如何阅读项目代码
阅读源代码的能力算是程序员的一种底层基础能力之一,这个能力之所以重要,原因在于:
不可避免的需要阅读或者接手他人的项目。比如调研一个开源项目,比如接手一个其他人的项目。
阅读优秀的项目源码是学习他人优秀经验的重要途径之一,这一点我自己深有体会。
读代码与写代码是两个不太一样的技能,原因在于“写代码是在表达自己,读代码是在理解别人”。因为面对的项目多,项目的作者有各自的风格,理解起来需要花费不少的精力。
1.先跑起来
开始阅读一份项目源码的第一步,是先让这个项目能够通过你自己编译通过并且顺利跑起来。这一点尤其重要。
有的项目比较复杂,依赖的组件多,搭建起一个调试环境并不容易,所以并不见得是所有项目都能顺利的跑起来。如果能自己编译跑起来,那么后面讲到的情景分析、加上调试代码、调试等等才有展开的基础。
就我的经验而言,一个项目代码,是否能顺利的搭建调试环境,效率大不一样。
跑起来之后,又要尽量的精简自己的环境,减少调试过程中的干扰信息。比如,Nginx使用多进程的方式处理请求,为了调试跟踪Nginx的行为,我经常把worker数量设置为1个,这样调试的时候就知道待跟踪的是哪个进程了。
再比如,很多项目默认是会带上编译优化选项或者去掉调试信息的,这样在调试的时候可能会有困扰,这时候我会修改makefile编译成-O0 -g,即编译生成带上调试信息且不进行优化的版本。
总而言之,跑起来之后的调试效率能提升很多,而在跑起来的前提之下又要尽量精简环境排除干扰的因素。
2.明确自己的目的
尽管阅读项目源码很重要,但是并不见得所有项目都需要从头到尾看的清清楚楚。在开始展开阅读之前,需要明确自己的目的:是需要了解其中一个模块的实现,还是需要了解这个框架的大体结构,还是需要具体熟悉其中的一个算法的实现,等等。
比如,很多人看Nginx的代码,而这个项目有很多模块,包括基础的核心模块(epoll、网络收发、内存池等)和扩展具体某个功能的模块,并不是所有这些模块都需要了解的非常清楚,我在阅读Nginx代码的过程中,主要涉及了以下方面:
了解Nginx核心的基础流程以及数据结构。
了解Nginx如何实现一个模块。
有了这些对这个项目大体的了解,剩下的就是遇到具体的问题查看具体的代码实现了。
总而言之,并不建议毫无目的的就开始展开一个项目的代码阅读,无头苍蝇式的乱看只会消耗自己的时间和热情。
3. 区分主线和支线剧情
有了前面明确的阅读目的,就能在阅读过程中区分开主线和支线剧情了。比如:
想了解一个业务逻辑的实现流程,在某个函数中使用一个字典来保存数据,在这里,“字典这个数据结构是如何实现的”就属于支线剧情,并不需要深究其实现。
在这一原则的指导下,对于支线剧情的代码,比如一个不需要了解其实现的类,读者只需要了解其对外接口,了解这些接口的入口、出口参数以及作用,把这部分当成一个“黑盒”即可。
顺便一提的是,早年间看到一种C++的写法,头文件中只有一个类的对外接口声明,将实现通过内部的impl类转移到C++文件中,比如:
头文件:
// test.h
class Test {
public:
void fun();
private:
class Impl;
Impl *impl_;
};
C++文件:
void Test::fun() {
impl_->fun()
}
class Test::Impl {
public:
void fun() {
// 具体的实现
}
}
这样的写法,让头文件清爽了很多:头文件中没有与实现相关的私有成员、私有函数,只有对外暴露的接口,使用者一目了然就能知道这个类对外提供的功能。
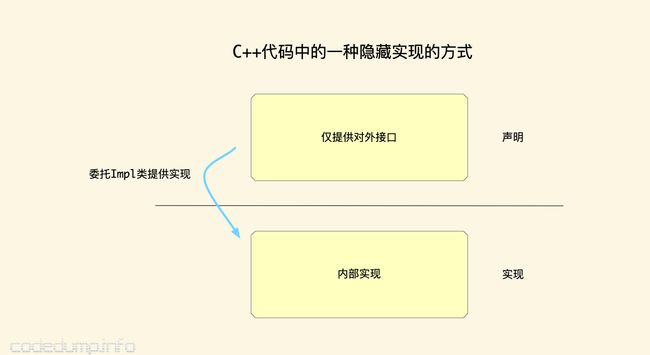
“主线”和“支线”剧情在整个代码阅读的过程中经常切换,需要阅读者有一定的经验,清楚自己在这段代码的阅读中哪部分属于主线剧情。
4. 纵向和横向
代码阅读过程中,分为两个不同的方向:
纵向:顺着代码的顺序阅读,在需要具体了解一个流程、算法的时候,经常需要纵向阅读。
横向:区分不同的模块进行阅读,在需要首先弄清楚整体框架时,经常需要横向阅读。
两个方向的阅读,应该交替进行,这需要代码阅读者有一定的经验,能够把握当前代码阅读的方向。我的建议是:过程中还是以整体为首,在不理解整体的前提之前,不要太过深入某个细节。把某个函数、数据结构当成一个黑盒,知道它们的输入、输出就好,只要不影响整体的理解就暂且放下接着往前看。
5. 情景分析
假如有了前面的基础,已经能够让项目顺利在自己的调试环境跑起来了,也明确了自己想了解的功能,那么就可以对项目代码进行情景分析了。
所谓的“情景分析”,就是自己构造一些情景,然后通过加断点、调试语句等分析在这些场景下的行为。
以我自己为例,在写《Lua设计与实现》时,讲解到Lua虚拟机指令的解释和执行过程中,需要针对每个指令做分析,此时用的就是情景分析的方法。我会模拟出来使用该指令的Lua脚本代码,然后在程序里断点调试这些场景下的行为。
我惯用的做法,是在某个重要的入口函数上面加上断点,然后构造触发场景的调试代码,当代码在断点处停下,通过查看堆栈、变量值等等来观察代码的行为。
例如,Lua解释器代码中中,生成Opcode最终都会调用函数luaK_code,那么我就在这个函数上面加上断点,然后构造我想要调试的场景,只要在断点处中断,我通过函数堆栈就能看到完整的调用流程:
(lldb) bt
* thread #1: tid = 0xb1dd2, 0x00000001000071b0 lua`luaK_code, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
* frame #0: 0x00000001000071b0 lua`luaK_code
frame #1: 0x000000010000753e lua`discharge2reg + 238
frame #2: 0x000000010000588f lua`exp2reg + 31
frame #3: 0x000000010000f15b lua`statement + 3131
frame #4: 0x000000010000e0b6 lua`luaY_parser + 182
frame #5: 0x0000000100009de9 lua`f_parser + 89
frame #6: 0x0000000100008ba5 lua`luaD_rawrunprotected + 85
frame #7: 0x0000000100009bf4 lua`luaD_pcall + 68
frame #8: 0x0000000100009d65 lua`luaD_protectedparser + 69
frame #9: 0x00000001000047e1 lua`lua_load + 65
frame #10: 0x0000000100018071 lua`luaL_loadfile + 433
frame #11: 0x0000000100000eb9 lua`pmain + 1545
frame #12: 0x00000001000090cd lua`luaD_precall + 589
frame #13: 0x00000001000098c1 lua`luaD_call + 81
frame #14: 0x0000000100008ba5 lua`luaD_rawrunprotected + 85
frame #15: 0x0000000100009bf4 lua`luaD_pcall + 68
frame #16: 0x00000001000046fb lua`lua_cpcall + 43
frame #17: 0x00000001000007af lua`main + 63
frame #18: 0x00007fff6468708d libdyld.dylib`start + 1
情景分析的好处在于:不会在一个项目中大海捞针似的查找,而是能够把问题缩小到一个范围内展开来理解。
“情景分析”这一概念不是我想出来的名词,比如有这么几本分析代码的书籍,如:《Linux内核源代码情景分析》,《Windows内核情景分析》。
6. 利用好测试用例
好的项目都会自带不少用例,这类型的例子有:etcd、google出品的几个开源项目。
如果测试用例写的很仔细,那么很值得好好去研究一下。原因在于:测试用例往往是针对某个单一的场景,独自构造出一些数据来对程序的流程进行验证。所以,其实跟前面的“情景分析”一样,都是让你从大的项目转而关注具体某个场景的手段之一。
7. 厘清核心数据结构之间的关系
虽然说“程序设计=算法+数据结构”,然后我实际中的体会,数据结构更加重要。
因为结构定义了一个程序的架构,结构定下来了才有具体的实现。好比盖房子,数据结构就是房子的框架结构,如果一间房子很大,而你并不清楚这个房子的结构,会在这里面迷路。而对于算法,如果属于暂时不需要深究的细节部分,可以参考前面“区分主线和支线剧情”部分,先了解其入口、出口参数以及作用即可。
Linus说: “烂程序员关心的是代码。好程序员关心的是数据结构和它们之间的关系。”
因此,在阅读一份代码时,厘清核心的数据结构之间的关系尤其重要。这个时候,需要使用一些工具来画一下这些结构之间的关系,我的源码分析类博客中有很多这样的例子,比如《Leveldb代码阅读笔记》、《Etcd存储的实现》等等。
需要说明的是,情景分析、厘清核心数据结构这两步并没有严格的顺序关系,不见得是先做某事再做某事,而是交互进行的。
比如,你如果现在刚接手某个项目,需要简单的了解一下项目,可以先阅读代码了解都有哪些核心数据结构。理解了之后,如果不清楚某些情景下的流程,可以使用情景分析法。总而言之,交替进行直到解答你的疑问为止。
8. 多问自己几个问题
学习的过程中离不开交互。
如果阅读代码只是输入(Input),那么还需要有输出(Output)。只有简单的输入好比喂东西给你吃,而只有更好的消化才能变为自己的营养,而输出就是更好消化知识的重要手段。
其实这个思想很常见,比如学生上课(Input)了需要做练习作业(Output),比如学了算法(Input)需要自己编码练习(Output),等等。简而言之,输出是学习过程中的一种及时反馈,质量越高学习效率越高。
输出的手段有很多,在阅读代码时,比较建议的是自己能够多问自己一些问题,比如:
为什么选择这个数据结构来描述这个问题?类似的场景下,其他项目是怎么设计的?都有哪些数据结构做这样的事情?
如果由我来设计这样的项目,我会怎么做?
等等等等。越是主动积极的思考,就越有更好的输出,输出质量与学习质量成正比关系。
9. 写自己的代码阅读笔记
我从开始写博客,就是写不少各种项目的代码解读类文章,网名“codedump”也源于想把“code内部的实现原理dump出来”之意。
前面提到学习质量与输出质量成正比关系,这是我自己的深刻体会。也因为如此,所以才要坚持阅读源码之后写自己的分析类笔记。
写这类笔记,有以下几个需要注意的地方。
虽然是笔记,但是要想象着在向一个不太熟悉这个项目的人讲解原理,或者想象一下是几个月甚至几年后的自己回头来看这个文章。在这种情况下,会尽量的把语言组织好,循循善诱的解释。
尽量避免大段的贴代码。我认为在这类文章中,大段贴上代码有点自欺欺人:就是看上去自己懂了,其实并不见得。如果真要解释某段代码,可以使用伪代码或者缩减代码的方式。记住:不要自欺欺人,要真的懂了。如果真的想在代码上加上自己的注释,我有一个建议是fork出来一份该项目某个版本的代码,提交到自己的github上,上面随时可以加上自己的注释并且保存提交。比如我自己注释的etcd 3.1.10代码:etcd-3.1.10-codedump,类似的我阅读的其他项目都会在github上fork出一个带上codedump后缀的项目。
多画图,一图胜千言,使用图形展示代码流程、数据结构之间的关系。我最近才发现画图能力也是很重要的能力,自己在从头学习如何使用图像来表达自己的想法。
写作是很重要的基础能力,我一个朋友最近教育我,大体的意思是说:如果你在某方面的能力很强,如果再加上写作好、英语好,那么将极大放大你在这方面的能力。而类似写作、英语这样的底层基础能力,不是一撮而就的,需要长时间保持练习才可以。而写博客,对于技术人员而言,就是一种很好的锻炼写作的手段。
PS:如果很多事情,你当时做的时候能想到今后面对这个输出的人是你自己,比如自己写的代码后面要自己维护、自己写的文章后面给自己看,等等的,世界会美好很多。
比如写技术博客这些事情,因为我在写的时候考虑到以后看这份文档的人可能就是我本人,所以在写的时候会尽量的清晰、易懂,力图我自己一段时间后再看到自己的这份文档时,能够马上回忆起当时的细节,也正是因为这样,我很少在博客里贴大段的代码,尽可能的补充图例。
10. 总结
以上是我简单总结的一些阅读源码时候的手段和注意方法,大体而言有那么几点吧:
只有更好的输出才能更好的消化知识,所谓的搭建调试环境、情景分析、多问自己问题、写代码阅读笔记等都是围绕输出来展开的。总而言之,不能像一条死鱼一样指望着光靠看代码就能完全理解它的原理,需要想办法跟它互动起来。
写作是人的基础硬实力之一,不仅锻炼自己表达能力,还能帮助整理自己的思路。对程序员而言锻炼写作能力的手段之一就是写博客,越早开始锻炼越好。
最后,如同任何可以习得的技能一般,阅读代码这种能力也需要长时间、大量的反复练习,下一次就从自己感兴趣的项目开始锻炼自己的这种技能吧。