Redis Cluster集群架构部署实现及节点的扩容和缩容
redis通过主从或者哨兵机制确实解决了单点失败问题,但是写操作都只发生在master节点,而master节点只有一个,写性能没有提升,因此,在大量的高并发场景下主从加上哨兵机制是支撑不了的,所以我们需要redis cluster来解决这个问题,
redis cluster是3.0之后推出的一个技术,也就是相对偏后的一个技术,它可以很好的提升redis集群写操作的性能,也能保证服务的高可用,redis cluster的实现方案是基于所谓分布式的集群解决方案,所谓分布式就是数据不是放在单一的一个主机上,而是把数据分片或者是切割成多个部分,每个部分放在不同的服务器上,总体来讲,每个主机只承担了一部分数据,自然也只是承担了一部分用户的访问,每个主机的负荷自然也就减轻了,从而,对外就可以提供更好的性能
当然分布式还要解决数据访问的位置问题,存在一个寻找数据的问题,早期在redis cluster之前有一些第三方公司开发了一些redis分布式解决方案,比如客户端分区,写数据由客户端来提前约定数据的存放位置,这样的话对客户端的要求比较高,需要提前约定好,这种方式也存在一个问题,如果某个主机故障,会造成数据丢失,为了容错,我们应该增加从节点,哨兵机制加主从可以解决这个问题,但是这是独立的集群,每个集群之间没有联系,毫不相干,还有代理机制,通过第三方软件来解决,客户端通过代理机制作为媒介去访问redis,代理手机客户端的请求,通过代理机制的vip调度到后端redis服务器,不过这个代理机制不是redis官方推出,为第三方软件,例如codis,twemproxy
而redis cluster彻底的解决了这些问题,不需要设代理,无中心架构的redis cluster机制,在无中心的redis集群当中其每个节点保存当前节点数据和整个集群状态每个节点都和其他所有节点连接,类似ping的机制探测每个节点的健康性,如果某个节点失效是由整个集群中超过半数的节点检测都失效(类似于sentinel的投票机制),才能算真正的失效,客户端不需要proxy而是提供了API开发接口即可连接redis,应用程序需要配置所有redis服务器的IP,具体连接哪个由其决定,redis cluster把所有的redis node平均映射到0-16383个槽位上,也就是说把所有数据平均分成了16384份,把16384分数据再平均分配到redis节点上,因此有多少个redis node相当于redis并发扩展了多少倍,节点越多,每个服务器分配的槽位就越少,每个主机的负担就减轻很多,负载均衡,总体的性能就会得到改善,当需要在redis集群中写入一个key-value的时候,会利用CRC16的哈希运算得出一个哈希值对16384取模,决定key写入值应该放在哪个槽位哪个节点上,从而有效的解决单机瓶颈问题。
!注意:集群中的 master节点须是奇数个,偶数容易形成脑裂。
Redis cluster集群架构详解
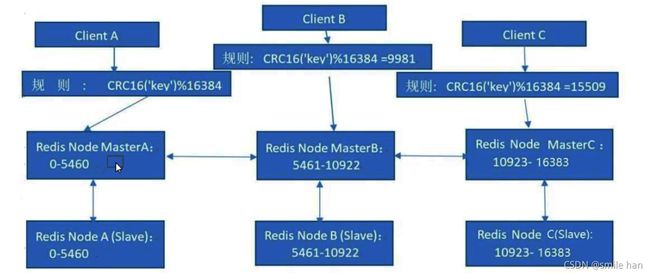
假设有三个节点来存放槽位,每个节点承担三分之一的槽位数,即A节点覆盖0-5460,B节点覆盖5461-10922,C节点覆盖10923-16383,当用户访问某一个数据时,会根据哈希算法得出的哈希值判断数据所在的槽位位置,实现数据的分布式存放管理,为了避免节点的单点问题,配合主从复制来同步数据,实现redis的高可用。
Redis cluster集群通信
Redis cluster寻找槽位的过程并不是一次命中,如上图,并不是一次就能找到数据,可能先去询问nodeA,然后再访问nodeB,nodeC
而集群中节点之间的通信,保证了最多两次就能命中对应槽位所在的节点,因为在每个节点中,都保存了其他节点的信息,知道哪个槽位由哪个节点负责,这样即使第一次访问没有命中槽位,但是会通知客户端,该槽位在哪个节点,这样访问对应节点就能精准命中。
节点A对节点B发送一个meet操作,B返回后表示A和B之间能够进行沟通
节点A对节点C发送meet操作,C返回后表示A和C之间能够进行沟通
然后B根据对A的了解,就能够找到C,B和C 之间也建立了联系
直到所有节点都能建立联系,这样每个节点就能够互相知道对方都负责哪些槽位
Redis cluster集群的扩容和缩容
集群并不是建立之后节点就固定不变了,将来有必要的情况下可以增加新节点或者更换节点,如果某个节点有故障可以选择使其下线,但是需要把其故障节点负责的槽位平均分配到其他节点上,扩容的话,把节点加入到集群中,同样也存在类似的一个过程,把其他节点的槽位分配给新节点一些,使其与其他节点的槽位平均。
迁移过程如下:
通知目标节点准备接受数据的槽位—>通知源节点准备输出槽位-->获取源节点槽位中的数据—>迁移数据-->循环迁移数据直至全部迁完-->分配槽位并通知目标节点
故障转移
除了主观下线以外,也会面对突发故障,主要是主节点故障,因为从节点故障并不影响主节点工作,对应的主节点只会记住自己哪个节点下线了,并将信息发送给其他节点,故障的从节点重连后,继续官复原职,复制主节点的数据
只有主节点才需要故障转移,之前可以通过sentinel哨兵机制来实现故障转移,而Redis cluster不需要sentinel哨兵机制,自己就具备故障转移的功能
主观下线是一个节点认为down机了,客观下线是所有节点半数以上认为其down机了,那么主节点客观下线之后,其从节点都有资格成为新的主节点,会有一个选举的过程,只有具备资格的从节点才能参加选举,首先检查从节点和故障节点之间的断线时间,超过cluster-node-timeout的值(默认为10)则会取消选举资格,说明连接时间较长,相对其他节点同步数据差异较大,集群则会自动排除其选举资格,offset的值越大说明同步数据越全,则会取得优先选举资格。
Redis cluster架构部署
集群节点
10.0.0.8(redis5.0.3 node1)
10.0.0.18(redis5.0.3 node2)
10.0.0.28(redis5.0.3 node3)
10.0.0.38(redis5.0.3 node4)
10.0.0.48(redis5.0.3 node5)
10.0.0.58(redis5.0.3 node6)
预留服务器扩展使用
10.0.0.68(redis5.0.3 node7)
10.0.0.78(redis5.0.3 node8)
基于key验证,各个节点互相能够ssh远程连接
Keygen生成密钥先copy到自身节点,后把密钥文件一起copy到需要远程互相ssh的各个节点,之前用过的方法,在此不多做解释
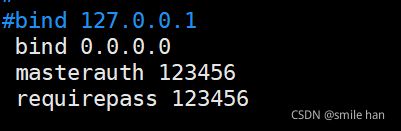
修改每个redis节点的配置,必须开启cluster功能的参数(10.0.0.8-10.0.0.58)
cluster-enabled yes取消此行的注释,必须开启集群,开启后redis进程会有cluster标识
cluster-config-file nodes-6379.conf取消此行注释,集群状态文件,存放的是主从节点之间主从关系以及槽位的分配情况,此文件cluster自行创建和维护。
cluster-require-full-coverage no默认为yes,需修改为no,该项内容是指如果有一个节点不可用,是否整个cluser不可用,目前为6个节点,其中有三主三从,如果有一组主从节点down机,相当于三组集群中的一组故障,会缺少三分之一的数据,该项意指在这种情况下cluster集群还是否提供服务,设置为no,假如一组主从节点故障不影响整个cluster集群的服务,还可以继续用仅剩的三分之二的数据为用户提供服务
[10:24:18 root@node1 ~]$vim /etc/redis.conf



所有节点重启redis服务,开机启动并立即启动
systemctl enable –now redis
![]()
![]()
![]()
![]()
![]()
![]()
查看redis进程,查看是否启用cluster功能

创建集群,分配槽位
此条命令在六个节点中的任意一个节点都可以执行
cluster-replicas 1表示一个master节点配置一个slave节点
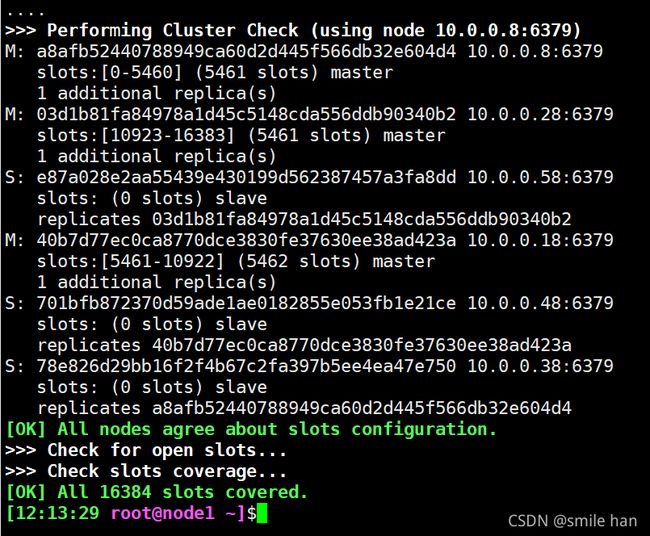
[11:46:16 root@node1 ~]$redis-cli -a 123456 --cluster create 10.0.0.8:6379 10.0.0.18:6379 10.0.0.28:6379 10.0.0.38:6379 10.0.0.48:6379 10.0.0.58:6379 --cluster-replicas 1
10.0.0.8 master node1à10.0.0.38 slave node4
10.0.0.18 master node2à10.0.0.48 slave node5
10.0.0.28 master node3à10.0.0.58 slave node6

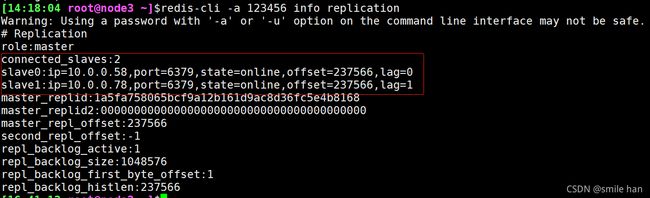
查看主从状态
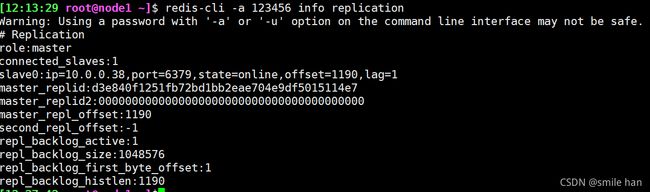
[12:13:29 root@node1 ~]$ redis-cli -a 123456 info replication
[11:44:18 root@node2 ~]$redis-cli -a 123456 info replication
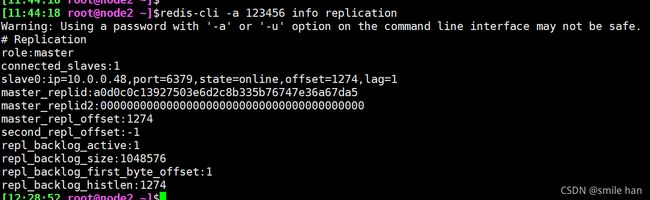
[12:29:33 root@node3 ~]$redis-cli -a 123456 info replication
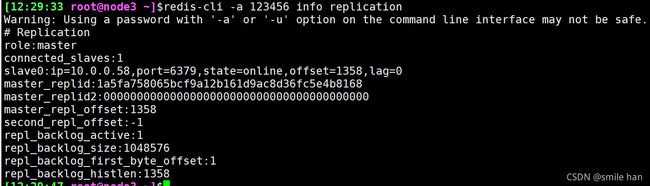
查看mster节点上slave节点的信息
[13:01:02 root@node1 ~]$redis-cli -a 123456 cluster nodes

Cluster info也可以查看主从节点的信息
Cluster_status:ok(集群状态ok)
Cluster_know_nodes:6(共6个节点)
Cluster_size:3(3组主从)

写入数据验证集群
如果是用户的话并不知道数据应该写道那个节点上,如果随意登录一个节点写入key时有可能会报错,同时也会发送moved指令提醒你应该去哪个节点上写入,取相应的节点写入key即可写入成功,同时在写入的节点查询可以查到,如果去其他任意一个节点查询的话同样也会发送moved指令提示你应该去哪个节点查询,此为节点之间的重定向
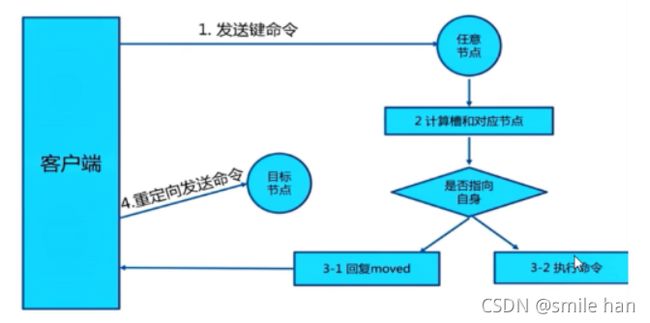



redis帮助里 -c的选项可以自动重定向,识别写入以及查询的key在哪个节点和槽位,请求同样还是发送到node2节点上,只是不需要再去node2节点上写入查询了

![]()
根据集群分配node5是node2的从节点,正常来说在主节点上写入数据从节点上是可以同步过来的,但是仍然报错,可以看出集群的所有slave节点虽然同步数据,但是不对外提供服务,读写都在master节点上,slave节点只提供了备用功能,容错和高可用功能,不能直接访问,只有master节点故障down机时,才会被提升为新主,即可读写

Python脚本实现redis cluster集群的写入
[13:51:54 root@node1 ~]$yum -y install python3
[13:52:06 root@node1 ~]$pip3 install redis-py-cluster
[13:58:57 root@node1 ~]$vim redis_cluster_test.py
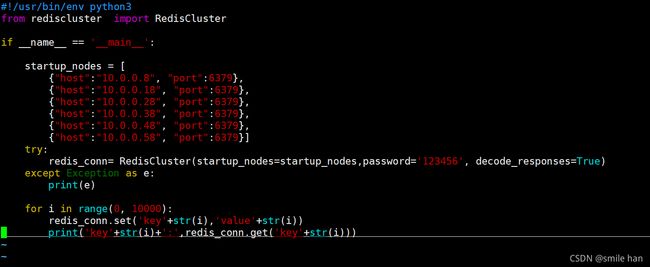
[14:01:03 root@node1 ~]$chmod +x redis_cluster_test.py
[14:13:40 root@node1 ~]$./redis_cluster_test.py
查看节点数据写入情况(一万个值分别写入3个master节点)
Redis默认16(0-15)个数据库,但是集群模式下是不支持多个数据库的,只支持0号这一个数据库
![]()


模拟master节点down机(node1)
[14:25:02 root@node1 ~]$systemctl stop redis
[14:25:27 root@node1 ~]$redis-cli -h 10.0.0.38 -a 123456 info replication
连接自己的slave节点查看状态,10.0.0.38对应的node4节点已成为新主
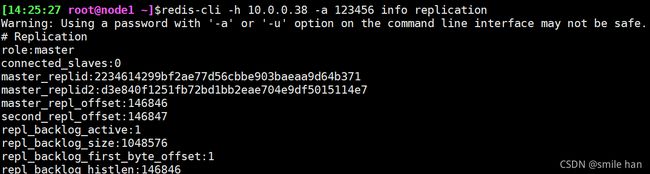
查看主从状态,显示10.0.0.8node1已连接失败,故障down机
如果重新启动故障master节点,会自动成为新主的slave节点
[14:26:42 root@node1 ~]$redis-cli -h 10.0.0.18 -a 123456 --no-auth-warning cluster nodes

[14:31:37 root@node1 ~]$systemctl start redis

到此,redis cluster集群架构已完成,可以看出集群本身就带有高可用功能,自动完成因故障主从位置的切换。
redis cluster动态扩容
10.0.0.68 node7
10.0.0.78 node8
修改配置文件,启用cluster功能
[10:04:23 root@node7 ~]$vim /etc/redis.conf



[14:50:35 root@node8 ~]$vim /etc/redis.conf




启动redis服务,开机启动并立即启动
systemctl enable --now redis
![]()
![]()
查看是否启用cluster集群机制
![]()
![]()
把两个节点加入现有集群中
将10.0.0.68和10.0.0.78加入到集群中,命令中后面的节点可以是任意的集群中的节点,意指把10.0.0.68和10.0.0.78加入到其节点所在的集群中
[15:28:51 root@node7 ~]$redis-cli -a 123456 --cluster add-node 10.0.0.68:6379 10.0.0.28:6379
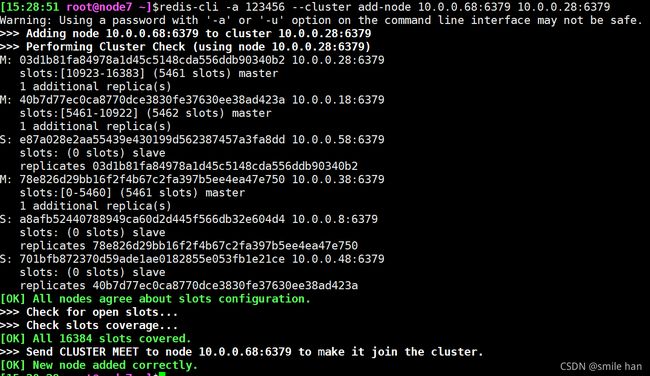
连接其他节点查看当前状态
成功加入集群之后自动成为master节点,但是没有槽位,没有槽位的话,此节点虽然是master,但是不能对外提供访问
[15:32:44 root@node7 ~]$redis-cli -h 10.0.0.18 -a 123456 --no-auth-warning cluster nodes

在新的master节点上重新分配槽位
此命令可在任意节点上执行,其中的节点是当前集群中任意节点,执行之后会把当前集群的节点重新分配
移动的数量为16384的四分之一,4096
然后填写10.0.0.68的ID
[15:44:18 root@node1 ~]$redis-cli -a 123456 --cluster reshard 10.0.0.28:6379
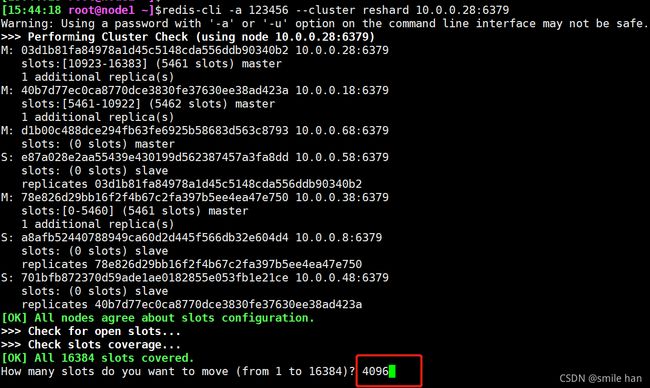
查看节点槽位状态
10.0.0.68的槽位:0-1364 5461-6826 10923-12287

加入10.0.0.78node8节点,为node7的slave节点
[16:02:28 root@node1 ~]$redis-cli -a 123456 --cluster add-node 10.0.0.78:6379 10.0.0.28:6379 --cluster-slave --cluster-master-id d1b00c488dce294fb63fe6925b58683d563c8793
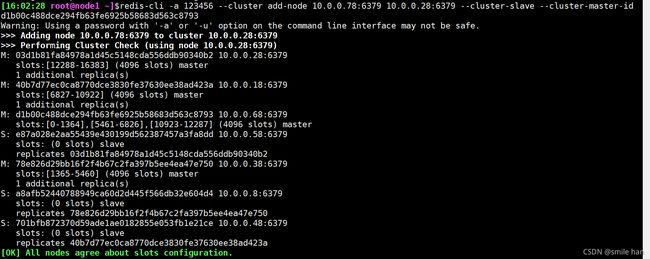
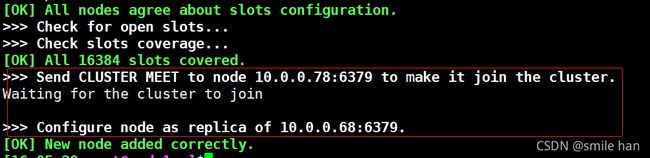
查看新加节点主从状态
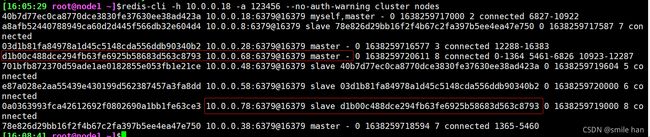
节点的缩容
在集群中的任意节点上都可操作
输入需要移动的槽位和接收的节点(10.0.0.38)
和需要移走槽位的源节点(10.0.0.68)
[16:08:41 root@node1 ~]$redis-cli -a 123456 --cluster reshard 10.0.0.28:6379
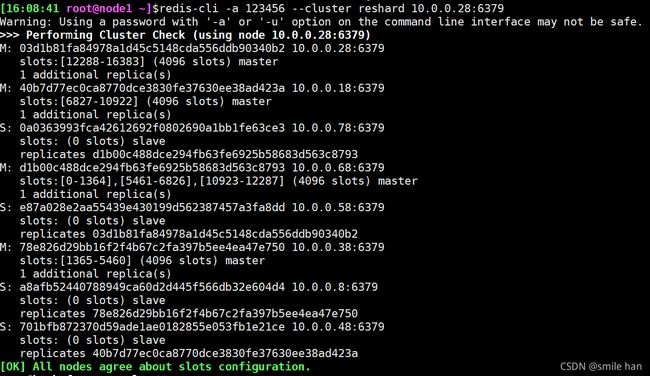
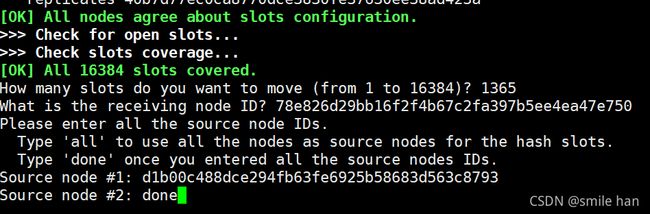
10.0.0.38的 槽位已全部归还
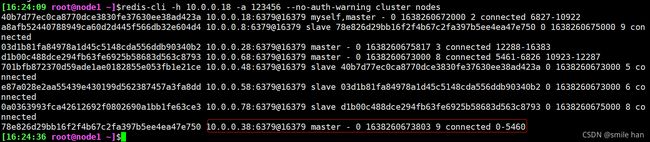
16:24:36 root@node1 ~]$redis-cli -a 123456 --cluster reshard 10.0.0.28:6379


[16:30:04 root@node1 ~]$redis-cli -h 10.0.0.18 -a 123456 --no-auth-warning cluster nodes

[16:30:26 root@node1 ~]$redis-cli -a 123456 --cluster reshard 10.0.0.28:6379
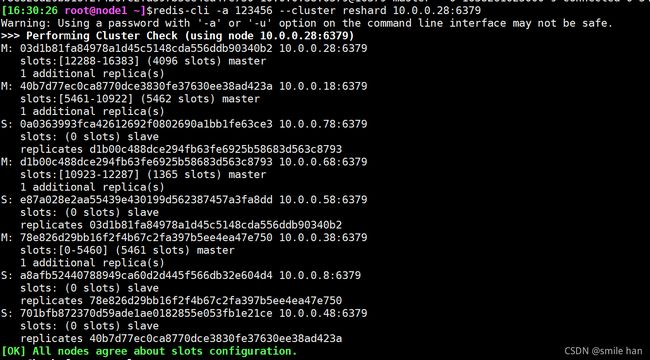
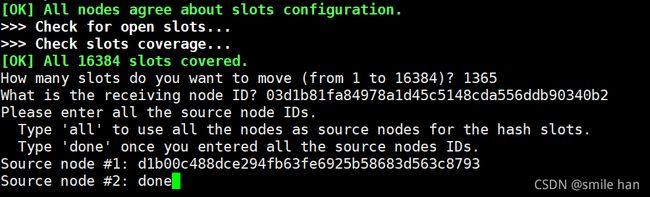
[16:34:20 root@node1 ~]$redis-cli -h 10.0.0.18 -a 123456 --no-auth-warning cluster nodes
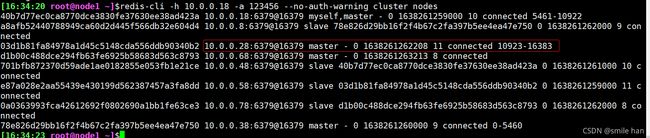
新master节点槽位已分配完毕,查看node8 slave节点的状态
已认新主,其master节点为10.0.0.28 node3
10.0.0.68 node7还是master节点,只是没有槽位了

查看master node3节点
删除已空置的节点(10.0.0.68)
IP为集群中的任意节点ip,但是id为需要删除的节点的id
此命令的-h10.0.0.8不需要写,我忘记删掉了,但是不影响删除操作
[16:34:23 root@node1 ~]$redis-cli -h 10.0.0.18 -a 123456 --cluster del-node 10.0.0.28:6379 d1b00c488dce294fb63fe6925b58683d563c8793

可以看到集群中已没有10.0.0.68

如需要删除新加入的10.0.0.78,操作如上同样执行此命令即可。