利用python批量下载ERA5-Daily数据
前言:
ERA5是ECMWF对全球气候的第五代大气再分析。再分析将模型数据与来自世界各地的观测数据结合起来,形成一个全球完整的、一致的数据集。ERA5取代了其前身ERA-Interim再分析,ERA5数据一般为Grid和NetCDF格式。ERA5是一套质量很高的在分析资料!!!
ERA5数据直接提供了逐小时、逐月的在分析资料,但是daily资料下载有点说法。
下载方式:
1. 最粗暴的方式
就是把逐小时的资料全部下载下来,然后自己计算逐日平均。
Copernicus Climate Data Store |
但是把,这样下载时间成本、储存成本和再处理成本有点高。。。
2. 官方提供了daily的统计资料哦
先把官网甩出来~:
Log in |
ERA5 DAILY提供每天7个ERA5气候再分析参数的汇总值:2米空气温度、2米露点温度、总降水量、平均海平面气压、表面气压、10米u风分量和10米v风分量。此外,根据每小时的2米空气温度数据,计算出2米处的每日最低和最高空气温度。每日总降水质以每日总和给出。所有其他参数都以日平均数提供。

根据你想要的选择合适之后,点击RUN便会生成.nc数据,点击下载就行。
但是还是有个问题啊,每个变量每个月都得点击一次,这也太麻烦了!!!
3. 用脚本批量下载
下面主要介绍如何用linux下载,windows下载可见这篇博客,博主写的很详细了!!!
ERA5逐日资料下载方法-数据资料-气象家园_气象人自己的家园
step1:
安装CDS API,大佬可以直接参阅官网提供的AAPI进行下载:
How to use the CDS API |
如果大佬们懒得开,我就简单bb两句怎么搞:
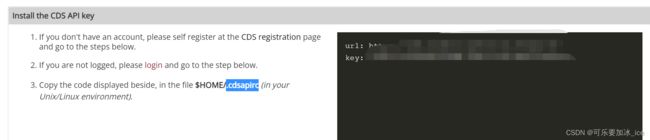
首先,创建.cdsapirc 文件并填入url和key
vim $HOME/.cdsapirc
然后键入i进入写入模式,填写你自己的url和key,类似于:,自己的url和key在此网站中:How to use the CDS API | Copernicus Climate Data Store,将右侧黑框中的url和key复制过来即可,注意需要先登录才会显示自己的url和key。
然后,使用pip安装就行了
pip install cdsapistep2:
运行downloadERA5Daily.py就行 这个脚本代码如下:
# -*- coding: utf-8 -*-
"""
@author:Tong
"""
import time
import cdsapi
import requests
import multiprocessing
# CDS API script to use CDS service to retrieve daily ERA5* variables and iterate over
# all months in the specified years.
# Requires:
# 1) the CDS API to be installed and working on your system
# 2) You have agreed to the ERA5 Licence (via the CDS web page)
# 3) Selection of required variable, daily statistic, etc
# Output:
# 1) separate netCDF file for chosen daily statistic/variable for each month
# Uncomment years as required
# For valid keywords, see Table 2 of:
# https://datastore.copernicus-climate.eu/documents/app-c3s-daily-era5-statistics/C3S_Application-Documentation_ERA5-daily-statistics-v2.pdf
# select your variable; name must be a valid ERA5 CDS API name.
# Select the required statistic, valid names given in link above
c = cdsapi.Client()#timeout=300
years = [ str(id1) for id1 in range(1959,2016) ]
months =[ '%02d' % id2 for id2 in range(1,13) ]
var = "2m_temperature"
stat = "daily_mean"
def Download(iyear, imonth):
t000=time.time()
result = c.service(
"tool.toolbox.orchestrator.workflow",
params={
"realm": "c3s",
"project": "app-c3s-daily-era5-statistics",
"version": "master",
"kwargs": {
"dataset": "reanalysis-era5-single-levels",
"product_type": "reanalysis",
"variable": var,
"statistic": stat,
"year": iyear,
"month": imonth,
"time_zone": "UTC+00:0",
"frequency": "1-hourly",
#
# Users can change the output grid resolution and selected area
#
# "grid": "1.0/1.0",
# "area":{"lat": [10, 60], "lon": [65, 140]}
},
"workflow_name": "application"
})
# set name of output file for each month (statistic, variable, year, month
file_name = stat + "_" + var + iyear + imonth + ".nc"
location = result[0]['location']
res = requests.get(location, stream=True)
print("Writing data to " + file_name)
with open(file_name, 'wb') as fh:
for r in res.iter_content(chunk_size=1024):
fh.write(r)
fh.close()
print('***样本%s 保存结束, 耗时: %.3f s / %.3f mins****************' % (file_name,(time.time() - t000), (time.time() - t000) / 60))
if __name__ == "__main__":
t0 = time.time()
# ===================================================================================
print('*****************程序开始*********************')
for yr in years:
for mn in months:
Download(yr, mn)
print('***********************程序结束, 耗时: %.3f s / %.3f mins****************' % (
(time.time() - t0), (time.time() - t0) / 60))