、子网掩码、默认网关、DNS 服务器以及 IP 地址租用期。
- 客户端收到一个或多个服务器的 DHCP 提供报文后,从中选择一个服务器,并向选中的服务器发送 DHCP 请求报文(DHCP REQUEST进行响应,回显配置的参数。
- 最后,服务端用 DHCP ACK 报文对 DHCP 请求报文进行响应,应答所要求的参数。
一旦客户端收到 DHCP ACK 后,交互便完成了,并且客户端能够在租用期内使用 DHCP 服务器分配的 IP 地址。
DHCP 交互中,全程都是使用 UDP 广播通信。
NAT
网络地址转换 NAT 的,缓解了 IPv4 地址耗尽的问题。简单的来说 NAT 就是同个公司、家庭、教室内的主机对外部通信时,把私有 IP 地址转换成公有 IP 地址。
由于 NAT/NAPT 都依赖于自己的转换表,因此会有以下的问题:
- 外部无法主动与 NAT 内部服务器建立连接,因为 NAPT 转换表没有转换记录。
- 转换表的生成与转换操作都会产生性能开销。
- 通信过程中,如果 NAT 路由器重启了,所有的 TCP 连接都将被重置。
如何解决 NAT 潜在的问题呢?
解决的方法主要有两种方法。
第一种就是改用 IPv6、第二种 NAT 穿透技术
-
ICMP/IGMP协议
ICMP
ICMP 全称是 Internet Control Message Protocol,也就是互联网控制报文协议。
ICMP主要的功能包括:确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。在
IP通信中如果某个IP包因为某种原因未能达到目标地址,那么这个具体的原因将由 ICMP 负责通知。ICMP 大致可以分为两大类:
- 一类是用于诊断的查询消息,也就是「查询报文类型」
- 另一类是通知出错原因的错误消息,也就是「差错报文类型」
IGMP
我们知道了组播地址,也就是 D 类地址,既然是组播,那就说明是只有一组的主机能收到数据包,不在一组的主机不能收到数组包,怎么管理是否是在一组呢?那么,就需要
IGMP协议了。IGMP 是因特网组管理协议,工作在主机(组播成员)和最后一跳路由之间
- IGMP 报文向路由器申请加入和退出组播组,默认情况下路由器是不会转发组播包到连接中的主机,除非主机通过 IGMP 加入到组播组,主机申请加入到组播组时,路由器就会记录 IGMP 路由器表,路由器后续就会转发组播包到对应的主机了。
- IGMP 报文采用 IP 封装,IP 头部的协议号为 2,而且 TTL 字段值通常为 1,因为 IGMP 是工作在主机与连接的路由器之间。
常规查询与响应工作机制
- 路由器会周期性发送目的地址为
224.0.0.1(表示同一网段内所有主机和路由器) IGMP 常规查询报文。 - 主机1 和 主机 3 收到这个查询,随后会启动「报告延迟计时器」,计时器的时间是随机的,通常是 0~10 秒,计时器超时后主机就会发送 IGMP 成员关系报告报文(源 IP 地址为自己主机的 IP 地址,目的 IP 地址为组播地址)。如果在定时器超时之前,收到同一个组内的其他主机发送的成员关系报告报文,则自己不再发送,这样可以减少网络中多余的 IGMP 报文数量。
- 路由器收到主机的成员关系报文后,就会在 IGMP 路由表中加入该组播组,后续网络中一旦该组播地址的数据到达路由器,它会把数据包转发出去。
离开组播组工作机制
离开组播组的情况一,网段中仍有该组播组:
- 主机 1 要离开组 224.1.1.1,发送 IGMPv2 离组报文,报文的目的地址是 224.0.0.2(表示发向网段内的所有路由器)
- 路由器 收到该报文后,以 1 秒为间隔连续发送 IGMP 特定组查询报文(共计发送 2 个),以便确认该网络是否还有 224.1.1.1 组的其他成员。
- 主机 3 仍然是组 224.1.1.1 的成员,因此它立即响应这个特定组查询。路由器知道该网络中仍然存在该组播组的成员,于是继续向该网络转发 224.1.1.1 的组播数据包。
离开组播组的情况一,网段中仍有该组播组:
- 主机 1 要离开组播组 224.1.1.1,发送 IGMP 离组报文。
- 路由器收到该报文后,以 1 秒为间隔连续发送 IGMP 特定组查询报文(共计发送 2 个)。此时在该网段内,组 224.1.1.1 已经没有其他成员了,因此没有主机响应这个查询。
- 一定时间后,路由器认为该网段中已经没有 224.1.1.1 组播组成员了,将不会再向这个网段转发该组播地址的数据包。
-
ICMP 有哪些应用
ICMP 主要有两个应用,一个是 Ping,一个是 Traceroute。
1. Ping
Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
Ping 的原理是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率。
2. Traceroute
Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
- 源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文;
- 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
- 不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
- 之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
4.5 其他面试题
-
应用层常见协议知道多少
协议 名称 默认端口 底层协议 HTTP 超文本传输协议 80 TCP HTTPS 超文本传输安全协议 443 TCP Telnet 远程登录服务的标准协议 23 TCP FTP 文件传输协议 20传输和21连接 TCP TFTP 简单文件传输协议 69 UDP SMTP 简单邮件传输协议(发送用) 25 TCP POP 邮局协议(接收用) 110 TCP DNS 域名解析服务 53 服务器间进行域传输的时候用TCP 客户端查询DNS服务器时用 UDP -
常见的HTTP状态码有哪些
状态码 类别 含义 1XX Informational(信息性状态码) 接收的请求正在处理 2XX Success(成功状态码) 请求正常处理完毕 3XX Redirection(重定向状态码) 需要进行附加操作以完成请求 4XX Client Error(客户端错误状态码) 服务器无法处理请求 5XX Server Error(服务器错误状态码) 服务器处理请求出 1xx 信息
100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
2xx 成功
- 200 OK
- 204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
- 206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
3xx 重定向
- 301 Moved Permanently :永久性重定向
- 302 Found :临时性重定向
- 303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
- 304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
- 307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
4xx 客户端错误
- 400 Bad Request :请求报文中存在语法错误。
- 401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
- 403 Forbidden :请求被拒绝。
- 404 Not Found
5xx 服务器错误
- 500 Internal Server Error :服务器正在执行请求时发生错误。
- 503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
-
OSI的七层模型和功能
简要概括
- 物理层:底层数据传输,如网线;网卡标准。
- 数据链路层:定义数据的基本格式,如何传输,如何标识;如网卡MAC地址。
- 网络层:定义IP编址,定义路由功能;如不同设备的数据转发。
- 传输层:端到端传输数据的基本功能;如 TCP、UDP。
- 会话层:控制应用程序之间会话能力;如不同软件数据分发给不同软件。
- 表示层:数据格式标识,基本压缩加密功能。
- 应用层:各种应用软件,包括 Web 应用。
说明
- 在四层,既传输层数据被称作段(Segments);
- 三层网络层数据被称做包(Packages);
- 二层数据链路层时数据被称为帧(Frames);
- 一层物理层时数据被称为比特流(Bits)。
总结
- 网络七层模型是一个标准,而非实现。
- 网络四层模型是一个实现的应用模型。
- 网络四层模型由七层模型简化合并而来。
-
网络五层模型,每一层的职责
- 物理层
一台计算机与另一台计算机要进行通信,第一件要做的事是什么?当然是要把这台计算机与另外的其他计算机连起来啊,这样,我们才能把数据传输过去。例如可以通过光纤啊,电缆啊,双绞线啊等介质把他们连接起来,然后才能进行通信。
物理层负责把两台计算机连起来,然后在计算机之间通过高低电频来传送0,1这样的电信号。
- 数据链路层
物理层它只是单纯着负责把计算机连接起来,并且在计算机之间传输0,1这样的电信号。如果这些0,1组合的传送毫无规则的话,计算机是解读不了的。
因此,我们需要制定一套规则来进行0,1的传送。例如多少个电信号为一组啊,每一组信号应该如何标识才能让计算机读懂啊等等。
于是,有了以太网协议。
1. 以太网协议
以太网协议规定,一组电信号构成一个数据包,我们把这个数据包称之为帧。每一个桢由标头(Head)和数据(Data)两部分组成。
帧的大小一般为 64 – 1518 个字节。假如需要传送的数据很大的话,就分成多个桢来进行传送。
对于表头和数据这两个部分,他们存放的都是一些什么数据呢?我猜你眯着眼睛都能想到他们应该放什么数据。 毫无疑问,我们至少得知道这个桢是谁发送,发送给谁的等这些信息吧?所以标头部分主要是一些说明数据,例如发送者,接收者等信息。而数据部分则是这个数据包具体的,想给接守者的内容。
把一台计算的的数据通过物理层和链路层发送给另一台计算机,究竟是谁发给谁的,计算机与计算机之间如何区分,,你总得给他们一个唯一的标识吧?
于是,MAC 地址出现了。
2. MAC 地址
连入网络的每一个计算机都会有网卡接口,每一个网卡都会有一个唯一的地址,这个地址就叫做 MAC 地址。计算机之间的数据传送,就是通过 MAC 地址来唯一寻找、传送的。
MAC地址 由 48 个二进制位所构成,在网卡生产时就被唯一标识了。
3. 广播与ARP协议
(1). 广播
如图,假如计算机 A 知道了计算机 B 的 MAC 地址,然后计算机 A 想要给计算机 B 传送数据,虽然计算机 A 知道了计算机 B 的 MAC 地址,可是它要怎么给它传送数据呢?计算机 A 不仅连着计算机 B,而且计算机 A 也还连着其他的计算机。 虽然计算机 A 知道计算机 B 的 MAC 地址,可是计算机 A 却不知道知道计算机 B 是分布在哪边路线上,为了解决这个问题,于是,有了广播的出现。
在同一个子网中,计算机 A 要向计算机 B 发送一个数据包,这个数据包会包含接收者的 MAC 地址。当发送时,计算机 A 是通过广播的方式发送的,这时同一个子网中的计算机 C, D 也会收到这个数据包的,然后收到这个数据包的计算机,会把数据包的 MAC 地址取出来,与自身的 MAC 地址对比,如果两者相同,则接受这个数据包,否则就丢弃这个数据包。这种发送方式我们称之为广播,就像我们平时在广场上通过广播的形式呼叫某个人一样,如果这个名字是你,你就理会一下,如果不是你,你就当作听不见。
(2). ARP 协议。
那么问题来了,计算机 A 是如何知道计算机 B 的 MAC 地址的呢?这个时候就得由 ARP 协议这个家伙来解决了,不过 ARP 协议会涉及到IP地址,我们下面才会扯到IP地址。因此我们先放着,就当作是有这么一个 ARP 协议,通过它我们可以知道子网中其他计算机的 MAC 地址。
3. 网络层
上面我们有说到子网这个关键词,实际上我们所处的网络,是由无数个子网络构成的。广播的时候,也只有同一个子网里面的计算机能够收到。
假如没有子网这种划分的话,计算机 A 通过广播的方式发一个数据包给计算机 B , 其他所有计算机也都能收到这个数据包,然后进行对比再舍弃。世界上有那么多它计算机,每一台计算机都能收到其他所有计算机的数据包,那就不得了了。那还不得奔溃。 因此产生了子网这么一个东西。
那么问题来了,我们如何区分哪些 MAC 地址是属于同一个子网的呢?假如是同一个子网,那我们就用广播的形式把数据传送给对方,如果不是同一个子网的,我们就会把数据发给网关,让网关进行转发。
为了解决这个问题,于是,有了 IP 协议。
1. IP协议
IP协议,它所定义的地址,我们称之为IP地址。IP协议有两种版本,一种是 IPv4,另一种是 IPv6。不过我们目前大多数用的还是 IPv4,我们现在也只讨论 IPv4 这个版本的协议。
这个 IP 地址由 32 位的二进制数组成,我们一般把它分成4段的十进制表示,地址范围为0.0.0.0~255.255.255.255。
每一台想要联网的计算机都会有一个IP地址。这个IP地址被分为两部分,前面一部分代表网络部分,后面一部分代表主机部分。并且网络部分和主机部分所占用的二进制位数是不固定的。
可是问题来了,你怎么知道网络部分是占几位,主机部分又是占几位呢?也就是说,单单从两台计算机的IP地址,我们是无法判断他们的是否处于同一个子网中的。
这就引申出了另一个关键词————子网掩码。子网掩码和IP地址一样也是 32 位二进制数,不过它的网络部分规定全部为 1,主机部分规定全部为 0.也就是说,假如上面那两个IP地址的网络部分为 24 位,主机部分为 8 位的话,那他们的子网掩码都为 11111111.11111111.11111111.00000000,即255.255.255.0。

那有了子网掩码,如何来判端IP地址是否处于同一个子网中呢。显然,知道了子网掩码,相当于我们知道了网络部分是几位,主机部分是几位。我们只需要把 IP 地址与它的子网掩码做与(and)运算,然后把各自的结果进行比较就行了,如果比较的结果相同,则代表是同一个子网,否则不是同一个子网。
2. ARP协议
有了上面IP协议的知识,我们回来讲一下ARP协议。
有了两台计算机的IP地址与子网掩码,我们就可以判断出它们是否处于同一个子网之中了。
假如他们处于同一个子网之中,计算机A要给计算机B发送数据时。我们可以通过ARP协议来得到计算机B的MAC地址。
ARP协议也是通过广播的形式给同一个子网中的每台电脑发送一个数据包(当然,这个数据包会包含接收方的IP地址)。对方收到这个数据包之后,会取出IP地址与自身的对比,如果相同,则把自己的MAC地址回复给对方,否则就丢弃这个数据包。这样,计算机A就能知道计算机B的MAC地址了。
可能有人会问,知道了MAC地址之后,发送数据是通过广播的形式发送,询问对方的MAC地址也是通过广播的形式来发送,那其他计算机怎么知道你是要传送数据还是要询问MAC地址呢?其实在询问MAC地址的数据包中,在对方的MAC地址这一栏中,填的是一个特殊的MAC地址,其他计算机看到这个特殊的MAC地址之后,就能知道广播想干嘛了。
假如两台计算机的IP不是处于同一个子网之中,这个时候,我们就会把数据包发送给网关,然后让网关让我们进行转发传送
3. DNS服务器
这里再说一个问题,我们是如何知道对方计算机的IP地址的呢?这个问题可能有人会觉得很白痴,心想,当然是计算机的操作者来进行输入了。这没错,当我们想要访问某个网站的时候,我们可以输入IP来进行访问,但是我相信绝大多数人是输入一个网址域名的,例如访问百度是输入 www.baidu.com 这个域名。其实当我们输入这个域名时,会有一个叫做DNS服务器的家伙来帮我们解析这个域名,然后返回这个域名对应的IP给我们的。
因此,网络层的功能就是让我们在茫茫人海中,能够找到另一台计算机在哪里,是否属于同一个子网等。
4. 传输层
通过物理层、数据链路层以及网络层的互相帮助,我们已经把数据成功从计算机A传送到计算机B了,可是,计算机B里面有各种各样的应用程序,计算机该如何知道这些数据是给谁的呢?
这个时候,**端口(Port)**这个家伙就上场了,也就是说,我们在从计算机A传数据给计算表B的时候,还得指定一个端口,以供特定的应用程序来接受处理。
传输层的功能就是建立端口到端口的通信。相比网络层的功能是建立主机到主机的通信。
也就是说,只有有了IP和端口,我们才能进行准确着通信。这个时候可能有人会说,我输入IP地址的时候并没有指定一个端口啊。其实呢,对于有些传输协议,已经有设定了一些默认端口了。例如http的传输默认端口是80,这些端口信息也会包含在数据包里的。
传输层最常见的两大协议是 TCP 协议和 UDP 协议,其中 TCP 协议与 UDP 最大的不同就是 TCP 提供可靠的传输,而 UDP 提供的是不可靠传输。
5. 应用层
虽然我们收到了传输层传来的数据,可是这些传过来的数据五花八门,有html格式的,有mp4格式的,各种各样。你确定你能看的懂?
因此我们需要指定这些数据的格式规则,收到后才好解读渲染。例如我们最常见的 Http 数据包中,就会指定该数据包是 什么格式的文件了。
-
一次完整的HTTP请求过程包括哪些内容
第一种回答
- 建立起客户机和服务器连接。
- 建立连接后,客户机发送一个请求给服务器。
- 服务器收到请求给予响应信息。
- 客户端浏览器将返回的内容解析并呈现,断开连接。
第二种回答
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户。
-
谈谈你对停止等待协议的理解
停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组;在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认。主要包括以下几种情况:无差错情况、出现差错情况(超时重传)、确认丢失和确认迟到。
-
谈谈你对 ARQ 协议的理解
自动重传请求 ARQ 协议
停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求 ARQ。
连续 ARQ 协议
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
-
Cookie是什么与用途
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销.。
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
-
Session知识总结
Session 存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
工作原理
session 的工作原理是客户端登录完成之后,服务器会创建对应的 session,session 创建完之后,会把 session 的 id 发送给客户端,客户端再存储到浏览器中。这样客户端每次访问服务器时,都会带着 sessionid,服务器拿到 sessionid 之后,在内存找到与之对应的 session 这样就可以正常工作了。
-
Cookie与Session的对比
Cookie和Session都是客户端与服务器之间保持状态的解决方案 1,存储的位置不同,cookie:存放在客户端,session:存放在服务端。Session存储的数据比较安全 2,存储的数据类型不同 两者都是key-value的结构,但针对value的类型是有差异的 cookie:value只能是字符串类型,session:value是Object类型 3,存储的数据大小限制不同 cookie:大小受浏览器的限制,很多是是4K的大小, session:理论上受当前内存的限制, 4,生命周期的控制 cookie的生命周期当浏览器关闭的时候,就消亡了 (1)cookie的生命周期是累计的,从创建时,就开始计时,20分钟后,cookie生命周期结束, (2)session的生命周期是间隔的,从创建时,开始计时如在20分钟,没有访问session,那么session生命周期被销毁
-
使用 Session 的过程是怎样的
过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
注意:Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
-
保活计时器的作用
除时间等待计时器外,TCP 还有一个保活计时器(keepalive timer)。设想这样的场景:客户已主动与服务器建立了 TCP 连接。但后来客户端的主机突然发生故障。显然,服务器以后就不能再收到客户端发来的数据。应当有措施使服务器不要再白白等待下去。这就需要使用保活计时器了。
服务器每收到一次客户的数据,就重新设置保活计时器,时间的设置通常是两个小时。若两个小时都没有收到客户端的数据,服务端就发送一个探测报文段,以后则每隔 75 秒钟发送一次。若连续发送 10个 探测报文段后仍然无客户端的响应,服务端就认为客户端出了故障,接着就关闭这个连接。
-
DDos攻击、Sql注入、SYN攻击、XSS攻击、CSRF攻击
DDos攻击
客户端向服务端发送请求链接数据包,服务端向客户端发送确认数据包,客户端不向服务端发送确认数据包,服务器一直等待来自客户端的确认 没有彻底根治的办法,除非不使用TCP DDos 预防: 1)限制同时打开SYN半链接的数目 2)缩短SYN半链接的Time out 时间 3)关闭不必要的服务
SQL注入攻击
攻击者在HTTP请求中注入恶意的SQL代码,服务器使用参数构建数据库SQL命令时,恶意SQL被一起构造,并在数据库中执行。 用户登录,输入用户名 lianggzone,密码 ‘ or ‘1’=’1 ,如果此时使用参数构造的方式,就会出现 select * from user where name = ‘lianggzone’ and password = ‘’ or ‘1’=‘1’ 不管用户名和密码是什么内容,使查询出来的用户列表不为空。如何防范SQL注入攻击使用预编译的PrepareStatement是必须的,但是一般我们会从两个方面同时入手。 Web端 1)有效性检验。 2)限制字符串输入的长度。 服务端 1)不用拼接SQL字符串。 2)使用预编译的PrepareStatement。 3)有效性检验。(为什么服务端还要做有效性检验?第一准则,外部都是不可信的,防止攻击者绕过Web端请求) 4)过滤SQL需要的参数中的特殊字符。比如单引号、双引号。
SYN攻击
服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到SYN洪泛攻击。SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server则回复确认包,等待Client确认,由于源地址不存在,因此Server需要不断重发直至超时,这些伪造的SYN包将长时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络拥塞甚至系统瘫痪。SYN 攻击是一种典型的 DoS/DDoS 攻击。
常见的防御 SYN 攻击的方法有如下几种:
- 缩短超时(SYN Timeout)时间
- 增加最大半连接数
- 过滤网关防护
- SYN cookies技术
XSS攻击
跨站点脚本攻击,指攻击者通过篡改网页,嵌入恶意脚本程序,在用户浏览网页时,控制用户浏览器进行恶意操作的一种攻击方式。如何防范XSS攻击 1)前端,服务端,同时需要字符串输入的长度限制。 2)前端,服务端,同时需要对HTML转义处理。将其中的”<”,”>”等特殊字符进行转义编码。 防 XSS 的核心是必须对输入的数据做过滤处理。
CSRF攻击
跨站点请求伪造,指攻击者通过跨站请求,以合法的用户的身份进行非法操作。可以这么理解CSRF攻击:攻击者盗用你的身份,以你的名义向第三方网站发送恶意请求。CRSF能做的事情包括利用你的身份发邮件,发短信,进行交易转账,甚至盗取账号信息
如何防范CSRF攻击
安全框架,例如Spring Security。 token机制。在HTTP请求中进行token验证,如果请求中没有token或者token内容不正确,则认为CSRF攻击而拒绝该请求。 验证码。通常情况下,验证码能够很好的遏制CSRF攻击,但是很多情况下,出于用户体验考虑,验证码只能作为一种辅助手段,而不是最主要的解决方案。 referer识别。在HTTP Header中有一个字段Referer,它记录了HTTP请求的来源地址。如果Referer是其他网站,就有可能是CSRF攻击,则拒绝该请求。但是,服务器并非都能取到Referer。很多用户出于隐私保护的考虑,限制了Referer的发送。在某些情况下,浏览器也不会发送Referer,例如HTTPS跳转到HTTP。 1)验证请求来源地址; 2)关键操作添加验证码; 3)在请求地址添加 token 并验证。
-
服务器出现大量close_wait的连接的原因是什么?有什么解决方法
close_wait状态是在TCP四次挥手的时候收到FIN但是没有发送自己的FIN时出现的,服务器出现大量close_wait状态的原因有两种:
- 服务器内部业务处理占用了过多时间,都没能处理完业务;或者还有数据需要发送;或者服务器的业务逻辑有问题,没有执行close()方法
- 服务器的父进程派生出子进程,子进程继承了socket,收到FIN的时候子进程处理但父进程没有处理该信号,导致socket的引用不为0无法回收
处理方法:
- 停止应用程序
- 修改程序里的bug
-
MTU和MSS分别是什么
MTU:maximum transmission unit,最大传输单元,由硬件规定,如以太网的MTU为1500字节。
MSS:maximum segment size,最大分节大小,为TCP数据包每次传输的最大数据分段大小,一般由发送端向对端TCP通知对端在每个分节中能发送的最大TCP数据。MSS值为MTU值减去IPv4 Header(20 Byte)和TCP header(20 Byte)得到。
-
Ping命令基于什么协议?原理是什么
ping是基于网络层的ICMP协议实现的。通过向对方发送一个ICMP回送请求报文,如果对方主机可达的话会收到该报文,并响应一个ICMP回送回答报文。
扩展:ICMP报文的介绍。ICMP报文分为两个种类:
- ICMP差错报告报文,常见的有
- 终点不可达
- 时间超过
- 参数问题
- 改变路由
- ICMP询问报文
- 回送请求和回答:向特定主机发出回送请求报文,收到回送请求报文的主机响应回送回答报文。
- 时间戳请求和回答:询问对方当前的时间,返回的是一个32位的时间戳。
- ICMP差错报告报文,常见的有
5. 熟悉操作系统
5.1 进程、线程管理
-
进程和线程基础知识
进程:进程是系统进行资源分配和调度的一个独立单位,是系统中的并发执行的单位。
线程:线程是进程的一个实体,也是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,有时又被称为轻权进程或轻量级进程。
-
进程
运行中的程序,就被称为「进程」(Process)。
在一个进程的活动期间至少具备三种基本状态,即运行状态、就绪状态、阻塞状态。
- 运行状态(Running):该时刻进程占用 CPU;
- 就绪状态(Ready):可运行,由于其他进程处于运行状态而暂时停止运行;
- 阻塞状态(Blocked):该进程正在等待某一事件发生(如等待输入/输出操作的完成)而暂时停止运行,这时,即使给它CPU控制权,它也无法运行;
当然,进程还有另外两个基本状态:
- 创建状态(new):进程正在被创建时的状态;
- 结束状态(Exit):进程正在从系统中消失时的状态;
挂起状态可以分为两种:
- 阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现;
- 就绪挂起状态:进程在外存(硬盘),但只要进入内存,即刻立刻运行;
PCB 进程控制块 是进程存在的唯一标识
PCB 具体包含什么信息呢?
进程描述信息:
- 进程标识符:标识各个进程,每个进程都有一个并且唯一的标识符;
- 用户标识符:进程归属的用户,用户标识符主要为共享和保护服务;
进程控制和管理信息:
- 进程当前状态,如 new、ready、running、waiting 或 blocked 等;
- 进程优先级:进程抢占 CPU 时的优先级;
资源分配清单:
- 有关内存地址空间或虚拟地址空间的信息,所打开文件的列表和所使用的 I/O 设备信息。
CPU 相关信息:
- CPU 中各个寄存器的值,当进程被切换时,CPU 的状态信息都会被保存在相应的 PCB 中,以便进程重新执行时,能从断点处继续执行。
-
线程
线程是进程当中的一条执行流程。
同一个进程内多个线程之间可以共享代码段、数据段、打开的文件等资源,但每个线程各自都有一套独立的寄存器和栈,这样可以确保线程的控制流是相对独立的。
线程的实现
主要有三种线程的实现方式:
- 用户线程(*User Thread*):在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理;
- 内核线程(*Kernel Thread*):在内核中实现的线程,是由内核管理的线程;
- 轻量级进程(*LightWeight Process*):在内核中来支持用户线程;
第一种关系是多对一的关系,也就是多个用户线程对应同一个内核线程
第二种是一对一的关系,也就是一个用户线程对应一个内核线程
第三种是多对多的关系,也就是多个用户线程对应到多个内核线程
用户线程的整个线程管理和调度,操作系统是不直接参与的,而是由用户级线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。
线程的优点:
- 一个进程中可以同时存在多个线程;
- 各个线程之间可以并发执行;
- 各个线程之间可以共享地址空间和文件等资源;
线程的缺点:
- 当进程中的一个线程崩溃时,会导致其所属进程的所有线程崩溃(这里是针对 C/C++ 语言,Java语言中的线程奔溃不会造成进程崩溃
内核线程是由操作系统管理的,线程对应的 TCB 自然是放在操作系统里的,这样线程的创建、终止和管理都是由操作系统负责。
-
-
进程/线程上下文切换
-
进程
一个进程切换到另一个进程运行,称为进程的上下文切换。
进程的上下文切换到底是切换什么呢?
进程是由内核管理和调度的,所以进程的切换只能发生在内核态。
所以,进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
通常,会把交换的信息保存在进程的 PCB,当要运行另外一个进程的时候,我们需要从这个进程的 PCB 取出上下文,然后恢复到 CPU 中,这使得这个进程可以继续执行
发生进程上下文切换有哪些场景?
- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,进程就从运行状态变为就绪状态,系统从就绪队列选择另外一个进程运行;
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行;
- 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度;
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行;
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序;
-
线程
-
线程上下文切换的是什么?
这还得看线程是不是属于同一个进程:
- 当两个线程不是属于同一个进程,则切换的过程就跟进程上下文切换一样;
- 当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据;
所以,线程的上下文切换相比进程,开销要小很多。
-
-
-
进程/线程间通信方式
进程间通信(IPC,InterProcess Communication)是指在不同进程之间传播或交换信息。IPC 的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams 等。其中 Socket 和 Streams 支持不同主机上的两个进程 IPC。
管道
- 它是半双工的,具有固定的读端和写端;
- 它只能用于父子进程或者兄弟进程之间的进程的通信;
- 它可以看成是一种特殊的文件,对于它的读写也可以使用普通的 read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
命名管道
- FIFO 可以在无关的进程之间交换数据,与无名管道不同;
- FIFO 有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
消息队列
- 消息队列,是消息的链接表,存放在内核中。一个消息队列由一个标识符 ID 来标识;
- 消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级;
- 消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除;
- 消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
信号量
- 信号量(semaphore)是一个计数器。用于实现进程间的互斥与同步,而不是用于存储进程间通信数据;
- 信号量用于进程间同步,若要在进程间传递数据需要结合共享内存;
- 信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作;
- 每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数;
- 支持信号量组。
共享内存
- 共享内存(Shared Memory),指两个或多个进程共享一个给定的存储区;
- 共享内存是最快的一种 IPC,因为进程是直接对内存进行存取。
Socket通信
前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了。Socket 实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信,可根据创建 Socket 的类型不同,分为三种常见的通信方式,一个是基于 TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。
以上,就是进程间通信的主要机制了。你可能会问了,那线程通信间的方式呢?
同个进程下的线程之间都是共享进程的资源,只要是共享变量都可以做到线程间通信,比如全局变量,所以对于线程间关注的不是通信方式,而是关注多线程竞争共享资源的问题,信号量也同样可以在线程间实现互斥与同步:
- 互斥的方式,可保证任意时刻只有一个线程访问共享资源;
- 同步的方式,可保证线程 A 应在线程 B 之前执行;
-
线程、进程崩溃发生什么
一般来说如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃,为什么系统要让进程崩溃呢,这主要是因为在进程中,各个线程的地址空间是共享的,既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃
崩溃机制
- CPU 执行正常的进程指令
- 调用 kill 系统调用向进程发送信号
- 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
- 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
- 操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出
注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行
-
守护进程、僵尸进程和孤儿进程
守护进程
指在后台运行的,没有控制终端与之相连的进程。它独立于控制终端,周期性地执行某种任务。Linux的大多数服务器就是用守护进程的方式实现的,如web服务器进程http等
创建守护进程要点:
(1)让程序在后台执行。方法是调用fork()产生一个子进程,然后使父进程退出。
(2)调用setsid()创建一个新对话期。控制终端、登录会话和进程组通常是从父进程继承下来的,守护进程要摆脱它们,不受它们的影响,方法是调用setsid()使进程成为一个会话组长。setsid()调用成功后,进程成为新的会话组长和进程组长,并与原来的登录会话、进程组和控制终端脱离。
(3)禁止进程重新打开控制终端。经过以上步骤,进程已经成为一个无终端的会话组长,但是它可以重新申请打开一个终端。为了避免这种情况发生,可以通过使进程不再是会话组长来实现。再一次通过fork()创建新的子进程,使调用fork的进程退出。
(4)关闭不再需要的文件描述符。子进程从父进程继承打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。首先获得最高文件描述符值,然后用一个循环程序,关闭0到最高文件描述符值的所有文件描述符。
(5)将当前目录更改为根目录。
(6)子进程从父进程继承的文件创建屏蔽字可能会拒绝某些许可权。为防止这一点,使用unmask(0)将屏蔽字清零。
(7)处理SIGCHLD信号。对于服务器进程,在请求到来时往往生成子进程处理请求。如果子进程等待父进程捕获状态,则子进程将成为僵尸进程(zombie),从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux下可以简单地将SIGCHLD信号的操作设为SIG_IGN。这样,子进程结束时不会产生僵尸进程。
孤儿进程
如果父进程先退出,子进程还没退出,那么子进程的父进程将变为init进程。(注:任何一个进程都必须有父进程)。
一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程
如果子进程先退出,父进程还没退出,那么子进程必须等到父进程捕获到了子进程的退出状态才真正结束,否则这个时候子进程就成为僵尸进程。
设置僵尸进程的目的是维护子进程的信息,以便父进程在以后某个时候获取。这些信息至少包括进程ID,进程的终止状态,以及该进程使用的CPU时间,所以当终止子进程的父进程调用wait或waitpid时就可以得到这些信息。如果一个进程终止,而该进程有子进程处于僵尸状态,那么它的所有僵尸子进程的父进程ID将被重置为1(init进程)。继承这些子进程的init进程将清理它们(也就是说init进程将wait它们,从而去除它们的僵尸状态)。
如何避免僵尸进程
- 通过signal(SIGCHLD, SIG_IGN)通知内核对子进程的结束不关心,由内核回收。如果不想让父进程挂起,可以在父进程中加入一条语句:signal(SIGCHLD,SIG_IGN);表示父进程忽略SIGCHLD信号,该信号是子进程退出的时候向父进程发送的。
- 父进程调用wait/waitpid等函数等待子进程结束,如果尚无子进程退出wait会导致父进程阻塞。waitpid可以通过传递WNOHANG使父进程不阻塞立即返回。
- 如果父进程很忙可以用signal注册信号处理函数,在信号处理函数调用wait/waitpid等待子进程退出。
- 通过两次调用fork。父进程首先调用fork创建一个子进程然后waitpid等待子进程退出,子进程再fork一个孙进程后退出。这样子进程退出后会被父进程等待回收,而对于孙子进程其父进程已经退出所以孙进程成为一个孤儿进程,孤儿进程由init进程接管,孙进程结束后,init会等待回收。
第一种方法忽略SIGCHLD信号,这常用于并发服务器的性能的一个技巧因为并发服务器常常fork很多子进程,子进程终结之后需要服务器进程去wait清理资源。如果将此信号的处理方式设为忽略,可让内核把僵尸子进程转交给init进程去处理,省去了大量僵尸进程占用系统资源。
-
进程和线程的比较
线程是调度的基本单位,而进程则是资源拥有的基本单位。
线程与进程的比较如下:
- 进程是资源(包括内存、打开的文件等)分配的单位,线程是 CPU 调度的单位;
- 进程拥有一个完整的资源平台,而线程只独享必不可少的资源,如寄存器和栈;
- 线程同样具有就绪、阻塞、执行三种基本状态,同样具有状态之间的转换关系;
- 线程能减少并发执行的时间和空间开销;
对于,线程相比进程能减少开销,体现在:
- 线程的创建时间比进程快,因为进程在创建的过程中,还需要资源管理信息,比如内存管理信息、文件管理信息,而线程在创建的过程中,不会涉及这些资源管理信息,而是共享它们;
- 线程的终止时间比进程快,因为线程释放的资源相比进程少很多;
- 同一个进程内的线程切换比进程切换快,因为线程具有相同的地址空间(虚拟内存共享),这意味着同一个进程的线程都具有同一个页表,那么在切换的时候不需要切换页表。而对于进程之间的切换,切换的时候要把页表给切换掉,而页表的切换过程开销是比较大的;
- 由于同一进程的各线程间共享内存和文件资源,那么在线程之间数据传递的时候,就不需要经过内核了,这就使得线程之间的数据交互效率更高了;
所以,不管是时间效率,还是空间效率线程比进程都要高。
1、线程启动速度快,轻量级
2、线程的系统开销小
3、线程使用有一定难度,需要处理数据一致性问题
4、同一线程共享的有堆、全局变量、静态变量、指针,引用、文件等,而独自占有栈
- 进程是资源分配的最小单位,而线程是 CPU 调度的最小单位;
- 创建进程或撤销进程,系统都要为之分配或回收资源,操作系统开销远大于创建或撤销线程时的开销;
- 不同进程地址空间相互独立,同一进程内的线程共享同一地址空间。一个进程的线程在另一个进程内是不可见的;
- 进程间不会相互影响,而一个线程挂掉将可能导致整个进程挂掉;
5.2 内存管理
-
物理地址、逻辑地址、虚拟内存的概念
- 物理地址:它是地址转换的最终地址,进程在运行时执行指令和访问数据最后都要通过物理地址从主存中存取,是内存单元真正的地址。
- 逻辑地址:是指计算机用户看到的地址。例如:当创建一个长度为 100 的整型数组时,操作系统返回一个逻辑上的连续空间:指针指向数组第一个元素的内存地址。由于整型元素的大小为 4 个字节,故第二个元素的地址时起始地址加 4,以此类推。事实上,逻辑地址并不一定是元素存储的真实地址,即数组元素的物理地址(在内存条中所处的位置),并非是连续的,只是操作系统通过地址映射,将逻辑地址映射成连续的,这样更符合人们的直观思维。
- 虚拟内存:是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
-
虚拟内存有什么好处
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
-
内存管理
内存管理的概念就是操作系统对内存的划分和动态分配。
内存管理功能:
内存空间的分配与回收:由操作系统完成主存储器空间的分配和管理,是程序员摆脱存储分配的麻烦,提高编程效率。
地址转换:将逻辑地址转换成相应的物理地址。
内存空间的扩充:利用虚拟存储技术或自动覆盖技术,从逻辑上扩充主存。
存储保护:保证各道作业在各自的存储空间内运行,互不干扰。
创建进程首先要将程序和数据装入内存。将用户源程序变为可在内存中执行的程序,通常需要以下几个步骤:编译:由编译程序将用户源代码编译成若干目标模块(把高级语言翻译成机器语言)
链接:由链接程序将编译后形成的一组目标模块及所需的库函数连接在一起,形成一个完整的装入模块(由目标模块生成装入模块,链接后形成完整的逻辑地址)
装入:由装入程序将装入模块装入内存运行,装入后形成物理地址
程序的链接有以下三种方式:静态链接:在程序运行之前,先将各目标模块及它们所需的库函数连接成一个完整的可执行文件(装入模块),之后不再拆开。
装入时动态链接:将各目标模块装入内存时,边装入边链接的链接方式。
运行时动态链接:在程序执行中需要该目标模块时,才对它进行链接。其优点是便于修改和更新,便于实现对目标模块的共享。
内存的装入模块在装入内存时,有以下三种方式:重定位:根据内存的当前情况,将装入模块装入内存的适当位置,装入时对目标程序中的指令和数据的修改过程称为重定位。
静态重定位:地址的变换通常是在装入时一次完成的。一个作业装入内存时,必须给它分配要求的全部内存空间,若没有足够的内存,则不能装入该作业。此外,作业一旦装入内存,整个运行期间就不能在内存中移动,也不能再申请内存空间。
动态重定位:需要重定位寄存器的支持。可以将程序分配到不连续的存储区中;在程序运行之前可以只装入它的部分代码即可投入运行,然后在程序运行期间,根据需要动态申请分配内存。
内存分配前,需要保护操作系统不受用户进程的影响,同时保护用户进程不受其他用户进程的影响。内存保护可采取如下两种方法:在CPU中设置一对上、下限寄存器,存放用户作业在主存中的上限和下限地址,每当CPU要访问一个地址时,分别和两个寄存器的值相比,判断有无越界。
采用重定位寄存器(或基址寄存器)和界地址寄存器(又称限长存储器)来实现这种保护。重定位寄存器包含最小的物理地址值,界地址寄存器含逻辑地址的最大值。每个逻辑地址值必须小于界地址寄存器;内存管理机构动态得将逻辑地址与界地址寄存器进行比较,若未发生地址越界,则加上重定位寄存器的值后映射成物理地址,再送交内存单元。 -
常见的内存分配方式
(1) 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
(2) 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3) 从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
常见内存分配内存错误
(1)内存分配未成功,却使用了它。
(2)内存分配虽然成功,但是尚未初始化就引用它。
(3)内存分配成功并且已经初始化,但操作越过了内存的边界。
(4)忘记了释放内存,造成内存泄露。
(5)释放了内存却继续使用它。常见于以下有三种情况:
- 程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
- 函数的return语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用”,因为该内存在函数体结束时被自动销毁。
- 使用free或delete释放了内存后,没有将指针设置为NULL。导致产生“野指针”。
-
malloc如何分配内存
从操作系统层面上看,malloc是通过两个系统调用来实现的: brk和mmap
- brk是将进程数据段(.data)的最高地址指针向高处移动,这一步可以扩大进程在运行时的堆大小
- mmap是在进程的虚拟地址空间中寻找一块空闲的虚拟内存,这一步可以获得一块可以操作的堆内存。
通常,分配的内存小于128k时,使用brk调用来获得虚拟内存,大于128k时就使用mmap来获得虚拟内存。
进程先通过这两个系统调用获取或者扩大进程的虚拟内存,获得相应的虚拟地址,在访问这些虚拟地址的时候,通过缺页中断,让内核分配相应的物理内存,这样内存分配才算完成。
-
如何避免预读失效和缓存污染
预读失效
这些被提前加载进来的页,并没有被访问,相当于这个预读工作是白做了,这个就是预读失效。
传统的 LRU 算法法无法避免下面这两个问题:
- 预读失效导致缓存命中率下降;
- 缓存污染导致缓存命中率下降;
为了避免「预读失效」造成的影响,Linux 和 MySQL 对传统的 LRU 链表做了改进:
- Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active list)和非活跃 LRU 链表(inactive list)。
- MySQL Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
缓存污染
如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
为了避免「缓存污染」造成的影响,Linux 操作系统和 MySQL Innodb 存储引擎分别提高了升级为热点数据的门槛:
-
Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
-
MySQL Innodb:在内存页被访问
第二次
的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行
停留在 old 区域的时间判断:
- 如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;
- 如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域;
通过提高了进入 active list (或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
-
物理内存管理
操作系统物理内存管理主要包括程序装入、交换技术、连续分配管理方式和非连续分配管理方式(分页、分段、段分页)。
连续分配管理方式
连续内存分配
内存碎片
当给程序分配空间时,可能会出现一些无法被利用的空闲碎片空间。
1.外部碎片:分配单元之间无法被利用的内存碎片
2.内部碎片:分配给任务内存大小大于任务所需内存大小时,多出来的内存碎片。分区的动态分配
连续内存分配情况:将应用程序从硬盘加载到内存中,给内存分配一块内存。应用程序运行访问数据,数据的连续内存空间。内存分配算法:
具体问题具体分析适配算法。-
首次适配:
定义:使用第一块内存大小大于需求大小的可用空闲块
实现方法:需要有一个按地址排序的空闲块列表。寻找第一个满足内存需求的空闲块。对于回收,要考虑空闲块与相邻空闲块合并问题。
优点:简单,易于产生更大的空闲块,想着地址空间结尾分配
缺点:产生外部碎片,具有不确定性 -
最优适配:
定义:寻找整个空闲块中,最满足分配请求的空闲块,内存差值最小。
实现方法:需要有一个按尺寸排序的空闲块列表,寻找最满足分配的内存块。对于回收,要考虑空闲块与相邻空闲块合并问题。
优点:避免分割大空闲块,最小化外部碎片的产生,简单
缺点:外部碎片很细,有很多微小碎片,不利于后续分配管理。 -
最差适配:
定义:找到差距最大的内存空闲块。
实现:需要有一个按尺寸排序的空闲块列表,寻找差距最大的内存块。对于回收,要考虑空闲块与相邻空闲块合并问题。
优点:避免产生微小外部碎片,分配效率高,适用于分配中大快
缺点:对于大块请求带来一定影响
减少内存碎片方法
-
紧致:压缩式碎片整理
调整运行程序的位置。
1.重定位的时机。不能在程序运行时进行,可以在程序等待时拷贝。
2.内存拷贝开销很大。 -
swaping:交换式碎片整理
把硬盘作为一个备份。把等待的程序包括数据(主存)挪到硬盘上。当硬盘上程序需要执行时再拷贝到主存上。
1.交换那个程序,减小开销
2.交换的时机
非连续内存分配
连续内存分配和非连续内存分配
连续内存分配缺点:1.分配给一个程序的物理内存是连续的,内存利用率较低,由外碎片内碎片的问题。
非连续内存分配优点:1.程序物理地址是非连续的 2.更好的内存利用和管理 3.允许共享代码与数据 4.支持动态加载和动态链接
非连续内存分配缺点:建立虚拟地址到物理地址的映射,软件开销太大,可以用硬件支持
-》硬件两种管理方案:分段和分页
分段
分段地址空间
对于一段程序内存可以分为:程序(主程序+子程序+共享库)+变量(栈、堆、共享数据段)
分段:更好的分离与共享,将逻辑地址空间分散到多个物理地址空间
逻辑地址是连续的,将具有不同功能的映射到物理空间中,这些段大小不一,位置不一硬件实现分段寻址机制
一维逻辑地址有不同段组成,首先将逻辑地址分为两段:段寻址(段号)+段偏移寻址(addr)
通过段号在段表找到逻辑内存的段起始地址,看段起始地址是否满足段大小限制,不满足返回内存异常,满足将逻辑地址加偏移量是物理地址。段表:
1.存储逻辑地址段段号到物理地址段号之间的映射关系
2.存储段大小,起始地址
段表的建立:操作系统在寻址前建立。分页
分页地址空间
需要页号和页地址偏移。相比分段,分页页帧大小固定不变。
可以划分物理内存至固定大小的帧,将逻辑地址的页也划分至相同内存大小。大小是2的幂。
建立方案
页帧(Frame):物理内存被分割为大小相等的帧
一个内存物理地址是一个二元组(f,o)
物理地址 = 2^S*f+o
f是帧号(F位,2F个帧),o是帧内偏移(S位,每帧2S字节),页(Page):逻辑地址空间分割为大小相等的页
页内偏移大小 = 帧内偏移大小(页帧大小和页大小一致)
页号大小和帧号大小可能不一致一个逻辑地址是一个二元组(p,o)
逻辑地址 = 2^S*p+o
p:页号(P位,2P个页),o:页内偏移(S位,每页2S个字节)页寻址机制
CPU寻址(逻辑地址),逻辑地址包含两部分(p,o),首先把p(页号)作为索引,再加上页表基址查页表(pagetable)中对应帧号(物理地址中f),知道帧号加上页内偏移就是物理地址(f,o)。页表:以页号为索引的对应的帧号(物理地址),为此需要知道页表的基址位置(页号从哪个地址开始查)。
页表的建立:操作系统初始化时,enable分页机制前就需要建立好分页与分段:
分页:相比分段,分页页内存固定,导致页内偏移大小范围是固定的。不需要想分段一样考虑分页大小不一致的问题。
逻辑地址和物理地址空间
1.总逻辑页大小和总物理帧大小不一致,一般逻辑地址空间大于物理地址空间。
2.逻辑地址空间连续,物理地址空间不连续。减少内外碎片。
页表
页表结构
页表是个数组,索引是页号,对应的数组项内容里有帧号。分页机制性能问题
1.时间开销:访问一个内存单元需要两次内存访问页表不能放在CPU里,只能放在内存里,CPU先做内存寻址找页表基址,再进行页表访问,进行两次内存访问,访问速度很慢
2空间代价:页表占用空间
1.64位计算机,每页1KB,页表大小?2^54个数的页表,很大
2.多个程序有多个页表解决方法
时间上:缓存 ——快表,TLB,Translation Look-aside Buffer
TLB:位于CPU中的一块缓存区域,存放常用的页号-帧号对,采用关联内存的方式实现,具有快速访问功能。
-CPU寻址时会先通过页号在TLB查找,看是否存在页号的Key,对应得到帧号,进而得到物理地址(减少对物理地址的访问)。TLB未命中,把该项更新到TLB中(x86CPU这个过程是硬件完成,对于mps是操作系统完成)。
编写程序时,把访问的地址写在一个页号里。
空间上:间接访问(多级页表机制),以时间换空间
二级页表:对于逻辑地址(p1,p2,o)
CPU寻址时先通过p1查找一级页表,一级页表中存放的是二级页表的p2的起始地址,再在二级页表对应起始地址查找偏移p2,对应存放的就是帧号。提高时间开销,但一级页表中不存在页表项就不需要占用二级页表项的内存,节省空间。
多级页表页号分为K个部分,建立页表“树”
-
-
快表
快表,又称联想寄存器(TLB) ,是一种访问速度比内存快很多的高速缓冲存储器,用来存放当前访问的若干页表项,以加速地址变换的过程。与此对应,内存中的页表常称为慢表。
地址变换过程 访问一个逻辑地址的访存次数 基本地址变换机构 ①算页号、页内偏移量 ②检查页号合法性 ③查页表,找到页面存放的内存块号 ④根据内存块号与页内偏移量得到物理地址 ⑤访问目标内存单元 两次访存 具有快表的地址变换机构 ①算页号、页内偏移量 ②检查页号合法性 ③查快表。若命中,即可知道页面存放的内存块号,可直接进行⑤;若未命中则进行④ ④查页表,找到页面存放的内存块号,并且将页表项复制到快表中 ⑤根据内存块号与页内偏移量得到物理地址 ⑥访问目标内存单元 快表命中,只需一次访存 快表未命中,需要两次访存 -
内存交换技术
交换(对换)技术的设计思想:内存空间紧张时,系统将内存中某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存(进程在内存与磁盘间动态调度)
换入:把准备好竞争CPU运行的程序从辅存移到内存。 换出:把处于等待状态(或CPU调度原则下被剥夺运行权力)的程序从内存移到辅存,把内存空间腾出来。
**交换时机:**内存交换通常在许多进程运行且内存吃紧时进行,而系统负荷降低就暂停。例如:在发现许多进程运行时经常发生缺页,就说明内存紧张,此时可以换出一些进程;如果缺页率明显下降,就可以暂停换出。
关键点
- 交换需要备份存储,通常是快速磁盘,它必须足够大,并且提供对这些内存映像的直接访问。
- 为了有效使用CPU,需要每个进程的执行时间比交换时间长,而影响交换时间的主要是转移时间,转移时间与所交换的空间内存成正比。
- 如果换出进程,比如确保该进程的内存空间成正比。
- 交换空间通常作为磁盘的一整块,且独立于文件系统,因此使用就可能很快。
- 交换通常在有许多进程运行且内存空间吃紧时开始启动,而系统负荷降低就暂停。
- 普通交换使用不多,但交换的策略的某些变种在许多系统中(如UNIX系统)仍然发挥作用。
-
分页与分段的区别
- 段是信息的逻辑单位,它是根据用户的需要划分的,因此段对用户是可见的 ;页是信息的物理单位,是为了管理主存的方便而划分的,对用户是透明的;
- 段的大小不固定,有它所完成的功能决定;页大大小固定,由系统决定;
- 段向用户提供二维地址空间;页向用户提供的是一维地址空间;
- 段是信息的逻辑单位,便于存储保护和信息的共享,页的保护和共享受到限制。
5.3 进程调度算法
-
进程调度算法详细介绍
选择一个进程运行这一功能是在操作系统中完成的,通常称为调度程序(scheduler)。
调度时机
在进程的生命周期中,当进程从一个运行状态到另外一状态变化的时候,其实会触发一次调度。
比如,以下状态的变化都会触发操作系统的调度:
- 从就绪态 -> 运行态:当进程被创建时,会进入到就绪队列,操作系统会从就绪队列选择一个进程运行;
- 从运行态 -> 阻塞态:当进程发生 I/O 事件而阻塞时,操作系统必须选择另外一个进程运行;
- 从运行态 -> 结束态:当进程退出结束后,操作系统得从就绪队列选择另外一个进程运行;
因为,这些状态变化的时候,操作系统需要考虑是否要让新的进程给 CPU 运行,或者是否让当前进程从 CPU 上退出来而换另一个进程运行。
另外,如果硬件时钟提供某个频率的周期性中断,那么可以根据如何处理时钟中断 ,把调度算法分为两类:
- 非抢占式调度算法挑选一个进程,然后让该进程运行直到被阻塞,或者直到该进程退出,才会调用另外一个进程,也就是说不会理时钟中断这个事情。
- 抢占式调度算法挑选一个进程,然后让该进程只运行某段时间,如果在该时段结束时,该进程仍然在运行时,则会把它挂起,接着调度程序从就绪队列挑选另外一个进程。这种抢占式调度处理,需要在时间间隔的末端发生时钟中断,以便把 CPU 控制返回给调度程序进行调度,也就是常说的时间片机制。
调度原则
- CPU 利用率:调度程序应确保 CPU 是始终匆忙的状态,这可提高 CPU 的利用率;
- 系统吞吐量:吞吐量表示的是单位时间内 CPU 完成进程的数量,长作业的进程会占用较长的 CPU 资源,因此会降低吞吐量,相反,短作业的进程会提升系统吞吐量;
- 周转时间:周转时间是进程运行+阻塞时间+等待时间的总和,一个进程的周转时间越小越好;
- 等待时间:这个等待时间不是阻塞状态的时间,而是进程处于就绪队列的时间,等待的时间越长,用户越不满意;
- 响应时间:用户提交请求到系统第一次产生响应所花费的时间,在交互式系统中,响应时间是衡量调度算法好坏的主要标准。
调度算法
调度算法是指:根据系统的资源分配策略所规定的资源分配算法。常用的调度算法有:先来先服务调度算法、时间片轮转调度法、短作业优先调度算法、最短剩余时间优先、高响应比优先调度算法、优先级调度算法等等。
- 先来先服务调度算法
先来先服务调度算法是一种最简单的调度算法,也称为先进先出或严格排队方案。当每个进程就绪后,它加入就绪队列。当前正运行的进程停止执行,选择在就绪队列中存在时间最长的进程运行。该算法既可以用于作业调度,也可以用于进程调度。先来先服务比较适合于常作业(进程),而不利于段作业(进程)。
- 时间片轮转调度算法
时间片轮转调度算法主要适用于分时系统。在这种算法中,系统将所有就绪进程按到达时间的先后次序排成一个队列,进程调度程序总是选择就绪队列中第一个进程执行,即先来先服务的原则,但仅能运行一个时间片。
- 短作业优先调度算法
短作业优先调度算法是指对短作业优先调度的算法,从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。 短作业优先调度算法是一个非抢占策略,他的原则是下一次选择预计处理时间最短的进程,因此短进程将会越过长作业,跳至队列头。
- 最短剩余时间优先调度算法
最短剩余时间是针对最短进程优先增加了抢占机制的版本。在这种情况下,进程调度总是选择预期剩余时间最短的进程。当一个进程加入到就绪队列时,他可能比当前运行的进程具有更短的剩余时间,因此只要新进程就绪,调度程序就能可能抢占当前正在运行的进程。像最短进程优先一样,调度程序正在执行选择函数是必须有关于处理时间的估计,并且存在长进程饥饿的危险。
- 高响应比优先调度算法
高响应比优先调度算法主要用于作业调度,该算法是对 先来先服务调度算法和短作业优先调度算法的一种综合平衡,同时考虑每个作业的等待时间和估计的运行时间。在每次进行作业调度时,先计算后备作业队列中每个作业的响应比,从中选出响应比最高的作业投入运行。
- 优先级调度算法
优先级调度算法每次从后备作业队列中选择优先级最髙的一个或几个作业,将它们调入内存,分配必要的资源,创建进程并放入就绪队列。在进程调度中,优先级调度算法每次从就绪队列中选择优先级最高的进程,将处理机分配给它,使之投入运行。
5.4 磁盘调度算法
-
磁盘调度算法详细介绍
常见的磁盘调度算法有:
- 先来先服务算法
- 最短寻道时间优先算法
- 扫描算法
- 循环扫描算法
- LOOK 与 C-LOOK 算法
先来先服务
先来先服务(First-Come,First-Served,FCFS),顾名思义,先到来的请求,先被服务。
最短寻道时间优先
最短寻道时间优先(Shortest Seek First,SSF)算法的工作方式是,优先选择从当前磁头位置所需寻道时间最短的请求
扫描算法
最短寻道时间优先算法会产生饥饿的原因在于:磁头有可能再一个小区域内来回得移动。
为了防止这个问题,可以规定:磁头在一个方向上移动,访问所有未完成的请求,直到磁头到达该方向上的最后的磁道,才调换方向,这就是扫描(*Scan*)算法。
这种算法也叫做电梯算法,比如电梯保持按一个方向移动,直到在那个方向上没有请求为止,然后改变方向。
循环扫描算法
扫描算法使得每个磁道响应的频率存在差异,那么要优化这个问题的话,可以总是按相同的方向进行扫描,使得每个磁道的响应频率基本一致。
循环扫描(Circular Scan, CSCAN )规定:只有磁头朝某个特定方向移动时,才处理磁道访问请求,而返回时直接快速移动至最靠边缘的磁道,也就是复位磁头,这个过程是很快的,并且返回中途不处理任何请求,该算法的特点,就是磁道只响应一个方向上的请求。
LOOK 与 C-LOOK算法
扫描算法和循环扫描算法,都是磁头移动到磁盘「最始端或最末端」才开始调换方向。
那这其实是可以优化的,优化的思路就是磁头在移动到「最远的请求」位置,然后立即反向移动。
针对 SCAN 算法的优化叫 LOOK 算法,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中会响应请求。
针对C-SCAN 算法的优化叫 C-LOOK,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中不会响应请求。
5.5 页面置换算法
-
页面置换算法详细介绍
请求调页,也称按需调页,即对不在内存中的“页”,当进程执行时要用时才调入,否则有可能到程序结束时也不会调入。而内存中给页面留的位置是有限的,在内存中以帧为单位放置页面。为了防止请求调页的过程出现过多的内存页面错误(即需要的页面当前不在内存中,需要从硬盘中读数据,也即需要做页面的替换)而使得程序执行效率下降,我们需要设计一些页面置换算法,页面按照这些算法进行相互替换时,可以尽量达到较低的错误率。常用的页面置换算法如下:
- 先进先出置换算法(FIFO)
先进先出,即淘汰最早调入的页面。
- 最佳置换算法(OPT)
选未来最远将使用的页淘汰,是一种最优的方案,可以证明缺页数最小。
- 最近最久未使用(LRU)算法
即选择最近最久未使用的页面予以淘汰
- 时钟(Clock)置换算法
时钟置换算法也叫最近未用算法 NRU(Not RecentlyUsed)。该算法为每个页面设置一位访问位,将内存中的所有页面都通过链接指针链成一个循环队列。
5.6 网络系统
-
什么是零拷贝
为了提高文件传输的性能,于是就出现了零拷贝技术,它通过一次系统调用(
sendfile方法)合并了磁盘读取与网络发送两个操作,降低了上下文切换次数。另外,拷贝数据都是发生在内核中的,天然就降低了数据拷贝的次数。Kafka 和 Nginx 都有实现零拷贝技术,这将大大提高文件传输的性能。
零拷贝技术是基于 PageCache 的,PageCache 会缓存最近访问的数据,提升了访问缓存数据的性能,同时,为了解决机械硬盘寻址慢的问题,它还协助 I/O 调度算法实现了 IO 合并与预读,这也是顺序读比随机读性能好的原因。这些优势,进一步提升了零拷贝的性能。
-
I/O多路复用
既然为每个请求分配一个进程/线程的方式不合适,那有没有可能只使用一个进程来维护多个 Socket 呢?答案是有的,那就是 I/O 多路复用技术。
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
我们熟悉的 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。
-
select/poll/epoll
select 和 poll 并没有本质区别,它们内部都是使用「线性结构」来存储进程关注的 Socket 集合。
在使用的时候,首先需要把关注的 Socket 集合通过 select/poll 系统调用从用户态拷贝到内核态,然后由内核检测事件,当有网络事件产生时,内核需要遍历进程关注 Socket 集合,找到对应的 Socket,并设置其状态为可读/可写,然后把整个 Socket 集合从内核态拷贝到用户态,用户态还要继续遍历整个 Socket 集合找到可读/可写的 Socket,然后对其处理。
很明显发现,select 和 poll 的缺陷在于,当客户端越多,也就是 Socket 集合越大,Socket 集合的遍历和拷贝会带来很大的开销,因此也很难应对 C10K。
epoll 是解决 C10K 问题的利器,通过两个方面解决了 select/poll 的问题。
- epoll 在内核里使用「红黑树」来关注进程所有待检测的 Socket,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn),通过对这棵黑红树的管理,不需要像 select/poll 在每次操作时都传入整个 Socket 集合,减少了内核和用户空间大量的数据拷贝和内存分配。
- epoll 使用事件驱动的机制,内核里维护了一个「链表」来记录就绪事件,只将有事件发生的 Socket 集合传递给应用程序,不需要像 select/poll 那样轮询扫描整个集合(包含有和无事件的 Socket ),大大提高了检测的效率。
而且,epoll 支持边缘触发和水平触发的方式,而 select/poll 只支持水平触发,一般而言,边缘触发的方式会比水平触发的效率高。
-
高性能网络模式:Reactor和Proactor
常见的 Reactor 实现方案有三种。
第一种方案单 Reactor 单进程 / 线程,不用考虑进程间通信以及数据同步的问题,因此实现起来比较简单,这种方案的缺陷在于无法充分利用多核 CPU,而且处理业务逻辑的时间不能太长,否则会延迟响应,所以不适用于计算机密集型的场景,适用于业务处理快速的场景,比如 Redis(6.0之前 ) 采用的是单 Reactor 单进程的方案。
第二种方案单 Reactor 多线程,通过多线程的方式解决了方案一的缺陷,但它离高并发还差一点距离,差在只有一个 Reactor 对象来承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
第三种方案多 Reactor 多进程 / 线程,通过多个 Reactor 来解决了方案二的缺陷,主 Reactor 只负责监听事件,响应事件的工作交给了从 Reactor,Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案,Nginx 则采用了类似于 「多 Reactor 多进程」的方案。
Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。
因此,真正的大杀器还是 Proactor,它是采用异步 I/O 实现的异步网络模型,感知的是已完成的读写事件,而不需要像 Reactor 感知到事件后,还需要调用 read 来从内核中获取数据。
不过,无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
-
一致性哈希介绍
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
但是一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
引入虚拟节点后,可以会提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
5.7 锁
-
什么是死锁和产生死锁原因
死锁,是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。 如下图所示:如果此时有一个线程 A,已经持有了锁 A,但是试图获取锁 B,线程 B 持有锁 B,而试图获取锁 A,这种情况下就会产生死锁。
产生死锁原因
由于系统中存在一些不可剥夺资源,而当两个或两个以上进程占有自身资源,并请求对方资源时,会导致每个进程都无法向前推进,这就是死锁。
- 竞争资源
例如:系统中只有一台打印机,可供进程 A 使用,假定 A 已占用了打印机,若 B 继续要求打印机打印将被阻塞。
系统中的资源可以分为两类:
- 可剥夺资源:是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺,CPU 和主存均属于可剥夺性资源;
- 不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
- 进程推进顺序不当
例如:进程 A 和 进程 B 互相等待对方的数据。
死锁产生的必要条件?
- 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
-
如何避免死锁
预防死锁、避免死锁、检测死锁、解除死锁
预防死锁
- 破坏请求条件:一次性分配所有资源,这样就不会再有请求了;
- 破坏请保持条件:只要有一个资源得不到分配,也不给这个进程分配其他的资源:
- 破坏不可剥夺条件:当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源;
- 破坏环路等待条件:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反。
解除死锁
- 资源剥夺:挂起某些死锁进程,并抢占它的资源,将这些资源分配给其他死锁进程(但应该防止被挂起的进程长时间得不到资源);
- 撤销进程:强制撤销部分、甚至全部死锁进程并剥夺这些进程的资源(撤销的原则可以按进程优先级和撤销进程代价的高低进行);
- 进程回退:让一个或多个进程回退到足以避免死锁的地步。进程回退时自愿释放资源而不是被剥夺。要求系统保持进程的历史信息,设置还原点。
-
什么是悲观锁、乐观锁
悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
可见,乐观锁的心态是,不管三七二十一,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫无锁编程。
互斥锁、自旋锁、读写锁,都是属于悲观锁。
-
哲学家进餐问题
生产者-消费者问题描述:
- 生产者在生成数据后,放在一个缓冲区中;
- 消费者从缓冲区取出数据处理;
- 任何时刻,只能有一个生产者或消费者可以访问缓冲区;
我们对问题分析可以得出:
- 任何时刻只能有一个线程操作缓冲区,说明操作缓冲区是临界代码,需要互斥;
- 缓冲区空时,消费者必须等待生产者生成数据;缓冲区满时,生产者必须等待消费者取出数据。说明生产者和消费者需要同步。
那么我们需要三个信号量,分别是:
- 互斥信号量
mutex:用于互斥访问缓冲区,初始化值为 1; - 资源信号量
fullBuffers:用于消费者询问缓冲区是否有数据,有数据则读取数据,初始化值为 0(表明缓冲区一开始为空); - 资源信号量
emptyBuffers:用于生产者询问缓冲区是否有空位,有空位则生成数据,初始化值为 n (缓冲区大小);
如果消费者线程一开始执行
P(fullBuffers),由于信号量fullBuffers初始值为 0,则此时fullBuffers的值从 0 变为 -1,说明缓冲区里没有数据,消费者只能等待。接着,轮到生产者执行
P(emptyBuffers),表示减少 1 个空槽,如果当前没有其他生产者线程在临界区执行代码,那么该生产者线程就可以把数据放到缓冲区,放完后,执行V(fullBuffers),信号量fullBuffers从 -1 变成 0,表明有「消费者」线程正在阻塞等待数据,于是阻塞等待的消费者线程会被唤醒。消费者线程被唤醒后,如果此时没有其他消费者线程在读数据,那么就可以直接进入临界区,从缓冲区读取数据。最后,离开临界区后,把空槽的个数 + 1。
-
生产者、消费者问题
哲学家就餐的问题描述:
5个老大哥哲学家,闲着没事做,围绕着一张圆桌吃面;- 巧就巧在,这个桌子只有
5支叉子,每两个哲学家之间放一支叉子; - 哲学家围在一起先思考,思考中途饿了就会想进餐;
- 这些哲学家要两支叉子才愿意吃面,也就是需要拿到左右两边的叉子才进餐;
- 吃完后,会把两支叉子放回原处,继续思考;
一、让偶数编号的哲学家「先拿左边的叉子后拿右边的叉子」,奇数编号的哲学家「先拿右边的叉子后拿左边的叉子」。
在 P 操作时,根据哲学家的编号不同,拿起左右两边叉子的顺序不同。另外,V 操作是不需要分支的,因为 V 操作是不会阻塞的。
二、用一个数组 state 来记录每一位哲学家的三个状态,分别是在进餐状态、思考状态、饥饿状态(正在试图拿叉子)。
那么,一个哲学家只有在两个邻居都没有进餐时,才可以进入进餐状态。
上面的程序使用了一个信号量数组,每个信号量对应一位哲学家,这样在所需的叉子被占用时,想进餐的哲学家就被阻塞。
-
读者写者问题
读者只会读取数据,不会修改数据,而写者即可以读也可以修改数据。
读者-写者的问题描述:
- 「读-读」允许:同一时刻,允许多个读者同时读
- 「读-写」互斥:没有写者时读者才能读,没有读者时写者才能写
- 「写-写」互斥:没有其他写者时,写者才能写
使用信号量的方式来尝试解决:
- 信号量
wMutex:控制写操作的互斥信号量,初始值为 1 ; - 读者计数
rCount:正在进行读操作的读者个数,初始化为 0; - 信号量
rCountMutex:控制对 rCount 读者计数器的互斥修改,初始值为 1;
这种实现,是读者优先的策略,因为只要有读者正在读的状态,后来的读者都可以直接进入,如果读者持续不断进入,则写者会处于饥饿状态。
那既然有读者优先策略,自然也有写者优先策略:
- 只要有写者准备要写入,写者应尽快执行写操作,后来的读者就必须阻塞;
- 如果有写者持续不断写入,则读者就处于饥饿;
在方案一的基础上新增如下变量:
- 信号量
rMutex:控制读者进入的互斥信号量,初始值为 1; - 信号量
wDataMutex:控制写者写操作的互斥信号量,初始值为 1; - 写者计数
wCount:记录写者数量,初始值为 0; - 信号量
wCountMutex:控制 wCount 互斥修改,初始值为 1;
注意,这里
rMutex的作用,开始有多个读者读数据,它们全部进入读者队列,此时来了一个写者,执行了P(rMutex)之后,后续的读者由于阻塞在rMutex上,都不能再进入读者队列,而写者到来,则可以全部进入写者队列,因此保证了写者优先。同时,第一个写者执行了
P(rMutex)之后,也不能马上开始写,必须等到所有进入读者队列的读者都执行完读操作,通过V(wDataMutex)唤醒写者的写操作。既然读者优先策略和写者优先策略都会造成饥饿的现象,那么我们就来实现一下公平策略。
公平策略:
- 优先级相同;
- 写者、读者互斥访问;
- 只能一个写者访问临界区;
- 可以有多个读者同时访问临界资源;
5.8 其他面试题
-
对并发和并行的理解
- 并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生;
- 并行是在不同实体上的多个事件,并发是在同一实体上的多个事件;
-
什么是用户态和内核态
用户态和内核态是操作系统的两种运行状态。
内核态:处于内核态的 CPU 可以访问任意的数据,包括外围设备,比如网卡、硬盘等,处于内核态的 CPU 可以从一个程序切换到另外一个程序,并且占用 CPU 不会发生抢占情况,一般处于特权级 0 的状态我们称之为内核态。用户态:处于用户态的 CPU 只能受限的访问内存,并且不允许访问外围设备,用户态下的 CPU 不允许独占,也就是说 CPU 能够被其他程序获取。
-
两大局部性原理是什么
主要分为时间局部性和空间局部性。
**时间局部性:**如果执行了程序中的某条指令,那么不久后这条指令很有可能再次执行;如果某个数据被访问过,不久之后该数据很可能再次被访问。(因为程序中存在大量的循环)
**空间局部性:**一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的,并且程序的指令也是顺序地在内存中存放的)
-
异常和中断是什么,有什么区别
中断
当我们在敲击键盘的同时就会产生中断,当硬盘读写完数据之后也会产生中断,所以,我们需要知道,中断是由硬件设备产生的,而它们从物理上说就是电信号,之后,它们通过中断控制器发送给CPU,接着CPU判断收到的中断来自于哪个硬件设备(这定义在内核中),最后,由CPU发送给内核,有内核处理中断。
异常
CPU处理程序的时候一旦程序不在内存中,会产生缺页异常;当运行除法程序时,当除数为0时,又会产生除0异常。所以,大家也需要记住的是,异常是由CPU产生的,同时,它会发送给内核,要求内核处理这些异常。
相同点
- 最后都是由CPU发送给内核,由内核去处理
- 处理程序的流程设计上是相似的
不同点
- 产生源不相同,异常是由CPU产生的,而中断是由硬件设备产生的
- 内核需要根据是异常还是中断调用不同的处理程序
- 中断不是时钟同步的,这意味着中断可能随时到来;异常由于是CPU产生的,所以它是时钟同步的
- 当处理中断时,处于中断上下文中;处理异常时,处于进程上下文中
-
原子操作
**处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。**首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。Pentium 6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器是不能自动保证其原子性的,比如跨总线宽度、跨多个缓存行和跨页表的访问。但是,处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
(1)使用总线锁保证原子性 第一个机制是通过总线锁保证原子性。
所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
(2)使用缓存锁保证原子性 第二个机制是通过缓存锁定来保证原子性。
-
服务器高并发解决方案
- 应用数据与静态资源分离 将静态资源(图片,视频,js,css等)单独保存到专门的静态资源服务器中,在客户端访问的时候从静态资源服务器中返回静态资源,从主服务器中返回应用数据。
- 客户端缓存 因为效率最高,消耗资源最小的就是纯静态的html页面,所以可以把网站上的页面尽可能用静态的来实现,在页面过期或者有数据更新之后再将页面重新缓存。或者先生成静态页面,然后用ajax异步请求获取动态数据。
- 集群和分布式 (集群是所有的服务器都有相同的功能,请求哪台都可以,主要起分流作用)
(分布式是将不同的业务放到不同的服务器中,处理一个请求可能需要使用到多台服务器,起到加快请求处理的速度。)
可以使用服务器集群和分布式架构,使得原本属于一个服务器的计算压力分散到多个服务器上。同时加快请求处理的速度。 - 反向代理 在访问服务器的时候,服务器通过别的服务器获取资源或结果返回给客户端。
-
抖动你知道是什么吗?它也叫颠簸现象
刚刚换出的页面马上又要换入内存,刚刚换入的页面马上又要换出外存,这种频繁的页面调度行为称为抖动,或颠簸。产生抖动的主要原因是进程频繁访问的页面数目高于可用的物理块数(分配给进程的物理块不够)
为进程分配的物理块太少,会使进程发生抖动现象。为进程分配的物理块太多,又会降低系统整体的并发度,降低某些资源的利用率 为了研究为应该为每个进程分配多少个物理块,Denning 提出了进程工作集” 的概念
6. 熟悉Redis的基本使用
6.1 基本数据结构
-
什么是Redis
Redis是一个数据库,不过与传统数据库不同的是Redis的数据库是存在内存中,所以读写速度非常快,因此 Redis被广泛应用于缓存方向。
除此之外,Redis也经常用来做分布式锁,Redis提供了多种数据类型来支持不同的业务场景。除此之外,Redis 支持事务持久化、LUA脚本、LRU驱动事件、多种集群方案。
-
Redis有哪几种数据类型
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
Redis 五种数据类型的应用场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AZ9MTye1-1678081583396)(https://cdn.xiaolincoding.com/gh/xiaolincoder/redis/%E5%85%AB%E8%82%A1%E6%96%87/%E4%BA%94%E7%A7%8D%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B.png)]
随着 Redis 版本的更新,后面又支持四种数据类型: BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。 Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
-
详细介绍Redis的五种基本数据类型
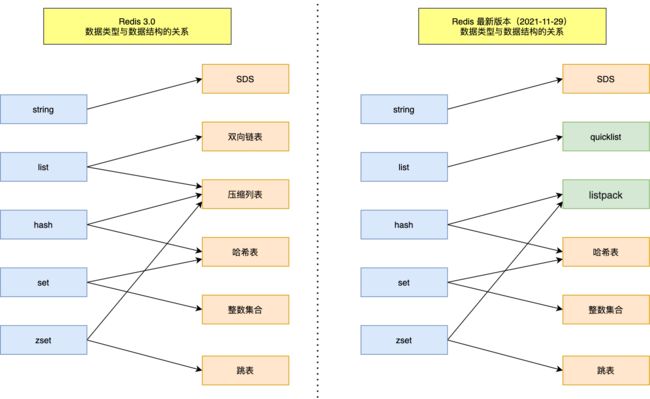
String 类型内部实现
String 类型的底层的数据结构实现主要是 SDS(简单动态字符串)。 SDS 和我们认识的 C 字符串不太一样,之所以没有使用 C 语言的字符串表示,因为 SDS 相比于 C 的原生字符串:
- SDS 不仅可以保存文本数据,还可以保存二进制数据。因为 SDS 使用 len 属性的值而不是空字符来判断字符串是否结束,并且 SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据。所以 SDS 不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据。
- SDS 获取字符串长度的时间复杂度是 O(1)。因为 C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n);而 SDS 结构里用 len 属性记录了字符串长度,所以复杂度为 O(1)。
- Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。
List 类型内部实现
List 类型的底层数据结构是由双向链表或压缩列表实现的:
- 如果列表的元素个数小于 512 个(默认值,可由 list-max-ziplist-entries 配置),列表每个元素的值都小于 64 字节(默认值,可由 list-max-ziplist-value 配置),Redis 会使用压缩列表作为 List 类型的底层数据结构;
- 如果列表的元素不满足上面的条件,Redis 会使用双向链表作为 List 类型的底层数据结构;
但是在 Redis 3.2 版本之后,List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表。
Hash 类型内部实现
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
- 如果哈希类型元素个数小于 512 个(默认值,可由 hash-max-ziplist-entries 配置),所有值小于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构;
- 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
Set 类型内部实现
Set 类型的底层数据结构是由哈希表或整数集合实现的:
- 如果集合中的元素都是整数且元素个数小于 512 (默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构;
- 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
ZSet 类型内部实现
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数小于 128 个,并且每个元素的值小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构;
- 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
-
Redis数据结构详解
- 简单动态字符串(Simple Dynamic String,SDS)
Redis没有直接使用C语言传统的字符串,而是自己构建了一种名为简单动态字符串(Simple dynamic string,SDS)的抽象类型,并将SDS用作Redis的默认字符串表示。
其实SDS等同于C语言中的char * ,但它可以存储任意二进制数据,不能像C语言字符串那样以字符’\0’来标识字符串的结 束,因此它必然有个长度字段。
优点
- 获取字符串长度的复杂度为O(1)。
- 杜绝缓冲区溢出。
- 减少修改字符串长度时所需要的内存重分配次数。
- 二进制安全。
- 兼容部分C字符串函数。
它具有很常规的 set/get 操作,value 可以是String也可以是数字,一般做一些复杂的计数功能的缓存。
- 链表
当有一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的额字符串时,Redis就会使用链表作为列表建的底层实现。
特性
- 链表被广泛用于实现Redis的各种功能,比如列表建、发布与订阅、慢查询、监视器等。
- 每个链表节点由一个listNode结构来表示,每个节点都有一个指向前置节点和后置节点的指针,所以Redis的链表实现是双端链表。
- 每个链表使用一个list结构表示,这个结构带有表头节点指针、表尾节点指针,以及链表长度等信息。
- 因为链表表头的前置节点和表尾节点的后置节点都指向NULL,所以Redis的链表实现是无环链表。
- 通过为链表设置不同的类型特定函数,Redis的链表可以用于保存各种不同类型的值。
- 字典
字典的底层是哈希表,类似 C++中的 map ,也就是键值对。
- 哈希表
哈希算法
当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis使用MurmurHash算法。这种算法的优点在于即使输入的键是规律的,算法仍能给出一个个很好的随机分布性,并且算法的计算速度非常快。
哈希冲突的解决方式
Redis的哈希表使用链地址法来解决键冲突,每个哈希表节点都有一个next指针,多个哈希表节点可以用这个单向链表连接起来,这就解决了键冲突的问题。
特性
-
字典被广泛用于实现Redis的各种功能,其中包括数据库和哈希键。
-
Redis中的字典使用哈希表作为底层结构实现,每个字典带有两个哈希表,一个平时使用,另一个仅在进行rehash时使用。
-
Redis使用MurmurHash2算法来计算键的哈希值。
-
哈希表使用链地址法来解决键冲突。
-
跳跃表
Redis 只有 Zset 对象的底层实现用到跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
zset 结构体里有两个数据结构:一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
- 如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
- 如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
特性
- 跳跃表是有序集合的底层实现之一
- Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳跃表信息(比如表头节点、表尾节点、长度),而zskiplistNode则用于表示跳跃表节点
- 每个跳跃表节点的层高都是1至32之间的随机数
- 在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的。
- 跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序。
- 跳表是一种实现起来很简单,单层多指针的链表,它查找效率很高,堪比优化过的二叉平衡树,且比平衡树的实现。
- 压缩列表
压缩列表(ziplist)是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。
特性
看他的名字就能看出来,是为了节省内存造的列表结构。
- quicklist
其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
- listpack
listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。
listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
- 整数集合
整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集这个数据结构作为底层实现。整数集合本质上是一块连续内存空间。
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割,如果 encoding 属性值为 INTSET_ENC_INT16,则每个元素的间隔就是 16 位。
整数集合升级的好处是节省内存资源。
-
Redis的线程模式
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的,这也是我们常说 Redis 是单线程的原因。
但是,Redis 程序并不是单线程的,Redis 在启动的时候,是会启动后台线程(BIO)的
关闭文件、AOF 刷盘、释放内存
Redis 单线程模式是怎样的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IMjNfraQ-1678081583397)(https://cdn.xiaolincoding.com/gh/xiaolincoder/redis/%E5%85%AB%E8%82%A1%E6%96%87/redis%E5%8D%95%E7%BA%BF%E7%A8%8B%E6%A8%A1%E5%9E%8B.drawio.png)]
图中的蓝色部分是一个事件循环,是由主线程负责的,可以看到网络 I/O 和命令处理都是单线程。 Redis 初始化的时候,会做下面这几件事情:
- 首先,调用 epoll_create() 创建一个 epoll 对象和调用 socket() 创建一个服务端 socket
- 然后,调用 bind() 绑定端口和调用 listen() 监听该 socket;
- 然后,将调用 epoll_ctl() 将 listen socket 加入到 epoll,同时注册「连接事件」处理函数。
初始化完后,主线程就进入到一个事件循环函数,主要会做以下事情:
- 首先,先调用处理发送队列函数,看是发送队列里是否有任务,如果有发送任务,则通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
- 接着,调用 epoll_wait 函数等待事件的到来:
- 如果是连接事件到来,则会调用连接事件处理函数,该函数会做这些事情:调用 accpet 获取已连接的 socket -> 调用 epoll_ctl 将已连接的 socket 加入到 epoll -> 注册「读事件」处理函数;
- 如果是读事件到来,则会调用读事件处理函数,该函数会做这些事情:调用 read 获取客户端发送的数据 -> 解析命令 -> 处理命令 -> 将客户端对象添加到发送队列 -> 将执行结果写到发送缓存区等待发送;
- 如果是写事件到来,则会调用写事件处理函数,该函数会做这些事情:通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会继续注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
-
使用Redis的好处有哪些
1、访问速度快,因为数据存在内存中,类似于Java中的HashMap或者C++中的哈希表(如unordered_map/unordered_set),这两者的优势就是查找和操作的时间复杂度都是O(1)
2、数据类型丰富,支持String,list,set,sorted set,hash这五种数据结构
3、支持事务,Redis中的操作都是原子性,换句话说就是对数据的更改要么全部执行,要么全部不执行,这就是原子性的定义
4、特性丰富:Redis可用于缓存,消息,按key设置过期时间,过期后将会自动删除。
-
Memcached与Redis的区别都有哪些
1、存储方式
- Memecache把数据全部存在内存之中,断电后会挂掉,没有持久化功能,数据不能超过内存大小。
- Redis有部份存在硬盘上,这样能保证数据的持久性。
2、数据支持类型
- Memcache对数据类型支持相对简单,只有String这一种类型
- Redis有复杂的数据类型。Redis不仅仅支持简单的k/v类型的数据,同时还提供 list,set,zset,hash等数据结构的存储。
3、使用底层模型不同
- 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。
- Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4、集群模式:Memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前 是原生支持 cluster 模式的.
5、Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。
6、Value 值大小不同:Redis 最大可以达到 512MB;Memcached 只有 1MB。
-
单线程的Redis为什么这么快
-
Redis的全部操作都是纯内存的操作;
-
Redis采用单线程,有效避免了频繁的上下文切换;
-
采用了非阻塞I/O多路复用机制。
-
-
Hash 冲突怎么办
Redis 通过链式哈希解决冲突:也就是同一个 桶里面的元素使用链表保存。但是当链表过长就会导致查找性能变差可能,所以 Redis 为了追求快,使用了两个全局哈希表。用于 rehash 操作,增加现有的哈希桶数量,减少哈希冲突。
开始默认使用 「hash 表 1 」保存键值对数据,「hash 表 2」 此刻没有分配空间。当数据越来越多触发 rehash 操作,则执行以下操作:
- 给 「hash 表 2 」分配更大的空间;
- 将 「hash 表 1 」的数据重新映射拷贝到 「hash 表 2」 中;
- 释放 「hash 表 1」 的空间。
值得注意的是,将 hash 表 1 的数据重新映射到 hash 表 2 的过程中并不是一次性的,这样会造成 Redis 阻塞,无法提供服务。
而是采用了渐进式 rehash,每次处理客户端请求的时候,先从「 hash 表 1」 中第一个索引开始,将这个位置的 所有数据拷贝到 「hash 表 2」 中,就这样将 rehash 分散到多次请求过程中,避免耗时阻塞。
-
Redis的过期删除策略
我们都知道,Redis是key-value数据库,我们可以设置Redis中缓存的key的过期时间。Redis的过期策略就是指当Redis中缓存的key过期了,Redis如何处理。
过期策略通常有以下三种:
- 定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
- 惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
- 定期清除:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
(expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。)
Redis中同时使用了惰性过期和定期过期两种过期策略。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yPoc3v2v-1678081583397)(https://cdn.xiaolincoding.com/gh/xiaolincoder/redis/%E8%BF%87%E6%9C%9F%E7%AD%96%E7%95%A5/%E8%BF%87%E6%9C%9F%E5%88%A0%E9%99%A4%E7%AD%96%E7%95%A5.jpg)]
-
Redis的内存淘汰策略
Redis 内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。
1、不进行数据淘汰的策略
noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,这时如果有新的数据写入,则会触发 OOM,但是如果没用数据写入的话,只是单纯的查询或者删除操作的话,还是可以正常工作。
2、进行数据淘汰的策略
针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。
在设置了过期时间的数据中进行淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值。
- volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
- volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
Redis 是如何实现 LRU 算法的?
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
Redis 实现的 LRU 算法的优点:
- 不用为所有的数据维护一个大链表,节省了空间占用;
- 不用在每次数据访问时都移动链表项,提升了缓存的性能;
什么是 LFU 算法?
LFU 全称是 Least Frequently Used 翻译为最近最不常用,LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
所以, LFU 算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。这样就解决了偶尔被访问一次之后,数据留存在缓存中很长一段时间的问题,相比于 LRU 算法也更合理一些。
Redis 是如何实现 LFU 算法的?
LFU 算法相比于 LRU 算法的实现,多记录了「数据的访问频次」的信息。
访问频次(访问频率)的 logc 会随时间推移而衰减的。
- 先按照上次访问距离当前的时长,来对 logc 进行衰减;
- 然后,再按照一定概率增加 logc 的值
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MVmju7O5-1678081583398)(https://cdn.xiaolincoding.com/gh/xiaolincoder/redis/%E8%BF%87%E6%9C%9F%E7%AD%96%E7%95%A5/%E5%86%85%E5%AD%98%E6%B7%98%E6%B1%B0%E7%AD%96%E7%95%A5.jpg)]
6.2 数据持久化
-
Redis如何实现持久化
Redis是一个支持持久化的内存数据库,通过持久化机制把内存中的数据同步到硬盘文件来保证数据持久化。当Redis重启后通过把硬盘文件重新加载到内存,就能达到恢复数据的目的。
很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机 器、机器故障之后回复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
Redis 共有三种数据持久化的方式:
- AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里;
- RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
- 混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RBD 的优点;
-
AOF日志实现
AOF(append-only file)持久化
Redis 在执行完一条写操作命令后,就会把该命令以追加的方式写入到一个文件里,然后 Redis 重启时,会读取该文件记录的命令,然后逐一执行命令的方式来进行数据恢复。
Redis 提供了 3 种写回硬盘的策略,控制的就是上面说的第三步的过程。 在 Redis.conf 配置文件中的 appendfsync 配置项可以有以下 3 种参数可填:
- Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
- Everysec,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
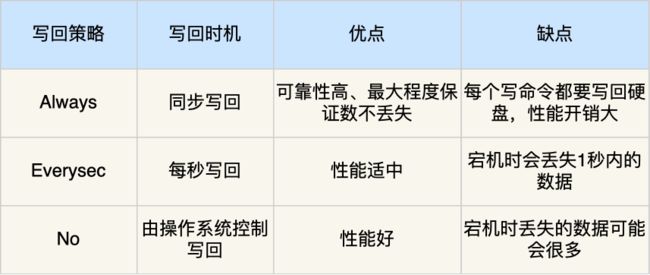
AOF 日志过大,会触发AOF 重写机制
AOF 重写机制是在重写时,读取当前数据库中的所有键值对,然后将每一个键值对用一条命令记录到「新的 AOF 文件」,等到全部记录完后,就将新的 AOF 文件替换掉现有的 AOF 文件。
Redis 提供了 AOF 重写机制,它会直接扫描数据中所有的键值对数据,然后为每一个键值对生成一条写操作命令,接着将该命令写入到新的 AOF 文件,重写完成后,就替换掉现有的 AOF 日志。重写的过程是由后台子进程完成的,这样可以使得主进程可以继续正常处理命令。
-
RDB快照实现
快照(snapshotting)持久化(RDB持久化)
将某一时刻的内存数据,以二进制的方式写入磁盘;RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据。
RDB 在执行快照的时候,数据能修改吗?
可以的,执行 bgsave 过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的,关键的技术就在于写时复制技术(Copy-On-Write, COW)。
执行 bgsave 命令的时候,会通过 fork() 创建子进程,此时子进程和父进程是共享同一片内存数据的,因为创建子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个,此时如果主线程执行读操作,则主线程和 bgsave 子进程互相不影响。
-
混合持久化
混合持久化方式 Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
使用了混合持久化,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
-
大Key对Redis持久化有什么影响
当 AOF 写回策略配置了 Always 策略,如果写入是一个大 Key,主线程在执行 fsync() 函数的时候,阻塞的时间会比较久,因为当写入的数据量很大的时候,数据同步到硬盘这个过程是很耗时的。
AOF 重写机制和 RDB 快照(bgsave 命令)的过程,都会分别通过
fork()函数创建一个子进程来处理任务。会有两个阶段会导致阻塞父进程(主线程):- 创建子进程的途中,由于要复制父进程的页表等数据结构,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长;
- 创建完子进程后,如果父进程修改了共享数据中的大 Key,就会发生写时复制,这期间会拷贝物理内存,由于大 Key 占用的物理内存会很大,那么在复制物理内存这一过程,就会比较耗时,所以有可能会阻塞父进程。
大 key 除了会影响持久化之外,还会有以下的影响。
- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
如何避免大 Key 呢?
最好在设计阶段,就把大 key 拆分成一个一个小 key。或者,定时检查 Redis 是否存在大 key ,如果该大 key 是可以删除的,不要使用 DEL 命令删除,因为该命令删除过程会阻塞主线程,而是用 unlink 命令(Redis 4.0+)删除大 key,因为该命令的删除过程是异步的,不会阻塞主线程。
6.3 高可用
-
主从复制模式介绍
Redis多副本,采用主从(replication)部署结构,相较于单副本而言最大的特点就是主从实例间数据实时同步,并且提供数据持久化和备份策略。主从实例部署在不同的物理服务器上,根据公司的基础环境配置,可以实现同时对外提供服务和读写分离策略。
优点:
- 高可靠性:一方面,采用双机主备架构,能够在主库出现故障时自动进行主备切换,从库提升为主库提供服务,保证服务平稳运行;另一方面,开启数据持久化功能和配置合理的备份策略,能有效的解决数据误操作和数据异常丢失的问题;
- 读写分离策略:从节点可以扩展主库节点的读能力,有效应对大并发量的读操作。
缺点:
- 故障恢复复杂,如果没有RedisHA系统(需要开发),当主库节点出现故障时,需要手动将一个从节点晋升为主节点,同时需要通知业务方变更配置,并且需要让其它从库节点去复制新主库节点,整个过程需要人为干预,比较繁琐;
- 主库的写能力受到单机的限制,可以考虑分片;
- 主库的存储能力受到单机的限制,可以考虑Pika;
- 原生复制的弊端在早期的版本中也会比较突出,如:Redis复制中断后,Slave会发起psync,此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时可能会造成毫秒或秒级的卡顿;又由于COW机制,导致极端情况下的主库内存溢出,程序异常退出或宕机;主库节点生成备份文件导致服务器磁盘IO和CPU(压缩)资源消耗;发送数GB大小的备份文件导致服务器出口带宽暴增,阻塞请求,建议升级到最新版本。
-
主从复制是怎么实现的
主从复制共有三种模式:全量复制、基于长连接的命令传播、增量复制。
主从服务器第一次同步的时候,就是采用全量复制,此时主服务器会两个耗时的地方,分别是生成 RDB 文件和传输 RDB 文件。为了避免过多的从服务器和主服务器进行全量复制,可以把一部分从服务器升级为「经理角色」,让它也有自己的从服务器,通过这样可以分摊主服务器的压力。
第一次同步完成后,主从服务器都会维护着一个长连接,主服务器在接收到写操作命令后,就会通过这个连接将写命令传播给从服务器,来保证主从服务器的数据一致性。
如果遇到网络断开,增量复制就可以上场了,不过这个还跟 repl_backlog_size 这个大小有关系。
如果它配置的过小,主从服务器网络恢复时,可能发生「从服务器」想读的数据已经被覆盖了,那么这时就会导致主服务器采用全量复制的方式。所以为了避免这种情况的频繁发生,要调大这个参数的值,以降低主从服务器断开后全量同步的概率。
-
集群模式的工作原理是什么
基本通信原理
集群元数据的维护有两种方式:集中式、Gossip 协议。Redis cluster 节点间采用 gossip 协议进行通信。
集中式是将集群元数据(节点信息、故障等等)集中存储在某个节点上。集中式元数据集中存储的一个典型代表,就是大数据领域的
storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper(分布式协调的中间件)对所有元数据进行存储维护。Redis 维护集群元数据采用另一个方式,
gossip协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。集中式的好处在于,元数据的读取和更新,时效性非常好,一旦元数据出现了变更,就立即更新到集中式的存储中,其它节点读取的时候就可以感知到;不好在于,所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。
gossip 好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续打到所有节点上去更新,降低了压力;不好在于,元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。
- 10000 端口:每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如 7001,那么用于节点间通信的就是 17001 端口。每个节点每隔一段时间都会往另外几个节点发送
ping消息,同时其它几个节点接收到ping之后返回pong。 - 交换的信息:信息包括故障信息,节点的增加和删除,hash slot 信息等等。
gossip 协议
gossip 协议包含多种消息,包含
ping,pong,meet,fail等等。- meet:某个节点发送 meet 给新加入的节点,让新节点加入集群中,然后新节点就会开始与其它节点进行通信。
其实内部就是发送了一个 gossip meet 消息给新加入的节点,通知那个节点去加入我们的集群。
- ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。
- pong:返回 ping 和 meet,包含自己的状态和其它信息,也用于信息广播和更新。
- fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说,某个节点宕机啦。
ping 消息深入
ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。
每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。当然如果发现某个节点通信延时达到了
cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长,落后的时间太长了。比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以cluster_node_timeout可以调节,如果调得比较大,那么会降低 ping 的频率。每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含
3个其它节点的信息,最多包含总节点数减 2个其它节点的信息。分布式寻址算法
- hash 算法(大量缓存重建)
- 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
- Redis cluster 的 hash slot 算法
hash 算法
来了一个 key,首先计算 hash 值,然后对节点数取模。然后打在不同的 master 节点上。一旦某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去取数据。这会导致大部分的请求过来,全部无法拿到有效的缓存,导致大量的流量涌入数据库。
一致性 hash 算法
一致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。
来了一个 key,首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,遇到的第一个 master 节点就是 key 所在位置。
在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。
燃鹅,一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。
Redis cluster 的 hash slot 算法
Redis cluster 有固定的
16384个 hash slot,对每个key计算CRC16值,然后对16384取模,可以获取 key 对应的 hash slot。Redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过
hash tag来实现。任何一台机器宕机,另外两个节点,不影响的。因为 key 找的是 hash slot,不是机器。
Redis cluster 的高可用与主备切换原理
Redis cluster 的高可用的原理,几乎跟哨兵是类似的。
判断节点宕机
如果一个节点认为另外一个节点宕机,那么就是
pfail,主观宕机。如果多个节点都认为另外一个节点宕机了,那么就是fail,客观宕机,跟哨兵的原理几乎一样,sdown,odown。在
cluster-node-timeout内,某个节点一直没有返回pong,那么就被认为pfail。如果一个节点认为某个节点
pfail了,那么会在gossip ping消息中,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail。从节点过滤
对宕机的 master node,从其所有的 slave node 中,选择一个切换成 master node。
检查每个 slave node 与 master node 断开连接的时间,如果超过了
cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成master。从节点选举
每个从节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset 越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。
所有的 master node 开始 slave 选举投票,给要进行选举的 slave 进行投票,如果大部分 master node
(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成 master。从节点执行主备切换,从节点切换为主节点。
与哨兵比较
整个流程跟哨兵相比,非常类似,所以说,Redis cluster 功能强大,直接集成了 replication 和 sentinel 的功能。
- 10000 端口:每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如 7001,那么用于节点间通信的就是 17001 端口。每个节点每隔一段时间都会往另外几个节点发送
-
哨兵模式的作用
哨兵的介绍
sentinel,中文名是哨兵。哨兵是 Redis 集群架构中非常重要的一个组件,主要有以下功能:
- 集群监控:负责监控 Redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 Redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 Redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。
- 故障转移时,判断一个 master node 是否宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题。
- 即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的,因为如果一个作为高可用机制重要组成部分的故障转移系统本身是单点的,那就很坑爹了。
哨兵的核心知识
- 哨兵至少需要 3 个实例,来保证自己的健壮性。
- 哨兵 + Redis 主从的部署架构,是不保证数据零丢失的,只能保证 Redis 集群的高可用性。
- 对于哨兵 + Redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练。
哨兵集群必须部署 2 个以上节点,如果哨兵集群仅仅部署了 2 个哨兵实例,quorum = 1。
配置
quorum=1,如果 master 宕机, s1 和 s2 中只要有 1 个哨兵认为 master 宕机了,就可以进行切换,同时 s1 和 s2 会选举出一个哨兵来执行故障转移。但是同时这个时候,需要 majority,也就是大多数哨兵都是运行的。如果此时仅仅是 M1 进程宕机了,哨兵 s1 正常运行,那么故障转移是 OK 的。但是如果是整个 M1 和 S1 运行的机器宕机了,那么哨兵只有 1 个,此时就没有 majority 来允许执行故障转移,虽然另外一台机器上还有一个 R1,但是故障转移不会执行。
配置
quorum=2,如果 M1 所在机器宕机了,那么三个哨兵还剩下 2 个,S2 和 S3 可以一致认为 master 宕机了,然后选举出一个来执行故障转移,同时 3 个哨兵的 majority 是 2,所以还剩下的 2 个哨兵运行着,就可以允许执行故障转移。 -
Redis哨兵是怎么工作的
- 每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被当前 Sentinel 标记为主观下线。
- 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
- 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 (在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 )。
- 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会变成主观下线。若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
- sentinel节点会与其他sentinel节点进行“沟通”,投票选举一个sentinel节点进行故障处理,在从节点中选取一个主节点,其他从节点挂载到新的主节点上自动复制新主节点的数据。
-
哨兵主备切换的数据丢失问题
导致数据丢失的两种情况
主备切换的过程,可能会导致数据丢失:
- 异步复制导致的数据丢失
因为 master->slave 的复制是异步的,所以可能有部分数据还没复制到 slave,master 就宕机了,此时这部分数据就丢失了。
- 脑裂导致的数据丢失
脑裂,也就是说,某个 master 所在机器突然脱离了正常的网络,跟其他 slave 机器不能连接,但是实际上 master 还运行着。此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了 master。这个时候,集群里就会有两个 master ,也就是所谓的脑裂。
此时虽然某个 slave 被切换成了 master,但是可能 client 还没来得及切换到新的 master,还继续向旧 master 写数据。因此旧 master 再次恢复的时候,会被作为一个 slave 挂到新的 master 上去,自己的数据会清空,重新从新的 master 复制数据。而新的 master 并没有后来 client 写入的数据,因此,这部分数据也就丢失了。
数据丢失问题的解决方案
进行如下配置:
表示,要求至少有 1 个 slave,数据复制和同步的延迟不能超过 10 秒。
如果说一旦所有的 slave,数据复制和同步的延迟都超过了 10 秒钟,那么这个时候,master 就不会再接收任何请求了。
- 减少异步复制数据的丢失
有了
min-slaves-max-lag这个配置,就可以确保说,一旦 slave 复制数据和 ack 延时太长,就认为可能 master 宕机后损失的数据太多了,那么就拒绝写请求,这样可以把 master 宕机时由于部分数据未同步到 slave 导致的数据丢失降低的可控范围内。- 减少脑裂的数据丢失
如果一个 master 出现了脑裂,跟其他 slave 丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的 slave 发送数据,而且 slave 超过 10 秒没有给自己 ack 消息,那么就直接拒绝客户端的写请求。因此在脑裂场景下,最多就丢失 10 秒的数据。
-
哨兵集群的自动发现机制
哨兵互相之间的发现,是通过 Redis 的
pub/sub系统实现的,每个哨兵都会往__sentinel__:hello这个 channel 里发送一个消息,这时候所有其他哨兵都可以消费到这个消息,并感知到其他的哨兵的存在。每隔两秒钟,每个哨兵都会往自己监控的某个 master+slaves 对应的
__sentinel__:hellochannel 里发送一个消息,内容是自己的 host、ip 和 runid 还有对这个 master 的监控配置。每个哨兵也会去监听自己监控的每个 master+slaves 对应的
__sentinel__:hellochannel,然后去感知到同样在监听这个 master+slaves 的其他哨兵的存在。每个哨兵还会跟其他哨兵交换对
master的监控配置,互相进行监控配置的同步。 -
Redis 如何实现服务高可用
要想设计一个高可用的 Redis 服务,一定要从 Redis 的多服务节点来考虑,比如 Redis 的主从复制、哨兵模式、切片集群。
主从复制
主从复制是 Redis 高可用服务的最基础的保证,实现方案就是将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,且主从服务器之间采用的是「读写分离」的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
也就是说,所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
注意,主从服务器之间的命令复制是异步进行的。
具体来说,在主从服务器命令传播阶段,主服务器收到新的写命令后,会发送给从服务器。但是,主服务器并不会等到从服务器实际执行完命令后,再把结果返回给客户端,而是主服务器自己在本地执行完命令后,就会向客户端返回结果了。如果从服务器还没有执行主服务器同步过来的命令,主从服务器间的数据就不一致了。
所以,无法实现强一致性保证(主从数据时时刻刻保持一致),数据不一致是难以避免的。
哨兵模式
在使用 Redis 主从服务的时候,会有一个问题,就是当 Redis 的主从服务器出现故障宕机时,需要手动进行恢复。
为了解决这个问题,Redis 增加了哨兵模式(Redis Sentinel),因为哨兵模式做到了可以监控主从服务器,并且提供主从节点故障转移的功能。
切片集群模式
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 Redis 切片集群(Redis Cluster )方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和节点之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步:
- 根据键值对的 key,按照 CRC16 算法 (opens new window)计算一个 16 bit 的值。
- 再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
接下来的问题就是,这些哈希槽怎么被映射到具体的 Redis 节点上的呢?有两种方案:
- 平均分配: 在使用 cluster create 命令创建 Redis 集群时,Redis 会自动把所有哈希槽平均分布到集群节点上。比如集群中有 9 个节点,则每个节点上槽的个数为 16384/9 个。
- 手动分配: 可以使用 cluster meet 命令手动建立节点间的连接,组成集群,再使用 cluster addslots 命令,指定每个节点上的哈希槽个数。
然后在集群运行的过程中,key1 和 key2 计算完 CRC16 值后,对哈希槽总个数 4 进行取模,再根据各自的模数结果,就可以被映射到哈希槽 1(对应节点1) 和 哈希槽 2(对应节点2)。
需要注意的是,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作
6.4 缓存
-
缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存击穿、缓存降级全搞定!
缓存雪崩
缓存雪崩指的是缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
看不懂?那我说人话。
我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃。
解决办法
- 事前:尽量保证整个 Redis 集群的高可用性,发现机器宕机尽快补上,选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉, 通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 事后:利用 Redis 持久化机制保存的数据尽快恢复缓存
缓存穿透
一般是黑客故意去请求缓存中不存在的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量 请求而崩掉。
这也看不懂?那我再换个说法好了。
缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,接着查询数据库也无法查询出结果,因此也不会写入到缓存中,这将会导致每个查询都会去请求数据库,造成缓存穿透。
解决办法
1、布隆过滤器
这是最常见的一种解决方法了,它是将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压 力。
对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
这里稍微科普一下布隆过滤器。
布隆过滤器是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。 它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
该算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是布隆过滤器的基本思想,一般用于在大数据量的集合中判定某元素是否存在。
2、缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;如果一个查询返回的数据为空(不管是数据不存 在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
但是这种方法会存在两个问题:
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
我们可以从适用场景和维护成本两方面对这两汇总方法进行一个简单比较:
适用场景:缓存空对象适用于1、数据命中不高 2、数据频繁变化且实时性较高 ;而布隆过滤器适用1、数据命中不高 2、数据相对固定即实时性较低
维护成本:缓存空对象的方法适合1、代码维护简单 2、需要较多的缓存空间 3、数据会出现不一致的现象;布隆过滤器适合 1、代码维护较复杂 2、缓存空间要少一些
缓存预热
缓存预热是指系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。用户会直接查询事先被预热的缓存数据!
解决思路 1、直接写个缓存刷新页面,上线时手工操作下; 2、数据量不大,可以在项目启动的时候自动进行加载; 3、定时刷新缓存;
缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:定时删除和惰性删除,其中: (1)定时删除:定时去清理过期的缓存; (2)惰性删除:当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。 两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开一个洞。
比如常见的电商项目中,某些货物成为“爆款”了,可以对一些主打商品的缓存直接设置为永不过期。即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了。mutex key互斥锁基本上是用不上的,有个词叫做大道至简。
缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。 降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。 以参考日志级别设置预案: (1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级; (2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警; (3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级; (4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。
-
数据库和缓存如何保证一致性
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的 情况,最好不要做这个方案,最好将读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况。
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
最经典的缓存+数据库读写的模式,就是 预留缓存模式Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先删除缓存,然后再更新数据库,这样读的时候就会发现缓存中没有数据而直接去数据库中拿数据了。(因为要删除,狗日的编辑器可能会背着你做一些优化,要彻底将缓存中的数据进行删除才行)
在高并发的业务场景下,数据库的性能瓶颈往往都是用户并发访问过大。所以,一般都使用Redis做一个缓冲操作,让请求先访问到Redis,而不是直接去访问MySQL等数据库,从而减少网络请求的延迟响应。
-
如何保证缓存与数据库的双写一致性
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
Cache Aside Pattern
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。
最初级的缓存不一致问题及解决方案
问题:先更新数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
解决思路 1:先删除缓存,再更新数据库。如果数据库更新失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,所以去读了数据库中的旧数据,然后更新到缓存中。
解决思路 2:延时双删。依旧是先更新数据库,再删除缓存,唯一不同的是,我们把这个删除的动作,在不久之后再执行一次,比如 5s 之后。
删除的动作,可以有多种选择,比如:1. 使用
DelayQueue,会随着 JVM 进程的死亡,丢失更新的风险;2. 放在MQ,但编码复杂度为增加。总之,我们需要综合各种因素去做设计,选择一个最合理的解决方案。比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了…
为什么上亿流量高并发场景下,缓存会出现这个问题?
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新执行“读取数据+更新缓存”的操作,根据唯一标识路由之后,也发送到同一个 jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,没有读到缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题:
- 读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。
该解决方案,最大的风险点在于说,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。务必通过一些模拟真实的测试,看看更新数据的频率是怎样的。
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。如果一个内存队列里居然会挤压 100 个商品的库存修改操作,每个库存修改操作要耗费 10ms 去完成,那么最后一个商品的读请求,可能等待 10 * 100 = 1000ms = 1s 后,才能得到数据,这个时候就导致读请求的长时阻塞。
一定要做根据实际业务系统的运行情况,去进行一些压力测试,和模拟线上环境,去看看最繁忙的时候,内存队列可能会挤压多少更新操作,可能会导致最后一个更新操作对应的读请求,会 hang 多少时间,如果读请求在 200ms 返回,如果你计算过后,哪怕是最繁忙的时候,积压 10 个更新操作,最多等待 200ms,那还可以的。
如果一个内存队列中可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
其实根据之前的项目经验,一般来说,数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的。像这种针对读高并发、读缓存架构的项目,一般来说写请求是非常少的,每秒的 QPS 能到几百就不错了。
- 读请求并发量过高
这里还必须做好压力测试,确保恰巧碰上上述情况的时候,还有一个风险,就是突然间大量读请求会在几十毫秒的延时 hang 在服务上,看服务能不能扛的住,需要多少机器才能扛住最大的极限情况的峰值。
但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。
- 多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 Nginx 服务器路由到相同的服务实例上。
比如说,对同一个商品的读写请求,全部路由到同一台机器上。可以自己去做服务间的按照某个请求参数的 hash 路由,也可以用 Nginx 的 hash 路由功能等等。
- 热点商品的路由问题,导致请求的倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能会造成某台机器的压力过大。就是说,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以其实要根据业务系统去看,如果更新频率不是太高的话,这个问题的影响并不是特别大,但是的确可能某些机器的负载会高一些。
-
常见的数据优化方案
一、缓存双淘汰法
- 先淘汰缓存
- 再写数据库
- 往消息总线esb发送一个淘汰消息,发送立即返回。写请求的处理时间几乎没有增加,这个方法淘汰了缓存两次。因此被称为“缓存双淘汰法“,而在消息总线下游,有一个异步淘汰缓存的消费者,在拿到淘汰消息在1s后淘汰缓存,这样,即使在一秒内有脏数据入缓存,也能够被淘汰掉。
二、异步淘汰缓存
上述的步骤,都是在业务线里面执行,新增一个线下的读取binlog异步淘汰缓存模块,读取binlog总的数据,然后进行异步淘汰。
这里简单提供一个思路
1.思路:
MySQL binlog增量发布订阅消费+消息队列+增量数据更新到Redis
1)读请求走Redis:热数据基本都在Redis
2)写请求走MySQL: 增删改都操作MySQL
3)更新Redis数据:MySQ的数据操作binlog,来更新到Redis
2.Redis更新
1)数据操作主要分为两块:
- 一个是全量(将全部数据一次写入到Redis)
- 一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新,就无需在从业务线去操作缓存内容。
7.熟悉使用 Python 语言
7.1 Django框架
-
Django的优点和缺点
-
什么MVC、MTV模式
M:Model,模型,和数据库进行交互
V:View,视图,负责产生 Html 页面
C:Controller,控制器,接收请求,进行处理,与 M 和 V 进行交互,返回应答。
M:Model,模型,和 MVC 中的 M 功能相同,和数据库进行交互
V:view,视图,和 MVC 中的 C 功能相同,接收请求,进行处理,与 M 和 T 进行交互,返回应答
T:Template,模板,和 MVC 中的 V 功能相同,产生 Html 页面
-
Django中间件
Django 在中间件中预置了六个方法,这六个方法的区别在于不同的阶段执行,对输入或输出进行干预,方法如下:
1.初始化:无需任何参数,服务器响应第一个请求的时候调用一次,用于确定是否启用当前中间件。
2.处理请求前:在每个请求上调用,返回 None 或 HttpResponse 对象。
3.处理视图前:在每个请求上调用,返回 None 或 HttpResponse 对象。
4.处理模板响应前:在每个请求上调用,返回实现了 render 方法的响应对象。
5.处理响应后:所有响应返回浏览器之前被调用,在每个请求上调用,返回 HttpResponse 对象。
6.异常处理:当视图抛出异常时调用,在每个请求上调用,返回一个 HttpResponse 对象。
-
Django如何提升性能
对一个后端开发程序员来说,提升性能指标主要有两个一个是并发数,另一个是响应时间网站性能的优化一般包括 web 前端性能优化,应用服务器性能优化,存储服务器优化。
(1)合理的使用缓存技术,对一些常用到的动态数据,比如首页做一个缓存,或者某些常用的数据做个缓存,设置一定得过期时间,这样减少了对数据库的压力,提升网站性能。
(2) 使用 celery 消息队列,将耗时的操作扔到队列里,让 worker 去监听队列里的任务,实现异步操 作,比如发邮件,发短信。
(3) 就是代码上的一些优化,补充:nginx 部署项目也是项目优化,可以配置合适的配置参数,提升效率,增加并发量。
(4) 如果太多考虑安全因素,服务器磁盘用固态硬盘读写,远远大于机械硬盘,这个技术现在没有普及,主要是固态硬盘技术上还不是完全成熟, 相信以后会大量普及。
(5) 另外还可以搭建服务器集群,将并发访问请求,分散到多台服务器上处理。
7.2 爬虫
-
你用过的爬虫框架或者模块有哪些?谈谈他们的区别或者优缺点?
(1) Python 自带:urllib、urllib2
urllib 和 urllib2 模块都做与请求 URL 相关的操作,但他们提供不同的功能。
urllib2:urllib2.urlopen 可以接受一个 Request 对象或者 url,(在接受 Request 对象时候,并以此可以来设置一个 URL 的 headers),urllib.urlopen 只接收一个 url。
urllib 有 urlencode,urllib2 没有,因此总是 urllib,urllib2 常会一起使用的原因。
(2) 第三方:requests
request 是一个 HTTP 库, 它只是用来,进行请求,对于 HTTP 请求,他是一个强大的库,下载,解析全部自己处理,灵活性更高,高并发与分布式部署也非常灵活,对于功能可以更好实现
(3) 框架: Scrapy
scrapy 是封装起来的框架,它包含了下载器,解析器,日志及异常处理,基于多线程,twisted 的方式处理,对于固定单个网站的爬取开发,有优势,但是对于多网站爬取,并发及分布式处理方面,不够灵活,不便调整与括展。
Scrapy 优点
scrapy 是异步的
采取可读性更强的 xpath 代替正则
强大的统计和 log 系统
同时在不同的 url 上爬行
支持 shell 方式,方便独立调试
写 middleware,方便写一些统一的过滤器
通过管道的方式存入数据库
Scrapy 缺点
基于 python 的爬虫框架,扩展性比较差
基于 twisted 框架,运行中的 exception 是不会干掉 reactor,并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉。
-
你做过什么爬虫案例
- 爬取网易云音乐
- 爬取豆瓣电影TOP100
- 爬虫淘宝商品信息
-
常见的反爬虫和应对方法?
(1) 通过 Headers 反爬虫
从用户请求的 Headers 反爬虫是最常见的反爬虫策略。很多网站都会对 Headers 的 User-Agent 进行检测,还有一部分网站会对 Referer 进行检测(一些资源网站的防盗链就是检测 Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加 Headers,将浏览器的 User-Agent 复制到爬虫的 Headers 中;或者将 Referer 值修改为目标网站域名。对于检测 Headers 的反爬虫,在爬虫中修改或者添加 Headers 就能很好的绕过。
(2) 基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一 IP 短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
大多数网站都是前一种情况,对于这种情况,使用 IP 代理就可以解决。可以专门写一个爬虫,爬取网上公开的代理 ip,检测后全部保存起来。这样的代理 ip 爬虫经常会用到,最好自己准备一个。有了大量代理 ip 后可以每请求几次更换一个 ip,这在 requests 或者 urllib2 中很容易做到,这样就能很容易的绕过第一种反爬虫。
对于第二种情况,可以在每次请求后随机间隔几秒再进行下一次请求。有些有逻辑漏洞的网站,可以通过请求几次,退出登录,重新登录,继续请求来绕过同一账号短时间内不能多次进行相同请求的限制。
(3) 动态页面的反爬虫
上述的几种情况大多都是出现在静态页面,还有一部分网站,我们需要爬取的数据是通过 ajax 请求得到,或者通过 JavaScript 生成的。首先用 Fiddler 对网络请求进行分析。如果能够找到 ajax 请求,也能分析出具体的参数和响应的具体含义,我们就能采用上面的方法,直接利用 requests 或者 urllib2模拟 ajax 请求,对响应的 json 进行分析得到需要的数据。
能够直接模拟 ajax 请求获取数据固然是极好的,但是有些网站把 ajax 请求的所有参数全部加密了。我们根本没办法构造自己所需要的数据的请求。这种情况下就用 selenium+phantomJS,调用浏览器内核,并利用 phantomJS 执行 js 来模拟人为操作以及触发页面中的 js 脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程,只是完完整整的把人浏览页面获取数据的过程模拟一遍。
用这套框架几乎能绕过大多数的反爬虫,因为它不是在伪装成浏览器来获取数据(上述的通过添加Headers 一定程度上就是为了伪装成浏览器),它本身就是浏览器,phantomJS 就是一个没有界面的浏览器,只是操控这个浏览器的不是人。利 selenium+phantomJS 能干很多事情,例如识别点触式(12306)或者滑动式的验证码,对页面表单进行暴力破解等。
-
验证码的解决
(1) 图形验证码
干扰、杂色不是特别多的图片可以使用开源库 Tesseract 进行识别,太过复杂的需要借助第三方打码平台。
(2) 滑块验证码
点击和拖动滑块验证码可以借助 selenium、无图形界面浏览器(chromedirver 或者 phantomjs)和pillow 包来模拟人的点击和滑动操作,pillow 可以根据色差识别需要滑动的位置。
7.3 数据分析
-
实现数据分析的方法
使用numpy和pandas进行数据处理,使用matplotlib库实现数据可视化
-
数据分析项目
7.4 机器学习算法
-
常见的机器学习算法有哪些
KNN算法、线性回归法、决策树算法、随机森林算法
-
什么是机器学习
简单的说,机器学习就是让机器从数据中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好,这就是机器学习。
对上面这句话的理解:
数据:从现实生活抽象出来的一些事物或者规律的特征进行数字化得到。
学习:在数据的基础上让机器重复执行一套特定的步骤(学习算法)进行事物特征的萃取,得到一个更加逼近于现实的描述(这个描述是一个模型它的本身可能就是一个函数)。我们把大概能够描述现实的这个函数称作我们学到的模型。
更好:我们通过对模型的使用就能更好的解释世界,解决与模型相关的问题。
-
解释有监督和无监督机器学习之间的区别?
监督学习需要训练标记的数据。换句话说,监督学习使用了基本事实,这意味着我们对输出和样本已有知识。这里的目标是学习一个近似输入和输出之间关系的函数。
另一方面,无监督学习不使用标记的输出。此处的目标是推断数据集中的自然结构。
-
KNN算法介绍
邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法 。
k近邻法是一种基本的分类和回归方法,是监督学习方法里的一种常用方法。k近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测。
k近邻法三要素:距离度量、k值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的pL距离。k值小时,k近邻模型更复杂,容易发生过拟合;k值大时,k近邻模型更简单,又容易欠拟合。因此k值得选择会对分类结果产生重大影响。k值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k。
优点
-
简单,易于理解,易于实现,无需估计参数,无需训练;
-
适合对稀有事件进行分类;
-
特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
缺点
- 该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数 。
- 该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点 。
-
-
线性回归法介绍
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
- 特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归
线性回归当中主要有两种模型,一种是线性关系,另一种是非线性关系。
-
PCA算法介绍
PCA(principal components analysis)即主成分分析技术,又称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。
PCA算法优点:
1、使得数据集更易使用;
2、降低算法的计算开销;
3、去除噪声;
4、使得结果容易理解;
5、完全无参数限制。PCA算法缺点:
1、主成分解释其含义往往具有一定的模糊性,不如原始样本完整
2、贡献率小的主成分往往可能含有对样本差异的重要信息,也就是可能对于区分样本的类别(标签)更有用
3、特征值矩阵的正交向量空间是否唯一有待讨论
4、无监督学习PCA算法求解步骤:
-
去除平均值
-
计算协方差矩阵
-
计算协方差矩阵的特征值和特征向量
-
将特征值排序
-
保留前N个最大的特征值对应的特征向量
-
将原始特征转换到上面得到的N个特征向量构建的新空间中(最后两步,实现了特征压缩)**
PCA是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于识别和提取数据的主要特征分量,通过将数据坐标轴旋转到数据角度上那些最重要的方向(方差最大);然后通过特征值分析,确定出需要保留的主成分个数,舍弃其他非主成分,从而实现数据的降维。降维使数据变得更加简单高效,从而实现提升数据处理速度的目的,节省大量的时间和成本。降维也成为了应用非常广泛的数据预处理方法。PCA算法已经被广泛的应用于高维数据集的探索与可视化,还可以用于数据压缩,数据预处理,图像,语音,通信的分析处理等领域。
-
-
支持向量机-SVM介绍
SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他其他问题中。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类(binary classification)的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。- SVM的主要特点:
SVM主要思想是针对两类分类问题,在高维空间中寻找一个超平面作为两类的分割,以保证最小的分类错误率。
SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,即寻找一个分类面使它两侧的空白区域(margin)最大。
过两类样本中离分类面最近的点且平行于最优分类面的超平面上的训练样本就叫做支持向量。
最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。
- SVM的主要特点:
-
随机森林算法介绍
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
随机森林的优点有 :
1)对于很多种资料,它可以产生高准确度的分类器;
2)它可以处理大量的输入变数;
3)它可以在决定类别时,评估变数的重要性;
4)在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计;
5)它包含一个好方法可以估计遗失的资料,如果有很大一部分的资料遗失,仍可以维持准确度;
6)学习过程是很快速的。
算法过程
1、一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
2、当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
3、决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了),一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
4、按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
数据的随机选取
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。待选特征的随机选取
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
7.5 Python语言
-
Python 的内存管理机制及调优手段
内存管理机制:引用计数、垃圾回收、内存池。
引用计数
引用计数是一种非常高效的内存管理手段, 当一个 Python 对象被引用时其引用计数增加 1, 当其不再被一个变量引用时则计数减 1. 当引用计数等于 0 时对象被删除。
垃圾回收
(1) 引用计数
引用计数也是一种垃圾收集机制,而且也是一种最直观,最简单的垃圾收集技术。当 Python 的某
个对象的引用计数降为 0 时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为 1。如果引用被删除,对象的引用计数为 0,那么该对象就可以被垃圾回收。不过如果出现循环引用的话,引用计数机制就不再起有效的作用了(2)标记清除
如果两个对象的引用计数都为 1,但是仅仅存在他们之间的循环引用,那么这两个对象都是需要被
回收的,也就是说,它们的引用计数虽然表现为非 0,但实际上有效的引用计数为 0。所以先将循环引用摘掉,就会得出这两个对象的有效计数。(3) 分代回收
从前面“标记-清除”这样的垃圾收集机制来看,这种垃圾收集机制所带来的额外操作实际上与系统
中总的内存块的数量是相关的,当需要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾回收带来的额外操作就越少;反之,当需回收的内存块越少时,垃圾检测就将比垃圾回收带来更少的额外操作。内存池
(1) Python 的内存机制呈现金字塔形状,-1,-2 层主要有操作系统进行操作
(2) 第 0 层是 C 中的 malloc,free 等内存分配和释放函数进行操作
(3)第 1 层和第 2 层是内存池,有 Python 的接口函数 PyMem_Malloc 函数实现,当对象小于
256K 时有该层直接分配内存(4) 第 3 层是最上层,也就是我们对 Python 对象的直接操作
Python 在运行期间会大量地执行 malloc 和 free 的操作,频繁地在用户态和核心态之间进行切换,这将严重影响 Python 的执行效率。为了加速 Python 的执行效率,Python 引入了一个内存池机制,用于管理对小块内存的申请和释放。
Python 内部默认的小块内存与大块内存的分界点定在 256 个字节,当申请的内存小于 256 字节时,PyObject_Malloc 会在内存池中申请内存;当申请的内存大于 256 字节时,PyObject_Malloc 的行为将蜕化为 malloc 的行为。当然,通过修改 Python 源代码,我们可以改变这个默认值,从而改变 Python 的默认内存管理行为。
-
Python 函数调用的时候参数的传递方式是值传递还是引用传递
Python 的参数传递有:位置参数、默认参数、可变参数、关键字参数。函数的传值到底是值传递还是引用传递,要分情况:
不可变参数用值传递
像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变不可变对象
可变参数是引用传递的
比如像列表,字典这样的对象是通过引用传递、和 C 语言里面的用指针传递数组很相似,可变对象能在函数内部改变。
-
什么是装饰器?
「装饰器」作为 Python 高级语言特性中的重要部分,是修改函数的一种超级便捷的方式,适当使用能够有效提高代码的可读性和可维护性,非常的便利灵活。
「装饰器」本质上就是一个函数,这个函数的特点是可以接受其它的函数当作它的参数,并将其替换成一个新的函数(即返回给另一个函数)。
装饰器本质上是一个 Python 函数,它可以在让其他函数在不需要做任何代码的变动的前提下增加额外的功能。装饰器的返回值也是一个函数的对象,它经常用于有切面需求的场景。 比如:插入日志、性能测试、事务处理、缓存、权限的校验等场景 有了装饰器就可以抽离出大量的与函数功能本身无关的雷同代码并发并继续使用。
8. 了解前端技术
8.1 Html/Css
8.2 JavaScript
8.3 Vue框架
-
MVC和MVVM
MVVM是Model-View-ViewModel的缩写。MVVM是一种设计思想。Model 层代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑;View 代表UI 组件,它负责将数据模型转化成UI 展现出来,ViewModel 是一个同步View 和 Model的对象。
在MVVM架构下,View 和 Model 之间并没有直接的联系,而是通过ViewModel进行交互,Model 和 ViewModel 之间的交互是双向的, 因此View 数据的变化会同步到Model中,而Model 数据的变化也会立即反应到View 上。
ViewModel 通过双向数据绑定把 View 层和 Model 层连接起来,而View 和 Model 之间的同步工作完全是自动的,无需人为干涉,因此开发者只需关注业务逻辑,不需要手动操作DOM, 不需要关注数据状态的同步问题,复杂的数据状态维护完全由 MVVM 来统一管理。
mvc和mvvm其实区别并不大,都是一种设计思想。主要就是mvc中Controller演变成mvvm中的viewModel。mvvm主要解决了mvc中大量的DOM 操作使页面渲染性能降低,加载速度变慢,影响用户体验。
区别:vue数据驱动,通过数据来显示视图层而不是节点操作。
场景:数据操作比较多、频繁的场景,更加便捷。
-
Vue 生命周期的理解
总共分为8个阶段创建前/后,载入前/后,更新前/后,销毁前/后。
**创建前后:**在beforeCreated阶段,vue实例的挂载元素el和数据对象data都为undefined,还未初始化。在created阶段,vue实例的数据对象data有了,el和数据对象data都为undefined,还未初始化。在created阶段,vue实例的数据对象data有了,el还没有。
**载入前后:**在beforeMount阶段,vue实例的$el和data都初始化了,但还是挂载之前为虚拟的dom节点,data.message还未替换。在mounted阶段,vue实例挂载完成,data.message成功渲染。
**更新前后:**当data变化时,会触发beforeUpdate和updated方法。
**销毁前后:**在执行destroy方法后,对data的改变不会再触发周期函数,说明此时vue实例已经解除了事件监听以及和dom的绑定,但是dom结构依然存在
-
Vue的优点
- 轻量级框架:只关注视图层,是一个构建数据的视图集合,大小只有几十
kb; - 简单易学:国人开发,中文文档,不存在语言障碍 ,易于理解和学习;
- 双向数据绑定:保留了
angular的特点,在数据操作方面更为简单; - 组件化:保留了
react的优点,实现了html的封装和重用 - 在构建单页面应用方面有着独特的优势;
- 视图,数据,结构分离:使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作;
- 虚拟DOM:
dom操作是非常耗费性能的, 不再使用原生的dom操作节点,极大解放dom操作,但具体操作的还是dom不过是换了另一种方式; - 运行速度更快:相比较于
react而言,同样是操作虚拟dom,就性能而言,vue存在很大的优势。
- 轻量级框架:只关注视图层,是一个构建数据的视图集合,大小只有几十
二 项目经历
1. 基于机器学习的冬奥会智能分析与预测系统
1.1 项目描述
本项目是我校的省级创新创业项目,负责后端开发与数据库设计,对往届冬奥会数据处理与分析,前端通过可视化展示给用户,根据往届冬奥会信息进行预测模型训练,预测各个国家在下一届冬奥会所获得的奖牌情况。
1.2 工作内容
-
从冬奥会多个官网收集数据,进行处理,存储到MySQL数据库,进行数据库表结构设计。
-
首页数据缓存到Redis数据库,增加系统可维护性,提高网页的响应速度,提高并发访问量。
-
使用随机森林算法建立预测奖牌模型,进行各个国家奖牌预测,并将结果数据缓存到Redis中。
-
使用Viper配置项目参数,增加项目可扩展性,使用Swagger编写注释,方便前端理解接口和代码调试。
-
项目使用JWT跨域认证,增加用户数据安全性,注册使用Email进行身份验证,保障了账号的真实性。
-
使用Zap日志进行日志收集,提高日志收集效率,能够收集程序运行多种基本信息,便于系统调试。
1.3 面试问题
-
介绍一下项目
本项目是我校的省级创新创业项目,我负责后端开发与数据库设计,项目主要包括两部分,第一为冬奥会的数据分析与图表展示,第二为使用随机森林算法根据往届冬奥会信息进行预测模型训练,预测各个国家在下一届冬奥会所获得的奖牌情况。采用前后端分离开发,前端采用Vue+Echarts,后端采用GoLang的gin框架进行开发,预测算法机器学习中的随机森林算法,数据库采用Mysql,数据来源为2022北京冬奥组委官网、国际奥林匹克官网等网站收集奖牌及视频数据,百度百科收集运动员个人信息数据,聚会数据网收集预测因素数据。
-
项目重点难点有什么
预测使用的方法为随机森林。
预测模型建立时考虑了9种可能对预测产生影响的因素,分别为(1).参加冬奥会男子数(2).参加冬奥会女子数(3).是否为主办方(4).国家人均gdp(5).国家总gdp(6).国家人口总数 (7).国家社会制度 (8).获得奖牌排行 (9).获得奖牌占总奖牌数的比率。
首先用RandomForestRegressor按照不同的权重对9种因素进行模型训练,然后使用同种方法对每一种因素进行训练,并预测出2026年的值,再将2026年的数据带入总的预测模型,并得出2026年冬奥会各个国家获得的奖牌,并将2022年的奖牌进行数据检验,最后将获得的数据进行保存。
-
项目使用了哪些技术
本项目采用前后端分离开发,前端采用Vue+Echarts,后端采用GoLang的gin框架进行开发,预测算法机器学习中的随机森林算法,使用的语言为Python,在开发过程中我们使用了一下技术:
- 使用zap日志库进行系统日志收集
- 使用配置信息viper进行系统参数配置
- 使用swagger编写接口规范和接口文档
- 使用JWT跨域认证,实现Token机制
- 使用雪花算法生成用户ID,在并发操作下,保证了数据的唯一性,用户不知道系统内部信息
- 使用go-redis,首页数据缓存到Redis数据库,邮箱验证码和Token保存在Redis中
- 使用gorm开发,进行MySQL数据库操作。
-
项目有哪些亮眼的设计
- 采取随机森林算法
- 首页数据缓存到Redis数据库,提高网页的响应速度,提高并发访问量
- 使用zap日志库,增加日志文件的详细内容,系统出问题快速定位解决
- 使用Viper进行参数配置,使系统参数集中管理,方便参数的维护与修改
- 使用swagger编写接口文档,开发更加规范,降低了前后端交互的困难,并且支持在线测试接口
- 使用雪花算法生成用户分布式ID,使ID不会重复,有序并且生成速度很快
-
从项目中学到了什么
- 对项目开发的规范流程有了具体的掌握
- 使用多种中间件完成项目开发,加快项目开发效率,使项目更加健壮
- 使用机器算法完成预测功能,对机器学习有了更加深入的理解
2. 基于微服务的通用账户功能系统
2.1 项目描述
本项目是基于Micro框架开发的通用的账户功能系统,包括账户的基本操作如账号增删改查和权限操作,使用配置中心、链路追踪、监控等相关技术,详情查看博客:https://juejin.cn/column/7179162138446364732
2.2 工作内容
-
使用ProtoBuf进行参数传输和定义相关接口,定义了13个相关的账户功能接口。
-
使用Redis缓存Email验证码和存储Token,提高用户注册效率,实现定时清除Token机制。
-
使用Docker部署多个微服务插件,如Consul,Jaeger,Prometheus等,降低开发难度,提高开发效率。
-
客户端使用负载均衡,大大提高项目的并发量,使用Prometheus进行项目监控,及时发现并解决问题。
2.3 面试问题
-
介绍一下项目
项目是基于Micro框架开发的通用的账户功能系统,采用Mysql+Redis+Docker进行项目开发,包括账户的基本操作如账号增删改查和权限操作,使用配置中心、链路追踪、监控等相关技术,使用ProtoBuf进行数据传输和Api接口定义,相关插件使用Docker进行安装,避免花费大量精力放在安装部署方面。
-
项目重点难点有什么
- 对ProtoBuf需要定义的参数和接口进行细致的思考
- 使用Docker、Docker Compose进行插件安装和快速启动
- 对多个微服务插件的使用和配置
-
项目使用了哪些技术
- 使用go语言进行项目开发
- 使用go-micro微服务框架进行服务端开发
- 使用Docker安装部署中间件,加快开发效率
- 使用ProtoBuf行数据传输和Api接口定义
- 使用Gorm与Mysql数据库进行交互
- 使用Zap日志库进行日志记录
-
项目有哪些亮眼的设计
- 使用Docker进行相关插件的安装,提高了开发效率,跨系统移植更加简单
- 使用了许多微服务插件(如Consul、Jaeger、Prometheus)完善项目功能
- 使用ProtoBuf行数据传输和Api接口定义
- 使用Zap、Markflie、Redis进行项目开发,使项目更加完善。
-
从项目中学到了什么
-
学到了微服务开发流程:
-
创建项目(Docker或go-micro)
-
编写proto文件,并生成.go文件
-
编写domain数据库方面,包含(model层,repository层,service层)等
-
编写Handle层,实现proto定义接口
-
编写common层,配置,mysql,公共函数,jaeger(链路追踪)等
-
编写main函数,完成项目闭环
-
-
Docker、Docker Compose的基本使用
-
Proto的使用、命令、编写
-
对微服务组件有了更加深入的了解
-
对微服务的作用、使用和开发有了更加深入的了解
-
对中间件整合到项目中更加熟悉
-