鸿蒙舆情监测系统源码分析——功能架构
在前面几篇文章中,我们介绍了舆情监测系统的基本概念以及基本使用方法,接下来我们以鸿蒙舆情系统为例,从源码角度分析舆情监测系统的功能架构。
舆情监测系统的输入、处理和输出
输入
与一般的企业软件不同,舆情监测系统的数据全部来自互联网,经过对各式各样的数据进行清洗、加工、分析、存储,从而为客户提供有使用价值的数据。
因此,舆情监测系统的输入是互联网数据,包括网站、论坛、博客、微博、贴吧、平媒、视频号、头条等。要想将各种类型的网络平台数据统一接入到系统中来,需要一个强大的数据采集系统(又称爬虫系统)。在遵循互联网数据采集规范的前提下,针对不同的平台类型使用不同的采集方法。
鸿蒙舆情监测系统的采集方法主要有以下几类:
1、通用采集方式:这种方式使用最为简单,只需要指定一个入口URL地址即可发起采集,爬虫系统从入口地址开始逐层搜索,将采集到的数据丢给消息池,直到采集结束。
2、配置采集方式:这种方式在第一种方式的基础上,增加了一些配置工作,目的是将采集的范围更加明确,提高采集的工作效率。
3、脚本采集方式:一些特定的站点无法使用前两种方式完成采集,这时可以编写脚本,从而完成在采集或者解析过程中特定的工作。
4、浏览器插件采集:如果无法通过前面几种方式完成,可以使用浏览器插件采集的方式,通过编写插件脚本,通过系统将插件打包下载安装,按照指定的操作流程即可完成数据采集。
5、APP插件采集:如果数据来源是手机APP,那么可以使用APP插件采集完成数据收集工作。
以上,是鸿蒙舆情监测系统的典型数据采集方式介绍。
处理
通过数据采集阶段获得的数据,只是原始数据,这些数据没有经过筛选和加工,很难为我们使用。因此,接下来一个重要的工作,就是将采集到的原始数据进行加工处理。这一过程我们通过一张图来呈现:

在上面的流程图里,我们可以看到原始网页时如何变成结构化数据的。
网页结构化完成以后,需要对数据进行初步的分析,具体流程如下:
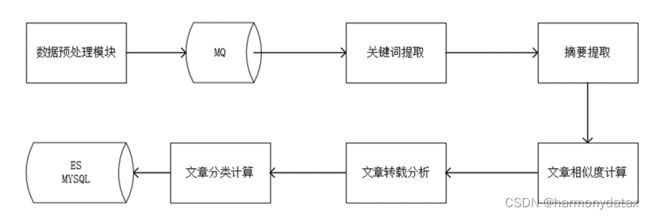
在数据分析的流程里,鸿蒙舆情系统实现了链式分析流程,即可以根据不同的数据选择需要的分析过程,形成最终的数据。比如有些用户关注的是某些事件的转发轨迹,那么分析流程就需要包含转载分析;而有些客户则关注网民态度,那么就需要引入观点分析过程。
另外,针对日益成熟的AI分析,也可以在这一阶段进行引入。
输出
在经过数据采集和处理之后,需要将结构化的数据保存起来,以便后续可以随时取用。舆情系统的数据量和采集能力相关,一般配置了2台采集器的舆情软件,每天的数据量在50万上下,一个月就达到1500万,一年的累计数量超过1亿条。因此需要对舆情数据存储进行设计。首先我们使用文档索引系统ElasticSearch(简称ES)作为舆情数据的存储容器。ES的特点是检索速度快,支持多种查询方式,存储空间可动态扩充,集群节点可动态扩容。其次,如果将所有数据放在ES的一个文档里,无法充分体现ES的优势,因此可以将数据按时间或者类型进行分别存储,特定时间的数据或者特定类型的数据定向查询,这样可以大大提升查询效率。
舆情监测系统的功能架构
上一节重点介绍了舆情系统的数据来源、处理和存储。有了这些数据以后,通过舆情监测系统的门户网站,可以对这些数据进行各种聚合展示,生成相应的报告。
下面的图是舆情监测系统的总体功能架构图,通过这张图,可以全面了解一个舆情监测系统的主要模块与能力。

总体而言,一个舆情系统需要包含以下模块:
1、数据管理模块:用来管理采集源、采集能力、监测采集进度
2、数据采集模块:分布式爬虫,采集互联网各种类型数据
3、数据分析模块:对采集到的数据进行分析处理存储
4、系统配置模块:包括组织机构,角色权限人员等,以及企业相关的参数配置
5、系统展示门户:实现舆情信息的检索、聚合、生成报告、大屏展示等
6、其他辅助模块:包括预警推送(微信消息、邮件提醒)、外部接口对接等
以上,我们从源码层级对鸿蒙舆情监测系统进行了功能架构分析,简述了舆情系统的典型流程,希望能给相关人员提供参考与帮助。