GPU进入数据中心约有8~10年,这些年内 GPU显存的容量、GPU P2P带宽、GPU性能都在不断提升。据不完全统计, 每年GPU显存大约有一倍的变化, P2P带宽有1.5倍到2倍的变化,而且性能变化更多。
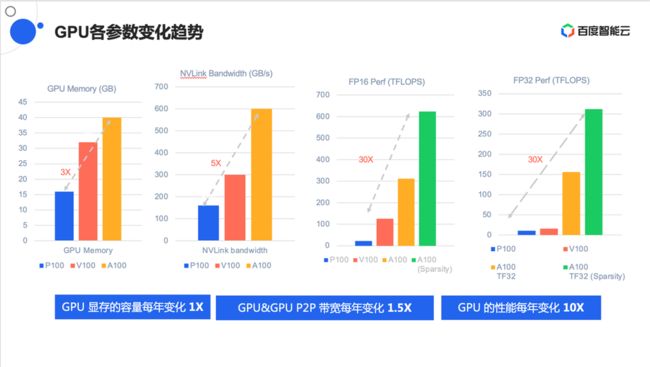
由于性能的变化,会引起GPU功耗的变化, GPU功耗变化从最早的40瓦一直到现在的400瓦、500瓦,以及到未来的700瓦等等,这种变化会引起算力提升。
由于业务模型的需求,算力的提升推动了硬件在整个性能方面的不断迭代。模型的变化大约在3~4个月会有一次迭代更新,每年大约有3~4次的迭代,而近几年硬件的变化速度明显低于模型的变化,这对整个硬件系统在设计过程中带来了极大挑战,主要表现在以下5方面:
1、算力挑战,主要表现在GPU的算力方面和整个系统的算力;
2、存储挑战,主要是GPU和存储之间通信的带宽和通信速度的挑战;
3、通信挑战,主要是GPU和GPU之间或者计算节点和计算机节之间的挑战;
4、散热挑战,GPU 功耗增加散热的挑战越来越明显;
5、供电挑战,最早是12V的供电,近几年逐渐发展到54V供电,目的是为了解决大功率密度GPU在供电过程中的高功耗问题。
X-MAN 4.0的设计恰好解决了上面提到的几个痛点。算力问题上,因为整个设计是一个硬件解耦的设计,采用了GPU资源池化的解决方案,同时是一个模块化的设计,兼容了OAI和OAM;由于 X-MAN 4.0设计有一个灵活的、拓扑的I/O,能够支持I/O扩展和多网卡的性能;在整体散热上,采用了风冷兼容液冷的设计,能够很好的发挥GPU的性能;供电上,采用了54V供电,相较于12V供电,系统更加稳定可靠,而且适合于大功率密度的GPU应用场景。

在整个硬件架构设计方面,采用了融合架构,即AI和HPC架构融合,整机柜和标准机架构融合,同时把存储靠近GPU,实现GPU和存储之间访问时延最短;
硬件解耦是GPU和计算节点完全分离,而且可以灵活支持不同的CPU,比如Intel 平台、ARM平台、AMD平台等;还有灵活分布的I/O,而且I/O可以扩展;GPU和网卡之间的配比关系可以实现1:1;在整个散热的过程中,有风冷和液冷共存;
另外,支持资源池化和模块化的设计。X-MAN 4.0在相同硬件配置下,它的MLperf结果在全球名列第二。
因为X-MAN 4.0具有I/O灵活的扩展性,所以对于超大规模集群来说,它有一个很好的组网能力。因为在整个集群的组网过程中,采用了200G的IB网络,实现了上行网络和下行网络的1:1的带宽。在整个的集群设计过程中,采用了Ethernet和IB共存的模式,实现了存储和GPU之间高带宽通信,实现了GPU和存储的池化。

除X-MAN 4.0之外,也看到了一些其他的产品,比如X-MAN 1.0、X-MAN 2.0、X-MAN 3.0,还有正在开发的X-MAN 5.0。对于每一代产品都有不同的产品形态和架构设计, X-MAN 1.0采用的是一个16卡的PCIe卡架构,这种架构设计当时是为了解决多机和单机处理不同任务时,可以给一个机器分配多个任务,或者把一个任务分配给多个机器,好处是可以充分利用GPU资源,从而实现 GPU资源的最大利用。
从X-MAN 1.0到X-MAN 2.0,实现了 GPU P2P带宽的提升,从PCIe 3.0提升到NVLink 2.0,而且在X-MAN 2.0时,具有灵活I/O雏形。
在X-MAN 2.0到X-MAN 3.0之后,整个网络实现了100G RDMA的通信,同时整个架构上的设计,可以支持单机内的大模型,从而在GPU和GPU之间通信采用了NVLink 3.0技术。
从X-MAN 3.0到X-MAN 4.0,整个架构发生了一些变化,即有了更丰富的I/O,能够支持更多的网卡,而且能够实现节点和节点之间的高速互联和灵活组网,支持100G网络和200G网络以及更高的一些网络。
X-MAN还能够结合4路CPU的计算节点,解决一些行业内应用的问题。
从整个架构上来看,
>> X-MAN是硬件的解耦,而且能够灵活匹配不同的硬件平台,比如Intel平台,AMD平台,ARM平台。
>> 另外,在整个设计过程中,采用资源池化的设计思路,即可以把一个机箱里的GPU看做一个资源池,按照业务需求去分配。
>> 同时,机内的网络能够支持Fabric任务架构,动态的对GPU资源进行分配。
在整个设计过程中,是模块化设计,可以把整个架构分为4个模块:网络交换模块, GPU模块,存储模块和供电模块,以及计算模块。整个网络模块从X-MAN1.0、X-MAN2.0、X-MAN3.0、X-MAN4.0发生了重大的变化,而且整个时延在不断减小,网络带宽在逐渐提升。
X-MAN架构还引领了 OAI和OAM标准,因为它有一个丰富的I/O,能够实现灵活扩展,而且适合于匹配不同的计算节点,或适合于组成不同的网络和集群。
同时 ,X-MAN在新技术方面,也在不断的探索和尝试,比如散热方面,从最早的风冷逐渐过渡到冷背技术,而冷背技术在X-MAN 2.0上已经大规模的应用,在数据中心已经应用了长达2~3年,而且非常的稳定。随着GPU功耗和性能的不断提升,在未来的某个时刻内,会发现冷背的散热技术已经满足不了GPU的需求,所以会采取浸没的散热方式彻底解决GPU散热问题,提高GPU的性能。
未来随着模型的发展,可以看到芯片的设计越来越大,而且需求的带宽和时延越来越低,这样可能会形成一个芯片在未来代表一个集群,这种设计的好处是时延低、带宽大。但对于系统设计来说,散热是一个挑战。另外,还需要有一些非常高速的带宽网络满足节点和节点之间的通信需求。
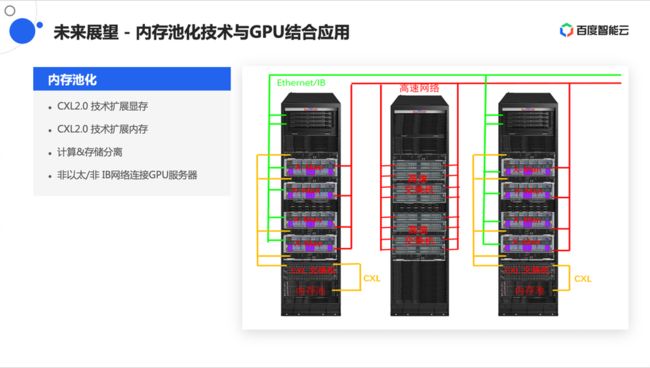
随着网络和网络带宽的不断提升,在整个集群方面,需要有更高的带宽网络来满足GPU和GPU之间通信的需求。同时,由于显存和内存的局限性,未来在显存和内存的扩展方面会有新技术的出现,这样会形成显存和内存的池化技术,来满足业务的需求,从而提升显存和内存的利用率。
随着技术的发展,未来整个系统架构的设计,模块化的融合设计。而对于应用场景来看,需要精准的匹配不同应用,来满足不同应用场景和业务需求。
随着芯片技术的不断发展和整个行业互联技术的发展,从底层的芯片到服务器节点内部,CPU和GPU之间互联技术的带宽比原来越来越高,大约有2~3倍的提升,而时延在不断的降低,节点之间和Rack之间的带宽也越来越高。所以,未来整个通信方面或互联技术方面,需要更高的Ethernet或IB网络支持整个节点和节点之间的通信,或Rack和Rack之间的通信。
随着技术发展,不仅仅有IB网络和以太网,还有其他的网络用于节点或集群之间的通信,可能有另外一种低时延、高利用率的网络出现,来满足像HPC或者AI集群的通讯需求。
产品传送门:https://cloud.baidu.com/solution/ai-heterogeneus-computing-platform.html?=acg-bilibili