大数据系列之Spark SQL、DataFrame和RDD数据统计与可视化
Spark大数据分析中涉及到RDD、Data Frame和SparkSQL的操作,本文简要介绍三种方式在数据统计中的算子使用。
1、在IPython Notebook运行Python Spark程序
IPython Notebook具备交互式界面,可以在Web界面输入Python命令后立刻看到结果,还可将数据分析的过程和运行后的命令与结果存储成笔记本,下次可以打开笔记本,重新执行这些命令,IPython Notebook笔记本可以包含文字、数学公式、程序代码、结果、图形等。
1.1 安装IPython
1)若无gcc,需先安装gcc
[root@tango-spark01 /]# gcc –v
[root@tango-spark01 /]# yum install gcc
2)若无pip,安装pip
[root@tango-spark01 /]# pip –v
[root@tango-spark01 /]# wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate
3)安装Python开发包
[root@tango-spark01 /]# yum install python-devel
4)执行以下命令安装IPython和IPython Notebook:
[root@tango-spark01 /]# pip install ipython
[root@tango-spark01 /]# pip install urllib3
[root@tango-spark01 /]# pip install jupyter
5)输入ipython进入交互界面
6)输入jupyter notebook

1.2 IPython配置
1)创建远程连接密码
In [2]: from notebook.auth import passwd;
In [3]: passwd()
Enter password:
Verify password:
Out[3]: 'sha1:fea9052f4d92:114eb32c684004bf4a6196faac0b26a28156fe5d'
2)生成jupyter配置文件
[root@tango-spark01 /]# jupyter notebook --generate-config
Writing default config to: /root/.jupyter/jupyter_notebook_config.py
3)打开配置文件,设置以下内容
## The IP address the notebook server will listen on.
#c.NotebookApp.ip = 'localhost'
c.NotebookApp.ip = '0.0.0.0'
## The directory to use for notebooks and kernels.
#c.NotebookApp.notebook_dir = u''
c.NotebookApp.notebook_dir = u'/usr/local/spark/ipynotebook'
## Hashed password to use for web authentication.
# To generate, type in a python/IPython shell:
# from notebook.auth import passwd; passwd()
# The string should be of the form type:salt:hashed-password.
#c.NotebookApp.password = u''
c.NotebookApp.password = u'sha1:fea9052f4d92:114eb32c684004bf4a6196faac0b26a28156fe5d'
4)打开jupyter notebook
[root@tango-spark01 /]# jupyter notebook --allow-root
[I 14:20:05.618 NotebookApp] Serving notebooks from local directory: /usr/local/spark/ipynotebook
[I 14:20:05.618 NotebookApp] The Jupyter Notebook is running at:
[I 14:20:05.619 NotebookApp] http://(tango-spark01 or 127.0.0.1):8888/
[I 14:20:05.619 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[W 14:20:05.619 NotebookApp] No web browser found: could not locate runnable browser.
[I 14:21:00.346 NotebookApp] 302 GET / (192.168.112.1) 2.50ms
[I 14:21:00.352 NotebookApp] 302 GET /tree? (192.168.112.1) 1.71ms
[I 14:22:16.241 NotebookApp] 302 POST /login?next=%2Ftree%3F (192.168.112.1) 1.58ms
5)浏览器输入地址和端口

输入密码登录进去
1.3 在IPython Notebook中使用Spark
1)进入ipynotebook工作目录
[root@tango-spark01 /]# cd /usr/local/spark/ipynotebook
[root@tango-spark01 ipynotebook]#
2)在IPython Notebook界面中运行pyspark
[root@tango-spark01 ipynotebook]# PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS="notebook" pyspark
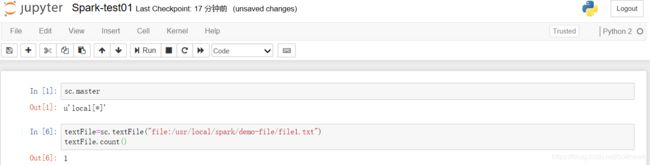
3)单击New选择Python 2,新建Notebook

4)新建Notebook后会出现新的页面,默认notebook名称为Untitled,单击后修改名称
5)在Notebook运行程序代码
6)保存Notebook下次可继续打开使用
2、Spark SQL、DataFrame、RDD数据统计与可视化
2.1 RDD、DataFrame和Spark SQL比较
RDD和Data Frame都是Spark平台下分布式弹性数据集,都有惰性机制,在进行创建、转换时不会立即执行,等到Action时才会遍历运算。
- RDD API进行数据统计,主要使用map配合reduceByKey,需要有Map/Reduce概念
- 与RDD不同的是Data Frame更像是传统的数据库表格,除了数据以外,还记录了数据的结构信息
- Spark SQL则是由DataFrame派生出来,必须先创建DataFrame,然后通过登录Spark SQL temp table就可以使用Spark SQL语句,直接使用SQL语句进行查询
下表列出在进行数据统计计算时候,RDD、Data Frame和Spark SQL使用的不同方法。
| Items | 功能描述 |
|---|---|
| RDD API | userRDD.map(lambda x:(x[2],1)).reduceByKey(lambda x,y: x+y).collect() |
| DataFrame | user_df.select(“gender”).groupby(“gender”).count().show() |
| Spark SQL | sqlContext.sql(“””SELECT gender,count(*) counts FROM user_table GROUP BY gender”””).show() |
2.2 创建RDD、DataFrame和Spark SQL
在Hadoop YARN-client模式运行IPython Notebook
[root@tango-spark01 ipynotebook]# PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS="notebook" HADOOP_CONF_DIR=/usr/local/spark/hadoop-2.9.0/etc/hadoop pyspark --master yarn --deploy-mode client
- 创建RDD
1)配置文件读取路径
global Path
if sc.master[0:5] =="local":
Path="file:/usr/local/spark/ipynotebook/"
else:
Path="hdfs://tango-spark01:9000/input/"
- 如果sc.master[0:5]是“local”,代表当前在本地运行,读取本地文件
- 如果sc.master[0:5]不是“local”,有可能是YARN client或Spark Stand Alone,必须读取HDFS文件
2)读取文本文件并且查看数据项数
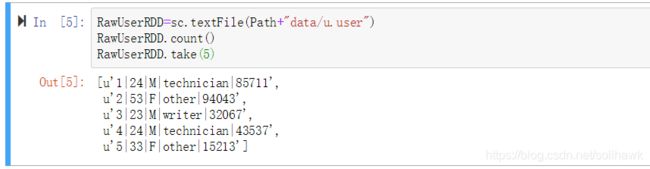
RawUserRDD=sc.textFile(Path+"data/u.user")
RawUserRDD.count()
RawUserRDD.take(5)
3)获取每一个字段
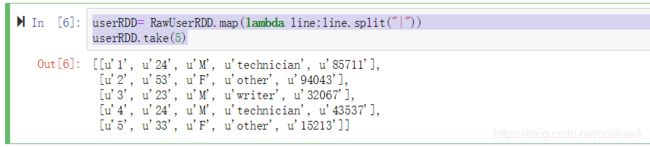
userRDD= RawUserRDD.map(lambda line:line.split("|"))
userRDD.take(5)
- 创建Data Frame
1)创建sqlContext:在Spark早期版本中,spark context是Spark的入口、SQLContext是SQL入口、HiveContext是hive入口。在Spark 2.0中,使用Spark Session可同时具备spark context、sqlContext、HiveContext功能
sqlContext=SparkSession.builder.getOrCreate()
2)定义Schema:定义DataFrames的每个字段名与数据类型
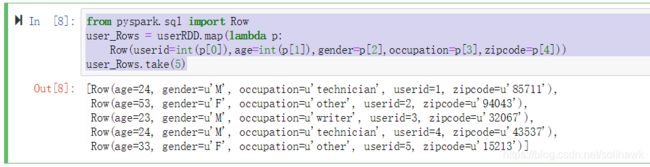
from pyspark.sql import Row
user_Rows = userRDD.map(lambda p:
Row(userid=int(p[0]),age=int(p[1]),gender=p[2],occupation=p[3],zipcode=p[4]))
user_Rows.take(5)
3)创建DataFrames:使用sqlContext.createDataFrame()方法创建DataFrame
user_df=sqlContext.createDataFrame(user_Rows)
user_df.printSchema()
4)查看DataFrames数据
user_df.show(5)
5)为DataFrame创建别名:可以使用.alias帮DataFrame创建别名
df=user_df.alias("df")
df.show(5)

- 使用SparkSQL
创建DataFrame后,使用该DataFrame登录Spark SQL temp table,登录后可以使用Spark SQL
1)登录临时表
user_df.registerTempTable("user_table")
2)使用Spark SQL查看项数
sqlContext.sql("SELECT count(*) counts FROM user_table").show()
3)多行输入Spark SQL语句,需要使用3个双引号引住SQL
sqlContext.sql("""
SELECT count(*) counts
FROM user_table
""").show()
4)使用SparkSQL查看数据,限定数据项
sqlContext.sql("SELECT * FROM user_table").show()
sqlContext.sql("SELECT * FROM user_table").show(5)
sqlContext.sql("SELECT * FROM user_table LIMIT 5").show()

2.3 数据统计操作
2.3.1 筛选数据
- 使用RDD筛选数据
RDD中使用filter方法筛选每一项数据,配合lambda语句创建匿名函数传入参数
userRDD.filter(lambda r:r[3]=='technician' and r[2]=='M' and r[1]=='24').take(5)
- 输入DataFrames筛选数据
user_df.filter((df.occupation=='technician')&(df.gender=='M')&(df.age==24)).show()
- 使用Spark SQL筛选数据
sqlContext.sql("""
SELECT *
FROM user_table
where occupation='technician' and gender='M' and age=24""").show(5)
2.3.2 按字段给数据排序
- RDD按字段给数据排序
userRDD.takeOrdered(5,key=lambda x:int(x[1]))——升序排序
userRDD.takeOrdered(5,key=lambda x:-1*int(x[1]))——降序排序
userRDD.takeOrdered(5,key=lambda x:(-int(x[1]),x[2]))——多个字段排序
- 使用DataFrame排序
user_df.select("userid","occupation","gender","age").orderBy("age").show(5)——升序
user_df.select("userid","occupation","gender","age").orderBy("age",ascending=0).show(5)
df.orderBy(["age","gender"],ascending=[0,1]).show(5)——多个字段排序
- 使用Spark SQL排序
sqlContext.sql("""
SELECT userid,occupation,gender,age FROM user_table
order by age desc,gender""").show(5)
2.3.3 显示不重复数据
- RDD显示不重复数据
userRDD.map(lambda x:x[2]).distinct().collect()
- DataFrame显示不重复数据
user_df.select("gender").distinct().show()
- Spark SQL显示不重复数据
sqlContext.sql("select distinct gender FROM user_table").show()
2.3.4 分组统计数据
1)RDD分组统计数据
userRDD.map(lambda x:(x[2],1)).reduceByKey(lambda x,y:x+y).collect()
2)DataFrames分组统计数据
user_df.select("gender").groupby("gender").count().show()
3)Spark SQL分组统计数据
sqlContext.sql("""
SELECT gender,count(*) counts FROM user_table
group by gender""").show()
2.3.5 Join联接数据
- 准备zipcode数据
1)拷贝数据到HDFS目录下
[root@tango-spark01 data]# hadoop fs -copyFromLocal -f /usr/local/spark/ipynotebook/data/free-zipcode-database-Primary.csv /input/data
2)读取并查看数据
Path="hdfs://tango-spark01:9000/input/"
rawDataWithHeader=sc.textFile(Path+"data/free-zipcode-database-Primary.csv")
rawDataWithHeader.take(5)
3)删除第一项数据
header = rawDataWithHeader.first()
rawData = rawDataWithHeader.filter(lambda x:x !=header)
4)删除特殊符号
rawData.first()
rData=rawData.map(lambda x:x.replace("\"",""))
rData.first()
5)获取每一个字段
zipRDD=rData.map(lambda x:x.split(","))
zipRDD.first()
- 创建zipcode_tab
1)创建zipCode Row的schema
from pyspark.sql import Row
zipcode_data = zipRDD.map(lambda p:
Row(zipcode=int(p[0]),zipCodeType=p[1],city=p[2],state=p[3]))
zipcode_data.take(5)
2)Row类型数据创建DataFrames
zipcode_df=sqlContext.createDataFrame(zipcode_data)
zipcode_df.printSchema()
3)创建登录临时表
zipcode_df.registerTempTable("zipcode_table")
zipcode_df.show(10)
- Spark SQL联接zipcode_table
sqlContext.sql("""
select u.*,z.city,z.state from user_table u
left join zipcode_table z ON u.zipcode=z.zipcode
where z.state='NY'
""").show(10)
2.3.6 使用Pandas DataFrame绘图
- 按照不同的州统计并以直方图显示
1)转换为Pandas DataFrames
import pandas as pd
GroupByState_pandas_df = GroupByState_df.toPandas().set_index('state')
GroupByState_pandas_df

2)使用Pandas DataFrames绘出直方图
import matplotlib.pyplot as plt
#matplotlib inline
ax=GroupByState_pandas_df['count'].plot(kind='bar',title='State',figsize=(12,6),legend=True,fontsize=12)
plt.show()

- 按照不同的职业统计并以饼图显示
1)创建Occupation_df
Occupation_df=sqlContext.sql("""
SELECT u.occupation,count(*) counts
FROM user_table u
GROUP BY occupation
""")
Occupation_df.show(5)
2)创建Occupation_pandas_df
Occupation_pandas_df=Occupation_df.toPandas().set_index('occupation')
Occupation_pandas_df

3)用Pandas DataFrame是绘出饼图PieChart
ax=Occupation_pandas_df['counts'].plot(kind='pie',
title='occupation',figsize=(8,8),startangle=90,autopct='%1.1f%%')
ax.legend(bbox_to_anchor=(1.05,1),loc=2,borderaxespad=0.)
plt.show()
- kind=‘pie’:绘制饼图
- startangle=90:设置图形旋转角度
- autopct=’%1.1f%%’:设置显示饼图%

参考资料
- Python+Spark 2.0+Hadoop机器学习与大数据实战,林大贵
转载请注明原文地址:https://blog.csdn.net/solihawk/article/details/116050157
文章会同步在公众号“牧羊人的方向”更新,感兴趣的可以关注公众号,谢谢!
