SSIS 系列 - 在 SSIS 中使用 Multicast Task 将数据源数据同时写入多个目标表,备份数据表,以及写入Audit 信息
转自http://www.cnblogs.com/biwork/p/3328838.html
在 SSIS Data Flow 中有一个 Multicast 组件,它的作用和 Merge, Merge Join 或者 Union All 等合并数据流组件对比起来作用正好相反,非常直观,它可以将一个数据流平行分开成为多个数据流供下游其它 Data Flow 组件使用。
首先描述一下使用 Multicast Task 的几种情形 -
第一种,从同一个数据源中取出一部分数据直接放到 A 表中,一部分数据直接放到 B 表中。我曾经遇到一个370多列的一个文件,这370列的文件可以分出列数不等的7,8 张表。我最开始的做法是先将这个文件的数据 Load 到一个大表中,然后再从大表抽取不同的列到小表中,这样相当于形成了二次加载,效率不高,后来使用 Multicast 就可以一次性直接将 370 列宽的文件分散到不同的表中。
第二种,从数据源 A 抽取数据到 B,B 每次都会先 Truncate 一下,但是又需要备份一下每次从 A 抽取的数据,这个时候也可以使用 Multicast。在每次从 A 抽取数据的时候,通过 Multicast 使数据在导向 B 的同时也导向到 B 的备份表。
第三种,类似于第二种,不同的是没有备份表,但是需要保留加载的一些 Audit 信息数据。比如,从 Source 抽取数据到 Staging 的时候,同时需要记录一下抽取的行数,以及用来标示这批 Staging 数据中最大的时间戳,表名和列的名称。这样的话,下次加载数据到 Staging 的时候就只选择加载新增的 Source 数据,也就是上一批最大时间戳之后的新数据。
当然,同一种问题可能有不同的解决的方式,欢迎大家补充!
下面的示例演示一下第一种和第三种情形。
第一种 - 分散同一个 Source 表数据到多个目标表中
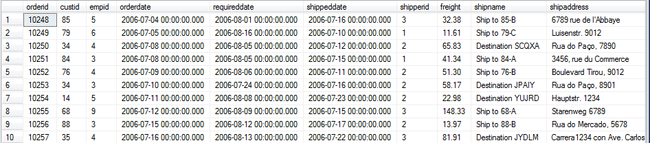
先从 TSQL2012 中抽取一部分测试的数据 (TSQL2012 是 Microsoft SQL Server 2012 High-Performance T-SQL Using Window Function 一书中的示例数据库),我们的 Source 表就是 SalesOrderSource
USE BIWORK_SSIS GO IF OBJECT_ID('dbo.SalesOrderSource','U') IS NOT NULL DROP TABLE dbo.SalesOrderSource GO SELECT * INTO dbo.SalesOrderSource FROM TSQL2012.Sales.Orders WHERE orderdate < '2006-08-01' SELECT * FROM dbo.SalesOrderSource
创建两个目标表,一个用来简单存储 Order 相关信息,一个用来简单存储 Ship 相关信息。
IF OBJECT_ID('dbo.SalesOrder','U') IS NOT NULL DROP TABLE dbo.SalesOrder IF OBJECT_ID('dbo.OrderShip','U') IS NOT NULL DROP TABLE dbo.OrderShip CREATE TABLE dbo.SalesOrder ( OrderID INT, CustID INT, EmpID INT, OrderDate DATETIME, CreateDate DATETIME DEFAULT(GETDATE()) ) CREATE TABLE dbo.OrderShip ( OrderID INT, ShippedDate DATETIME, Shipperid INT, freight MONEY, shipname NVARCHAR(40), CreateDate DATETIME DEFAULT(GETDATE()) )
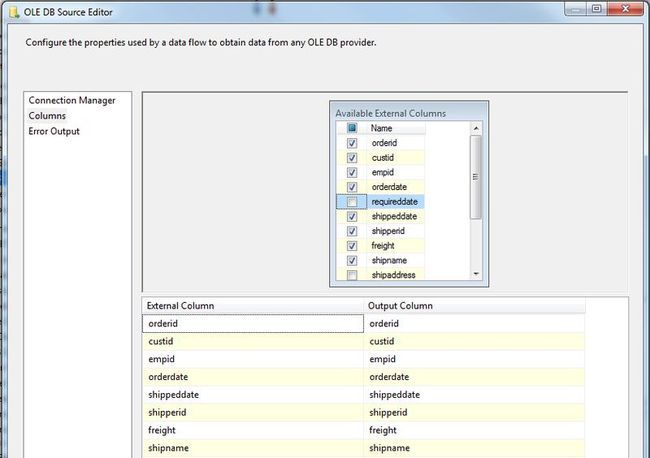
创建连接管理器的过程就不多说了,新建一个 Data Flow Task, 然后创建一个 OLE DB Source 指向 SalesOrderSource 这张数据源表。

在 Columns 中选择只需要向下输出的列,减少不必要的数据传输。
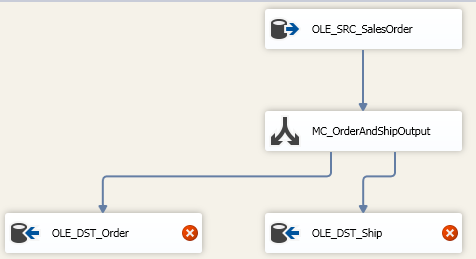
这时就可以添加 Multicast 组件了,并且同时添加另外两个 OLE DB Destination 组件连接到 Multicast 上。
编辑 OLE_DST_Order
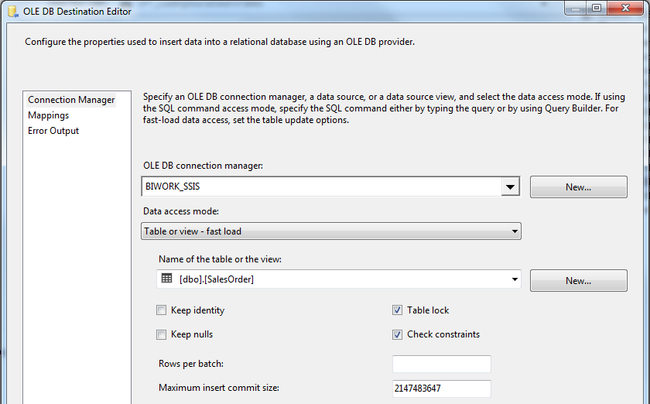
这里的 Avaliable Input 从 数据源经 Multicast 出来的对于 OLE_DST_Order 和 OLE_DST_Ship Task 来说都是等同的,一模一样的,不一样的就是 OLE_DST_Order 可能只需要其中一部分列,而 OLE_DST_Ship 只需要另外的一部分列。

编辑 OLE_DST_Ship

Column Mapping
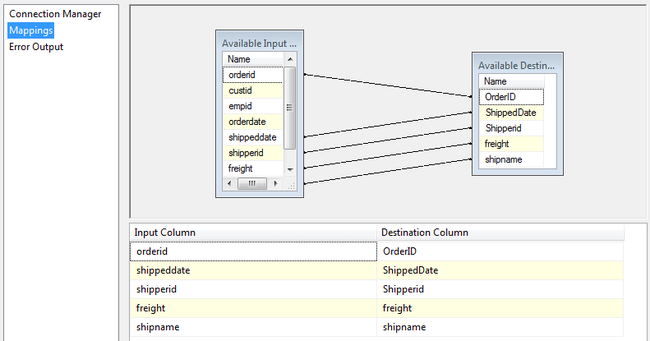
保存并执行 Package,可以看到一个数据源通过 Multicast 就将数据流分成不同的支流走向其它的 Task,并且支流中的数据也是一模一样的,只不过不同的 Destination Task 做了不同的操作。两个分支数据流的执行也是并行执行的,效率上得到的极大的提升。
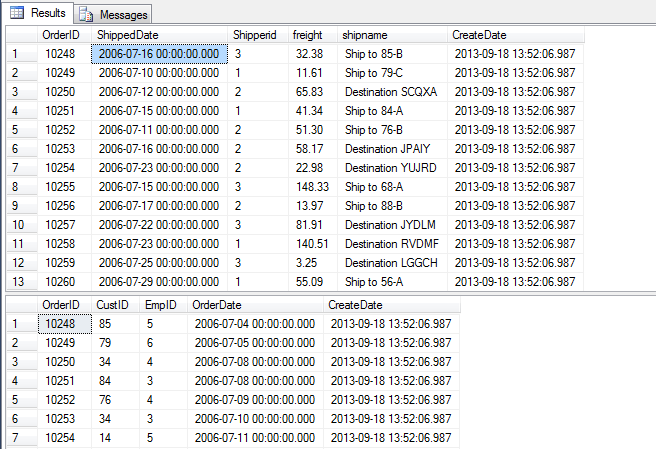
查询一下最终输出的结果,同一个数据源的数据分拆到不同的目标表中了。
第二种和第一种类似,略过。
第三种,假设 SalesOrderSource 是数据源表,现在需要从 数据源表加载数据到 Staging 表中,并且同时需要记录一下每次加载数据的条数,以及能够标示 SalesOrderSource 的在当此加载的最大时间戳,这样下次加载的时候就可以判断应该从什么时候开始只加载新增的部分数据了。
这种情况一般会配合 ProcessLogID 来使用,Package 每执行一次就是一个 Process 有 一个 ProcessLogID,并且可以记录成功或者失败的状态。在这个例子中,就不提供 ProcessLog 的流程了,只简单演示一下通过 Multicast 来实现 Audit 信息记录的处理方式。
先看一下这个订单表,每增加一笔订单就会增加一条数据,OrderDate 表示了下单的日期。假设今天是 2006-12-01,每次加载的时候只加载一个月以前的历史数据。如果第一次加载了 OrderDate < 2006-11-01 之前的数据,那么下一个月 2007-01-01 就只应该加载 2006-11-01 至 2006-12-01 之间的所谓增量数据了。这种情况下,时间点很好确定,都是上一个月1日之前的数据。那如果加载周期不固定呢?那么就有必要记录上次加载的最大时间戳,而这里的 OrderDate 列就是记录上次加载最大时间戳的时间依据。
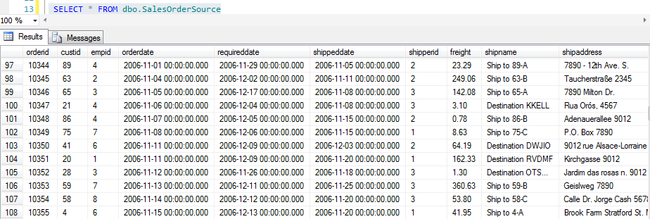
运行下面的 SQL 语句创建相关测试表
USE BIWORK_SSIS GO IF OBJECT_ID('dbo.SalesOrderSource','U') IS NOT NULL DROP TABLE dbo.SalesOrderSource GO SELECT * INTO dbo.SalesOrderSource FROM TSQL2012.Sales.Orders WHERE orderdate < '2006-08-01' SELECT * FROM dbo.SalesOrderSource IF OBJECT_ID('dbo.OrderShipStaging','U') IS NOT NULL DROP TABLE dbo.OrderShipStaging IF OBJECT_ID('dbo.StagingAudit','U') IS NOT NULL DROP TABLE dbo.StagingAudit CREATE TABLE dbo.OrderShipStaging ( OrderID INT, OrderDate DATETIME, ShippedDate DATETIME, Shipperid INT, freight MONEY, shipname NVARCHAR(40), CreateDate DATETIME DEFAULT(GETDATE()) ) CREATE TABLE dbo.StagingAudit ( ProcessLogID INT PRIMARY KEY IDENTITY(1,1), TableName NVARCHAR(50), TrackColumnName NVARCHAR(50), TotalCount INT, LastLoadingDate DATETIME ) SELECT * FROM dbo.StagingAudit SELECT * FROM dbo.OrderShipStaging
StagingAudit 表可以用来跟踪很多有 Fact 表特征的数据表加载信息,因为类似于 Dimension 信息一般在 Staging 阶段每次都是全部重新加载,数据量本身不大。但是对于有 Fact 事实特征的历史数据,每次都重新加载是非常浪费时间的,所以这些表都是要 Track 的。
StagingAudit 表中的 ProcessLogID 只是用来模拟一下 ProcessLog,实际开发当中还会用到其它的列信息,在这里就都省略了。包括每次加载的时候还有检查上一次加载是否成功,上一次加载的时间戳等检查逻辑在这里也省略掉。
把上一个例子中的 Data Flow Task 复制一份,然后删除掉 Multicast 下 Order Destination 的 Task,新添一个 Aggregate 组,OLE_DST_Ship 中的目标表现在换成 dbo.OrderShipStaging 并重新 Mapping 一下。
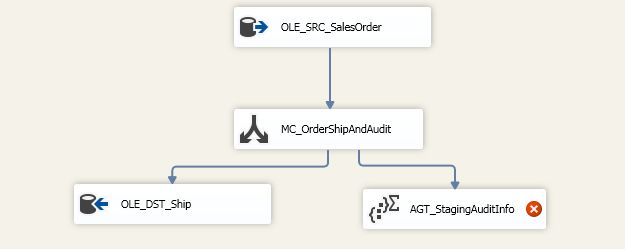
这里取到数据流中的行数以及最大的 OrderDate 值。
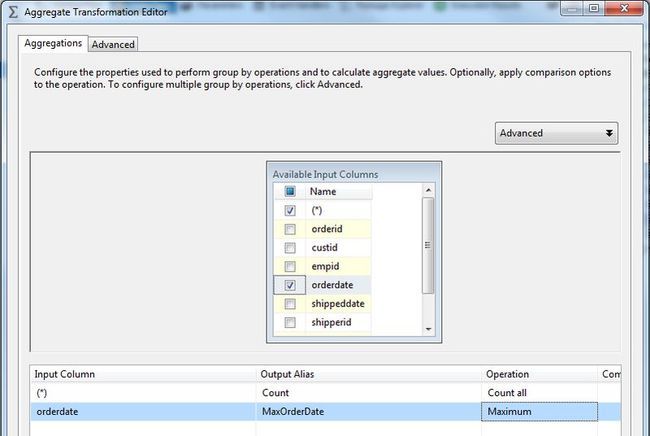
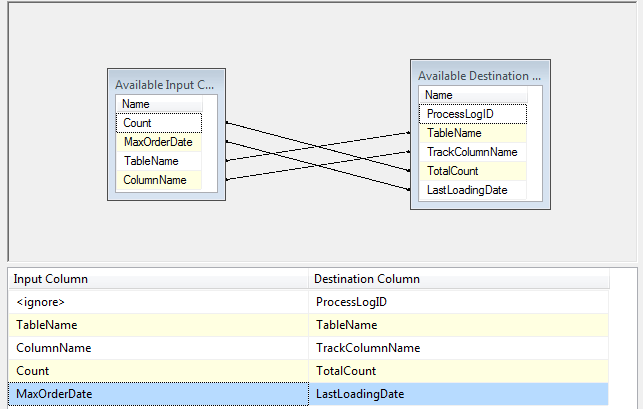
下面添加一个 Derived Column,写入 Table Name 和 Column Name,如果有 Process 或者其它的表的话,也可以添加其它表的信息。
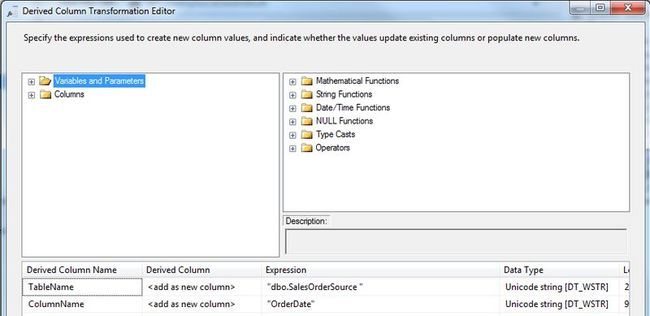
添加一个 OLE DB Destination 组件,并且配置 StagingAudit 表。
Column Mapping
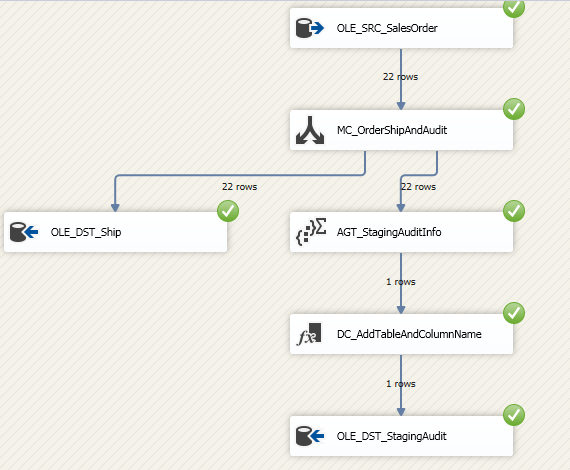
保存 Package 并执行这个 Data Flow Task,在这里可以看到当从 Source 源抽取数据到 Staging 表的同时,通过 Multicast 并行的将数据流分向 Aggregate 组件进行了信息统计,并且保存到 StagingAudit 表中。
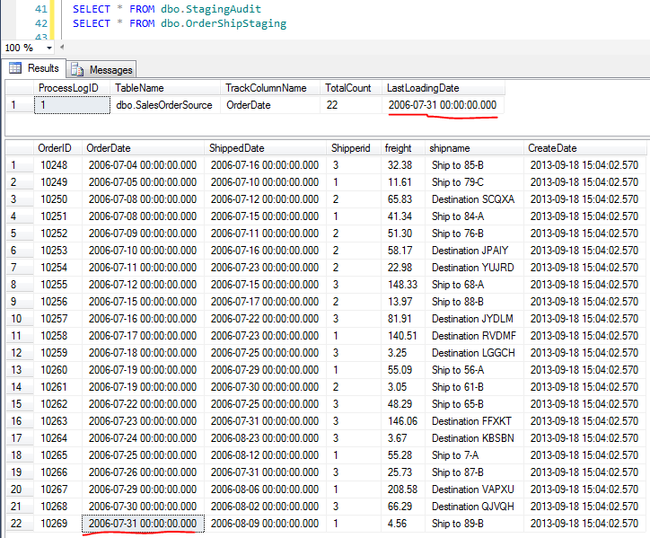
再来看看 StagingAudit 表中的记录。
至此,可以通过上面的几个小示例认识到 Multicast 的作用和特点。
总结:对于上面几个例子中提出的一些解决方案在性能上也有进一步的提升空间,特别是在数据量超过百万或者千万级以上应该要好好尝试一下不同的解决方案,哪一种方案在性能上会更好一些。
比如说,之前提到的有关表备份的问题,通过 Multicast 分支平行写入目标表,当数据量很大的时候就应该可以考虑使用分区表切换分区的方式来进行了。
还有就是第三个示例中出现的 Aggregate 组件和 Sort 组件一样是一个 Blocked 组件,非同步组件,它需要将上游数据流全部加载完毕处理完了之后才开发它自身的数据流到下游组件。这样它所在的整个 Data Flow Task 将会一直被阻塞直到它全部处理完成之后才会走向下一个 Data Flow Task。 所以,也可以考虑当 Staging 数据写完之后再来基于 Staging 数据来记录一些统计信息。
关于在上面提到的有关解决方案,需求不同,项目背景不同可能在解决方案的选择上会有一些差别。在性能方面出现的问题,可能与表本身结构,索引相关,与数据源网络传输,与开发环境的配置高低多少,数据量大小都有关系,但是不同解决方案性能上的临界点,高低之分是需要在这些特定环境下不断尝试,优化才能真正选择一个最优的解决方案。