CHI的Cache Stashing和DVM操作
本文介绍CHI协议中的Cache Stashing操作和DVM操作,将分为两章节来描述。
一、Cache Stashing
本文描述cache stashing机制,据此,RN刷下来的数据可以储存在其它peer RN的cache里。包含如下小节。
1.1 Overview
Cache stashing机制可将数据存在系统中特定cache中,确保data靠近使用的节点,因此可以提高系统性能。Cache stashing只支持Snoopable memory空间。CHI协议主要支持两种类型的cache stashing操作。
- Write with stash hint:WriteUniqueStash,用于cache data需要allocate在某一个数据需要被写更新的节点。write携带的stash hint信号可以是Full或Ptl的cacheline写,这会影响到使用的snoop transactions;
- Independent stash request:StashOnce,当写数据和贮存stash data到特定cacheline的request是分开的情况下。independent Stash transaction可以用于指示cacheline应该以Unique或Shared的状态贮存着,通过分别使用StashOnceUnique或StashOnceShared transaction来实现。
上述两种cache stashing的形式都可以贮存数据到不同的cache level。Stash target cache可以是peer cache(通过NodeID),也可以是peer node的logical processor cache(通过LPID+NodeID)。
cache stashing请求可以指向比peer cache更低层次的cache级上,比如ICN cache或SystemCache(通过不指定peer cache NodeID)。
对于所有的cache stashing情况,stashing只是性能预示,允许Stash request的接收者不执行任何的stashing行为操作。
Snoop requests and Data Pull
以下的Snoop requests用于通知peer cache是stash request的目标:SnpUniqueStash,SnpMakeInvalidStash,SnpStashShared,SnpStashUnique。表1为每个Stash requests对应的Snoop requests。
表2 Stash request and the correspondingSnoop request

一个Snoopee在收到一笔Stash type request后,可以做的选择有:
- 返回携带Read request的snoop response,携带Read request的snoop response也称作Data Pull。Data Pull只有在snoop response的DoNotDataPull域段没有置位才可以。表2为每个Stash type snoop request的Data Pull响应隐含的Read request类型。
表2 Read request and corresponding Data Pull response

- 返回不使用Data Pull的snoop response,但是分离发送一笔Read request去获得一份cache data。如果使用这种方法,就没有机制将read request与stash操作相关联。无法确定read request是由stash操作直接引起的还是不相关的。
- 返回不使用Data Pull的snoop response,也不跟随下一笔request,即忽略掉cache stash hint。
SnpResp和SnpRespData响应中DataPull的值指示是否使用Data Pull;使用Data Pull完成带Stash的snoop request是可选的,interface的两边都可以控制:
- 如果HN不支持Data Pull transactions流程,那么HN必须在发送snoop request时将DoNotDataPull域段置位;
- 如果Snoopee不支持Data Pull transaction,它要么忽略stash操作,要么发送一笔独立的read request请求。
注意:在snoop response之后使用Data Pull transaction流程可以减少发送额外的Request packet,也可以通过原始stash operation和数据移动到目的cache之间的紧密耦合来提高HN的效率。
1.2 Write with Stash hint
在Stash requester、HN以及Stash target node上发送和处理WriteUniqueFullStash和WriteUniquePtlStash请求遵循如下规则:
Request的约束:
- 发送WriteUniqueFullStash或WriteUniquePtlStash请求取决于是否是full cacheline或者partial cacheline写;
- request请求需要包含一个stash target;
HN的约束:
- 允许发送对WriteUniqueStash发送RetryAck响应,并遵循Retry传输流程;
- 发送SnpUniqueStash来标识Stash target;
- 发送SnpUnique给其它含有该cacheline的Requester;
- 对于WriteUniqueFullStash,允许发送SnpMakeInvalidStash和SnpMakeInvalid来替代SnpUniqueStash和SnpUnique;
- 允许忽略stash hint,将其当做常规的WriteUnique处理;
- 不带stash target处理该request,具体在Stash target not specified小节描述;
- 如果Stash target返回的snoop response带有Data Pull request,但是在HN或其它cache都没有该cacheline的数据,允许HN使用DMT将从SN-F获得数据直接DMT传输给Stash target;
- 如果Stash target返回的snoop response带有Data Pull request,允许HN使用分离的Non-data和Data-only响应;
Stash target的约束:
- 如果snoop request中的DoNotDataPull没有置位,CHI协议建议但不要求snoop response携带Read request请求;
- snoop response响应包含Data Pull有:SnpResp_I_Read,SnpRespData_I_Read,SnpRespData_I_PD_Read,SnpRespDataPtl_I_PD_Read;
- 在以下情况不能使用Data Pull:1. DoNotDataPull置位;2. Snoop有一个地址hazard的outstanding request;
- 当请求Data Pull时:1. Stash target必须保证Read data被接受,和其它任何structural或protocol没有任何的依赖关系,否则可能造成死锁;2. HN认为该读请求是ReadUnique;3. Stash target必须将TxnID给DBID域,这样HN可以用于Read transaction;
- 允许忽略Stash hint,当做SnpUnique处理;
1.3 Independent Stash request
cache stashing的第二种机制允许Stash request和Stash data的写分开。这样的机制在以下的例子中有用:
- 当需要stash的data已经写下去了,但Stash target可能暂时不需要,因此延迟Stash可以变cache的data污染,即占用cache但又没有马上用;
- 当该stash data在System已经存在,并且data已经被预取到cache中;
- 在写stash data时暂时不知道给谁,直到后面才知道;
在这些情况中,Requester可以使用StashOnce requests来请求HN或peer node预取一份cacheline的数据。
Stash requester、HN和Stash target对于发送和处理independent stash request有如下约束:
Requester Node的约束:
- 基于是否要修改stashe cache,可以发送StashOnceUnique或StashOnceShared给HN;
- 当data要被贮存在peer cache中,需要StashOnce request提供一个Stash target;
- 当data需要allocate给下级cache时,StashOnce request不需要提供一个Stash target;
HN的约束:
- 允许对StashOnce request发送RetryAck,且遵循retry流程;
- 对于StashOnceUnique,发送SnpStashUnique;
- 对于StashOnceShared,发送SnpStashShared;
- 对于StashOnce request,允许不发送snoop requ;
- 即使丢弃Stash request,也需要发送Comp响应;
- 当StashOnce request没有指定一个Stash target时,从memory中预取地址对应cacheline的数据到共享的System cache;
- 如果request在HN上命中cacheline,发送Comp_[X],[X]不是I态;只有当[X]状态与Home cache状态匹配时,才允许使用该状态。
- 如果在HN的cache中没有找到或HN没有在回响应之前没有查找cache,应该发送Comp_I;
- 如果从SN-F获得数据给Stash target,允许使用DMT传输data;
- 如果从SN-F获得数据给Stash target,允许使用分离的Non-data和Data-only响应。
Stash target的约束:
- snoop请求不能改变Stash target的cacheline状态;
- snoop对于stash target指示一种指示,去获取一份cacheline状态;
- 如果Snoop request中的DoNotDataPull没有置位CHI协议建议但不要求在snoop response中包含Data Pull请求;
- 在以下情况不能使用Data Pull:DoNotDataPull置位;2. snoop请求和一个正在outstanding request的address hazard;3. 在执行查找本地cache之前,响应就已经发送;4.snoop请求时SnpStashShared,并且cache中已经有该cacheline;
- 当request要求Data Pull:1. Stash target必须保证Read data被接收,不能和其它structural或protocol有任何的依赖关系,不然可能导致死锁;2. 对SnpOnceShared,HN处理DataPull为ReadNotSharedDirty;3. 对于SnpOnceUnique,HN处理DataPull为ReadUnique;4. Stash target将TxnID放到response的DBID域段,对于Read transaction会用于HN;
- 当snoop是SnpStashUnique并且该cacheline状态为Share态,Data Pull request或independent CleanUnique request可以发送,但不是必须的;
- 在发送Snoop response之前,允许但不要求Stash target等到local cache查找完成;
- snoop response的cache state不要求精确:1. 任何非精确的响应必须是SnpResp_I;2. 除了I态,response的其它state必须精确。
注意:对于StashOnceShared或StashOnceUnique transactions,注意要避免任何可能导致期望使用的cacheline从cache中移除;StashOnceUnique transaction会导致cacheline的无效化,并要注意该transaction不会和exclusive access sequences有交互。
1.4 Stash target identifiers
对于所有的Stash requests,支持specified和non-specified Stash target;
Stash target specified
如果Stash target在Stash request中有效,那么HN可以发送带stash hint的snoop request给specified target。specified target可以是RN或RN内的logical processor。
Stash target not specified
如果HN收到没有Stash target的WriteUniquePtlStash或WriteUniqueFullStash request:
- 如果在一个RN中该cacheline是Unique状态,那么HN可以认为该RN是Stash target;
- 如果cacheline没有Unique态,如果需要的话,HN必须只能发送SnpUnique,且不能发送SnpUniqueStash给任何RN;
- 对于WriteUniquePtlStash,如果cacheline在任何cache都没有,CHI协议建议HN预取并将cacheline数据放置在Systemcache,并允许但不建议执行partial write到主存中;
- 对于WriteUniqueFullStash,如果cacheline不在任何cache中,HN允许allocate cacheline在Systemcache中。
如果HN收到没有Stash target的StashOnceUnique或StashOnceShared request:
- 如果在任何peer cache中都没有该cacheline数据,CHI协议建议将该cacheline放置于共享的Systemcache中;
- 如果在peer cache中存在该cacheline,如果发送snoop来传输cacheline的数据并将其分配到Systemcache中是由具体实现决定的。对于StashOnceUnique,在分配给Systemcache之前,如果所有的cacheline数据都无效,也是由具体实现决定的。
1.5 Stash messages
Stash messages可以按如下分类:
- Write requests:WriteUniqueFullStash、WriteUniquePtlStash;
- Dataless requests:StashOnceUnique、StashOnceShared;
- Snoop requests:SnpUniqueStash、SnpMakeInvalidStash、SnpStashUnique、SnpStashShared;
Supporting REQ packet fields
为了支持Stash requests,在REQ packet定义的域段有:
- StashNID,StashLPID;
- StashNIDValid、StashLPIDValid;
Supporting SNP packet fields
为了支持Stash requests,在SNP packet定义的域段有:
- StashLPID;
- StashLPIDValid;
- DoNotDataPull;
Supporting RSP packet fields
为了支持Stash request,在RSP packet定义的域段有:
- DataPull;
Supporting DAT packet fields
为了支持Stash request,在DAT packet定义的域段有:
- DataPull;
二、DVM Operations
本文描述CHI协议中用于管理virtual memory的DVM(Distributed Virtual Memory) operations,包含如下小节。
2.1 DVM transaction flow
所有的DVM transactions都有相似的流程,本小结讲述Non-sync和Sync类型DVM transaction的需求。
2.1.1 Non-sync type DVM transaction flow
图1为Non-sync类型DVM transaction的流程步骤。
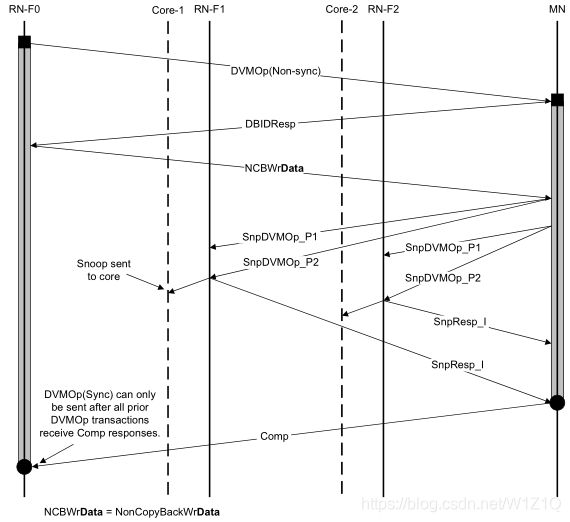
图1 Non-sync type DVM transaction flow
在Non-sync type DVM transactions中,target RN发送SnpResp只是说明已经将SnpDVMOp转发给required RN structures,并且把资源释放掉以备其它DVM operation。但并不意味着requested DVM transaction已经完成;
对于DVMOps,DBIDResp和Comp响应不能合并起来返回。
2.1.2 Sync type DVM transaction flow
图2为Sync类型DVM transaction。

只有之前所有DVMOp request都已经收到Comp响应后,RN才能发送DVMOp(Sync)操作,DVMOp(Sync)操作才能保证之前所有DVMOp操作的真正完成。因为DVMOp sync的SnpResp只有在core内完成所有DVM相关operations之后才能返回的。另外,返回SnpResp意味着RN已经释放资源,有能力接收其它SnpDVMOp。
2.1.3 Flow control
DVMOp request flow control:
- DVMOp可以接收到来自MN的RetryAck响应;
- DVMOp如果收到RetryAck,那么它需要等待来自MN的带有合适PCrdType的PCrdGrant响应;
- 只有之前所有DVMOp request都已经收到Comp响应后,RN才能发送DVMOp(Sync)操作,DVMOp(Sync)操作才能保证之前所有DVMOp操作的真正完成。
- ICN必须保证能处理DVMOp(Non-Sync),这意味着MN中必须至少保留一个入口给DVMOp(Non-Sync);
- 允许来自同一个RN的DVMOp(Non-Sync)和DVMOp(Sync)两者操作交叠进行,如果这样的话,DVMOp(Sync)就不保证DVMOp(Non-Sync)的真正完成;
SynDVMOp flow control:
- 每个SnpDVMOp transaction要求两个SnpDVMOp request packets;
- 对于同一个transaction的两个SnpDVMOp request packets的TxnID必须一样;
- 对于同一个transaction的两个SnpDVMOp request packets可以以任何顺序发送和被接收;
- MN可以将多个SnpDVMOp(Non-Sync) transaction outstanding发送;
- MN给一个RN只能发送一个outstanding的SnpDVMOp(Sync);
- 为了防止死锁,RN只有预分配可以接收SnpDVMOp transaction的两笔packets资源后,MN才能发送SnpDVMOp transaction;
- RN在收到一个SnpDVMOp transaction的两笔packets之后,才能返回snoop响应;
- 当RN可以继续接收来自MN的SnpDVMOp操作时,RN必须给SnpDVMOp返回响应;
- 系统中每个RN-F和RN-D需要指定可以同时接收SnpDVMOp transactions的数目;
- 除了接收一个SnpDVMOp(Sync) transaction之外,系统中每个RN-F和RN-D必须有能力至少接收一个SnpDVMOp(Non-Sync) transaction;
- RN可以并行处理的最少SnpDVMOp transactions数目是2,如果RN没有指定的话。
2.1.4 DVMOp field value restrictions
对于DVMOp操作的Request message、Data message、Response message的各个域段值限制可以参看CHI-issueC P257的表8-1;
2.1.5 Field value requirements
对于一笔DVMOp request产生的两笔SnpDVMOp request packets,在以下域段两者必须相等:
- TxnID;
- Opcode;
- SrcID;
- TgtID;
2.2 DVM Operation types
DVM操作有支持如下类型:
- TLB Invalidate;
- Branch Predictor Invalidate;
- Instruction Cache Invalidate:1. Physical address invalidate;2. Virtual address invalidate;
- Synchronization;
2.2.1 DVMOp payload
从RN发送给MN的DVM operation的payload分布在:
- the address field in the DVM request from the RN;
- the lower 8bytes of write data in the NonCopyBackWrData packet;
从MN发给RN的DVM operation的payload分布在两笔SnpDVMOp request packets的address域段。
表3为payload不同域段以及相应的解释。
表3 DVMOp fields and encodings


2.2.2 DVMOp and SnpDVMOp packet
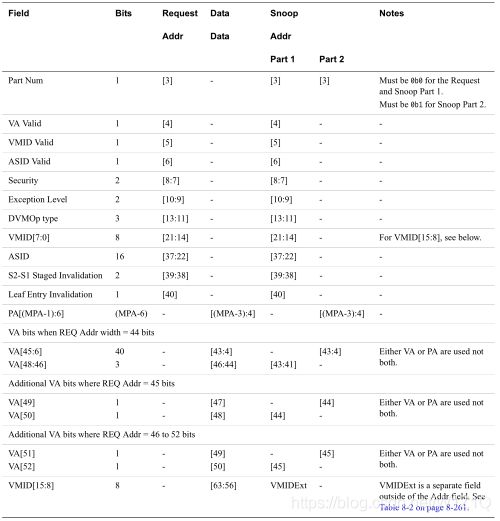
表4为使用8bytes write格式的RN发送的DVMOp request的payload分布,以及MN发送的SnpDVMOp requests的payload的分布。
在DVMop request中,request的address域段和write data的8bytes共同完成完整的request payload,其中request的Addr[3]没有用,且必须设置为0。
在SnpDVMOp中,两笔SnpDVMOp的address域段组成完整的request payload。SnpDVMOp request的Addr[3]指示哪一笔SnpDVMOp正在传输。
Maximum PA(MPA)和Maximum VA(MVA) address的有效组合是:
- MPA = 44 : MVA = 49.
- MPA = 45 : MVA = 51.
- MPA = 46 to 52 : MVA = 53.
表4为Address和Data的数字指示哪些bit被用于DVMOp field。例如Addr[4]是被VA Valid所替代。在Request packet中,该bit会在address域段的第五bit,但是在snoop packet中,该bit会在address的第二bit,因为snoop packet没有包含地址的低3bits;
同样的,write data packet的Data[4]被PA[6]所替代,在snoop packet中,Addr[4]同样也被占用了。对于两个snoop packets,PA[6]是在第二个packet中,但是VA Valid是在第一个packet中。
表4 DVMOp and SnpDVMOp request payloads using a 49-bit VA and 44-bit PA
2.3 DVM Operations
本节描述CHI支持的DVM operations。
表5为DVM operations的Part Num域段值。
表5 Part Num field values

2.3.1 TLB Invalidate
TLB Invalidate operations的各个具体含义值参考CHI issue-C P265的表8-5。
2.3.2 Branch Predictor Invalidate
Branch Predictor Invalidate的各个具体含义值参考CHI issue-C P267的表8-6。
2.3.3 Physical Instruction Cache Invalidate
Physical Instruction Cache Invalidate的各个具体含义值参考CHI issue-C P268的表8-9。
2.3.4 Virtual Instruction Cache Invalidate
Virtual Instruction Cache Invalidate的各个具体含义值参考CHI issue-C P269的表8-11。
2.3.5 Synchronization
Synchronization的各个具体含义值参考CHI issue-C P270的表8-12。