LDA主题建模过程及参数详解
平台及工具
语言:python
平台:anaconda+jupyter notebook
语料库:近三百篇英文文献的摘要
主要代码
首先,# pandas处理csv数据
import pandas as pd
df = pd.read_csv("abs_all.csv",error_bad_lines=False,encoding='gb18030')
df.head()
输出:

文本预处理
def lemmatize_stemming (text):
# 词形归并
wordnet_lematizer = WordNetLemmatizer()
word = wordnet_lematizer.lemmatize(text)
return word
def preprocess(text):
result = []
for token in gensim.utils.simple_preprocess (text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len (token) > 2:
result.append (lemmatize_stemming (token) )
return result
#关键词提取和文本向量化包
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2,
max_features=1500,
stop_words='english')
tf = tf_vectorizer.fit_transform(result)
#导入LDA软件包 狄利克雷分布
from sklearn.decomposition import LatentDirichletAllocation
#设置主题数量为20
n_topics = 20
lda = LatentDirichletAllocation(n_components=n_topics,# 文章表示成20维的向量
max_iter=50,#EM算法的最大迭代次数。
learning_method='online',
learning_offset=50.0,
random_state=0)
lda.fit(tf)
#输出每个主题中前20个关键词
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()
#可视化分析
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
可视化结果示意:
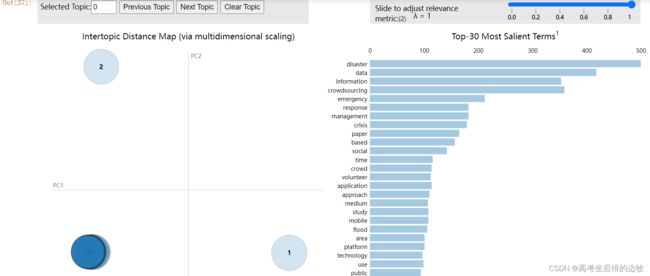
主要参数解读
可以调整的参数:
n_topics: 主题的个数,即隐含主题数K,需要调参。K的大小取决于我们对主题划分的需求,比如我们只需要类似区分是动物,植物,还是非生物这样的粗粒度需求,那么K值可以取的很小,个位数即可。如果我们的目标是类似区分不同的动物以及不同的植物,不同的非生物这样的细粒度需求,则K值需要取的很大,比如上千上万,此时要求我们的训练文档数量要非常的多。
n_features: feature的个数,即常用词个数
doc_topic_prior:即文档主题先验Dirichlet分布θd的参数α,一般如果没有主题分布的先验知识,可以使用默认值1/K。
topic_word_prior:即主题词先验Dirichlet分布βk的参数η,一般如果没有主题分布的先验知识,可以使用默认值1/K。
learning_method: 即LDA的求解算法,有’batch’和’online’两种选择.batch’即变分推断EM算法,而”online”即在线变分推断EM算法,在”batch”的基础上引入了分步训练,将训练样本分批,逐步一批批的用样本更新主题词分布的算法。默认是”online”,选择了‘online’则我们可以在训练时使用partial_fit函数分布训练。不过在scikit-learn 0.20版本中默认算法会改回到”batch”。建议样本量不大只是用来学习的话用”batch”比较好,这样可以少很多参数要调。而样本太多太大的话,”online”则是首选。
learning_decay:仅仅在算法使用”online”时有意义,取值最好在(0.5, 1.0],以保证”online”算法渐进的收敛。主要控制”online”算法的学习率,默认是0.7。一般不用修改这个参数。
learning_offset:仅仅在算法使用”online”时有意义,取值要大于1。用来减小前面训练样本批次对最终模型的影响。
max_iter :EM算法的最大迭代次数。
total_samples:仅仅在算法使用”online”时有意义, 即分步训练时每一批文档样本的数量。在使用partial_fit函数时需要。
batch_size: 仅仅在算法使用”online”时有意义, 即每次EM算法迭代时使用的文档样本的数量
方法:
1)fit(X[, y]):利用训练数据训练模型,输入的X为文本词频统计矩阵。
2)fit_transform(X[, y]):利用训练数据训练模型,并返回训练数据的主题分布。
3)get_params([deep]):获取参数
4)partial_fit(X[, y]):利用小batch数据进行Online方式的模型训练。
5)perplexity(X[, doc_topic_distr, sub_sampling]):计算X数据的approximate perplexity。
6)score(X[, y]):计算approximate log-likelihood。
7)set_params(**params):设置参数。
8)transform(X):利用已有模型得到语料X中每篇文档的主题分布
参考并致谢:
https://www.cnblogs.com/MaggieForest/p/12457093.html