mysql 5.7.9 并行复制
mysql 5.7.9 并行复制
背景
在生产环境mysql 5.7.9上出现了从库追不上主库的情况,复制延迟在不断增加。主库的负载比较高,TPS达到500~1000,主要是insert操作。由于插入的数据中,存在一些大文本字段,导致生成的binlog非常大,达到每秒3-4G左右。从库TPS只能达到200~300。
基于上述问题,希望通过mysql 5.7.9的并行提高优化复制效率。
第一部分:基础简介
GTID
GTID(Global Transaction ID)是对于一个已提交事务的编号,并且是一个全局唯一的编号。GTID实质上是由UUID+TID组成的。其中UUID是一个MYSQL实例的唯一标识。(另外还有一个UUID()函数可以生成一个UUID格式的值,该值与机器、时间等变量有关,每次调用均不太一样。select UUID(), UUID() \G)
而TID则是事务ID,随着事务提交而单调递增。
GTID的格式如下
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
GTID从mysql 5.6开始出现,主要有以下两个功能:
根据GTID可以确认事务是由哪个实例提交的
GTID的存在方便了Replication的Failover
假设我现在有A-B-C主从复制集群。 A为主库,BC均为A的从库。假设A库宕机,需要将B升级为主库,同时让C变成B的从库,则会遇到以下问题:
以往,若没有使用GTID模式进行主从复制,当我需要修改复制源时,我需要使用以下命令:
CHANGE MASTER TO MASTER_HOST='xxx', MASTER_LOG_FILE='xxx', MASTER_LOG_POS=nnnn而问题在于,我需要知道新的复制源的MASTER_LOG_FILE及MASTER_LOG_POS与我的从库的同步停止点对应得上才能继续同步。因为新老主库采用的MASTER_LOG_FILE及MASTER_LOG_POS是不一致的,这样就会造成麻烦。GTID可以知道我复制到了A的UUID:TID这个事务了,只要继续同步UUID:TID+1即可。甚至GTID提供了MASTER_AUTO_POSITION,只需要键入以下命令即可修改复制源。
CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION二阶段提交
这个两阶段提交不是分布式事务的两阶段提交,而是在开启binlog之后,redo与binlog的两阶段提交。 两阶段提交,首先redo log prepare,然后写binlog,最后redo log commit。mysql把它称之为内部xa事务(Distributed Transactions),内部xa事务主要是mysql内部为了保证binlog与redo log之间数据的一致性而存在的,这也是由其架构决定的(binlog在mysql层,而redo log 在存储引擎层)
prepare阶段:
主要进行redo log 的写入(具体点说是写入磁盘)。但此时在mysql内部并不认为事务已经commit完成。
commit阶段:
主要进行binlog的写入(先利用write()将binlog内存数据写入文件系统缓存,然后利用fsync()从文件系统缓存刷到磁盘上),最后再调用存储引擎(举个例子:innodb)
也就是三个小阶段:Flush – Sync – Commit,下面组提交有叙述。
如果redo log prepare之后,binlog之前宕机,则回滚事务,日志如下:
2015-07-29 17:03:18 21957 [Note] Starting crash recovery…
2015-07-29 17:03:18 7ffff7fe4780 InnoDB: Starting recovery for XA transactions…
2015-07-29 17:03:18 7ffff7fe4780 InnoDB: Transaction 35077 in prepared state after recovery
2015-07-29 17:03:18 7ffff7fe4780 InnoDB: Transaction contains changes to 1 rows
2015-07-29 17:03:18 7ffff7fe4780 InnoDB: 1 transactions in prepared state after recovery
2015-07-29 17:03:18 21957 [Note] Found 1 prepared transaction(s) in InnoDB
2015-07-29 17:03:18 21957 [Note] rollback xid ‘MySQLXid\1\0\0\0\0\0\0\0\6\0\0\0\0\0\0\0’
如果binlog写入之后宕机,则recover事务
2015-07-29 17:06:23 7ffff7fe4780 InnoDB: Starting recovery for XA transactions…
2015-07-29 17:06:23 7ffff7fe4780 InnoDB: Transaction 35590 in prepared state after recovery
2015-07-29 17:06:23 7ffff7fe4780 InnoDB: Transaction contains changes to 1 rows
2015-07-29 17:06:23 7ffff7fe4780 InnoDB: 1 transactions in prepared state after recovery
2015-07-29 17:06:23 22040 [Note] Found 1 prepared transaction(s) in InnoDB
2015-07-29 17:06:23 22040 [Note] commit xid ‘MySQLXid\1\0\0\0\0\0\0\0\6\0\0\0\0\0\0\0’
2015-07-29 17:06:23 22040 [Note] Crash recovery finished.
组提交(GROUP COMMIT)
组提交分为redo log的组提交和binlog 组提交
redo log的组提交
WAL(Write-Ahead-Logging)是实现事务持久性的一个常用技术,其基本原理就是利用顺序写redo到磁盘来避免磁盘页面的随机写,提高IO效率的同时,保证了事务的持久性。虽然可以顺序写redo日志,但仍然需要一次日志刷盘动作,受限于磁盘IO,这个操作依然是事务并发的瓶颈。
组提交思想就是,将多个redo刷盘动作合并,减少磁盘顺序写的次数。Innodb的日志系统里面,每条redo log都有一个LSN(Log Sequence Number),LSN是单调递增的。每个事务执行更新操作都会包含一条或多条redo log,各个事务将日志拷贝到log_sys_buffer时(log_sys_buffer 通过log_mutex 保护),都会获取当前最大的LSN,因此可以保证不同事务的LSN不会重复。
那么假设三个事务Trx1,Trx2和Trx3的日志的最大LSN分别为LSN1,LSN2,LSN3,(LSN1 < LSN2 < LSN3),它们同时进行提交,那么如果Trx3日志先获取到log_mutex进行落盘,它就可以顺便把[LSN1—LSN3]这段日志也刷了,这样Trx1和Trx2就不用再次请求磁盘IO。
- 获取 log_mutex
- 若flushed_to_disk_lsn>=lsn,表示日志已经被刷盘,跳转5
- 若 current_flush_lsn>=lsn,表示日志正在刷盘中,跳转5后进入等待状态
- 将小于LSN的日志刷盘(flush and sync)
- 退出log_mutex
binlog的组提交
MySQL 5.6 引入BLGC(Binary Log Group Commit),二进制日志的提交过程分成三个阶段,Flush stage、Sync stage、Commit stage。
那么事务提交过程简化为:
存储引擎(InnoDB) Prepare —-> 数据库上层(Binary Log) Flush Stage —-> Sync Stage —-> 调存储引擎(InnoDB)Commit stage.
每个stage阶段都有各自的队列,使每个session的事务进行排队。当一个线程注册了一个空队列,该线程就视为该队列的leader,后注册到该队列的线程为follower,leader控制队列中follower的行为。leader同时带领当前队列的所有follower到下一个stage去执行,当遇到下一个stage并非空队列,此时leader可以变成follower到此队列中(注:follower的线程不可能变成leader)

图1:二进制日志三阶段提交过程
在 Flush stage:所有已经注册线程都将写入binary log缓存
在Sync stage :binary log缓存的数据将会sync到磁盘,当sync_binlog=1时所有该队列事务的二进制日志缓存永久写入磁盘
在 Commit stage:leader根据顺序调用存储引擎提交事务。
当一组事务在进行Commit阶段时,其他新的事务可以进行Flush阶段,从而使group commit不断生效。那么为了提高group commit中一组队列的事务数量,MySQL用binlog_max_flush_queue_time来控制在Flush stage中的等待时间,让Flush队列在此阶段多等待一些时间来增加这一组事务队列的数量使该队列到Sync阶段可以一次fysn()更多的事务。
MySQL 5.7 Parallel replication实现主备多线程复制基于主库Binary Log Group Commit, 并在Binary log日志中标识同一组事务的last_commited=N和该组事务内所有的事务提交顺序。为了增加一组事务内的事务数量提高备库组提交时的并发量引入
binlog_group_commit_sync_delay=N和binlog_group_commit_sync_no_delay_count=N (注:binlog_max_flush_queue_time 在MySQL的5.7.9及之后版本不再生效)参数,MySQL等待binlog_group_commit_sync_delay毫秒直到达到binlog_group_commit_sync_no_delay_count事务个数时,将进行一次组提交。
第二部分:MTS(enhanced multi-threaded slave)
5.6 multi-threaded slave
MySQL 5.6版本也支持所谓的并行复制,但是其并行只是基于schema的,也就是基于库的。因为不同库之间的事务基本上是不存在冲突的。在MySQL 5.6版本之前,Slave服务器上有两个线程I/O线程和SQL线程。I/O线程负责接收二进制日志(更准确的说是二进制日志的event),SQL线程进行回放二进制日志。如果在MySQL 5.6版本开启并行复制功能,那么SQL线程就变为了coordinator线程,coordinator线程主要负责以前两部分的内容:
- 若判断可以并行执行,那么选择worker线程执行事务的二进制日志
- 若判断不可以并行执行,如该操作是DDL,亦或者是事务跨schema操作,则等待所有的worker线程执行完成之后,再执行当前的日志
这意味着 coordinator线程并不是仅将日志发送给worker线程,自己也可以回放日志 ,但是所有可以并行的操作交付由worker线程完成。coordinator线程与worker是典型的生产者与消费者模型。
5.7 enhanced multi-threaded slave
有了binlog的组提交,MySQL 5.7并行复制就简单很多了。 一个组提交的事务都是可以并行回放 ,因为这些事务都已进入到事务的prepare阶段,则说明事务之间没有任何冲突(否则就不可能提交)。
为了兼容MySQL 5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:
- DATABASE:默认值,基于库的并行复制方式
- LOGICAL_CLOCK:基于组提交的并行复制方式
通过mysqlbinlog挖掘binlog文件,可以发现较之原来的二进制日志内容多了last_committed和sequence_number,last_committed表示事务提交的时候,上次事务提交的编号,如果事务具有相同的last_committed,表示这些事务都在一组内,可以进行并行的回放。例如上述last_committed为0的事务有6个,表示组提交时提交了6个事务,而这6个事务在从机是可以进行并行回放的。
上述的last_committed和sequence_number代表的就是所谓的LOGICAL_CLOCK。先来看源码中对于LOGICAL_CLOCK的定义:
class Logical_clock
{
private:
int64 state;
/*
Offset is subtracted from the actual "absolute time" value at
logging a replication event. That is the event holds logical
timestamps in the "relative" format. They are meaningful only in
the context of the current binlog.
The member is updated (incremented) per binary log rotation.
*/
int64 offset;
......使用LOGICAL_CLOCK的场景如下:
class MYSQL_BIN_LOG: public TC_LOG
{
...
public:
/* Committed transactions timestamp */
Logical_clock max_committed_transaction;
/* "Prepared" transactions timestamp */
Logical_clock transaction_counter;
...可以看到在类MYSQL_BIN_LOG中定义了两个Logical_clock的变量:
- max_c ommitted_transaction:记录上次组提交时的logical_clock,代表上述mysqlbinlog中的last_committed
- transaction_counter:记录当前组提交中各事务的logcial_clock,代表上述mysqlbinlog中的sequence_number
第三部分:参数调整
- binlog_group_commit_sync_delay
- binlog_group_commit_sync_no_delay_count
- sync_binlog
- innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit
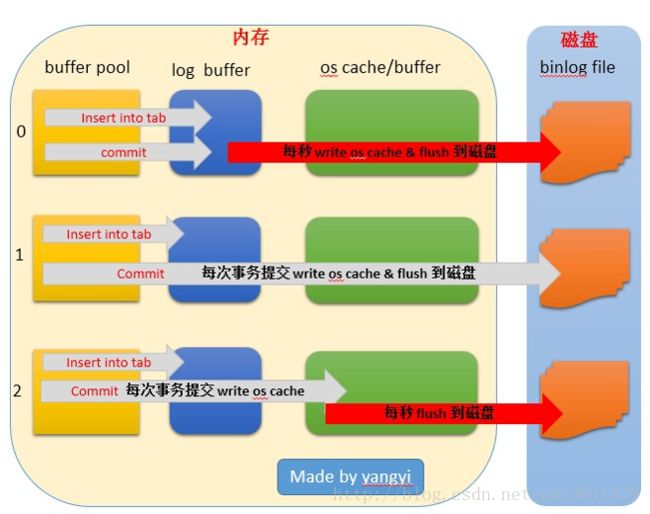
如图所示,该参数影响binlog刷盘的方式。当该值为0,则每秒从log buffer 刷到磁盘,是最不安全的,因为无论数据库宕机还是主机宕机,这一秒内的数据都无法恢复。
当该值为1时最安全,但效率最低,因为每次事务提交都需要刷盘,而磁盘IO是执行效率的瓶颈,但是这样最多只会丢失一个事务commit的信息。
当该值为2时,是一个这种的方法。每次提交都会写到os缓存,然后每隔一秒再刷盘。这样只要主机os不挂,与1的安全性是相等的,而且可以获得比1好的性能。
sync_binlog
sync_binlog参数可以用来设置多少个binlog事务产生的时候调用一次fsync()把二进制日志刷入磁盘。
sync_binlog=0,二进制日志fsync()的操作基于操作系统。
sync_binlog=1,每一个transaction commit都会调用一次fsync(),此时能保证数据最安全但是性能影响较大。
sync_binlog=N,当数据库crash的时候至少会丢失N-1个transactions。
*这个参数与上一个参数innodb_flush_log_at_trx_commit是协同作用的。双1时最安全,但效率最差。而innodb_flush为1,sync_binlog不为1时,性能会提高(这里就不知道到底宕机会丢失1条commit还是丢失sync_binlog的N条commit了。)
实验参考(http://blog.itpub.net/22664653/viewspace-1063134/)
binlog_group_commit_sync_delay
这个参数是以ms为单位,即每多少ms以内的事务会被安排作为一个组提交(如果这些事务之间没有冲突的话),因此调大这个参数应该可以提高group commit的组内事务数,从而提高从库的并行复制效率。是否提高了组内事务数,可以通过mysqlbinlog抓取binlog来查看last_commited相同的值的事务有多少个。
binlog_group_commit_sync_no_delay_count
这个参数与上一个参数协同作用,即每到达多少个事务之后将他们看作一个组。
通过实验,提高这两个值的确有效增加group commit的事务数量。使用sysbench测试软件进行并发测试。将binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count都设置为10000,即10秒内超过10000个事务才进行一次binlog刷盘。
通过mysqlbinlog解析binlog得到如下截图
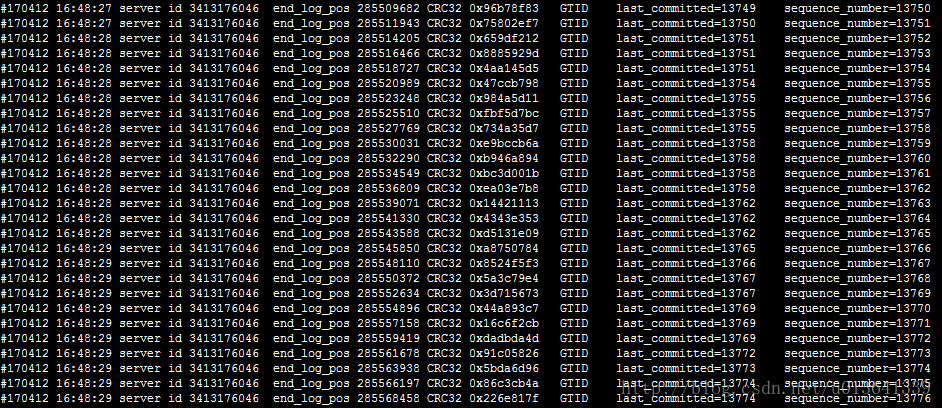
图3 两个参数设置为10000时
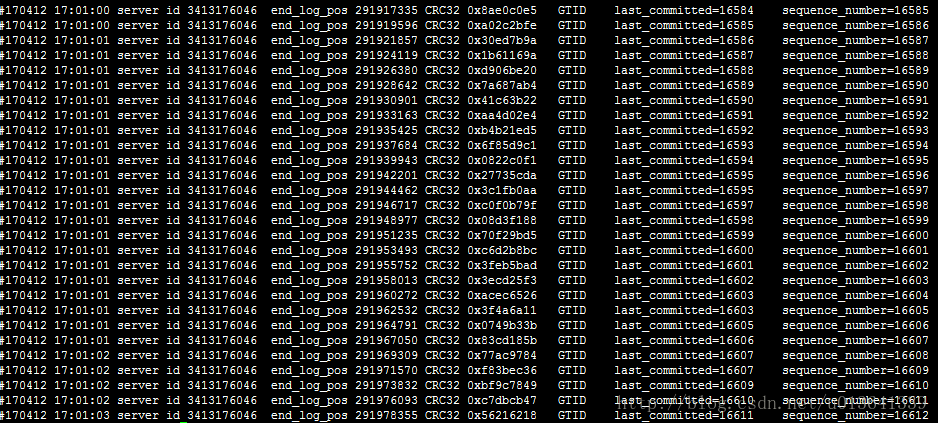
图4 两个参数设置为0时
可以看到,从采样的少量binlog信息中,last_committed相同的事务明显较多。